欢迎来到 Python 学习计划的第 30 天!🎉昨天我们学习了 map() 函数,它用于转换数据。今天我们要学习函数式编程三剑客中的另一位——filter() 函数。如果说 map() 是“加工工厂”,那么 filter() 就是“筛子”。它用于根据条件筛选序列中的元素。一、什么是 filter() 函数?
1. 定义
filter() 函数用于过滤序列。它接收一个函数和一个可迭代对象,将函数依次作用于每个元素,只保留函数返回值为 True 的元素。
2. 基本语法
filter(function, iterable)
- function:判断函数,接收一个参数,返回
True 或 False(或真值/假值)。 - iterable:可迭代对象(如列表、元组)。
- 返回值:一个 迭代器(iterator)(Python 3 中)。
⚠️ 注意:与 map() 一样,filter() 返回的是迭代器,需要用 list() 转换才能看到完整结果。def is_even(x): return x % 2 == 0numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]result = filter(is_even, numbers)print(list(result)) # [2, 4, 6, 8, 10]
二、基础使用示例
1. 使用自定义函数
筛选出列表中的偶数。
def is_even(x): return x % 2 == 0numbers = [1, 2, 3, 4, 5, 6]evens = filter(is_even, numbers)print(list(evens)) # [2, 4, 6]
2. 使用 lambda 函数(最常见)
结合 lambda,代码更简洁。
numbers = [1, 2, 3, 4, 5, 6]# lambda 返回布尔值evens = filter(lambda x: x % 2 == 0, numbers)print(list(evens)) # [2, 4, 6]
3. 筛选字符串
筛选出长度大于 3 的字符串。
words = ['cat', 'dog', 'bird', 'fish', 'ox']long_words = filter(lambda s: len(s) > 3, words)print(list(long_words)) # ['bird', 'fish']
4.使用None作为函数
当function为None时,filter会过滤掉所有"假值"(False、0、空字符串、None等):
data = [0, 1, 2, "", "hello", None, False, True, [], [1, 2]]result = filter(None, data)print(list(result)) # [1, 2, 'hello', True, [1, 2]]
三、filter对象是迭代器
filter()返回的是迭代器,只能遍历一次:
numbers = [1, 2, 3, 4, 5]evens = filter(lambda x: x % 2 == 0, numbers)print(type(evens)) # <class 'filter'># 第一次遍历print(list(evens)) # [2, 4]# 第二次遍历(已耗尽)print(list(evens)) # []
四、转换为其他类型
numbers = [1, 2, 3, 4, 5, 6]evens = filter(lambda x: x % 2 == 0, numbers)# 转为列表result_list = list(evens)# 转为元组numbers = [1, 2, 3, 4, 5, 6]result_tuple = tuple(filter(lambda x: x % 2 == 0, numbers))# 转为集合result_set = set(filter(lambda x: x % 2 == 0, numbers))
五、实际应用示例
示例:筛选字符串
words = ["python", "java", "c", "javascript", "go", "rust"]# 筛选长度大于3的单词long_words = list(filter(lambda w: len(w) > 3, words))print(long_words) # ['python', 'java', 'javascript', 'rust']# 筛选以'p'开头的单词starts_with_p = list(filter(lambda w: w.startswith('p'), words))print(starts_with_p) # ['python']# 筛选包含'a'的单词contains_a = list(filter(lambda w: 'a' in w, words))print(contains_a) # ['java', 'javascript']
示例:筛选字典列表
users = [ {"name": "张三", "age": 25, "active": True}, {"name": "李四", "age": 30, "active": False}, {"name": "王五", "age": 28, "active": True}, {"name": "赵六", "age": 22, "active": False}]# 筛选活跃用户active_users = list(filter(lambda u: u["active"], users))print([u["name"] for u in active_users]) # ['张三', '王五']# 筛选年龄大于25的用户older_users = list(filter(lambda u: u["age"] > 25, users))print([u["name"] for u in older_users]) # ['李四', '王五']# 组合条件result = list(filter(lambda u: u["active"] and u["age"] < 30, users))print([u["name"] for u in result]) # ['张三', '王五']
示例:数据清洗
