《Linux-0.12 基础篇》- 03 计算机基础知识
- 2026-06-29 11:57:53
字数 8828,阅读大约需 45 分钟
第三章:计算机基础知识
3.1 概述
在我们开始深入探索 Linux 0.12 内核的奥秘之前,需要先打好坚实的基础。如果你要攀登一座技术高峰,对基本的装备和路线没有充分了解,贸然出发只会迷失方向。本章将为你的内核学习之旅准备必要的知识装备,让你能够理解那些看似神秘的代码背后的原理。
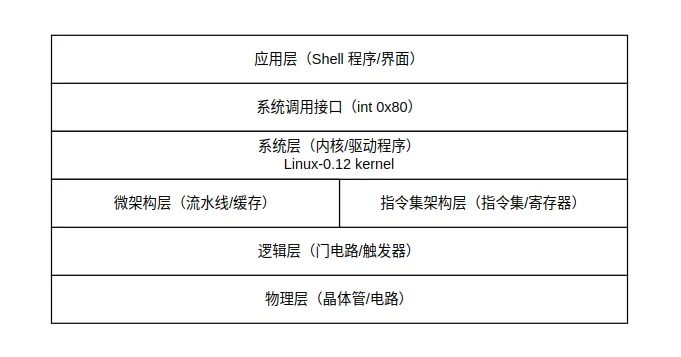
计算机科学的发展如同建造一座宏伟的宫殿。早期的程序员们从最基础的电路和逻辑门开始,一层层向上构建:机器语言 -> 汇编语言 -> 高级语言 -> 操作系统 -> 应用程序。每一层都建立在下层的基础上,同时又为上层提供了更便捷的抽象。Linux内核正是这座宫殿中承上启下的关键楼层——它既要理解下层硬件的“语言”,又要为上层的应用程序提供稳定可靠的运行环境。
学习 Linux 内核需要一种特殊的思维方式,我称之为“分层理解与穿透思考”。你需要同时掌握多个抽象层次的知识:从晶体管开关状态的物理层,到指令执行的架构层,再到进程调度、内存管理的系统层。这就像一位建筑师,既要懂得材料科学(硬件特性),又要精通结构力学(系统设计),还要考虑使用体验(用户界面)。
本章的内容安排遵循从具体到抽象、从底层到高层的逻辑顺序。我们将首先回顾x86汇编语言的基础,这是与硬件直接对话的语言;然后深入学习C语言的关键特性,特别是指针和内存管理,这是内核编程的核心工具;接着重温计算机组成原理,理解硬件如何执行软件指令;最后系统学习操作系统的核心概念,为后续的内核分析建立理论框架。
每一个知识点都不是孤立的,我们会将它们与Linux 0.12的实际代码联系起来。比如,在学习x86分段机制时,我们会查看内核如何设置全局描述符表;在学习进程概念时,我们会分析 task_struct 结构体的定 义。这种理论与实践的结合,让你在学习到解剖学理论知识的同时观察手术过程,能够获得最深刻的理解。
3.2 必要的计算机基础
3.2.1 x86汇编语言基础
汇编语言是计算机能理解的母语,是机器指令的人类可读形式。在Linux 0.12内核中,大约有5%的代码是用汇编语言编写的,主要集中在引导扇区、模式切换和关键性能路径上。理解汇编代码,让你获得直接观察CPU工作的“显微镜”。
x86架构的发展历程本身就是一部微缩的计算机发展史。从1978年的8086处理器开始,到我们关注的80386,再到今天的64位处理器,每一代都在兼容前代的基础上增加新特性。80386引入了保护模式、虚拟内存和32位寄存器,这些特性正是现代操作系统的基础。
让我们从最基础的寄存器开始。想象寄存器就像是CPU的工作台,数据在这里被处理和暂存。80386有8个32位通用寄存器:EAX、EBX、ECX、EDX、ESI、EDI、EBP、ESP。每个寄存器都有其习惯用法:EAX常用于存放函数返回值,ECX用于循环计数,ESP指向栈顶,EBP作为栈帧指针。
; 一个简单的汇编函数示例; 这个函数将两个数相加并返回结果add_numbers: push ebp ; 保存旧的栈帧指针 mov ebp, esp ; 建立新的栈帧 mov eax, [ebp+8] ; 获取第一个参数 add eax, [ebp+12] ; 加上第二个参数 pop ebp ; 恢复旧的栈帧指针 ret ; 返回,结果在EAX中在Linux 0.12的引导代码中,汇编语言发挥着关键作用。让我们查看boot/bootsect.s中的一段实际代码:
! bootsect.s中的关键代码! 将引导扇区从0x07C0移到0x9000BOOTSEG = 0x07c0 ! 原始加载地址INITSEG = 0x9000 ! 目标地址entry startstart: mov ax,#BOOTSEG mov ds,ax ! 设置数据段寄存器 mov ax,#INITSEG mov es,ax ! 设置附加段寄存器 mov cx,#256 ! 512字节 = 256字 sub si,si ! 源偏移清零 sub di,di ! 目标偏移清零 rep ! 重复执行 movw ! 移动字(16位)! 这里使用了段寄存器和重复前缀指令! 展示了x86汇编的典型模式理解这段代码需要知道几个关键点:在实模式下,内存地址由段寄存器和偏移地址共同构成;rep movw是一次高效的块移动操作;引导扇区移动自己是为了给后续代码腾出空间。
保护模式是80386的重要特性,也是现代操作系统的基础。在保护模式下,CPU提供了内存保护、特权级控制和虚拟内存支持。切换到保护模式的过程就像从平房搬进多层楼房——空间更大了,但管理也更复杂了。Linux 0.12在boot/setup.s中完成了这个切换:
! setup.s中切换到保护模式的代码! 设置全局描述符表(GDT)gdt: .word 0,0,0,0 ! 空描述符 ! 代码段描述符 .word 0xFFFF ! 段限长 0-15位 .word 0x0000 ! 段基址 0-15位 .word 0x9A00 ! 属性:存在,特权级0,代码段,可读 .word 0x00C0 ! 粒度4K,32位,限长16-19位 ! 数据段描述符 .word 0xFFFF .word 0x0000 .word 0x9200 ! 属性:存在,特权级0,数据段,可写 .word 0x00C0lgdt gdt_48 ! 加载GDTR寄存器mov ax,#0x0001lmsw ax ! 设置CR0的PE位,进入保护模式jmpi 0,8 ! 跳转到保护模式代码段这段代码创建了一个简单的全局描述符表,定义了代码段和数据段,然后通过设置CR0寄存器进入保护模式。理解这个过程对于理解操作系统的内存保护机制至关重要。
