在嵌入式与服务器领域,arm64架构凭借低功耗、高性能的优势,已成为Linux系统的主流承载架构之一。Linux 6.6内核作为近期稳定版内核,对arm64架构的内存管理、I/O交互进行了诸多优化,让CPU、内核与I/O设备的协同更高效、更稳定。本文将结合底层原理与Linux 6.6 arm64的实际实现,拆解三者之间的核心交互逻辑,帮大家理清从CPU指令执行到内核调度、再到I/O设备响应的完整链路。
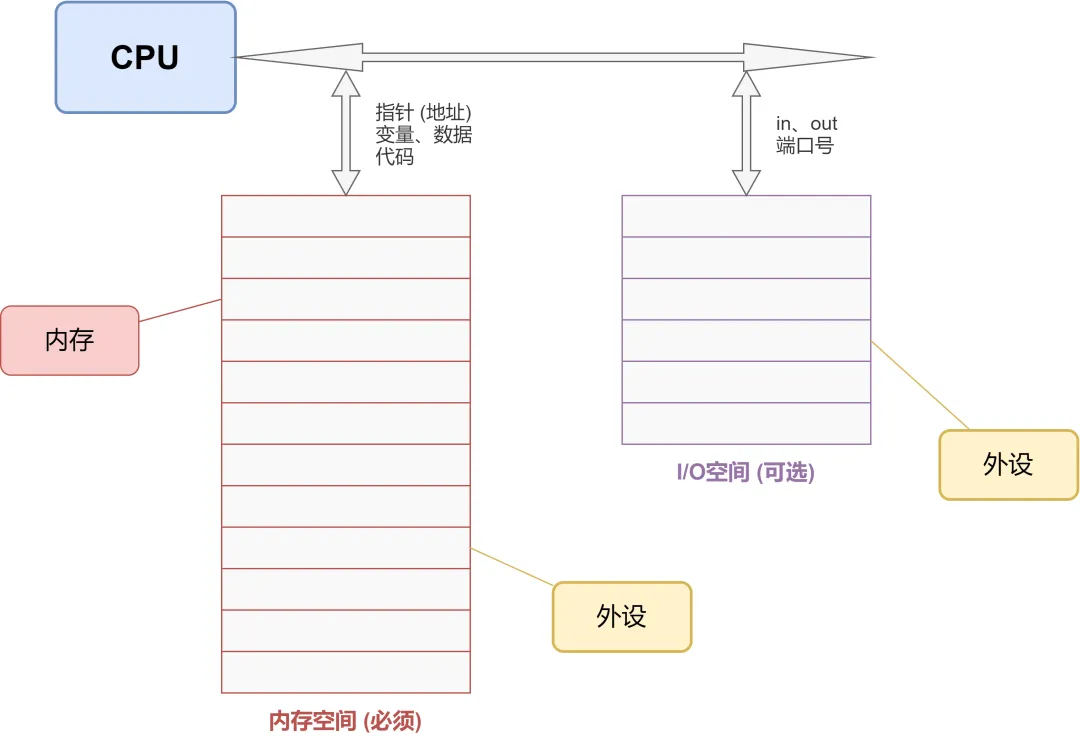
在此之前,我们先明确一个核心前提:与X86架构不同,arm64架构(包括多数ARM系列处理器)不存在独立的I/O空间,仅保留统一的内存空间——这是理解arm64下CPU、内核与I/O交互的关键,也是与X86架构最核心的差异点之一(X86有独立I/O空间,需通过in、out指令访问,而ARM、PowerPC等嵌入式微控制器仅用内存空间)。
一、基础认知:arm64架构下的内存空间与I/O访问
内存空间是所有处理器的必需组件,程序、变量、数据均存储其中,可通过地址、指针直接访问;而I/O空间是X86的可选组件,arm64架构则直接将I/O设备的寄存器映射到内存空间中,这种方式称为“内存映射I/O(MMIO)”。
在Linux 6.6 arm64系统中,CPU访问I/O设备的过程,本质上就是访问一段被映射的内存地址——内核会将I/O设备的寄存器地址分配到系统的物理内存地址空间中(对应arm64架构48位物理寻址空间的特定区域,如PCI I/O区域),CPU通过普通的内存访问指令(而非X86的in、out指令),就能实现对I/O设备的读写操作。
举个通俗的例子:假设我们有一个arm64处理器(如Cortex-A53),连接了一个UART串口设备。Linux 6.6内核会将该UART设备的控制寄存器、数据寄存器,映射到物理地址0x10000000-0x100000FF的区间。此时CPU要向串口发送数据,只需通过C语言指针操作这段内存即可,代码逻辑如下:
// 假设UART数据寄存器地址被映射到0x10000000unsignedchar *uart_data = (unsignedchar *)0x10000000;*uart_data = 0x55; // 向串口发送数据0x55,本质是访问映射后的内存地址
这种设计的优势的是简化了CPU的硬件设计,无需专门的I/O指令,同时让内核的I/O管理更统一——内核只需像管理普通内存一样管理I/O映射地址,就能实现对所有I/O设备的调度。而Linux 6.6内核对arm64的优化之一,就是优化了I/O映射的地址分配策略,减少了地址冲突,提升了I/O访问的稳定性。
补充一点:X86架构即便有I/O空间,也可将外设挂接在内存空间中,这与arm64的MMIO方式一致,可见“内存映射I/O”是更通用、更简洁的I/O访问方式,也是arm64架构的核心设计思路之一。
二、核心枢纽:Linux 6.6 arm64的MMU与内核内存管理
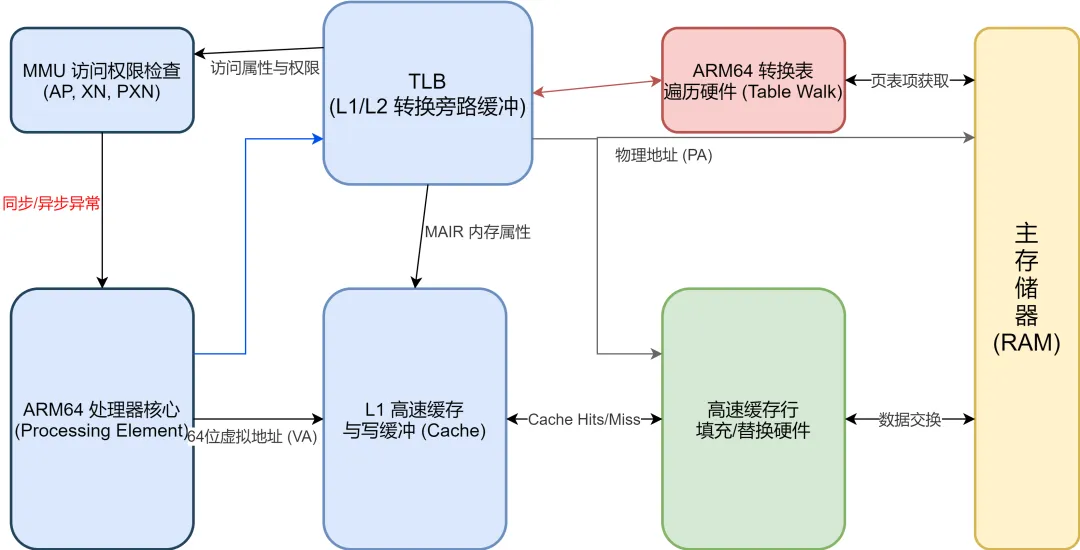
CPU与内存、I/O的交互,离不开内存管理单元(MMU)的支撑——MMU的核心功能是虚拟地址与物理地址的映射、内存访问权限保护、Cache缓存控制,而Linux 6.6内核针对arm64架构的MMU,做了进一步的优化,让内存访问更高效、更安全。
1. arm64 MMU的核心特性(结合Linux 6.6特性)
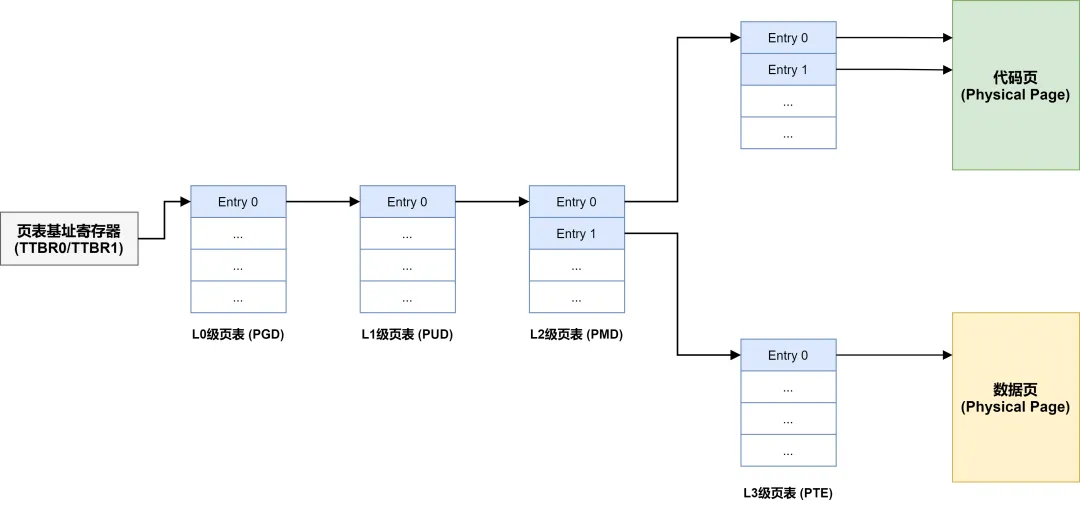
arm64架构的MMU支持4级页表(对应Linux内核的PGD、PUD、PMD、PTE),与Linux 6.6内核的页表管理机制完美适配——Linux从2.6.11开始引入4级页表以适配64位CPU,而arm64架构的MMU原生支持这种多级页表结构,无需内核额外适配。
此外,Linux 6.6内核针对arm64的MMU做了两个关键优化:
TLB(转换旁路缓存)优化:TLB是MMU的核心部件,用于缓存虚拟地址与物理地址的转换关系。Linux 6.6优化了TLB的刷新策略,减少了进程切换时TLB的刷新开销,尤其适合多进程并发的场景,提升了CPU的内存访问效率。