# 过滤空值data = ["apple", "", "banana", None, "cherry", ""]cleaned = list(filter(None, data))print(cleaned) # ['apple', 'banana', 'cherry']# 过滤特定值data = [1, 2, -1, 3, -1, 4, -1]without_invalid = list(filter(lambda x: x != -1, data))print(without_invalid) # [1, 2, 3, 4]
示例:数字筛选
numbers = list(range(1, 101))# 筛选3的倍数multiples_of_3 = list(filter(lambda x: x % 3 == 0, numbers))print(multiples_of_3[:10]) # [3, 6, 9, 12, 15, 18, 21, 24, 27, 30]# 筛选质数def is_prime(n): if n < 2: return False for i in range(2, int(n ** 0.5) + 1): if n % i == 0: return False return Trueprimes = list(filter(is_prime, range(2, 50)))print(primes) # [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
示例:文件过滤
files = [ "document.txt", "image.png", "script.py", "data.csv", "photo.jpg", "code.py"]# 筛选Python文件py_files = list(filter(lambda f: f.endswith('.py'), files))print(py_files) # ['script.py', 'code.py']# 筛选图片文件image_extensions = ('.png', '.jpg', '.gif')images = list(filter(lambda f: f.endswith(image_extensions), files))print(images) # ['image.png', 'photo.jpg']
filter() 与 map() 配合使用
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 先筛选偶数,再求平方evens = filter(lambda x: x % 2 == 0, numbers)squared = map(lambda x: x ** 2, evens)result = list(squared)print(result) # [4, 16, 36, 64, 100]
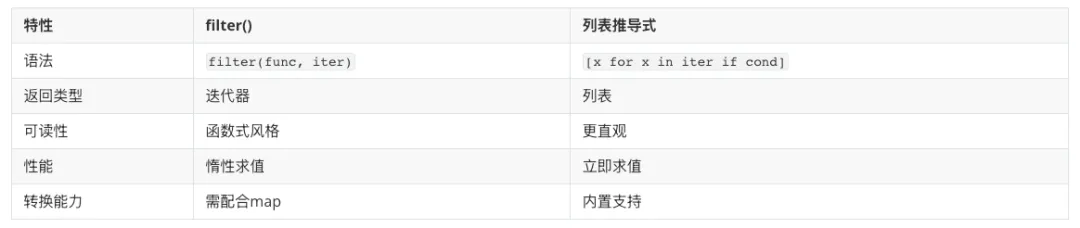
filter() 与列表推导式对比
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# filter方式result1 = list(filter(lambda x: x % 2 == 0, numbers))# 列表推导式result2 = [x for x in numbers if x % 2 == 0]print(result1) # [2, 4, 6, 8, 10]print(result2) # [2, 4, 6, 8, 10]
需要同时筛选和转换时
numbers = [1, 2, 3, 4, 5, 6]# 列表推导式更简洁result1 = [x ** 2 for x in numbers if x % 2 == 0]print(result1) # [4, 16, 36]# filter + mapresult2 = list(map(lambda x: x ** 2, filter(lambda x: x % 2 == 0, numbers)))print(result2) # [4, 16, 36]
itertools.filterfalse
from itertools import filterfalsenumbers = [1, 2, 3, 4, 5, 6]# filter:返回满足条件的evens = list(filter(lambda x: x % 2 == 0, numbers))print(evens) # [2, 4, 6]# filterfalse:返回不满足条件的odds = list(filterfalse(lambda x: x % 2 == 0, numbers))print(odds) # [1, 3, 5]
六、特性与陷阱
1. 惰性计算(Lazy Evaluation)
filter() 返回迭代器,只有在遍历时才计算。
# 不会立即过滤,不占用大量内存large_filter = filter(lambda x: x % 2 == 0, range(1000000))# 只取前 3 个结果for i, val in enumerate(large_filter): if i >= 3: break print(val) # 0, 2, 4
2. 只能遍历一次
迭代器一旦耗尽,就不能再次使用。
numbers = [1, 2, 3]result = filter(lambdax: x > 1, numbers)print(list(result)) # [2, 3]print(list(result)) # [] (❌ 第二次为空)
3. 函数返回值
判断函数必须返回布尔值或可转换为布尔值的对象。
# ❌ 错误:返回了数字而不是布尔值(虽然也能工作,但不规范)# filter(lambda x: x * 2, numbers) # ✅ 正确:返回布尔值filter(lambdax: x > 0, numbers)
七、最佳实践
✅ 推荐做法
- 配合内置方法:如
filter(str.isdigit, list),filter(None, list)。 - 大数据处理:利用其迭代器特性,节省内存。
- 简单筛选:如果逻辑简单,列表推导式优先。
❌ 避免做法
- 复杂 lambda:不要在
filter 里写复杂的 lambda 逻辑。 - 多次遍历:如果需要多次使用结果,请先转换为
list。 - 副作用操作:不要用
filter 执行打印等操作。
特性 | 说明 |
|---|
功能 | 根据条件筛选可迭代对象中的元素 |
语法 | filter(func, iterable)
|
返回值 | 迭代器(Python 3),需用 list() 查看 |
特殊用法 | filter(None, iterable) 过滤假值
|
对比 | 简单筛选推荐列表推导式,内置函数推荐 filter |
内存 | 惰性计算,适合大数据流 |