想象一下:老板说"把上个月所有退款订单按品类汇总给我",你不需要打开数据库,不需要写 SQL,直接用中文输入这句话,AI 自己去查,自己写 SQL,自己把结论告诉你。这不是 PPT 里的未来,这是今天可以用 100 行 Python 跑起来的东西。本文带你彻底搞懂两个核心系统的构建逻辑。
01为什么要做这两个 Agent?
大模型本身有两个致命弱点:
⚠️ 弱点一 训练数据有截止日期,不认识你的数据库,不知道公司昨天发生了什么。 | | ⚠️ 弱点二 容易"幻觉"。没有事实依据时,会一本正经地编造答案,且听起来极有说服力。 |
SQL Agent —— 直连业务数据库,让 AI 根据真实数据回答,彻底消灭数据类幻觉。
RAG Agent —— 先从私有文档里检索最相关内容,再让 AI 基于内容作答,只说"有据可查"的话。
02RAG Agent:给 AI 装上"私有大脑"
RAG · 检索增强生成
整体数据流
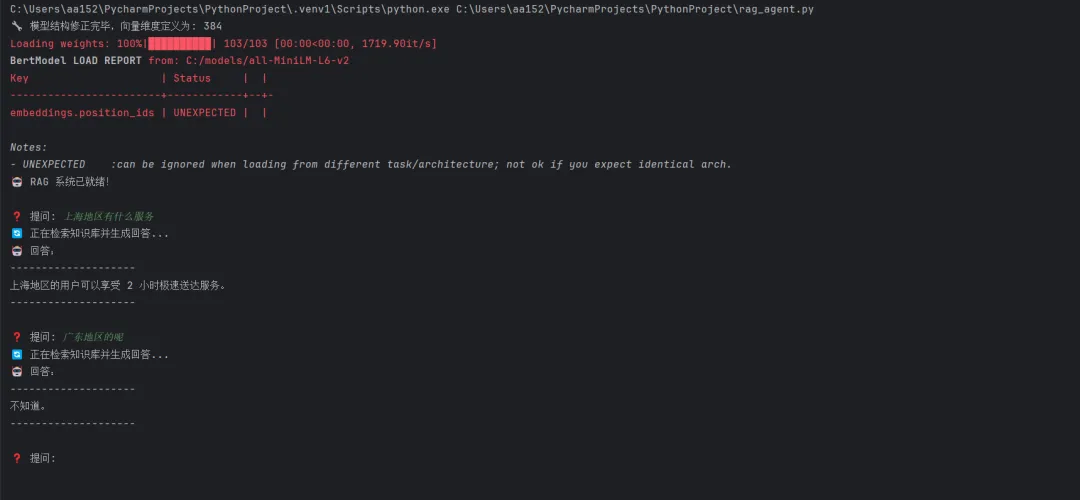
┌────────── RAG 数据流 ──────────┐ 用户提问 │ ▼ 【Embedding 模型】把问题转成向量坐标 │ ▼ 【FAISS 向量库】找最相似的 3 段内容 │ ▼ 【Prompt 组装】问题 + 相关内容打包给 LLM │ ▼ 【DeepSeek LLM】只基于给定内容作答 │ ▼ 输出答案(有据可查) └────────────────────────────────┘
核心一:语义分块,不是无脑切割
很多人忽视这一步,直接按固定字数切,结果把一句话切成两半,语义断裂,检索时就会找错内容。
💡 Overlap 为什么重要?