3.2.2 C语言编程(重点:指针、内存管理)
如果说汇编语言是与硬件对话的直接方式,那么C语言就是系统编程的“高级母语”。Dennis Ritchie在开发UNIX操作系统时创造了C语言,这种语言的设计哲学深刻影响了操作系统开发:提供接近硬件的控制能力,同时保持足够的高级抽象。
在Linux内核中,C语言的指针和内存管理特性被发挥到了极致。理解这些特性,就像是手持一把锋利的手术刀——它精准而危险,用得好可以创造奇迹,用不好会导致灾难。
1. 指针的本质
指针是内存地址的抽象。在32位系统中,指针是4字节的值,表示一个内存位置。但指针的真正力量在于它提供的间接访问能力。让我们通过Linux 0.12中的实际代码来理解:
// include/linux/kernel.h 中的典型指针使用// 计算数组元素个数#define ARRAY_SIZE(x) (sizeof(x) / sizeof((x)[0]))// mm/memory.c 中的内存操作// 复制内存页#define copy_page(from,to) \__asm__("cld ; rep ; movsl"::"S" (from),"D" (to),"c" (1024))// 指针的层级访问struct task_struct { // ...struct task_struct *next_task, *prev_task;struct m_inode *pwd, *root; // ...};在struct task_struct定义中,我们看到指针被用来构建链表(next_task、prev_task)和引用其他数据结构(pwd、root)。这种通过指针连接的数据结构是内核的骨架。
2. 指针运算与数组
在C语言中,数组名本质上是指向数组第一个元素的指针。这种设计带来了灵活性和一致性,但也需要格外小心。看看内核中如何遍历任务列表:
// kernel/sched.c 中遍历任务队列struct task_struct *p;// 这是Linux 0.12中经典的遍历方式for(p = &init_task ; (p = p->next_task) != &init_task ; ) { // 处理每个进程 if (p->state == TASK_RUNNING) { // ... }}这段代码展示了一个循环链表遍历。init_task是初始任务,所有任务通过next_task指针连接成环形链表。指针运算p = p->next_task使p指向下一个任务。
3. 结构体与内存对齐
结构体是C语言组织相关数据的核心机制。在内核中,结构体不仅用于数据封装,还通过精细的字段排列来优化内存访问。让我们查看进程控制块的定义:
// include/linux/sched.h 中task_struct的简化版本struct task_struct { long state; /* 进程状态 */ long counter; /* 时间片计数器 */ long priority; /* 优先级 */ long signal; /* 信号位图 */struct sigaction sigaction[32]; /* 信号处理 */ long blocked; /* 阻塞信号位图 */ int exit_code; /* 退出代码 */ unsigned long start_code; /* 代码段起始地址 */ unsigned long end_code; /* 代码段结束地址 */ unsigned long end_data; /* 数据段结束地址 */ unsigned long brk; /* 堆当前位置 */ unsigned long start_stack; /* 栈起始地址 */ long pid; /* 进程ID */ long father; /* 父进程ID */ // ... 更多字段};这个结构体的大小是84字节(在当时的编译环境下)。注意字段的排列顺序:频繁访问的字段(如state、counter)放在前面,这样能够提高缓存命中率。这是内核编程中的一项重要优化技巧。
5. 内存管理的内核视角
用户程序看到的内存是连续的虚拟地址空间,但内核需要管理物理内存的分配。在Linux 0.12中,内存管理相对简单,但也包含了现代内存管理器的雏形。
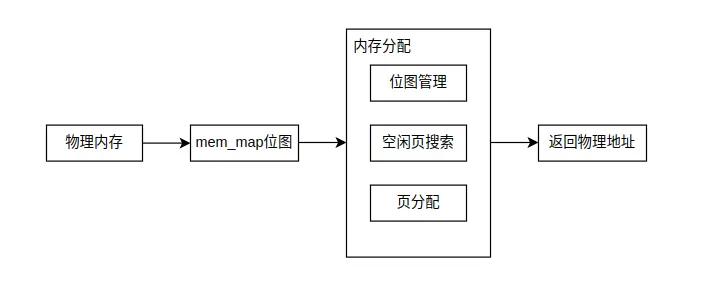
