大家好,我是 Howell。
最近在做系统性能优化时,我又看到了熟悉的“老朋友”——CPU利用率飙升。排查下来,发现是一个文件上传下载服务,在处理大文件传输时,把CPU吃得死死的。
我就纳闷了,不就是把文件从磁盘读出来,再丢给网卡发出去吗?这活儿主要不是I/O在干吗?CPU跟着凑什么热闹?
这其实是很多中级甚至高级开发容易忽略的盲区:你写的每一行 read() 和 write(),都在疯狂地“折腾”CPU和内存。
在高性能服务器开发中(比如Nginx、Kafka、Netty),“零拷贝”(Zero-Copy) 是绝对的必修课。不懂这个,你的系统吞吐量永远上不去。
今天,我们聊聊 read/write 到底笨在哪里,以及 mmap、sendfile、splice 这三位“零拷贝”大将到底谁更强。
一、 为什么传统的 read/write 这么慢?
很多同学觉得,我写代码逻辑很简单啊:
// 伪代码:最原始的文件传输while((n = read(disk_fd, buf, 4096)) > 0) { write(socket_fd, buf, n);}
这段代码看起来人畜无害,但在内核眼里,这简直就是一场“搬运工的噩梦”。
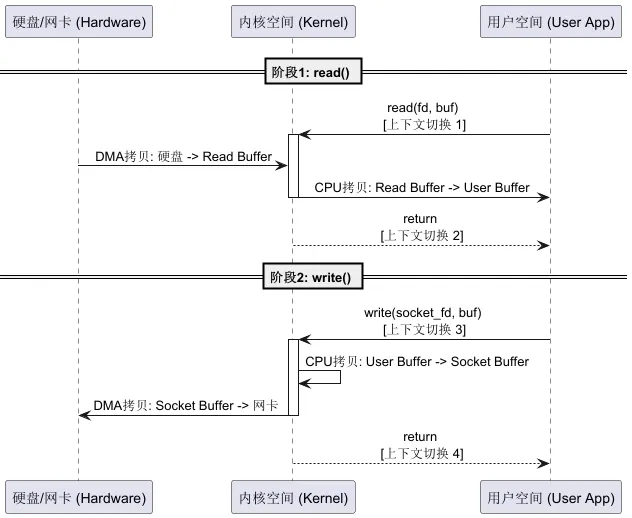
1.1 数据的四次“搬家”
当你执行一次上述操作时,数据经历了什么?
- 1. DMA拷贝:硬盘 -> 内核缓冲区(Read Buffer)。
- 2. CPU拷贝:内核缓冲区 -> 用户缓冲区(你的
buf)。 - 3. CPU拷贝:用户缓冲区 -> Socket缓冲区(内核空间)。
- 4. DMA拷贝:Socket缓冲区 -> 网卡 -> 发送出去。
看懂了吗?数据在内核态和用户态之间反复横跳,白白多拷贝了两次! 而且,这还伴随着 4次上下文切换(用户态->内核态->用户态->内核态->用户态)。
1.2 图解:传统I/O的悲剧
我们用 PlantUML 来看清这个流程:
痛点总结:
- • CPU忙于搬砖:CPU本该去计算业务逻辑,结果全在做
memcpy。
二、 零拷贝三剑客:mmap、sendfile、splice
为了解决这个问题,Linux 提供了几种“零拷贝”技术。注意,这里的“零”通常指减少CPU拷贝次数,DMA拷贝是物理硬件限制,少不了的。
2.1 mmap + write:内存映射的魔法
mmap 的核心思想是:我不搬运数据,我只建立映射。
它将内核缓冲区的数据直接映射到用户空间,这样用户态和内核态就共享了一块物理内存。
流程变化:
- 1.
mmap:建立虚拟内存映射。注意:此时数据还没进内存。 - 2. 缺页中断(Page Fault):当进程访问这块内存时,CPU 触发缺页中断,内核发起 DMA 将数据从硬盘拷贝到 Page Cache(内核缓冲区)。
- 3.
