- 核心操作可行广义最小二乘法(FGLS),利用组间与组内方差信息。
- 优点
4. 动态面板模型(GMM)
- 适用场景
- 类型差分GMM(Arellano-Bond)、系统GMM(Blundell-Bond)。
- 核心
四、Python实操(linearmodels库,推荐)
1. 环境配置
pip install linearmodels pandas numpy
2. 完整代码示例(企业投资面板数据)
步骤1:数据导入与预处理
import pandas as pdimport numpy as npfrom linearmodels.panel import PanelOLS, RandomEffects, comparefrom linearmodels.panel.panel_robust import PanelRobustOLS# 1. 导入数据(示例数据:企业投资、市值、资本存量)data = pd.read_csv("firm_investment.csv") # 列:firm_id, year, invest, value, capital# 2. 转换为面板数据结构(设置双索引:个体ID+时间)data = data.set_index(["firm_id", "year"])# 3. 描述性统计print(data.describe())# 4. 多重共线性检验(VIF)from statsmodels.stats.outliers_influence import variance_inflation_factorX = data[["value", "capital"]]X["const"] = 1vif = pd.DataFrame([variance_inflation_factor(X.values, i) for i inrange(X.shape[1])], index=X.columns, columns=["VIF"])print(vif) # VIF<10则无严重共线性
步骤2:模型拟合(混合OLS、FE、RE)
# 1. 混合OLS模型pooled_ols = PanelOLS.from_formula("invest ~ 1 + value + capital", # 1表示截距项 data=data, pool=True# 启用混合OLS)pooled_results = pooled_ols.fit(cov_type="clustered", cluster_entity=True) # 个体聚类标准误# 2. 单向固定效应模型(仅个体效应)fe_model = PanelOLS.from_formula("invest ~ 1 + value + capital + EntityEffects", # EntityEffects表示个体固定效应 data=data)fe_results = fe_model.fit(cov_type="clustered", cluster_entity=True)# 3. 双向固定效应模型(个体+时间效应)fe_time_model = PanelOLS.from_formula("invest ~ 1 + value + capital + EntityEffects + TimeEffects", data=data)fe_time_results = fe_time_model.fit(cov_type="clustered", cluster_entity=True, cluster_time=True)# 4. 随机效应模型re_model = RandomEffects.from_formula("invest ~ 1 + value + capital", data=data)re_results = re_model.fit()
步骤3:模型选择检验
# 1. F检验(混合OLS vs 单向FE)print("F检验(混合OLS vs 单向FE):")print(fe_model.fit().f_pooled) # p<0.05则选择FE# 2. Hausman检验(单向FE vs RE)hausman_test = compare({"FE": fe_results, "RE": re_results}, "hausman")print(hausman_test) # p<0.05则选择FE# 3. 模型结果对比comparison = compare({"Pooled OLS": pooled_results,"FE (Entity)": fe_results,"FE (Entity+Time)": fe_time_results,"RE": re_results}, "loglik")print(comparison)
步骤4:诊断检验与结果输出
# 1. 异方差+序列相关处理:Driscoll-Kraay标准误fe_dk_results = fe_time_model.fit(cov_type="kernel", kernel="bartlett", bandwidth=3)print("双向FE(Driscoll-Kraay标准误):")print(fe_dk_results.summary)# 2. 提取核心结果print("系数:", fe_dk_results.params)print("t统计量:", fe_dk_results.tstats)print("p值:", fe_dk_results.pvalues)print("R²:", fe_dk_results.rsquared)
五、其他软件速查
1. Stata(计量经济学主流)
* 1. 定义面板数据xtset firm_id year* 2. 混合OLSreg invest value capital, robust* 3. 单向固定效应xtreg invest value capital, fe vce(cluster firm_id)* 4. 双向固定效应xtreg invest value capital i.year, fe vce(cluster firm_id)* 5. 随机效应xtreg invest value capital, re vce(cluster firm_id)* 6. Hausman检验hausman fe_model re_model
2. R(统计学习主流)
library(plm)library(lmtest)# 1. 定义面板数据pdata <- pdata.frame(data, index =c("firm_id","year"))# 2. 混合OLSpooled <- plm(invest ~ value + capital, data = pdata, model ="pooling")# 3. 固定效应fe <- plm(invest ~ value + capital, data = pdata, model ="within")# 4. 随机效应re <- plm(invest ~ value + capital, data = pdata, model ="random")# 5. Hausman检验phtest(fe, re)
六、常见问题与陷阱
- 内生性问题自变量与误差项相关(如双向因果、测量误差)。解决方法:工具变量法(2SLS)、GMM、倾向得分匹配(PSM)。
- 时间不变变量固定效应模型会自动剔除这类变量,若需估计其影响,可改用随机效应或分层模型。
- 聚类标准误选择优先选择双向聚类(个体+时间),适用于N和T均较大的面板;若T较小,仅聚类个体即可。
- 动态面板偏误当T较小时,差分GMM存在小样本偏误,建议用系统GMM。
七、进阶方法简介
- 门槛面板模型研究自变量对因变量的影响存在门槛效应(如收入对消费的影响在不同收入阶段不同)。
- 空间面板模型考虑个体间的空间相关性(如省份经济增长的空间溢出效应)。
- 处理效应模型解决样本选择偏差(如仅研究上市公司的投资行为,存在自选择问题)。
- 分位数面板回归分析自变量对因变量不同分位数的影响(如研究市值对高/低投资水平企业的差异)。
总结
面板数据分析的核心是控制个体与时间异质性,模型选择的关键是F检验与Hausman检验。Python用linearmodels库可高效实现全流程分析,建议优先使用双向固定效应模型并搭配聚类标准误,以提高结果的稳健性。
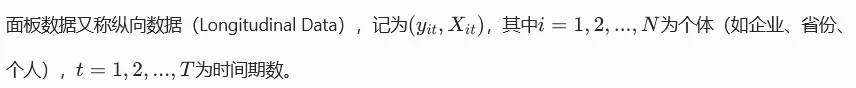
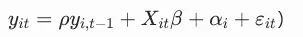 )
)
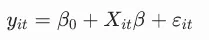
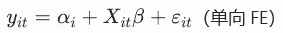
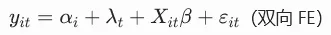

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