// mm/memory.c 中的物理内存分配unsigned long get_free_page(void){ register unsigned long __res asm("ax"); __asm__("std ; repne ; scasb\n\t" "jne 1f\n\t" "movb $1,1(%%edi)\n\t" "sall $12,%%ecx\n\t" "addl %2,%%ecx\n\t" "movl %%ecx,%%edx\n\t" "movl $1024,%%ecx\n\t" "leal 4092(%%edx),%%edi\n\t" "rep ; stosl\n\t" "movl %%edx,%%eax\n" "1:" :"=a" (__res) :"0" (0),"i" (LOW_MEM),"c" (PAGING_PAGES), "D" (mem_map+PAGING_PAGES-1) :"di","cx","dx"); return __res;}这段汇编与C混合的代码展示了Linux 0.12如何分配一个4KB的物理页。它搜索mem_map位图,找到空闲页后标记为已使用,然后返回物理地址。虽然现代内核的内存管理要复杂得多,但基本原理是一致的:使用位图跟踪页的使用状态。
3.2.3 计算机组成原理回顾
要真正理解操作系统如何工作,我们需要知道硬件如何执行软件指令。计算机组成原理提供了这种理解的基础框架。让我们从CPU的工作循环开始,这是所有计算的基础。
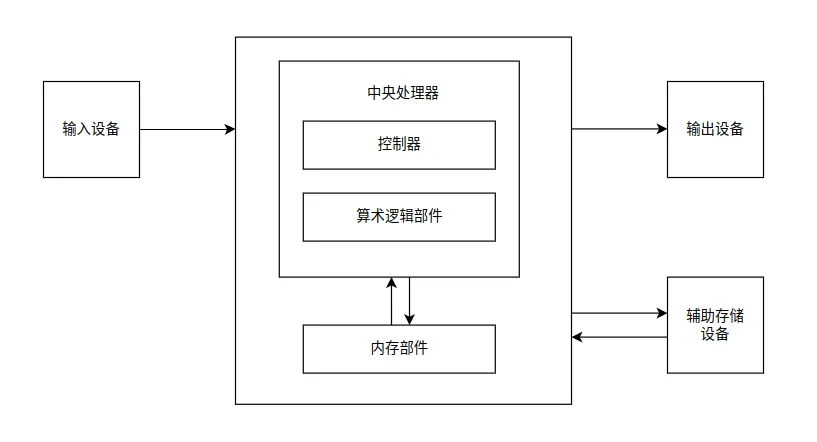
1. 冯·诺依曼架构
在1945年的一个阳光明媚的日子里,冯.诺依曼等人在《关于电子计算装置逻辑结构设计》的研究报告中提出了一种计算机的硬件结构,它就是大名鼎鼎的冯.诺依曼结构,这个结构被沿用至今。其核心思想是“存储程序”——指令和数据存储在同一个存储器中。冯.诺依曼结构指出计算机由控制器、运算器、存储器、输入设备和输出设备5个部分组成,CPU的工作就是不断重复**“取指-译码-执行”**循环。在Linux内核的上下文中,理解这个循环有助于理解上下文切换、中断处理等核心机制。
2. CPU的工作模式
x86处理器有多种工作模式,Linux 0.12主要涉及两种:实模式和保护模式。实模式是8086兼容模式,地址空间只有1MB,没有内存保护。保护模式提供了4GB地址空间、内存保护和多任务支持。内核启动过程中最戏剧性的时刻之一就是从实模式切换到保护模式。
3. 内存层次结构
从CPU寄存器到硬盘,存储设备的速度和容量呈反比关系。理解这个层次结构对于理解内核的缓存策略至关重要。Linux 0.12已经有了缓冲区缓存(buffer cache)的概念,这是磁盘数据在内存中的副本,用于加速文件访问。
// fs/buffer.c 中的缓冲区头结构struct buffer_head { char * b_data; /* 指向数据缓冲区的指针 */ unsigned long b_blocknr; /* 块号 */ unsigned short b_dev; /* 设备号 */ unsigned char b_uptodate; /* 数据是否最新 */ unsigned char b_dirt; /* 是否脏(需要写回磁盘) */ unsigned char b_count; /* 使用计数 */ unsigned char b_lock; /* 是否被锁定 */struct task_struct * b_wait; /* 等待该缓冲区的任务 */struct buffer_head * b_prev; /* 哈希表前驱 */struct buffer_head * b_next; /* 哈希表后继 */struct buffer_head * b_prev_free; /* 空闲链表前驱 */struct buffer_head * b_next_free; /* 空闲链表后继 */};这个数据结构管理着磁盘块在内存中的缓存。b_dirt标志位表示缓冲区内容是否被修改过,需要写回磁盘。b_count记录有多少个进程正在使用这个缓冲区。这些机制共同实现了高效的磁盘缓存。
4. I/O系统
输入输出设备是计算机与外界交互的窗口。内核通过设备驱动程序管理这些设备。在Linux 0.12中,设备管理相对简单,但已经具备了现代设备驱动框架的雏形。
理解计算机组成原理的关键是看到硬件与软件之间的相互作用。当内核执行outb指令向端口写入数据时,它直接与硬件对话;当设置页表项时,它在配置MMU(内存管理单元)的行为;当处理中断时,它在响应硬件信号。这些操作都建立在硬件特性的基础之上。
3.3 操作系统核心概念
3.3.1 进程与线程
进程是操作系统中最核心的抽象之一。它代表了一个正在执行的程序实例,拥有独立的内存空间和系统资源。理解进程就像理解一个独立的“宇宙”——它有自己的代码、数据、堆栈,与其他进程隔离,只能通过操作系统提供的机制进行交互。
1. 进程控制块(PCB)
在Linux 0.12中,进程管理相对简单但完整。让我们深入分析进程控制块(PCB),在内核中称为task_struct:
// include/linux/sched.h 中进程状态的定义#define TASK_RUNNING 0 // 正在运行或准备运行#define TASK_INTERRUPTIBLE 1 // 可中断睡眠#define TASK_UNINTERRUPTIBLE 2 // 不可中断睡眠#define TASK_ZOMBIE 3 // 僵尸状态#define TASK_STOPPED 4 // 停止状态// 进程调度相关的关键字段struct task_struct { // ... long state; /* 进程状态 */ long counter; /* 时间片计数器 */ long priority; /* 静态优先级 */ long signal; /* 接收到的信号 */ // ...};进程状态机是理解进程行为的关键。一个进程在生命周期中会在不同状态间转换:从创建(fork)开始,可能进入就绪状态(TASK_RUNNING),然后被调度执行,执行中可能因为等待I/O进入睡眠状态(TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE),最后通过退出(exit)结束生命。
