python代码 | 皮尔逊相关性气泡图+指标筛选
皮尔逊相关性气泡图+指标筛选
在做科研或者处理实验数据时,我们经常会收集到大量的指标变量。但是,变量并不是越多越好。如果多个变量之间表达的意思高度重合,它们就会在后续的计算中互相干扰,这种现象在统计学里叫做多重共线性。今天讲授的这套分析流程,就是为了完美解决这个难题。步骤1:皮尔逊相关性分析法
这个方法的原理是测量两个独立变量之间线性关系的紧密程度。它会给出一组介于-1到1之间的数值。数值越靠近1,说明两个变量越是同进同退;越靠近-1,说明它们呈现你高我低的相反趋势;如果是零,则说明两者各自为政,没有明显关联。步骤2:假设检验与显著性标记法
我们在实验中收集到的数据,往往只是现实世界的一小部分样本。有时候,两个变量算出来的相关得分很高,但那可能只是碰巧抽样抽出来的假象。假设检验就是通过计算一个概率值(也就是常说的 P 值),来判断这种关联是不是巧合。通常,当这个概率极小(比如小于百分之五)时,我们才认为这种关系是真实可信的,并用星号标注出来。这个方法为我们的研究提供了严谨的科学背书。它能过滤掉那些因为运气或随机误差产生的虚假结论,防止我们在错误的规律上浪费时间。步骤3. 逐步迭代的冗余特征淘汰法
在这个方法中,我们首先要设定一条红线(比如相关性得分达到0.7)。接着,我们统计每一个变量有多少个超过红线的同伴。重点来了:我们不能把超标的变量一次性全部扔掉,因为有些变量可能是被连累的。我们要做的是,每次只找出那个违规次数最多的头号嫌疑人,把它剔除出局。剔除之后,剩下的变量重新计算违规次数,再找下一个头号嫌疑人。一直这样重复,直到所有留下来的变量之间,关联得分都在红线以下。在统计学和机器学习中,如果把高度相似的变量一起放进模型,会造成模型运算混乱,这叫作多重共线性问题。这种淘汰法能够最精准地切除冗余信息,同时最大程度地保留有价值的、独立的特征,让最终的模型更加稳定和准确。步骤4:多维信息映射的可视化方法
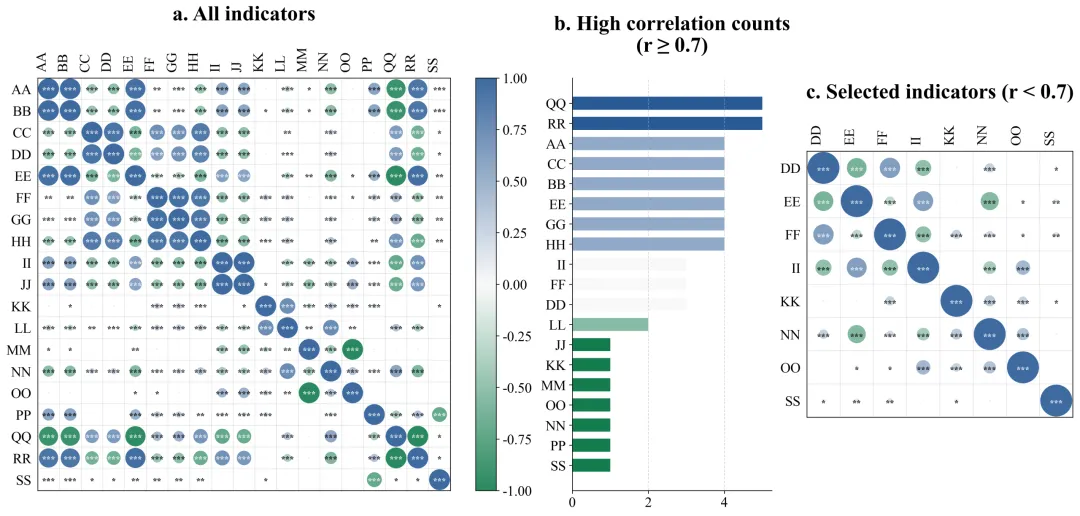
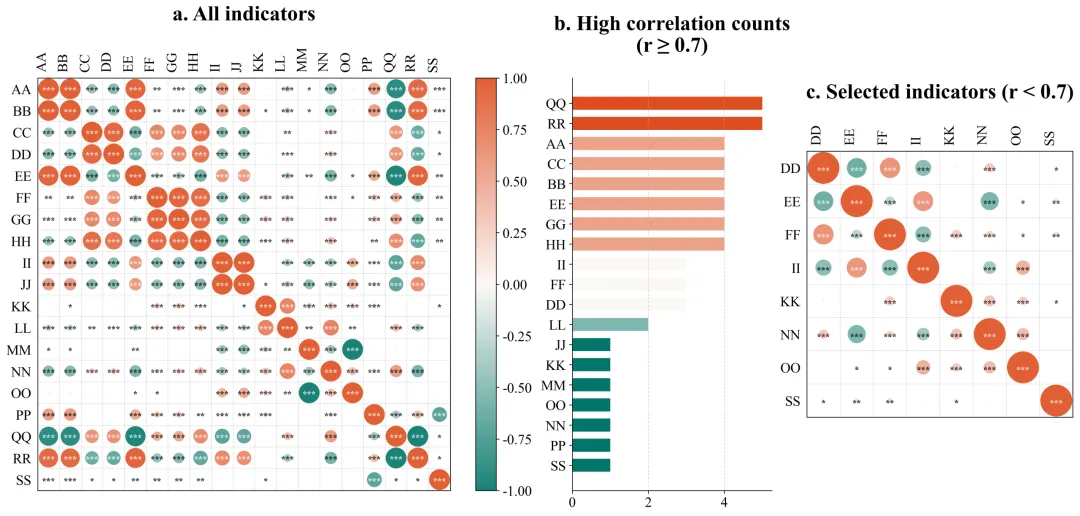
