Linux 字符设备驱动从零入门:核心结构体与 VFS 协作流程详解
- 2026-06-27 21:05:25
本文作者:@xlp666hub(
juejin.cn/user/2965810860569131)来源:掘金
🧭 云栈导读|为什么运维也要懂底层驱动?
坦白讲,很多运维和 SRE 兄弟对内核驱动有一种天然的抵触感,总觉得那是底层 C 语言开发该干的活,跟自己没啥关系。
但说实话,线上机器 /dev 目录下突然冒出个奇怪节点,或者排查 fd 句柄泄漏查到头秃时,不懂点底层逻辑,排障真的只能靠猜。我们每天操作的串口设备、/dev/null、/dev/zero,背后全靠字符设备驱动在撑着。
今天这篇文章,我特意从 云栈社区( YunPan.Plus ) 挑出来的干货。原作者把 struct cdev、file_operations 这些看似枯燥的结构体,用面向对象思想和 VFS 协作流程串得明明白白。读完这篇你会发现,平时敲的那个简单的 open() 命令,在内核里其实跑了一场精密的接力赛。
一、初识字符设备:名字从哪里来?
1.1 字符设备名字的历史渊源
Linux 内核把设备驱动分为三大类:字符设备(character device)、块设备(block device)和网络设备(network device)。其中字符设备是最基础、最常见的一类。
“字符设备”这个名字,第一印象大概是:这种设备在接收和发送数据时以单个字符为单位。其实这个名字的背后,既有历史渊源,也藏着内核的设计哲学。
历史渊源:
字符设备最早可以追溯到 1970 年代的 Unix 系统。那时有一种常见的外部设备是电传打字机——键盘和打印机组合的终端设备。用户敲键盘时设备一次发送一个字符到计算机,计算机输出时也是一个字符一个字符打印出来。
这种设备天然就是逐字符处理的,没有随机访问的需求。Unix 设计中,这类设备统一称为 character devices(字符设备),以区别于磁带、磁盘这类每次读写固定大小的块的设备。
所以“字符”这个词,直接来源于早期字符终端的工作方式:按字符流传输数据。
设计理念:
Linux 继承了 Unix 的设备模型,老规矩:一切皆文件。但不同设备类型的访问方式有本质区别。
字符设备的核心理念是提供一个无结构的、连续的字节流接口,就像水管里流出的水,只管读写字节,不关心块或结构。而块设备有固定大小的块,支持随机访问,并且有内核缓冲。