2. 进程创建与复制
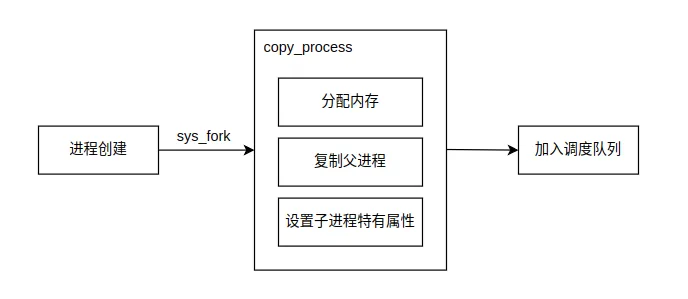
Linux使用fork系统调用创建新进程。这是一个巧妙的设计——通过复制当前进程来创建新进程。让我们看看内核中如何实现:
// kernel/fork.c 中fork系统调用的核心int sys_fork(struct pt_regs *regs){ // 调用copy_process函数创建新进程 return copy_process(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, regs->esp, regs);}static int copy_process(unsigned long clone_flags, unsigned long usp, struct pt_regs *regs){struct task_struct *p; // 1. 为新的task_struct分配内存 p = (struct task_struct *) get_free_page(); if (!p) return -EAGAIN; // 2. 复制父进程的task_struct *p = *current; // 注意:这是结构体复制 // 3. 重置子进程特有字段 p->pid = last_pid++; p->father = current->pid; p->counter = p->priority; // 4. 复制进程地址空间 copy_mem(nr,p); // 5. 设置子进程内核栈 p->tss.esp = usp; // 6. 将新进程加入进程链表 p->next_task = task[0]; task[nr] = p; return last_pid;}这个实现展示了几个重要概念:写时复制(Copy-On-Write)的思想雏形、进程控制块的复制、地址空间的复制。*p = *current;这一行是结构体整体复制,复制了父进程的所有状态。
3. 进程调度
调度器决定哪个进程获得CPU时间。Linux 0.12使用一个简单的轮转调度算法,但已经包含了优先级的概念:
// kernel/sched.c 中的调度函数void schedule(void){ int i, next, c;struct task_struct **p; // 检查每个任务的报警信号 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) if (*p && (*p)->timeout && (*p)->timeout < jiffies) { (*p)->timeout = 0; if ((*p)->state == TASK_INTERRUPTIBLE) (*p)->state = TASK_RUNNING; } // 主调度循环 while (1) { c = -1; next = 0; i = NR_TASKS; p = &task[NR_TASKS]; // 选择counter值最大的就绪任务 while (--i) { if (!*--p) continue; if ((*p)->state == TASK_RUNNING && (*p)->counter > c) c = (*p)->counter, next = i; } if (c) break; // 找到可运行任务 // 所有任务的counter都为0,重新分配时间片 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) if (*p) (*p)->counter = ((*p)->counter >> 1) + (*p)->priority; } // 切换到选中的任务 switch_to(next);}调度算法的核心逻辑是:优先运行counter值最大的就绪进程。每个时钟中断会减少当前进程的counter,当所有进程的counter都减到0时,重新计算counter值(counter = counter/2 + priority)。这种设计既保证了公平性(轮转),又考虑了优先级。
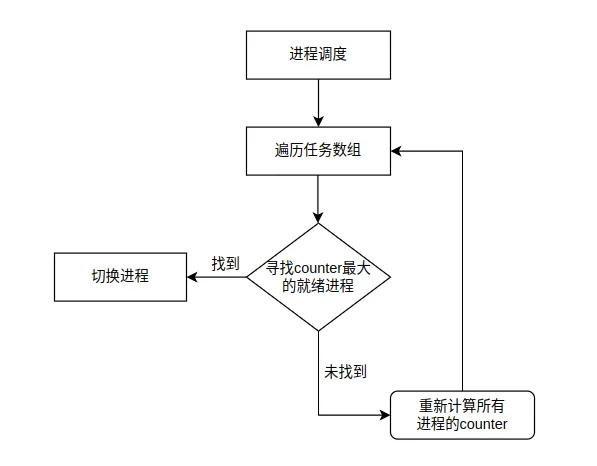
4. 进程间通信
虽然Linux 0.12的IPC机制相对简单,但已经有了信号和管道的支持。信号是进程间异步通知的机制,管道提供了进程间数据流动的通道。
3.3.2 内存管理
内存管理是操作系统的核心功能之一,负责将有限的物理内存分配给多个进程使用。Linux 0.12的内存管理虽然简单,但包含了现代内存管理器的所有基本要素:分段、分页、虚拟内存、物理内存分配。
1. 分段与分页
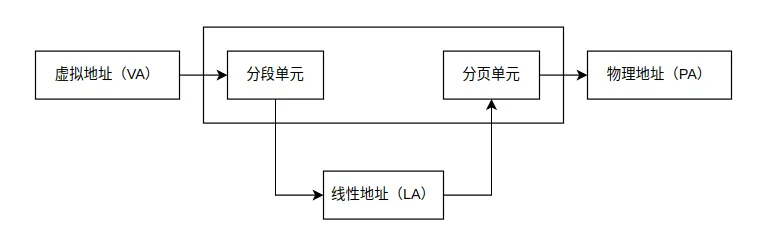
x86架构同时支持分段和分页机制。分段将内存划分为不同的段(代码段、数据段等),每个段有基地址和限长。分页将内存划分为固定大小的页(4KB),通过页表进行映射。Linux主要使用分页机制,分段被最小化使用以简化设计。
