面对 Excel 中多个班级成绩数据的分析需求,手动计算不仅效率低下,还容易出现误差。本文分享一个简单的 Python 脚本,可实现成绩数据的一键式读取、多维度统计分析,大幅提升工作效率与准确性。
任务需求
在日常教学管理工作中,成绩分析是一项高频且基础的任务,通常需要精准计算班级成绩的平均分、优秀率和不及格率等指标。若 Excel 表格中包含多个班级(按列排布),且各班人数不等、数据量较大时,传统的 Excel 手动筛选或公式计算方式存在以下显著痛点:
- 重复劳动成本高:每个班级需重复设置统计公式,耗时且无技术价值;
- 数据容错率低:行列选择范围稍有偏差,即会导致整体统计结果失效;
- 分析维度单一:难以快速完成多个班级的对比与整体分析。
本文给出一个 Python 脚本,可自动解析 Excel 数据结构、精准识别班级维度,并快速生成标准化的成绩统计报告。
Python 环境配置
在运行 Scores_Analyzer.py 脚本前,需先配置 Python 环境及核心依赖库,这是实现数据自动化分析的基础:
- Python 版本要求:建议使用 Python 3.9 及以上版本(兼容性更佳,运行速度更快);
- Pandas:用于高效读取 Excel 表格,并完成数据清洗(如剔除缺考人员的空值数据);
- Openpyxl:配合 Pandas 解析
.xlsx 格式文件,保障文件格式兼容性。
快速安装指令:在对应 Python 的终端(Terminal 或 CMD)中执行以下命令:
pip install pandas openpyxl
Python 脚本
脚本文件:Scores_Analyzer.py
# Scores_Analyzer.py# 该代码用于统计 Excel 文件中各班级的成绩情况,包括总人数、总分、平均分、优秀人数及率、不及格人数及率等。# 需要安装 pandas 库来读取 Excel 文件,可以使用命令:pip install pandas# 需要安装 openpyxl 库来支持 Excel 文件的读取,可以使用命令:pip install openpyxlimport pandas as pd# 读取 Excel 文件(默认读取第一个工作表)file_path = "Scores.xlsx"# 如果文件不在当前目录,请填写完整路径df = pd.read_excel(file_path)print("===== 各班成绩统计 =====")# 用于存储所有成绩(用于总体统计)all_scores = []# 遍历每一列(每个班级)for class_name in df.columns:# 读取该班级成绩,并去除空值 scores = df[class_name].dropna()# 转为列表 scores = scores.tolist() total_students = len(scores) total_score = sum(scores) average_score = total_score / total_students excellent_count = sum(1for s in scores if s >= 90) fail_count = sum(1for s in scores if s < 60) excellent_rate = (excellent_count / total_students) * 100 fail_rate = (fail_count / total_students) * 100 print(f"\n--- {class_name} ---") print(f"总人数:{total_students} 人") print(f"总分:{total_score} 分") print(f"平均分:{average_score:.2f} 分") print(f"优秀人数(≥ 90):{excellent_count} 