—— 告别“未安装”假象,三步打通Agent无头浏览器链路
大家好,我是李工!今天是2026年3月7日,星期六,欢迎来到心眸AI笔记。下面带来今日的硬核干货。
💡 懒人总结(核心要点速览)
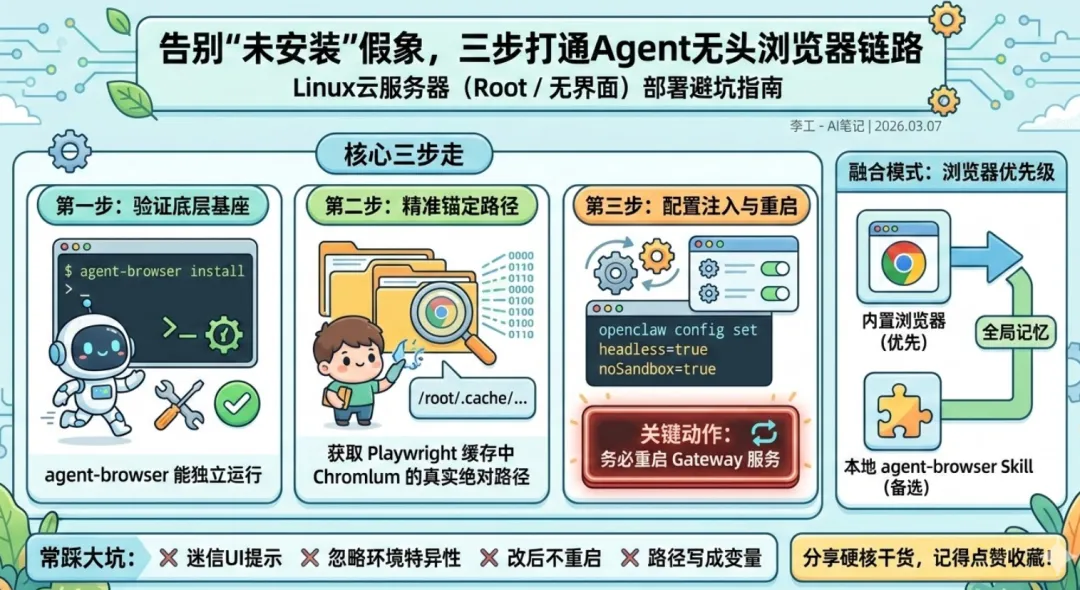
针对Linux云服务器(无桌面环境、Root用户)部署OpenClaw时,常遇到的“UI提示浏览器未安装”问题,核心解决路径不在于反复重装,而在于路径映射与运行态配置。只需牢记三步:
- 验证底层基座: 确保
agent-browser 或 Chromium 能够独立顺畅运行。 - 精准锚定路径: 摒弃系统默认路径依赖,手动为 OpenClaw 指定 Playwright 缓存中的真实执行路径(
browser.executablePath)。 - 适配云端沙盒: 强制开启
headless(无头模式)与 noSandbox(无沙盒模式),并务必重启 gateway 让配置生效。 - 最后为了保障浏览器可用的兜底方案:我的融合操作提示词为”我刚刚在本地的工作目录里面加入了 agent-browser 这个skill,并且这个agent-browser 这个skill已经配置成功(我已经验证),但是现在openclaw的系统内置的browser也能用。所以我现在要让你记住(加入到全局记忆),以后当我说用浏览器搜索或用浏览器进行某个操作的时候,这个时候的优先级要先用 openclaw的系统内置的browser,其次当内置browser不成功之后再用本地工作目录的agent-browser 这个skill。请帮我完成”
一、 现象拆解与根因追踪:打破“组件未安装”的UI假象
在实际的业务部署中,我们经常遇到一种令人迷惑的“断层”现象: 底层测试明明显示 agent-browser install 成功,甚至执行 agent-browser snapshot -i 都能精准抓取页面结构;但一回到 OpenClaw 的前端控制台,系统却冷冰冰地抛出三个 Null:Chrome/Chromium 未安装、detectedBrowser: null、detectedExecutablePath: null。
这背后的根因,本质上是“信息孤岛”导致的探测失效。OpenClaw 的自动化探测机制与 agent-browser 实际调用的浏览器来源往往并不一致。在Linux云环境中,我们安装的往往不是系统全局的 /usr/bin/chromium,而是深藏在 Playwright 缓存目录下的定制版 Chromium。 此外,Linux云服务器天生缺乏桌面环境(需强依赖 headless 模式),且 Root 用户的权限机制极易触发浏览器的安全沙盒拦截(需强依赖 noSandbox 模式)。探测机制一旦在这些前置条件上受阻,UI 就会产生误报。
二、 链路重构:打通浏览器环境的标准SOP
针对上述痛点,我们需要建立一套标准化的排查与配置流程,确保每一层级的数据流转都清晰可控。
步骤 1:基座验证(确认 agent-browser 状态)
不要急于在UI上点按,先在终端验证 Playwright/agent-browser 这一层的核心链路是否通畅:
agent-browser install --with-depsagent-browser open https://example.com --debug --args="--no-sandbox,--disable-setuid-sandbox,--disable-dev-shm-usage"agent-browser snapshot -i
若终端能成功返回网页的 Title 和 DOM 结构(如识别出 Example Domain),则说明底层浏览器引擎健康,问题已圈定在 OpenClaw 的配置层。
步骤 2:路径捕获(寻找真实的 Chromium)
放弃寻找系统自带浏览器,直接定位 Playwright 的下载目录。提取完整可执行路径:
find ~/.cache/ms-playwright -type f -path "*/chrome-linux*/chrome" 2>/dev/null
注:您将获得一个类似 /root/.cache/ms-playwright/chromium-xxxx/chrome-linux/chrome 的绝对路径。
步骤 3:核心配置注入与服务重启(关键动作)
拿到绝对路径后,直接使用 OpenClaw CLI 进行深度配置。强烈建议直接复制以下代码块(替换为您抓取到的真实路径),这是云服务器最稳的配置组合:
# 1. 自动化获取并验证路径PLAYWRIGHT_CHROME=$(find ~/.cache/ms-playwright -type f -path "*/chrome-linux*/chrome" 2>/dev/null | head -n 1)# 2. 注入核心配置openclaw config set browser.defaultProfile "openclaw"openclaw config set browser.headless true --strict-jsonopenclaw config set browser.noSandbox true --strict-jsonopenclaw config set browser.executablePath "$PLAYWRIGHT_CHROME"openclaw config validate# 3. 重启网关(切记!不重启不生效)openclaw gateway restart
步骤 4:终端闭环验证
完成重启后,直接通过命令行验证最终效果,无需理会UI的延迟报错:
openclaw browser --browser-profile openclaw startopenclaw browser --browser-profile openclaw open https://example.comopenclaw browser --browser-profile openclaw snapshot
若终端输出 running: true 并返回页面元素,恭喜你,链路已彻底打通。
三、 高频踩坑与故障诊断矩阵
作为产品经理,我习惯将常见问题进行分类,以便大家在遇到阻碍时能按图索骥:
- 认知误区:迷信UI提示。 只要上述的 CLI 闭环验证通过,UI 提示的“未安装”大概率只是状态未刷新。在云端环境中,以 CLI 的真实运行结果为准。
- 配置遗漏:忽略环境特异性。 无桌面环境强开界面(未设
headless=true),或 Root 强跑沙盒(未设 noSandbox=true),是导致服务闪退的两大元凶。 - 操作断层:改后不重启。 修改
~/.openclaw/openclaw.json 配置后,网关依然在运行旧的上下文。**openclaw gateway restart 是必须执行的终结技。** - 语法错误:路径未展开。 在设置
browser.executablePath 时,务必确保写入的是绝对路径字符串,而不是未经展开的环境变量(如直接写死了 $PLAYWRIGHT_CHROME 文本)。可以通过 openclaw config get browser.executablePath 进行复核。
四、 深度思考与行动呼吁
复盘这次的部署排障,从产品设计的角度来看,它暴露出当前部分 Agent 框架在环境自适应与错误引导机制上的不足。UI 面板应该忠实反映底层链路的真实状态,而不是被单一的探测策略所绑架,从而给出具有误导性的“未安装”提示。
作为开发者和使用者,我们在此类开源工具的迭代期,更需要具备“穿透表象看底层”的能力。明确组件间的调用逻辑,比盲目重装要高效得多。
你在部署 AI Agent 工具时,还遇到过哪些匪夷所思的环境配置坑?或者有哪些独家的排障技巧? 欢迎在评论区留言交流,我们一起探讨。如果你觉得这篇文章帮你省下了几小时的排错时间,别忘了点赞分享!我是李工,我们下期见。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