让我们查看内核如何设置页目录和页表:
// mm/memory.c 中的页表设置unsigned long * pg_dir = 0; // 页目录指针void mem_init(long start_mem, long end_mem){ int i; HIGH_MEMORY = end_mem; // 清除mem_map(物理内存位图) for (i=0 ; i<PAGING_PAGES ; i++) mem_map[i] = USED; // 标记可用页面为空闲 i = MAP_NR(start_mem); end_mem -= start_mem; end_mem >>= 12; // 转换为页数 while (end_mem-->0) mem_map[i++]=0;}// 设置页表项的函数#define set_bit(nr,addr) ({ \register int res __asm__("ax"); \__asm__ __volatile__("btsl %2,%1\n\tsetb %%al": \"=a" (res):"m" (*(addr)),"Ir" (nr)); \res;})2. 虚拟地址到物理地址的转换
这是内存管理的核心魔法。当进程访问一个虚拟地址时,MMU自动将其转换为物理地址。这个过程对进程透明,但内核需要设置好转换表(页表)。
3. 内存分配策略
内核需要管理物理内存的分配。Linux 0.12使用伙伴系统(buddy system)的简化版本和slab分配器的前身。让我们看看如何分配一页内存:
// 获取一页空闲内存unsigned long get_free_page(void){ register unsigned long __res asm("ax"); __asm__("std ; repne ; scasb\n\t" // 反向扫描字符串 "jne 1f\n\t" // 未找到跳转 "movb $1,1(%%edi)\n\t" // 标记页面为已使用 "sall $12,%%ecx\n\t" // 计算物理地址 "addl %2,%%ecx\n\t" "movl %%ecx,%%edx\n\t" "movl $1024,%%ecx\n\t" // 1024个双字 = 4096字节 "leal 4092(%%edx),%%edi\n\t" // 指向页末尾 "rep ; stosl\n\t" // 清空页面(填充0) "movl %%edx,%%eax\n" // 返回物理地址 "1:" :"=a" (__res) :"0" (0),"i" (LOW_MEM),"c" (PAGING_PAGES), "D" (mem_map+PAGING_PAGES-1) :"di","cx","dx"); return __res;}这个函数展示了几个重要技术:内联汇编的使用、位图搜索算法、页面清零操作。mem_map是一个数组,每个元素对应一个物理页,0表示空闲,1表示已用。
4. 内存保护
内存保护通过页表项中的标志位实现。每个页表项包含存在位(P)、读写位(R/W)、用户/超级用户位(U/S)等。这些标志位使得内核可以保护自己的代码和数据不被用户程序访问,同时保护不同用户程序彼此隔离。
3.3.3 文件系统
文件系统是操作系统管理持久化数据的机制。它将磁盘上的原始数据块组织成用户友好的文件和目录。Linux 0.12使用Minix文件系统,这是一个简单但完整的文件系统设计。
1. 文件系统层次
理解文件系统需要从多个层次思考。最底层是磁盘块设备,以固定大小的块(如1KB)为单位读写。上层是文件系统,将磁盘块组织成inode、目录项和数据块。最上层是用户看到的文件和目录树。
// fs.h 中Minix文件系统的超级块结构struct super_block { unsigned short s_ninodes; // inode数量 unsigned short s_nzones; // 块数量(V1版本) unsigned short s_imap_blocks; // inode位图块数 unsigned short s_zmap_blocks; // 块位图块数 unsigned short s_firstdatazone;// 第一个数据块 unsigned short s_log_zone_size;// 块大小对数 unsigned long s_max_size; // 最大文件大小 unsigned short s_magic; // 魔数 // ...};2. 文件的元数据(inode)
inode(索引节点)存储文件的元数据:大小、权限、时间戳,以及指向数据块的指针。在Minix文件系统中,每个inode有9个块指针:7个直接指针、1个一级间接指针、1个二级间接指针。
// fs.h 中Minix inode结构struct m_inode { unsigned short i_mode; // 文件类型和权限 unsigned short i_uid; // 用户ID unsigned long i_size; // 文件大小(字节) unsigned long i_mtime; // 修改时间 unsigned char i_gid; // 组ID unsigned char i_nlinks; // 链接数 unsigned short i_zone[9]; // 块指针数组 // ...};3. 目录结构
