Arthas 是 alibaba/arthas 开源的 Java 诊断工具。它能在不重启应用的前提下,动态查看线程/CPU、反编译类、追踪方法耗时、观察入参返回值、执行 OGNL、查看类加载器、线上取证定位问题——几乎是 Java 线上排障的“瑞士军刀”。
地址:https://github.com/alibaba/arthas
但现实也很直白:Arthas 很强,门槛也很高。
你得知道该用哪个命令(thread/dashboard/trace/watch/tt/vmtool/ognl/jad…);
你得知道参数怎么写、OGNL 怎么拼、如何限量,避免线上刷屏或增加开销;
你还得会“排障路径”:先拿证据,再收敛,再验证——而不是一通乱跑;
我们做的 Arthas Agent,就是把这件事反过来:让你用自然语言表达意图,让 Agent 负责把意图翻译成安全、可控、循证的 Arthas 操作,并把结果组织成一份“像 SRE 写的诊断报告”。
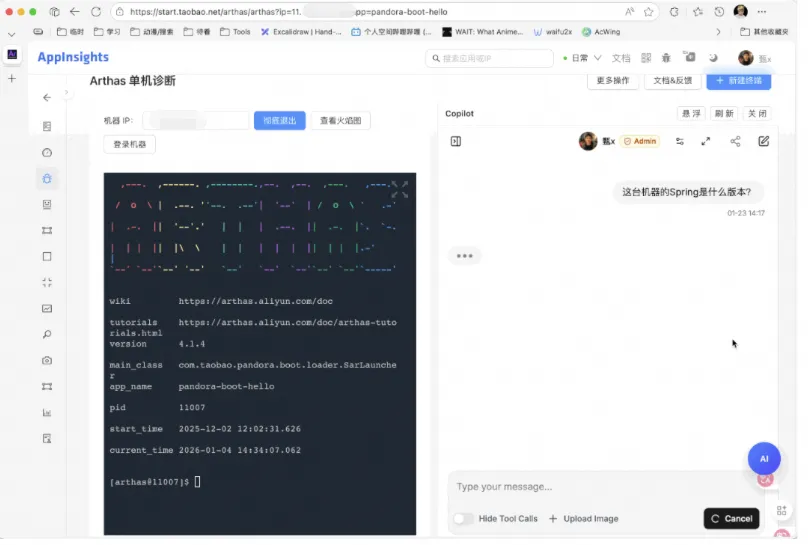
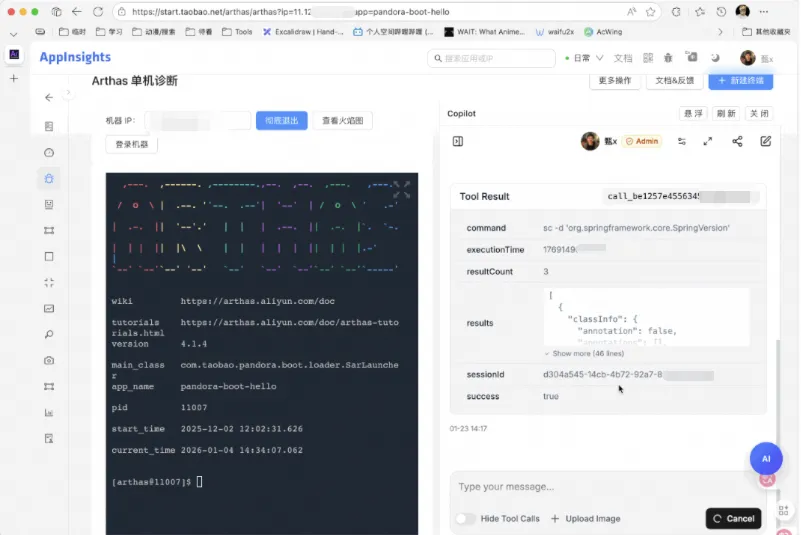
一个例子 - 直接询问正在运行的Spring的版本号:
整个过程不到30秒。
1. 没有 AI 的 Arthas:
你需要记住“命令”,而不是“问题”
传统方式里,你的大脑会被迫切换成“命令思维”:
“CPU 高”要先 dashboard 还是 thread -n?
“启动卡住”要看 main 线程,还是先扫 Spring Context?
“我只想看某种参数类型的调用”——watch 条件怎么写?
“我想拿 traceId 去查日志”——应该 watch 哪个点、怎么限量?