"产品保修期为两年。从购买日期起计算……"如果在句号后切断,"两年"和"从购买日期起"就分属两块。50字重叠能有效覆盖这类边界情况。
核心二:Prompt 约束,消灭幻觉的关键
通过 Prompt 强制约束 LLM 的"信息来源",让它只能用你提供的上下文作答,找不到答案就说不知道——这是减少幻觉最简单有效的方式。
📄 完整代码:rag_agent.py
import os, json, shutil, warningsfrom dotenv import load_dotenvfrom langchain_community.document_loaders import TextLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_huggingface import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParser# 初始化配置warnings.filterwarnings("ignore")load_dotenv()# ===== 1. 修复模型结构兼容性 =====def fix_local_model(path): config_path = os.path.join(path, "config.json") if not os.path.exists(config_path): return with open(config_path, "r") as f: dim = json.load(f).get("hidden_size", 384) pool_dir = os.path.join(path, "1_Pooling") os.makedirs(pool_dir, exist_ok=True) with open(os.path.join(pool_dir, "config.json"), "w") as f: json.dump({"word_embedding_dimension": dim, "pooling_mode_mean_tokens": True}, f) print(f"🔧 模型结构修正完毕,向量维度: {dim}") # ===== 2. 数据处理:语义分块 =====text_splitter = RecursiveCharacterTextSplitter( chunk_size=400, chunk_overlap=50, separators=["\n\n", "\n", "。", "!", "?"])loader = TextLoader("knowledge.txt", encoding="utf-8")splits = text_splitter.split_documents(loader.load())# ===== 3. 核心引擎:向量检索 =====fix_local_model(os.getenv("LOCAL_EMBED_MODEL"))embeddings = HuggingFaceEmbeddings( model_name=os.getenv("LOCAL_EMBED_MODEL"), encode_kwargs={"normalize_embeddings": True})vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)retriever = vectorstore.as_retriever(search_kwargs={"k": 3})# ===== 4. RAG 链:逻辑编排 =====prompt = ChatPromptTemplate.from_template("""你是一个专业助手。请【仅根据】以下上下文内容回答。找不到答案请直接说不知道。上下文:{context}问题:{input}回答:""")llm = ChatOpenAI( model='deepseek-chat', openai_api_key=os.getenv("DEEPSEEK_API_KEY"), openai_api_base=os.getenv("DEEPSEEK_API_BASE"), temperature=0.5)rag_chain = ( {"context": retriever, "input": RunnablePassthrough()} | prompt | llm | StrOutputParser())# ===== 5. 交互界面 =====print("🤖 RAG 系统已就绪!")while True: user_input = input("\n❓ 提问: ").strip() if user_input.lower() in ['exit', 'quit', '退出']: break print("🔄 正在检索知识库并生成回答...") print(f"🤖 回答:\n{rag_chain.invoke(user_input)}")
rag_agent查询实例:
03SQL Agent:用自然语言查数据库
SQL Agent · 智能数据分析
ReAct 推理链
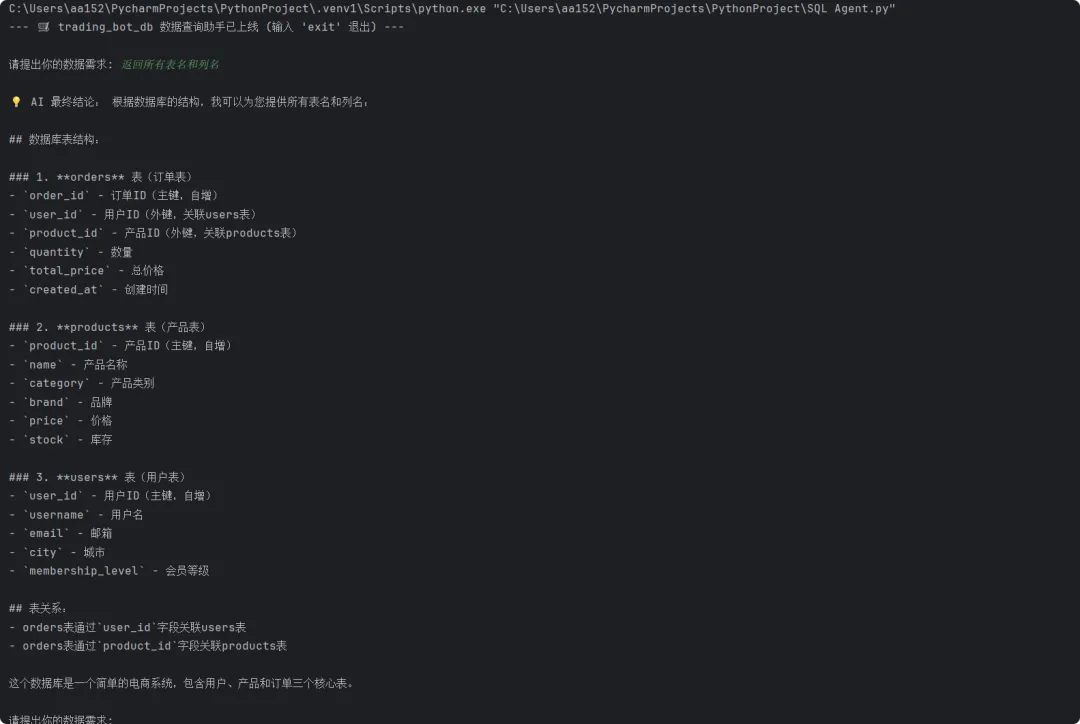