目录是一种特殊文件,内容为目录项列表。每2025个目录项包含inode号和文件名。
// fs.h 中目录项结构#define NAME_LEN 14struct dir_entry { unsigned short inode; // inode号 char name[NAME_LEN]; // 文件名};4. 文件操作流程:
让我们跟踪一个简单的文件读取操作,看看内核如何处理:
1. 用户程序调用 read(fd, buf, count)2. 触发 sys_read系统调用3. 内核通过文件描述符找到file结构 4. file结构指向inode 5. 根据文件偏移量计算逻辑块号 6. 通过inode的块指针找到物理块号 7. 从缓冲区缓存或磁盘读取数据 8. 复制数据到用户空间 9. 更新文件偏移量
// fs/read_write.c 中read系统调用实现int sys_read(unsigned int fd, char *buf, int count){struct file *file;struct m_inode *inode; // 参数检查 if (fd >= NR_OPEN || count < 0 || !(file = current->filp[fd])) return -EINVAL; if (!count) return 0; // 验证访问权限 inode = file->f_inode; if (inode->i_pipe) return read_pipe(inode, buf, count); if (S_ISCHR(inode->i_mode)) return rw_char(READ, inode->i_zone[0], buf, count); if (S_ISBLK(inode->i_mode)) return block_read(inode->i_zone[0], &file->f_pos, buf, count); // 普通文件读取 if (S_ISREG(inode->i_mode)) return file_read(inode, file, buf, count); // 目录文件读取 if (S_ISDIR(inode->i_mode) || S_ISREG(inode->i_mode)) return file_read(inode, file, buf, count); return -EINVAL;}5. 缓冲区缓存
为了减少磁盘访问,内核维护一个缓冲区缓存,存储最近使用的磁盘块。当需要读取块时,首先检查缓存;当修改块时,先在缓存中修改,稍后写回磁盘。
// fs/buffer.c 中从缓存读取块struct buffer_head * bread(int dev, int block){struct buffer_head *bh; // 在缓存中查找 bh = getblk(dev, block); if (bh->b_uptodate) return bh; // 缓存未命中,从磁盘读取 ll_rw_block(READ, bh); wait_on_buffer(bh); if (bh->b_uptodate) return bh; brelse(bh); return NULL;}3.3.4 设备驱动
设备驱动程序是内核与硬件设备之间的桥梁。在Linux 0.12中,设备驱动相对简单,但已经展示了现代设备驱动框架的基本结构。
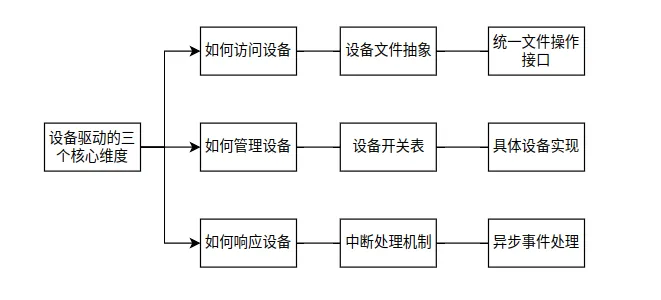
1. 设备分类
Linux将设备分为三类:字符设备(如终端)、块设备(如硬盘)、网络设备(在0.12中尚未完全支持)。每种设备类型有不同的接口和处理方式。
2. 设备文件
UNIX哲学中,"一切都是文件"的概念也适用于设备。设备在文件系统中表现为特殊文件,通过主设备号和次设备号标识。主设备号指定设备类型,次设备号指定具体设备。
// fs.h 中设备号处理#define MAJOR(a) (((unsigned)(a))>>8) // 获取主设备号#define MINOR(a) ((a)&0xff) // 获取次设备号// 字符设备开关表struct file_operations chr_dev_fops[] = { NULL, /* 0 - 无设备 */ rw_ttyx, /* 1 - /dev/ttyx 串行终端 */ rw_tty, /* 2 - /dev/tty 控制终端 */ rw_ram, /* 3 - /dev/ram 内存磁盘 */ rw_mem, /* 4 - /dev/mem 物理内存 */ rw_kmem, /* 5 - /dev/kmem 内核虚拟内存 */ NULL, /* 6 - 未使用 */ rw_port, /* 7 - /dev/port I/O端口 */ rw_mouse, /* 8 - /dev/mouse 鼠标 */ rw_tape, /* 9 - /dev/tape 磁带 */ rw_fd, /* 10 - /dev/fd 软盘 */ rw_wave, /* 11 - /dev/wave 声卡 */ rw_sb, /* 12 - /dev/sb 声霸卡 */ rw_dsp, /* 13 - /dev/dsp 数字信号处理器 */ rw_audio, /* 14 - /dev/audio 音频设备 */ rw_sequencer,/* 15 - /dev/sequencer 音序器 */ NULL, /* 16 - 未使用 */ rw_scsi /* 17 - /dev/scsi SCSI设备 */};3. 设备驱动结构