在早期 ASCII 编码时代,一个字符就是一个字节,字符流也就等于字节流。即使后来出现了 Unicode、多字节编码,依然延续了字符设备的叫法。
现在,写一个控制 LED 或读取传感器数据的驱动,它也叫字符设备驱动,因为符合同样的抽象模型——用户空间通过 read、write 或 ioctl 操作一个流。
理解了这个名字的来龙去脉,再看代码时就会更有感觉。它承载着设备模型核心理念的历史沉淀。
1.2 如何在 Linux /dev 目录下识别字符设备?
Linux 将几乎所有设备都抽象为文件,这些文件通常位于 /dev 目录下,可以用 ls -lh 命令查看:
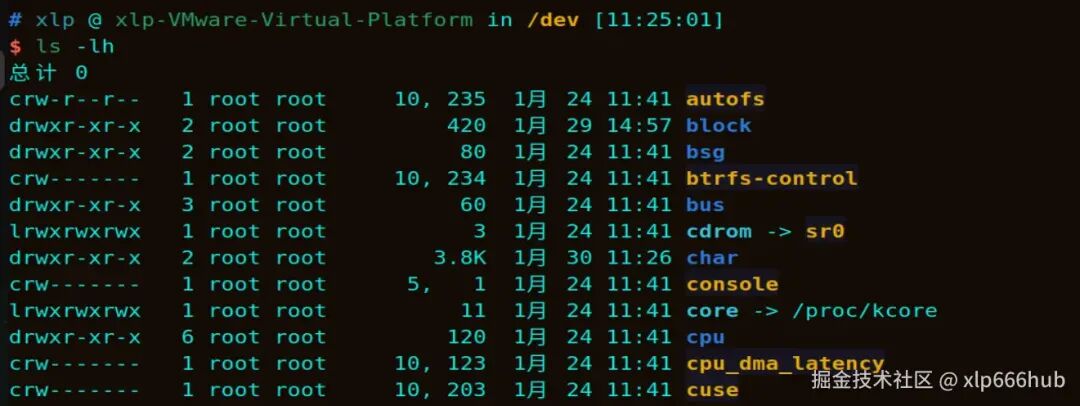
可以看到,权限列最前面字母为 c,就代表这是一个字符设备;若最前面字母为 b,则代表这是一个块设备。
此外,每个设备文件都有一个主设备号和一个次设备号:
主设备号标识驱动类型 次设备号标识具体的设备实例
上图中第一个字符设备 autofs,主设备号为 10,次设备号为 235。
下面简单介绍一些比较常见的字符设备:
/dev/ttyS*:串口设备,用于串口调试。/dev/tty*:终端设备,用于控制台的输入输出。/dev/null:空设备,读取会返回EOF,常用于将无用输出重定向到空设备。/dev/zero:读取该设备会返回全 0 字节。/dev/input/*:输入设备,比如鼠标、键盘、触摸屏等。
这些都是典型的字符设备,用户空间程序通过 open/read/write/close 操作它们,就像操作普通文件一样。
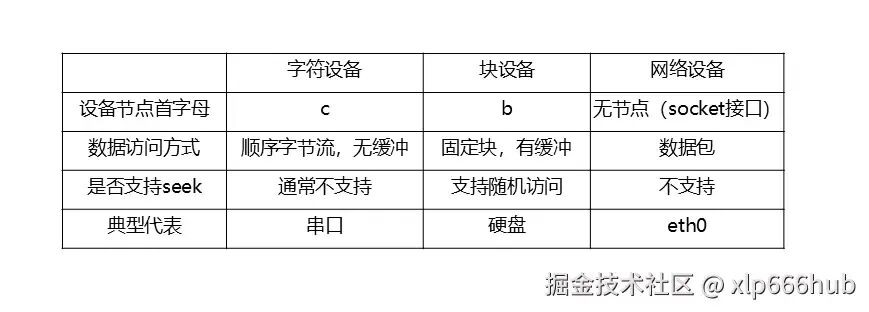
1.3 字符设备、块设备、网络设备三者对比
为了更好地区分字符设备与其他两种设备,咱们简单对比一下三者的特点:
二、字符设备驱动的抽象模型与核心结构体
在第一章中,我们看到了字符设备在用户空间的表现形式——位于 /dev 下的特殊文件。
用户程序通过熟悉的 open()、read()、write()、close() 系统调用操作它们。但这些操作最终是如何落实到真实硬件上的呢?这就涉及 Linux 内核对设备驱动的抽象模型。
2.1 用面向对象思想理解字符设备驱动框架
Linux 内核虽然是纯 C 语言写的,但驱动框架里全是面向对象编程(OOP)的影子。