巨页(HugeTLB)支持增强:Linux内核会通过pmd_thp_or_huge()判断巨页情况,而Linux 6.6在arm64架构中完善了巨页的动态分配机制,支持2MB、1GB等多种巨页大小,减少了页表遍历(TTW)的次数,降低了内存访问延迟,尤其适合高性能计算、大数据等场景。
2. 内核的页表管理与地址映射(Linux 6.6 arm64实操解析)
Linux四级页表的查询过程,这段代码在Linux 6.6 arm64架构中依然适用,只是针对arm64的地址布局做了细微调整——arm64架构的虚拟地址空间分为两部分:用户空间(0x0000_0000_0000_0000到0x0000_ffff_ffff_ffff,共256TB)和内核空间(0xffff_0000_0000_0000到0xffff_ffff_ffff_ffff,共256TB),没有高端内存的概念,这让内核的地址映射更简洁。
通过pgd_offset()获取一级页表(PGD)入口:pgd_offset接收当前进程的内存描述符(current->mm)和虚拟地址(addr),定位到该虚拟地址对应的PGD表项——这一步是地址映射的起点,arm64架构中PGD对应页表的L0级转换表。
通过pud_offset()获取二级页表(PUD)入口:基于PGD表项,进一步定位到PUD表项(对应arm64的L1级转换表),判断PUD表项是否有效,无效则返回错误。
通过pmd_offset()获取三级页表(PMD)入口:基于PUD表项定位到PMD表项(对应arm64的L2级转换表),同时判断是否为巨页(通过pmd_thp_or_huge())——如果是巨页,无需继续查询PTE,直接通过PMD表项访问物理内存,减少访存次数。
通过pte_offset_map_lock()获取四级页表(PTE)入口:如果不是巨页,基于PMD表项定位到PTE表项(对应arm64的L3级转换表),锁定页表并判断PTE表项的有效性(是否存在、是否可写等),最终获取到虚拟地址对应的物理地址。