这是一种将抽象的数学数字,转化为人类大脑最容易接收的视觉信号的方法。我们不画枯燥的表格,而是利用图形的不同属性来传递信息。气泡的面积大小代表关联程度的强弱;颜色的不同代表关联是正向还是负向;旁边的条形统计图则直观展示了被淘汰变量的具体违规次数。这个方法解决了科研成果难以直观表达的痛点。把数据全貌、清洗过程和最终结果,浓缩在了一张逻辑连贯的复合图表里。它不仅让复杂的逻辑变得一目了然,还能极大提升论文的专业感,让审稿人能够轻松看懂你的整个思考和处理过程。输出结果的详细解读:
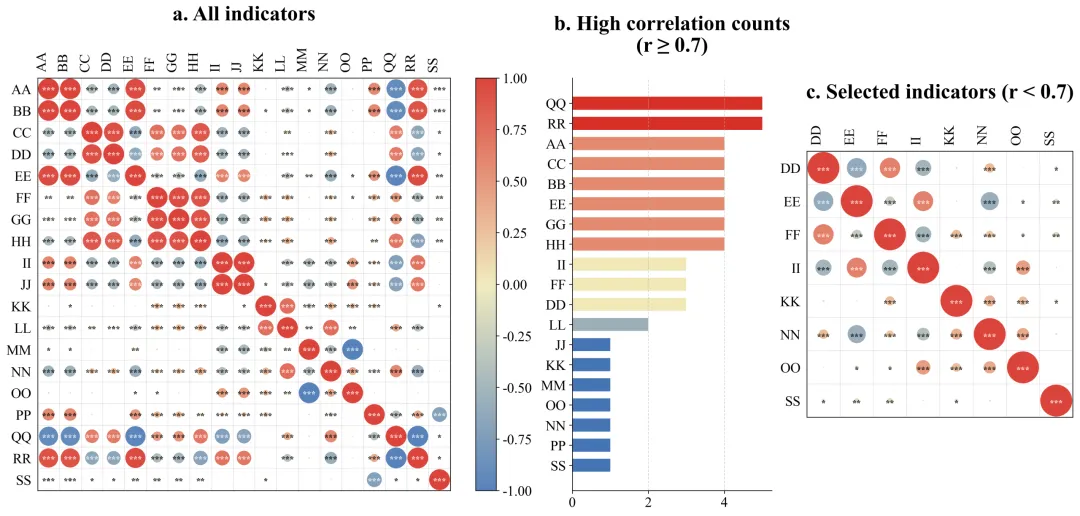
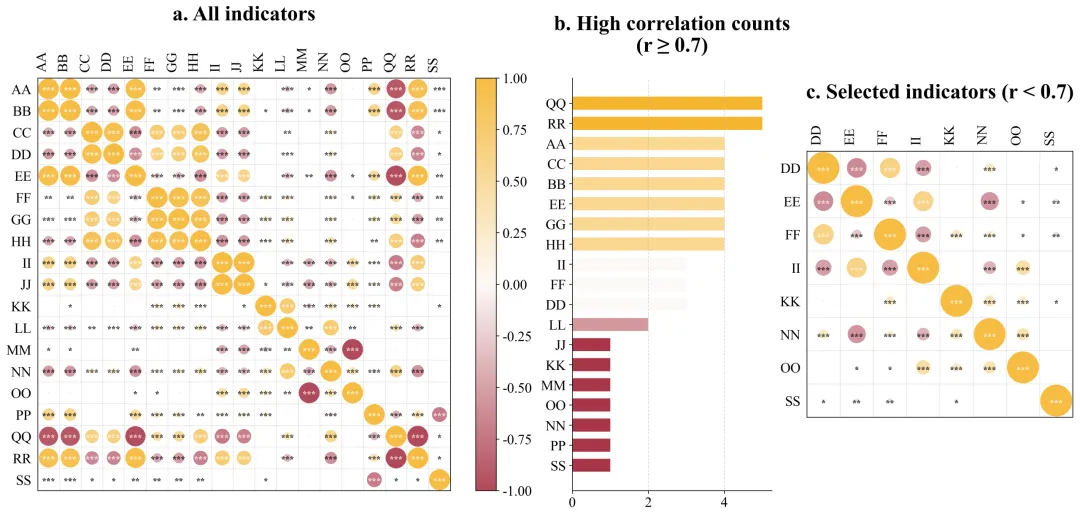
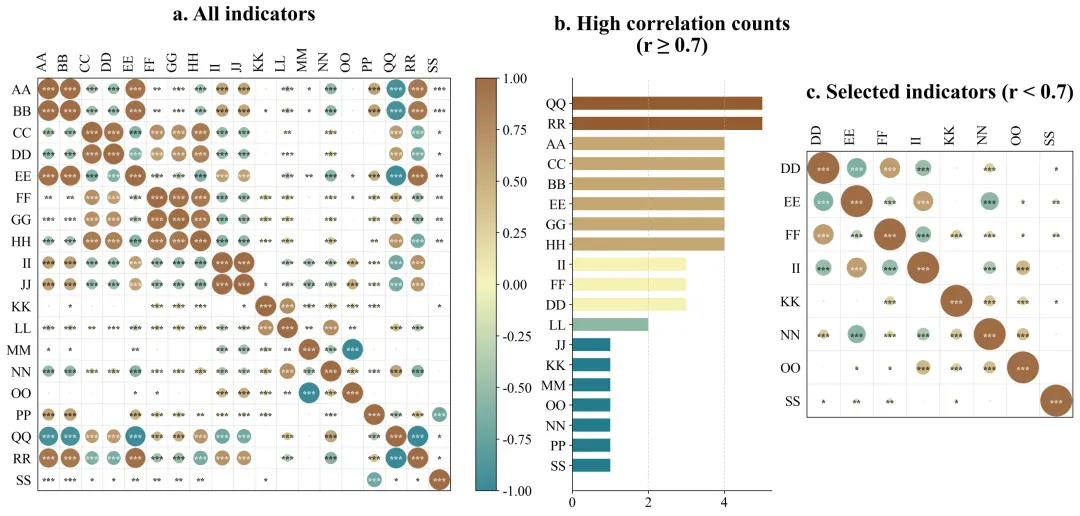
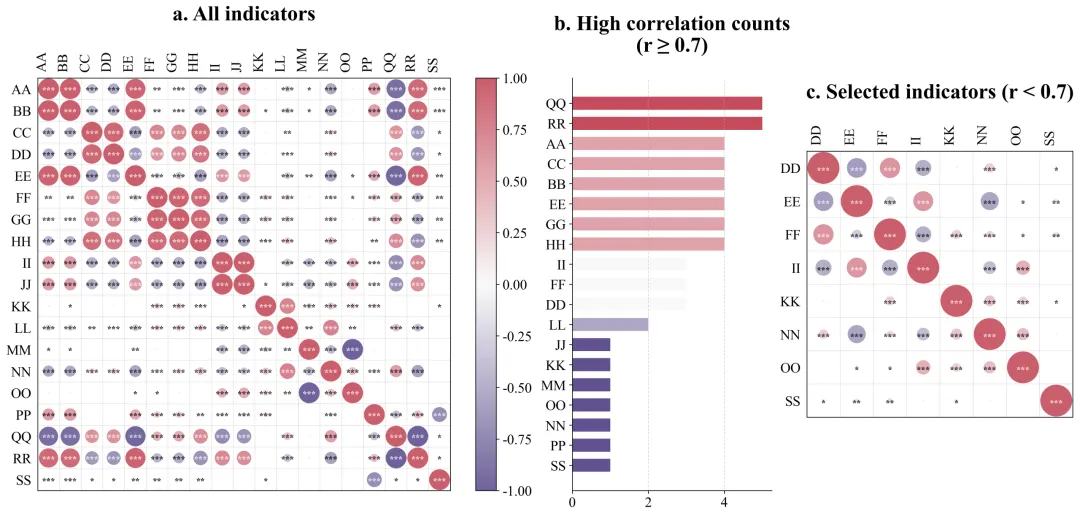
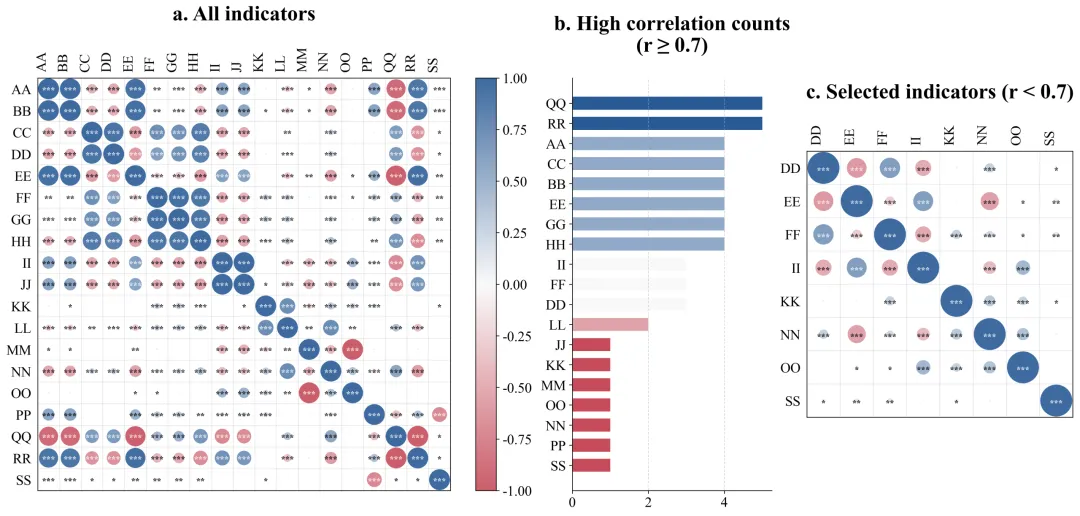
左图:原始指标关系全貌图