一个完整的设备驱动通常包含以下部分:初始化函数、打开/关闭函数、读写函数、控制函数(ioctl)。让我们看一个简单的字符设备驱动示例:
// kernel/chr_drv/tty_io.c 中tty设备写函数int tty_write(unsigned channel, char *buf, int nr){struct tty_struct *tty; char c, *b = buf; // 参数检查 if (channel > 2 || !(tty = TTY_TABLE(channel))) return -EIO; // 逐个字符处理 while (nr > 0) { // 如果输出缓冲区满,睡眠等待 if (FULL(tty->write_q)) { // 唤醒可能等待读取的进程 if (FULL(tty->read_q)) wake_up(&tty->read_wait); // 当前进程睡眠 sleep_if_full(&tty->write_q); continue; } // 从用户空间获取字符 c = get_fs_byte(b); // 特殊字符处理(如换行、退格等) if (O_POST(tty)) { if (c == '\n' && !O_ONLCR(tty)) PUTCH(13, tty->write_q); if (O_LCUC(tty)) c = toupper(c); } // 放入输出队列 PUTCH(c, tty->write_q); b++; nr--; } // 启动传输 tty->write(tty); return (b - buf);}4. 中断处理
设备通常通过中断与CPU通信。当设备完成一个操作或需要CPU注意时,会触发中断。内核的中断处理程序需要快速响应,通常分为上半部(快速处理)和下半部(延迟处理)。
// kernel/system_call.s 中的中断处理入口timer_interrupt: push %ds push %es push %fs pushl %edx pushl %ecx pushl %ebx pushl %eax movl $0x10,%eax mov %ax,%ds mov %ax,%es movl $0x17,%eax mov %ax,%fs incl jiffies // 更新系统时钟 movb $0x20,%al outb %al,$0x20 // 发送EOI到8259A call do_timer // 调用C函数处理定时器 popl %eax popl %ebx popl %ecx popl %edx pop %fs pop %es pop %ds iret5. DMA(直接内存访问)
对于大量数据传输,DMA允许设备直接访问内存,无需CPU干预。这提高了数据传输效率,减少了CPU负载。
3.4 系统调用机制
系统调用是用户程序与内核之间的接口。当用户程序需要内核服务时(如读写文件、创建进程),通过系统调用进入内核态。理解系统调用机制是理解操作系统如何保护自己、如何提供服务的关键。
1. 系统调用流程
当用户程序执行int 0x80指令时,CPU从用户态切换到内核态,跳转到内核预设的中断处理程序。这个过程涉及特权级切换、栈切换、寄存器保存等复杂操作。
// include/unistd.h 中系统调用号定义#define __NR_setup 0#define __NR_exit 1#define __NR_fork 2#define __NR_read 3#define __NR_write 4#define __NR_open 5#define __NR_close 6// ... 更多系统调用// kernel/system_call.s 中系统调用入口system_call: cmpl $NR_syscalls,%eax jae bad_sys_call push %ds push %es push %fs pushl %edx pushl %ecx pushl %ebx movl $0x10,%edx mov %dx,%ds mov %dx,%es movl $0x17,%edx mov %dx,%fs call *sys_call_table(,%eax,4) // 调用系统调用处理函数 pushl %eax // ... 后续处理2. 参数传递
系统调用参数通过寄存器传递。在Linux 0.12中,EAX存放系统调用号,EBX、ECX、EDX、ESI、EDI存放最多6个参数。
3. 从内核返回用户空间
系统调用完成后,需要恢复用户程序的执行环境。这包括恢复寄存器、切换栈、修改特权级等。
3.5 中断与异常处理
中断和异常是CPU响应外部事件或内部错误的机制。中断来自外部设备(如定时器、键盘),异常来自CPU内部(如除零错误、页错误)。内核必须妥善处理这些事件,确保系统稳定运行。
1. 中断描述符表(IDT)
x86使用IDT定义中断和异常的处理程序。Linux在启动时初始化IDT,为每个中断向量设置处理函数。