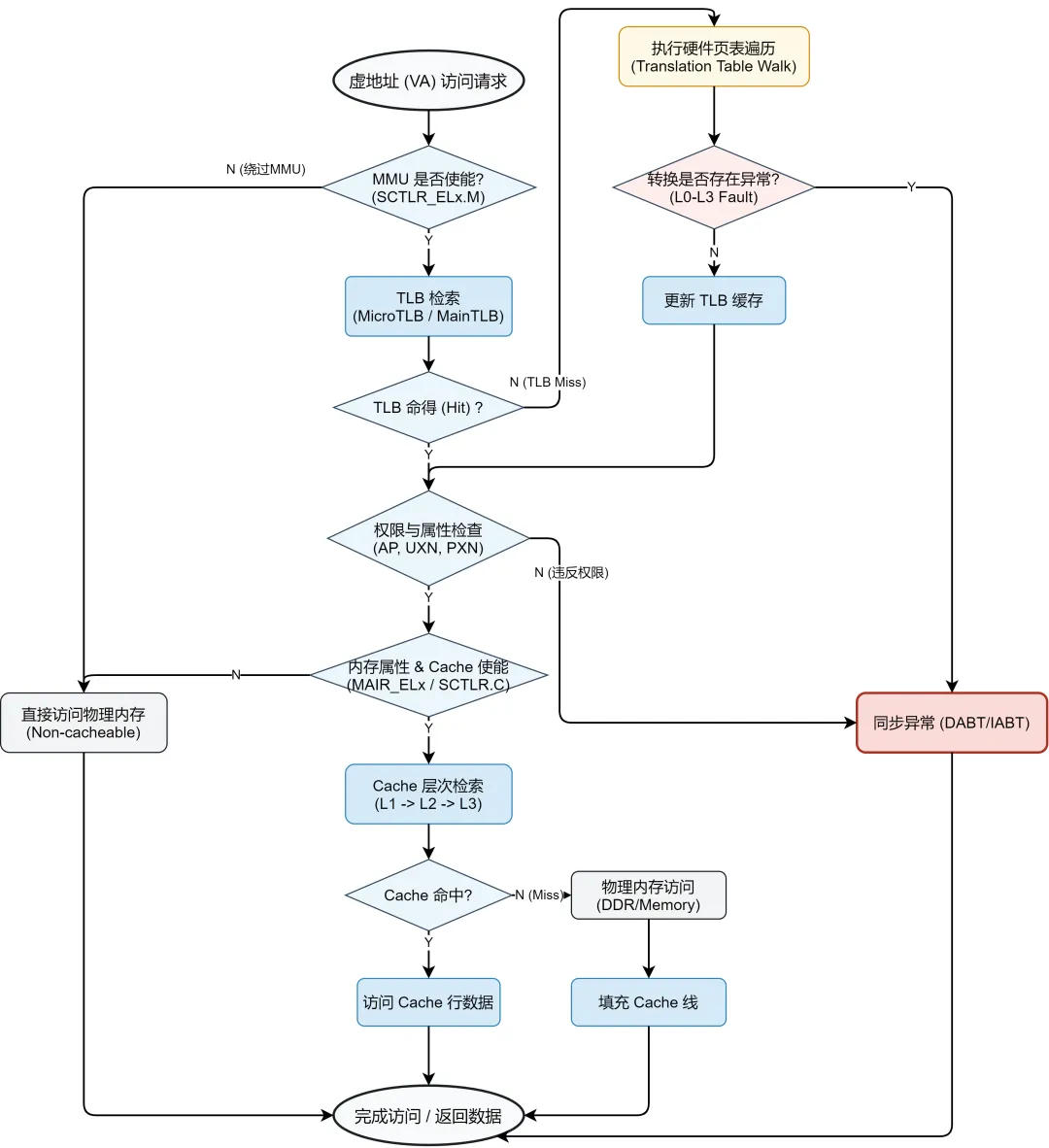
这个流程的核心意义在于:Linux 6.6内核通过四级页表,实现了虚拟地址到物理地址的精准映射,而MMU则负责硬件层面的地址转换和权限校验——CPU访问内存或I/O映射地址时,先通过MMU查询TLB,TLB未命中则查询四级页表获取物理地址,同时校验访问权限,确保内存安全。
值得注意的是,部分嵌入式处理器(如S3C44B0X)没有MMU,而Linux 6.6内核依然支持这类无MMU的arm64处理器,通过融合mClinux的特性,实现了对无MMU系统的兼容,扩大了arm64架构的应用场景(如低端嵌入式设备)。
三、协同工作:CPU、内核与I/O的完整交互链路(Linux 6.6 arm64场景)
结合前面的内容,我们以“CPU读取I/O设备数据”为例,拆解Linux 6.6 arm64架构下,CPU、内核与I/O的完整交互过程,让大家更直观地理解三者的协同逻辑:
I/O设备准备数据:假设一个GPIO设备采集到了外部传感器的数据,将数据写入自身的“数据寄存器”中——该寄存器已被Linux 6.6内核映射到特定的物理内存地址(如0x10001000)。
CPU发起访问请求:用户程序通过系统调用(如read()),请求读取该GPIO设备的数据,CPU接收到指令后,生成对应的虚拟地址(用户空间虚拟地址)。
内核进行地址转换与权限校验:Linux 6.6内核接收CPU的请求,通过前面提到的四级页表查询流程,将用户空间虚拟地址转换为物理地址(即0x10001000,I/O寄存器映射地址),同时通过MMU校验CPU的访问权限(确保CPU有权限访问该物理地址)。
MMU完成地址转换与缓存控制:MMU查询TLB,若存在该虚拟地址与物理地址的映射关系,直接返回物理地址;若不存在,执行查询四级页表,获取映射关系并缓存到TLB,同时根据TLB条目中的C位(高速缓存位)和B位(缓冲位),决定是否启用Cache缓存,提升访问效率。