左图包含了你最初输入进去的所有原始变量。在这里,你会看到横轴和纵轴排列着所有的指标名称,中间布满了颜色各异、大小不一的圆圈。看面积:圆圈越大,说明对应横纵坐标的两个变量关系越铁。看颜色:比如偏红代表互相正向促进,偏蓝代表负向互相排斥,颜色越深代表这种趋势越强烈。看星号:如果圆圈里有星星,代表这种关系在统计学上是靠谱的,不是巧合。这张图解决了揭示初始状态的问题。它直观地向读者展示,我们的原始数据内部确实存在大量巨大的、深色的圆圈,证明数据里存在严重的相互重叠,必须进行清理。中图:高相关次数排行榜
中间是一幅横向的条形图。它的纵轴是那些惹了麻烦的变量名称,横轴是它们超标违规的具体次数。条形越长,说明这个变量与其它变量高度相似的次数越多,它是导致数据冗余的核心源头。要解读这张图,你只需要看谁排在最上面、谁的条形最长。那些排在前面的,就是刚才我们在淘汰法里被踢出去的变量。这张图解决了科研依据透明化的问题。它向审稿人提供了你删除某些数据的硬性量化证据。这就向外界证明,你不是凭主观感觉去随意删减实验数据,而是基于严谨的数学统计结果做出的客观决策。右图:优选指标关系成果图