人,优秀率:{excellent_rate:.2f}%") print(f"不及格人数(< 60):{fail_count} 人,不及格率:{fail_rate:.2f}%")# 汇总到总成绩 all_scores.extend(scores)# =========================# 计算所有班级总体情况# =========================total_students = len(all_scores)total_score = sum(all_scores)average_score = total_score / total_studentsexcellent_count = sum(1for s in all_scores if s >= 90)fail_count = sum(1for s in all_scores if s < 60)excellent_rate = (excellent_count / total_students) * 100fail_rate = (fail_count / total_students) * 100print("\n========================")print("===== 全部班级统计 =====")print(f"总人数:{total_students} 人")print(f"总分:{total_score} 分")print(f"平均分:{average_score:.2f} 分")print(f"优秀人数(≥ 90):{excellent_count} 人,优秀率:{excellent_rate:.2f}%")print(f"不及格人数(< 60):{fail_count} 人,不及格率:{fail_rate:.2f}%")print("========================\n")
核心实现逻辑
- 智能表头识别:程序自动将 Excel 第一行的列名(如“班级1”,“班级2”)识别为统计维度,无需手动配置;
- 动态数据清洗:通过
.dropna() 方法自动过滤空值单元格,即使各班人数不一致,也能保证统计结果精准; - 质量维度:按“≥ 90 分优秀、< 60 分不及格”的标准,计算优秀人数/优秀率、不及格人数/不及格率;
- 全量数据汇总:在完成单班数据统计后,自动合并所有班级成绩,输出整体统计结果。
运行效果展示
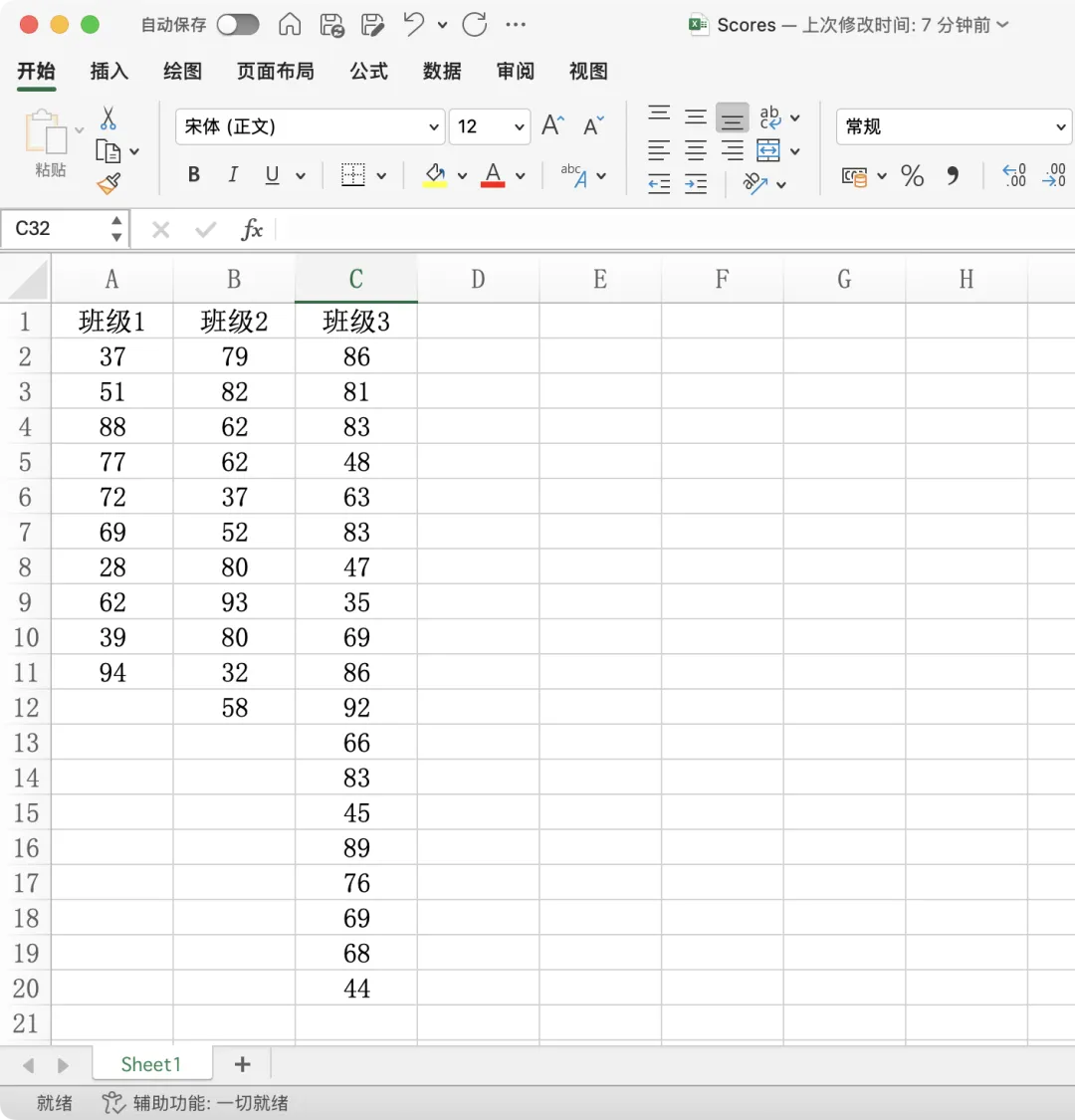
假设 Scores.xlsx 文件中,不同班级的成绩数据按列分布,如图
运行 Scores_Analyzer.py 脚本后,将输出如下分析结果:
===== 各班成绩统计 =====--- 班级1 ---总人数:10 人总分:617.0 分平均分:61.70 分优秀人数(≥ 90):1 人,优秀率:10.00%不及格人数(< 60):4 人,不及格率:40.00%--- 班级2 ---总人数:11 人总分:717.0 分平均分:65.18 分优秀人数(≥ 90):1 人,优秀率:9.09%不及格人数(< 60):4 人,不及格率:36.36%--- 班级3 ---总人数:19 人总分:1313 分平均分:69.11 分优秀人数(≥ 90):1 人,优秀率:5.26%不及格人数(< 60):5 人,不及格率:26.32%============================= 全部班级统计 =====总人数:40 人总分:2647.0 分平均分:66.17 分优秀人数(≥ 90):3 人,优秀率:7.50%不及格人数(< 60):13 人,不及格率:32.50%========================
结语
效率的提升,往往就来自这种顺手的小工具。如果你想从机械的算分工作中解脱出来,可以尝试使用一下这个 Python 脚本。