write:CPU 将数据从 Page Cache 拷贝到 Socket 缓冲区。
战绩:
代码示例 1:使用 mmap 读取并发送
#include <sys/mman.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>#include <stdio.h>void use_mmap(int fd_in, int fd_out) {struct stat statbuf; fstat(fd_in, &statbuf); // 1. 建立映射,直接把文件内容映射到内存地址 void *src = mmap(0, statbuf.st_size, PROT_READ, MAP_SHARED, fd_in, 0); if (src == MAP_FAILED) { perror("mmap error"); return; } // 2. 直接把映射的内存写入 socket,少了一次从内核到用户的拷贝 write(fd_out, src, statbuf.st_size); // 3. 解除映射 munmap(src, statbuf.st_size);}
运行结果说明:相比传统read/write,CPU占用率下降,但因为依然有一次CPU拷贝,大文件传输时依然会有一定开销。
2.2 sendfile:天生为文件传输而生
Linux 2.1 引入了 sendfile。它的定义非常简单粗暴:直接把两个文件描述符连起来。
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
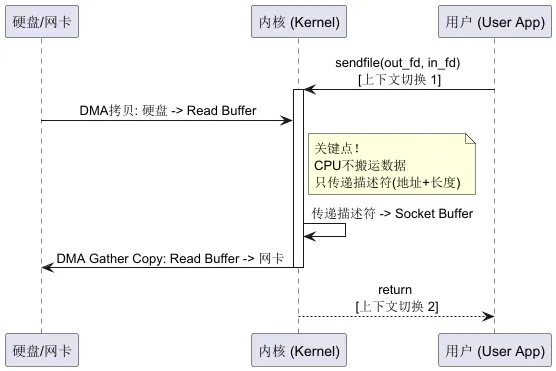
流程变化(Linux 2.4+ 带有 DMA Gather Copy):
- 1. 硬盘 -> Page Cache(内核缓冲区) (DMA)。
- 2. CPU 不拷贝数据,只将数据的描述符(地址+长度)写入 Socket 缓冲区。
- 3. DMA控制器根据描述符,直接把数据从 Page Cache -> 网卡。
注意:这一步“CPU 0拷贝”需要网卡硬件支持 SG-DMA (Scatter-Gather DMA) 技术。如果网卡不支持,内核仍然需要将数据从 Page Cache 拷贝到 Socket 缓冲区。
战绩:
- • CPU拷贝:0次(需硬件支持,这就是真正的零拷贝!)。
代码示例 2:sendfile 的极简调用
#include <sys/sendfile.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>void use_sendfile(int fd_in, int fd_out) {struct stat statbuf; fstat(fd_in, &statbuf); // 一行代码搞定文件发送,完全在内核中完成 // offset 为 NULL 表示从头开始 sendfile(fd_out, fd_in, NULL, statbuf.st_size);}
运行结果说明:这是 Kafka 和 Nginx 处理静态文件的核心技术。CPU 几乎不参与数据搬运,网络吞吐量极大提升。
2.2.1 图解:sendfile 的降维打击
2.3 splice:管道工的艺术
sendfile 虽好,但它有一个硬伤:in_fd 必须支持 mmap(通常是文件),而 out_fd 必须是 Socket。如果你想从 Socket 读数据再写入另一个 Socket(比如做代理服务器),sendfile 就废了。
这时候,splice 登场了(Linux 2.6.17+)。
splice 可以在两个文件描述符之间移动数据,而不需要数据流过用户空间。它的核心约束是:两个 fd 中必须至少有一个是管道(Pipe)。
流程变化:
- 2.
splice 将 Socket缓冲区的数据关联到管道(Pipe)。 - 3.
splice 将管道的数据关联到目标 Socket/文件。
全程数据都在内核态,没有 CPU 拷贝。
代码示例 3:splice 实现回显服务(Echo Server)
#define _GNU_SOURCE#include <fcntl.h>#include <unistd.h>#include <stdio.h>// 假设 fd_in 是客户端socket,fd_out 是目标socketvoid use_splice(int fd_in, int fd_out) { int pipefd[2]; // 1. 创建管道 pipe(pipefd); // 2. 将数据从 socket 移入管道写端 // SPLICE_F_MOVE: 尝试移动页面而不是复制 // SPLICE_F_MORE: 提示内核后续还有数据 int len = splice(fd_in, NULL, pipefd[1], NULL, 4096, SPLICE_F_MOVE | SPLICE_F_MORE); // 3. 将数据从管道读端 移入 目标socket // 注意:实际生产中需要循环调用 splice 直到数据传输完毕,这里仅演示单次调用 splice(pipefd[0], NULL, fd_out, NULL, len, SPLICE_F_MOVE | SPLICE_F_MORE); close(pipefd[0]); close(pipefd[1]);}
运行结果说明:HAProxy 等负载均衡器常用此技术。数据在内核中通过管道“流”过,无需用户态干预,效率极高。
三、 生产环境实战与踩坑
原理懂了,怎么选?怎么用?这里才是架构师和普通开发的分水岭。
3.1 场景对比表
3.2 真实案例:Netty 的 FileRegion