CPU访问I/O设备并返回数据:CPU通过MMU获取到物理地址后,发送内存访问指令,读取该地址(I/O寄存器)中的数据,再通过内核将数据传递给用户程序,完成一次I/O交互。
整个过程中,CPU负责发起指令和执行操作,内核负责地址映射、权限管理和调度,MMU负责硬件层面的地址转换和缓存控制,I/O设备则通过内存映射地址与CPU、内核交互——Linux 6.6内核的优化,本质上就是简化这个链路的每一个环节,减少延迟、提升稳定性。
四、Linux 6.6 arm64的关键优化与实操注意事项
1. 核心优化点总结
I/O映射优化:优化了arm64架构下I/O设备的地址分配,避免地址冲突,同时提升了MMIO访问的吞吐量,适合高并发I/O场景。
MMU与页表优化:完善TLB刷新策略和巨页支持,减少页表遍历开销,提升内存访问效率;适配arm64的48位寻址空间,简化地址映射逻辑。
无MMU系统兼容:强化对无MMU arm64处理器的支持,扩大嵌入式应用场景,让Linux 6.6内核能适配更多低端嵌入式设备。
2. 实操注意事项
地址映射注意:arm64架构下,I/O设备的映射地址属于物理内存地址,用户程序无法直接访问,必须通过内核提供的接口(如mmap()系统调用),将物理地址映射到用户空间虚拟地址后,才能进行访问。
页表配置注意:在Linux 6.6 arm64系统中,若需启用巨页,需在启动参数中配置(如hugepages=1024),同时确保硬件支持对应的巨页大小,否则会降级为普通页。
权限控制注意:MMU的访问权限校验严格,若CPU试图访问无权限的内存地址(如内核空间地址),MMU会向CPU发送存储器异常,内核会根据异常类型处理(如杀死进程),因此在驱动开发中,需注意地址访问权限的配置。
五、总结
Linux 6.6 arm64架构下,CPU、内核与I/O的交互,核心是“统一内存空间”和“MMU地址映射”——与X86架构的I/O空间+内存空间双空间设计不同,arm64通过MMIO方式将I/O设备融入内存空间,简化了硬件设计和内核管理;而Linux 6.6内核的优化,进一步提升了三者协同的效率和稳定性,让arm64架构在嵌入式、服务器等领域的竞争力更强。