┌────────── SQL Agent 推理链 ──────────┐ 用户输入 → "统计上月各品类退款金额" │ ▼ 【Thought】先看看数据库有哪些表... │ ▼ 【Action】list_tables → schema → query_checker │ ▼ 【Observation】SELECT ... FROM orders ... │ ▼ 【结果不满意?】回到 Thought 修正,再试 │ ▼ 输出最终结论 └──────────────────────────────────────┘
这个循环叫做ReAct(Reasoning + Acting),LLM 不是一次性输出答案,而是像人一样:想一步,做一步,看结果,再调整,错了自动修正 SQL 重试。
避坑重点:密码特殊字符处理
⚠️ 这个 Bug 很难排查
数据库密码包含 @ 符号时,SQLAlchemy 会误认为是 host 分隔符,报出"找不到主机"的错误。解决方法只需一个 quote_plus 转义。
📄 完整代码:sql_agent.py
import osimport urllib.parsefrom dotenv import load_dotenvfrom langchain_openai import ChatOpenAIfrom langchain_community.utilities import SQLDatabasefrom langchain_community.agent_toolkits import ( SQLDatabaseToolkit, create_sql_agent)# 配置与代码分离:切换环境只需换 .env,不改代码load_dotenv()# --- 数据库连接配置 ---db_user = os.getenv("DB_USER")db_password = os.getenv("DB_PASSWORD")db_host = os.getenv("DB_HOST", "127.0.0.1")db_port = os.getenv("DB_PORT", "3306")db_name = os.getenv("DB_NAME")# 密码含 @/:/ 等特殊字符必须转义,否则 URL 解析报错if db_password: encoded_password = urllib.parse.quote_plus(db_password)else: encoded_password = ""mysql_uri = ( f"mysql+pymysql://{db_user}:{encoded_password}" f"@{db_host}:{db_port}/{db_name}")# SQLDatabase 自动内省数据库:抓取表名、列名、示例行db = SQLDatabase.from_uri(mysql_uri)# --- LLM 配置 ---llm = ChatOpenAI( model='deepseek-chat', openai_api_key=os.getenv("DEEPSEEK_API_KEY"), openai_api_base=os.getenv("DEEPSEEK_API_BASE"), max_tokens=1024, temperature=0.3)# --- Agent 核心组件 ---# Toolkit 包含 4 个工具:# 1. list_tables_sql_db → 查有哪些表# 2. schema_sql_db → 查表结构# 3. query_checker_sql_db → SQL 语法预检# 4. query_sql_db → 执行 SQLtoolkit = SQLDatabaseToolkit(db=db, llm=llm)agent_executor = create_sql_agent( llm=llm, toolkit=toolkit, verbose=False, agent_type="openai-tools",)# --- 交互循环 ---print(f"--- 🛒 {db_name} 数据查询助手已上线 ---")while True: query = input("\n请提出你的数据需求: ") if query.lower() in ['exit', 'quit', '退出']: break try: result = agent_executor.invoke({"input": query}) print("\n💡 AI 最终结论:", result["output"]) except Exception as e: print(f"\n❌ 执行出错: {e}")
04两个 Agent 怎么选?
📊 SQL Agent 结构化数据:销售报表、用户行为、库存分析,任何存在 MySQL/PG 里的业务数据。 | | 📚 RAG Agent 非结构化知识:产品手册、合同文档、FAQ、内部 Wiki,任何存在文本文件里的知识。 |
两者也可以组合使用:RAG 提供背景知识,SQL Agent 提供实时数据,这是目前企业级智能问答系统的主流架构。
05核心设计原则回顾
工程设计备忘录
| |
| chunk_overlap=50 是经验起点,保证语义完整 |
| |
| |
| |
| |
两套代码加起来不超过 150 行,但背后的工程思路足够支撑一个真正可用的企业内部 AI 助手。建议直接跑一遍,体感比读文章强十倍。
— 如果这篇对你有帮助,欢迎转发给同样在折腾 AI 应用的朋友 —
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