// kernel/traps.c 中设置中断门#define set_intr_gate(n,addr) \ _set_gate(&idt[n],14,0,addr)void trap_init(void){ int i; // 设置陷阱门(异常) set_trap_gate(0,÷_error); set_trap_gate(1,&debug); set_trap_gate(2,&nmi); // ... // 设置系统调用门 set_system_gate(0x80,&system_call); // 设置中断门(硬件中断) for (i = 0; i < 16; i++) set_intr_gate(0x20+i, interrupt[i]); // 加载IDTR __asm__("lidt idt_descr");}2. 中断处理流程
当中断发生时,CPU自动保存部分寄存器,跳转到IDT指定的处理函数。处理函数需要保存剩余寄存器,处理中断,然后恢复寄存器并返回。
3. 中断优先级与屏蔽
多个中断可能同时发生,需要优先级管理。某些关键代码段需要临时屏蔽中断,避免被干扰。
3.6 同步与互斥
在多任务环境中,多个进程可能同时访问共享资源,需要同步机制避免冲突。Linux 0.12提供了基本的同步原语。
1. 临界区
访问共享资源的代码段称为临界区。内核需要确保同一时间只有一个进程进入临界区。
2. 原子操作
某些操作必须不可分割地完成。x86提供了一些原子指令,如xchg(交换)、lock前缀。
3. 信号量
Dijkstra提出的经典同步机制。Linux 0.12虽然未实现完整的信号量,但有类似的机制。
// 简单的忙等待锁volatile int lock = 0;void acquire_lock(void){ while (__sync_lock_test_and_set(&lock, 1)) { // 忙等待 }}void release_lock(void){ __sync_lock_release(&lock);}4. 死锁
多个进程互相等待对方释放资源,导致所有进程都无法继续执行。内核设计需要避免死锁。
3.7 性能与优化
虽然Linux 0.12设计简洁,但已经包含了一些性能优化考虑。理解这些优化有助于我们编写高效的系统代码。
缓存友好性:合理安排数据结构布局,提高CPU缓存命中率。比如将频繁访问的字段放在结构体开头。
减少拷贝:内核与用户空间之间的数据拷贝是性能瓶颈。优化拷贝操作可以提高性能。
延迟操作:将不紧急的操作推迟执行,如磁盘写回、内存回收。
批处理:将多个小操作合并为大操作,减少开销。如磁盘请求合并。
3.8 安全与保护
操作系统必须保护自己不被恶意或错误的用户程序破坏。Linux 0.12提供了基本的安全机制。
特权级:x86有4个特权级(0-3)。Linux使用0级(内核态)和3级(用户态)。用户程序运行在3级,只能执行非特权指令。
内存保护:通过页表项的标志位,内核可以保护自己的代码和数据不被用户程序访问。
系统调用验证:内核必须验证系统调用的参数,防止用户程序传递恶意参数。
资源限制:限制用户程序可以使用的资源,如打开文件数、内存大小。
3.9 本章总结
在本章中,我们系统地回顾了学习Linux内核所需的计算机基础知识。从最底层的汇编语言和硬件架构,到中间的C语言编程和内存管理,再到高层的操作系统概念,我们建立了一个完整的知识框架。
这些知识不是孤立的,它们相互关联、相互支撑。汇编语言让我们理解CPU如何执行指令;C语言让我们理解如何高效地操作内存;计算机组成原理让我们理解硬件如何支持软件;操作系统概念让我们理解系统如何管理资源。
最重要的是,我们看到了这些抽象概念在Linux 0.12中的具体实现。我们看到task_struct如何表示进程,mem_map如何管理物理内存,inode如何描述文件,buffer_head如何缓存磁盘数据。这种从理论到实践的连接,是深入理解操作系统的关键。
在后续章节中,我们将基于这些基础知识,深入分析Linux 0.12的各个子系统。你会看到进程调度器如何选择下一个运行进程,内存管理器如何分配和回收页面,文件系统如何组织磁盘数据,设备驱动如何控制硬件设备。
记住,学习内核是一个渐进的过程。开始时可能觉得复杂难懂,但随着你逐步深入,各个知识点会逐渐连接起来,形成完整的理解。就像拼图游戏,开始时只是一堆碎片,但随着拼凑的进行,整体的图案会越来越清晰。
技术之路,始于基础;深入理解,成于系统。 现在,你的知识基础已经奠定,让我们在下一章开始真正的内核探索之旅。
扩展思考
1. 从8086的实模式到80386的保护模式,x86架构的演进反映了计算机系统设计的哪些核心思想?这些思想对现代操作系统设计有什么影响? 2. C语言作为系统编程语言,其设计哲学(如"信任程序员"、"保持简洁")如何体现在Linux内核的代码风格和架构设计中?这种哲学在今天的系统编程中仍然适用吗? 3. 操作系统通过抽象隐藏硬件复杂性,为用户程序提供简洁接口。这种抽象带来的便利性和性能损失之间应该如何权衡?Linux内核的设计中体现了哪些权衡决策? 4. 从Linux 0.12到现代Linux内核,操作系统的基本原理没有改变,但具体实现变得复杂得多。这种复杂性主要来自哪些需求?在什么情况下,简单设计比复杂设计更可取?
“学问无遗力,少壮工夫老始成。”——陆游《冬夜读书示子聿》