我们可以把一个字符设备驱动想象成一个类:
设备本身就像一个类(比如 LED 驱动类、传感器驱动类) 每个打开的设备文件就像这个类的一个实例 用户空间的 read/write/ioctl调用就像调用这个实例的方法
内核通过结构体和函数指针,在 C 语言中巧妙实现了多态、封装和继承:
同一个 file_operations结构体可以被多个不同设备共享不同设备的实例可以通过 private_data携带自己专属的状态函数指针表使不同设备可以实现不同的 read/write行为
在 Linux 内核中,字符设备被抽象为具体的数据结构 struct cdev。当我们想添加一个字符设备时,就要将这个对象注册到内核中,通过创建一个设备节点绑定对象的 cdev。
当我们对这个文件进行读写操作时,就可以通过虚拟文件系统(VFS) 在内核中找到这个对象及其操作接口,从而控制实实在在的设备。这种设计让驱动框架高度模块化——内核只关心接口,不关心具体实现。
2.2 四大核心结构体详解
前面提到过,Linux 使用设备编号来表示设备:
主设备号用来区分设备类别 次设备号标识具体的设备
dev_t 是一个 32 位的数,用来表示设备编号,高 12 位表示主设备号,低 20 位表示次设备号。
所有设备都以文件的形式存放在 /dev 目录下,这些设备节点是连接内核与用户空间的枢纽。
2.2.1 struct cdev:字符设备的内核描述符
内核用 struct cdev 结构体来描述一个字符设备,该结构体在内核源码中定义如下:

各成员含义如下:
struct kobject kobj:内嵌的内核对象,通过它将设备统一加入到 Linux 设备驱动模型中管理。struct module *owner:驱动程序所在的内核模块对象的指针。const struct file_operations *ops:定义了文件操作,包含对文件进行打开、关闭、读写等操作的函数指针。struct list_head list:将系统中的字符设备集中起来的侵入式链表,内核源码中经常能看到它。dev_t dev:字符设备的设备号。unsigned int count:属于同一主设备号的次设备号的个数。
2.2.2 struct file_operations:驱动与用户空间的操作接口
这个结构体中的成员都是函数指针。