在 Java 的 Netty 中,当你调用 ctx.write(new DefaultFileRegion(file.getChannel(), 0, length)) 时,Netty 底层调用的就是 java.nio.channels.FileChannel.transferTo。
而在 Linux 上,transferTo 会智能降级:
- • 如果内核和硬件支持,它就是
sendfile。 - • 这也就是为什么 Netty 做文件服务器性能吊打传统 Tomcat(BIO模式)的原因。
代码示例 4:Java 中的零拷贝封装
public void nettyZeroCopy(FileChannel fileChannel, SocketChannel socketChannel) throws IOException { long position = 0; long count = fileChannel.size(); // 底层调用 sendfile fileChannel.transferTo(position, count, socketChannel);}
3.3 避坑指南:大文件传输的“粘滞”
坑点:虽然 sendfile 很快,但如果你传输一个 10GB 的文件,直接 sendfile 可能会导致该连接长时间占用网卡发送队列,阻塞其他小文件的发送。
架构师建议:不要一次性发送超大文件。在应用层做切片(Chunking)。
代码示例 5:分块发送的大文件处理
void send_large_file_chunked(int out_fd, int in_fd, size_t file_size) { off_t offset = 0; size_t chunk_size = 2 * 1024 * 1024; // 2MB 一块 while (offset < file_size) { // 每次只发 2MB,发完让出 CPU/网卡队列调度机会 size_t send_bytes = chunk_size; if (offset + send_bytes > file_size) { send_bytes = file_size - offset; } // sendfile 会自动更新 offset 吗?是的。 // 当传入 &offset 时,sendfile 执行完会自动将 offset 更新为读取后的新位置 // 所以下一次循环时,offset 已经是正确的值了 ssize_t sent = sendfile(out_fd, in_fd, &offset, send_bytes); if (sent <= 0) break; // 错误处理 // 可选:在这里加一点流控逻辑 // usleep(100); }}
运行结果说明:这种方式既享受了零拷贝的性能,又避免了“大象堵路”,保证了系统的响应性。
3.4 架构思考:RocketMQ 的选择
RocketMQ 选择了 mmap 而不是 sendfile,为什么?
因为 RocketMQ 不仅仅是把数据发出去,它还需要高频写入和随机读取。
- • 写入场景:RocketMQ 需要将接收到的消息持久化到磁盘(CommitLog)。
mmap 允许直接将文件映射到内存进行写入,配合 msync 或系统自动刷盘,性能极高。而 sendfile 是只读的,无法用于“收消息存盘”的场景。 - • 读取场景:虽然
sendfile 发送数据很快,但 RocketMQ 需要在发送前读取消息头判断状态,或者做一些过滤逻辑。mmap 提供了直接访问数据的能力,而 sendfile 是黑盒,数据进了内核你就摸不到了。
结论:如果你的业务需要修改/写入文件,或者在发送前需要读取文件内容做逻辑判断,选 mmap;如果只是单纯的搬运(如 Nginx 静态资源服务器),选 sendfile。
四、 邪修架构:内核态直接处理业务?
既然用户态和内核态切换这么慢,有没有更激进的玩法?
eBPF (Extended Berkeley Packet Filter) 和 DPDK。
- • DPDK:直接在用户态接管网卡,完全绕过内核协议栈。这是电信级网关的玩法,开发难度极大,但性能也是天花板。
- • eBPF:允许你在内核中运行沙盒代码。比如,你可以用 eBPF 在内核 Socket 层直接解析 HTTP 请求并根据规则丢弃或重定向,完全不需要把数据拷贝给用户进程。
代码示例 6:概念级 eBPF 挂载 (伪代码逻辑)
// 这是一个 eBPF 程序,运行在内核态// 它可以直接拦截 socket 数据包SEC("socket")int bpf_prog1(struct __sk_buff *skb) { // 直接读取数据包内容 // 如果是恶意流量,直接丢弃 (XDP_DROP) // 根本不需要 copy 到用户态让应用层去判断 return 0;}
运行结果说明:这是当前云原生安全(Cilium)和高性能网络(Katran)的最前沿方向。
五、 总结与 Takeaway
写了这么多,怎么把这些知识变现到你的项目中?
- 1. 别再无脑
read/write 了:如果你在做文件下载、视频流媒体、日志采集传输,请立刻检查你的代码。 - 2. 静态资源首选
sendfile:Nginx、Tomcat APR 模式默认开启是有原因的。 - 3. 需要改数据选
mmap:数据库、消息队列(RocketMQ)的存储引擎多依赖此特性。 - 4. 代理服务看
splice:做内网穿透、API 网关时,它能显著降低 CPU 负载。 - 5. 性能优化是做减法:减少拷贝、减少切换、减少内存占用。
最后送大家一句话:架构师的价值,不在于你会写多少复杂的代码,而在于你能在哪怕最简单的“文件读取”操作中,洞察到操作系统底层的代价,并做出最经济的选择。
我是 Howell,我们下期见。