右侧的图和左图看起来结构一样,但是你会发现里面的变量名称变少了。解读这张图的关键在于对比。你需要把它和左图放在一起看。你会惊讶地发现,右图里除了对角线上的圆圈之外,其他位置几乎再也看不到那种巨大且颜色极深的圆圈了。留下的圆圈大多比较小,颜色比较淡。这张图解决了验证清洗效果的问题。它完美地证实了你刚才所用的淘汰法是非常成功的。经过筛选后留下来的指标,既各自携带着独特的信息,互相之间又没有严重的重叠干扰。这样的干净数据,直接放进你的论文里,是非常具有说服力的。数据示范
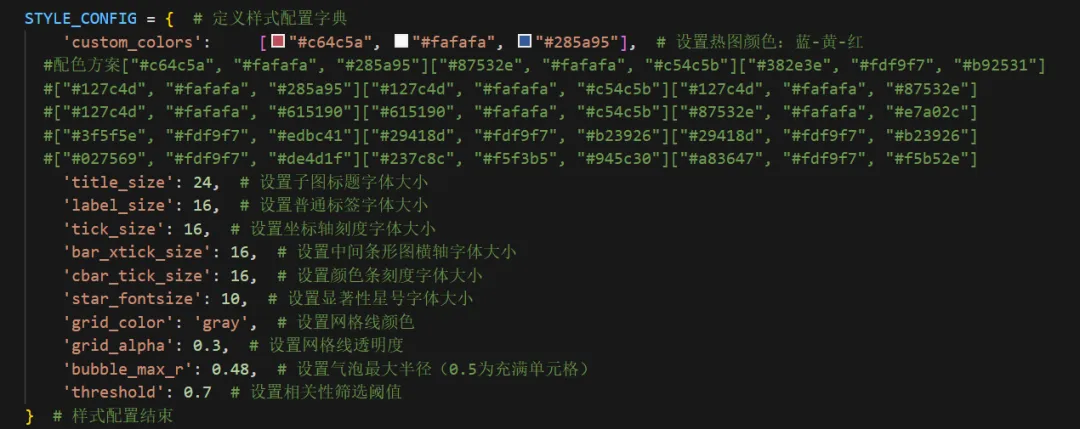
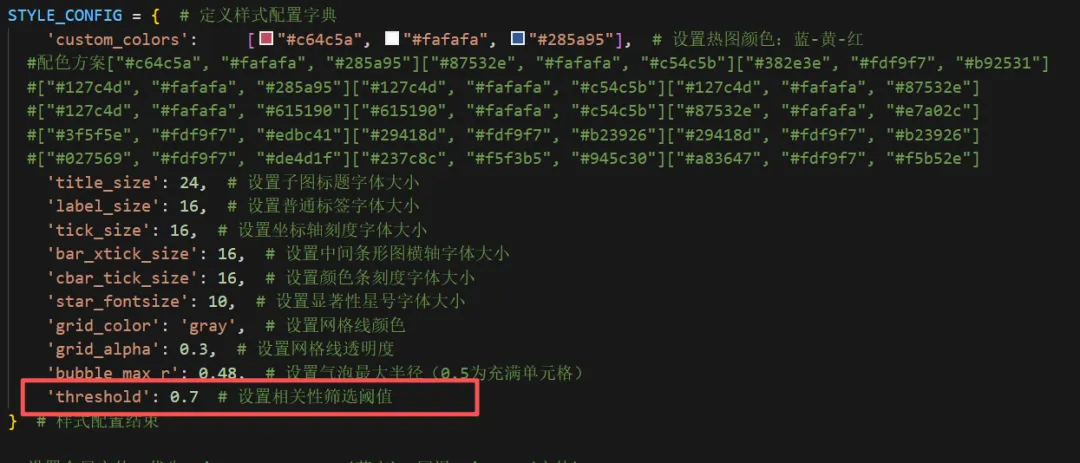
第三步:输入你喜欢的颜色代码以及调整输出图的字体等风格内容第四步:设置筛选阈值,我这里是相关性大于0.7的阈值



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