编写驱动程序时,需要编写对应的函数并让相应的函数指针指向它。这样一来,用户空间执行某个操作时,控制权就会通过 file_operations 结构体交到对应的执行函数手中。
该结构体在 Linux 内核源码中的定义如下(行号 1837 起):
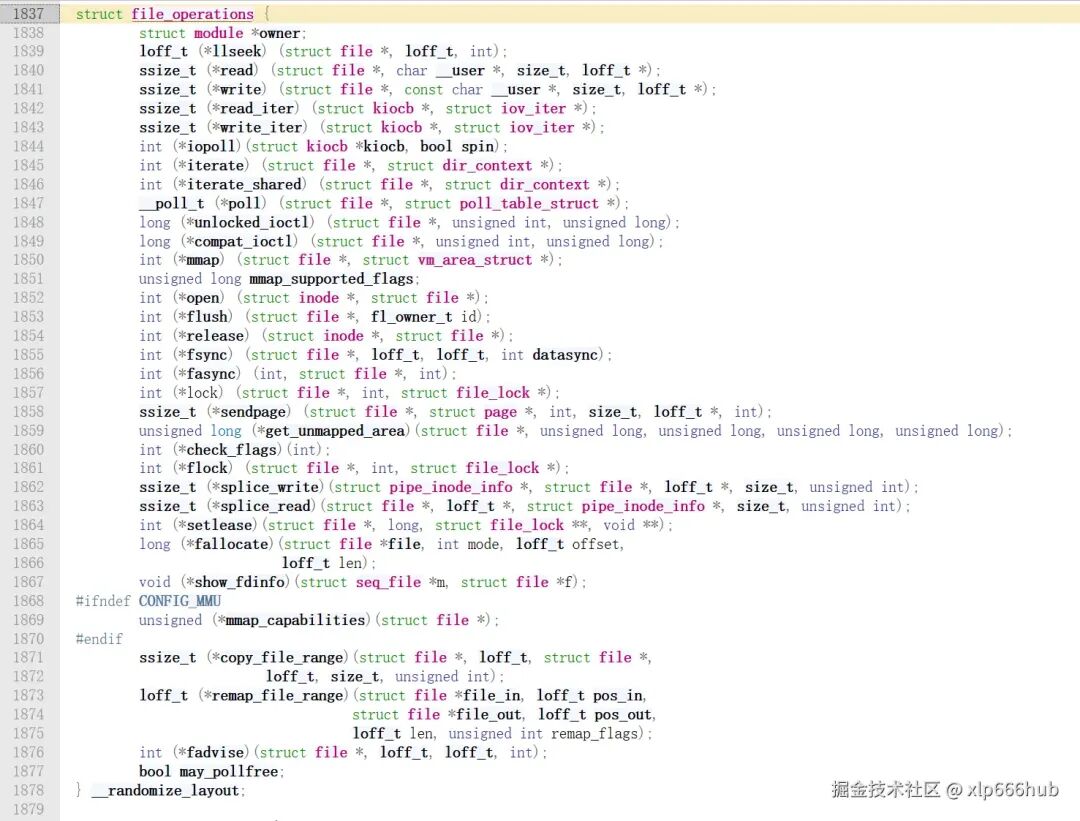
它的成员非常多,但实际上我们只会用到其中的一小部分,其他未用到的函数指针置为 NULL。最常用的几个:
struct module *owner:一般填THIS_MODULE,用来防止模块被卸载。llseek:用于修改当前文件的读写位置,返回值为偏移后的位置。read:用于读取设备中的数据。第二个参数是char __user *类型的缓冲区,__user修饰表明该变量所在的地址空间属于用户空间,内核模块不能直接使用该数据,需要使用copy_to_user函数来进行操作。write:用于向设备写入数据。访问__user修饰的数据缓冲区时,需要先使用copy_from_user函数将数据从用户空间拷贝到内核空间的缓冲区。open:设备驱动第一个被执行的函数,一般在这个函数中初始化硬件。release:在file结构体被释放时调用,对应用户态的close()。
2.2.3 struct file:每次 open() 的独立实例
内核中使用 struct file 结构体来表示每个打开的文件。
也就是说每打开一个文件,内核都会创建一个 struct file 结构体,并将对该文件的操作函数传递给该结构体的成员变量 f_op。当文件所有实例被关闭后,内核才会释放这个结构体。
该结构体在内核源码中的定义如下(行号 916 起):
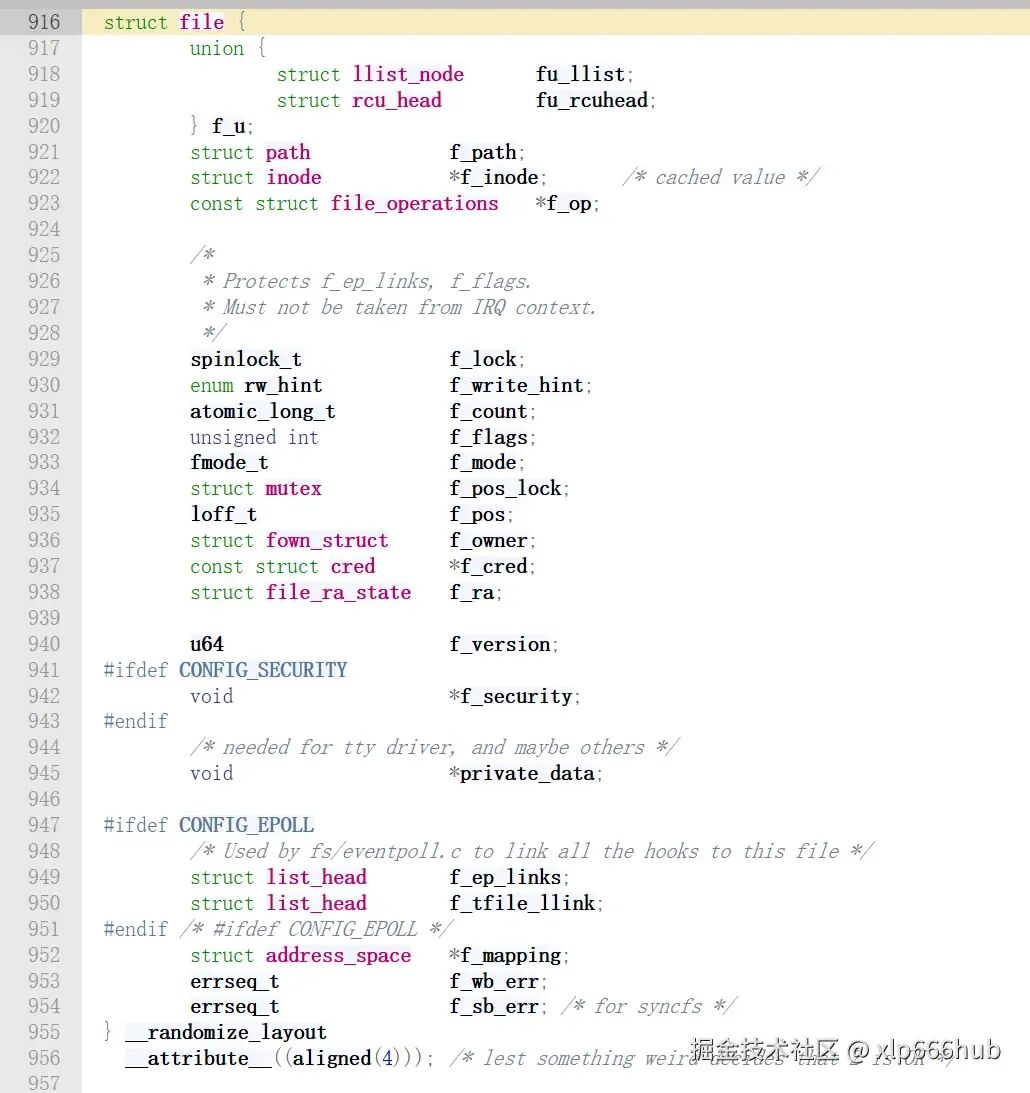
这个结构体成员也很多,但我们只需要重点关注两个:
f_op:用来存放文件操作相关函数指针。private_data:该指针变量只用于设备驱动程序中,内核并不会对该成员进行操作。通常用于指向描述设备的结构体——比如在open()中分配一个结构体保存设备状态(缓冲区、锁等),在release()中释放。
2.2.4 struct inode:文件在磁盘上的唯一实体
inode 结构体在内核内部表示一个文件,是 Linux 管理文件系统的最基本单位。
这两个东西初学者特别容易搞混。咱们直接对比看:
struct file | open() 创建,随 close() 释放 | |
struct inode |
同一个文件被打开多少次,就有多少个 struct file,但它们的 f_inode 成员指向的是同一个struct inode 结构体。
inode 结构体包含文件的访问权限、所有者、大小、创建时间、修改时间、访问时间等基本信息。
2.3 VFS 协作流程全解析:一次 open() 背后发生了什么?
这几个结构体怎么联动?全靠 VFS(虚拟文件系统)在中间牵线搭桥。VFS 把所有的文件统一抽象,使得用户层可以用最平常的 read 和 write 来操作设备文件。
下面以一个简单的字符设备驱动 my_chrdev 为例,完整走一遍从加载到卸载的生命周期:
① insmod 加载驱动模块
在命令行使用 insmod 加载内核模块时,发生了以下一系列操作:
使用 alloc_chrdev_region分配设备号使用 cdev_init初始化cdev使用 cdev_add将cdev注册到内核,在内核内部建立dev_t→struct cdev的映射使用 class_create和device_create在/dev目录下自动创建设备节点
到这一步,/dev 目录下就已经出现了 my_chrdev。
② 用户空间调用 open():CPU 如何陷入内核态?
用户空间调用 open 打开设备文件时,由于发生了系统调用,CPU 会从用户态陷入内核态,经过以下步骤:
VFS 层根据文件路径找到对应的 struct inode从 inode中取出设备号dev_t用 dev_t查找对应的struct cdev内核为这次打开分配一个 struct file结构体通过 struct file的f_op成员得到open操作的函数指针调用驱动程序中实现的初始化函数 CPU 切回用户态,返回文件描述符 fd
避坑细节:
open时创建struct file后,后续的read/write/close会直接从文件描述符表找到已经缓存的struct file,而不需要每次都重新查找inode。这个细节在分析高并发 I/O 性能问题时非常关键。
③ read / write / ioctl 操作流程
拿到文件描述符 fd 后,就可以对文件进行读写操作:
CPU 陷入内核态 经过 VFS 层找到 struct inode,进而找到struct file通过 f_op成员得到read或write操作对应的函数指针执行驱动程序中编写的函数,实现对硬件或设备私有数据的操作 CPU 切回用户态
④ close() 与 struct file 的释放
用户程序执行 close 时:
CPU 陷入内核态 通过 VFS 找到 struct inode,然后找到struct file中f_op结构体里的release指针执行驱动程序中编写的释放函数 对应的 struct file结构体被释放
⑤ rmmod 卸载驱动模块:资源回收
执行 rmmod 时,需要释放加载时申请的设备号、注销 cdev 等资源。到这里才算真正结束整个生命周期。
🔖 云栈点评|运维视角的踩坑启示
说实话,看完这篇底层逻辑,再回头看咱们平时排查的那些“疑难杂症”,很多都能对上号了。
比如 struct file 和 struct inode 的区别,简直是排查文件句柄耗尽(Too many open files 报错)的理论基础——fd 泄漏往往是因为进程里的 struct file 没释放,而磁盘上的 inode 其实好好的,这也是为什么有时候你删了日志文件但磁盘空间依然不释放的原因。
另外,VFS 里的缓存机制也挺有意思。open 之后直接走描述符表找缓存,不再查 inode,这设计确实能扛高并发。
最后留个坑: 既然 open 之后内核会缓存 struct file,那如果在这个期间,底层真实的硬件设备突然被拔掉了(比如 USB 串口线被物理扯断),用户态继续调 write 会发生什么?内核是怎么防止系统直接崩溃的?
欢迎在评论区聊聊你的踩坑经历或者看法!想深入研究运维与系统底层技术的兄弟,也可以来 云栈社区 - 运维/DevOps/SRE 板块 ( YunPan.Plus ) 找找灵感。
标签:#云栈社区 #云栈运维云原生 #Linux内核 #字符设备驱动 #VFS虚拟文件系统 #内核模块 #嵌入式Linux #运维排障
原文URL https://yunpan.plus/t/17100-1-1
👇 👇 👇 阅读原文访问云栈 ( YunPan.Plus )
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python三大Web框架之Django,从零开始学
- Python会议记录整理工具(Python Qt5 + 讯飞API)
- Python 必知必会:7 个我后悔忽略太久的 Python 特性!
- Python怎么学?熬夜整理 9 个核心编程概念
- Linux 命令行厉害,其实 Windows 的也很强
- Python联动TRNSYS——实现不同温度下的风机风速调控
- Linux 系统好好玩,但更应该好好用!
- Python 基础语法与基础数据类型
- 187-PHP公司收入支出记账系统 财务记账管理系统 员工记账系统源码开源
- 苏州Python培训:编程界“万金油”,零基础入门的首选编程语言