这些问题不难,但它们很耗时,而且常常发生在你最紧张的线上时刻。
更要命的是:真正耗时的不是“敲命令”,而是这些经验成本:
于是排障变成了同时需要“会命令的人”,和“理解问题的人”。缺少一项都无法排查。
2. 有了 Arthas Agent:
你只需要说“现象/目标”,剩下交给它
Arthas Agent 的核心不是“把 Arthas 包装成 ChatBot”,而是把线上诊断变成一种工程化的、可复用的能力:
最终体验是:你用一句话描述问题,它按步骤推进,并且每一步都会告诉你:
为什么要跑这条命令
期待看到什么
如果结果 A/B/C,下一步分别怎么走
一个例子 -- 应用启动不成功怎么办?
2.1 “AI 的方便”到底方便在哪:把长流程变成一句话
我们最想强调的,不是“AI 会背命令”,而是它能把下面这种长流程自动跑通:
你只需要说“现象/目标”,它负责把“专家脑内流程”显式化,并且每一步都把为什么要这么做讲清楚。
下面的例子来自我们在日常环境下的历史记录(已隐藏工具调用),重点看“诊断路径”和“证据收敛”。
3.1 一句话:诊断“应用启动卡住/无法正常启动”
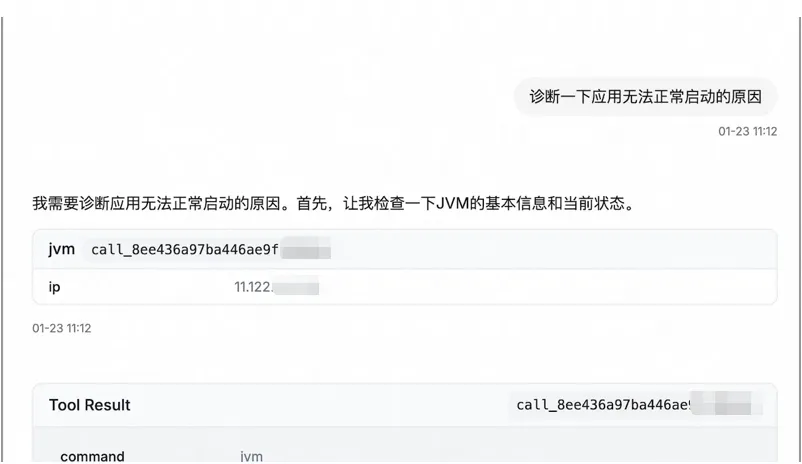
你说:诊断一下应用无法正常启动的原因。
3.1.1 没有 AI 时,资深同学怎么跑这条长流程
作为有经验的人,通常不会直接上来就 trace 或 watch,因为那样要么太宽、要么风险不可控。一个更“稳”的套路是:
这条链路“每一步都不难”,难的是:你要在压力下把下一步想清楚,还要保证每一步都可控。
3.1.2 来看看 AI 能不能做到:它是如何自动跑通并写出报告的
Agent 的推进路径(摘要):
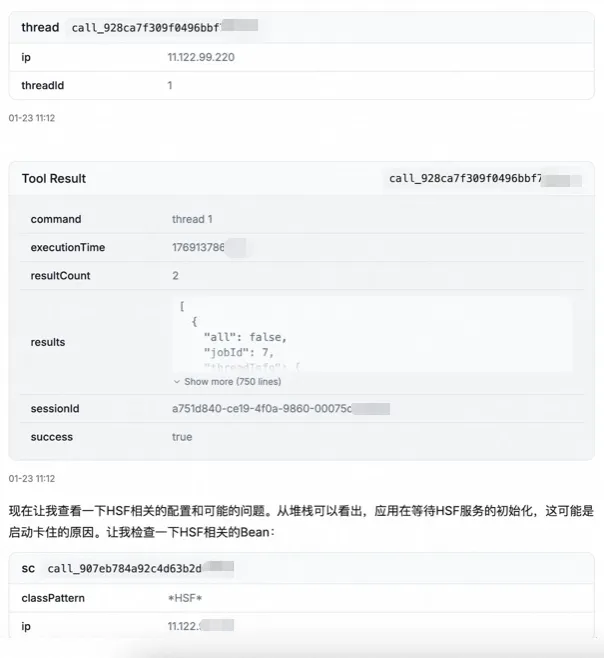
先拿 JVM 基本面(JVM/线程/GC 概况、dashboard);
再检查是否存在死锁/异常阻塞;
锚定 main 线程堆栈,发现卡在某个服务依赖初始化的等待点;
进一步定位到某业务类的静态初始化块:启动期创建 Spring Context 并触发远程依赖初始化;
给出“根因 + 证据 + 解决建议”:例如把启动期强依赖改成懒加载/异步,或缩短超时、检查注册中心/网络等;
为什么这类问题适合 Agent:
启动卡住往往是“线程堆栈 + 配置 + 初始化时序”的组合题。Agent 的价值在于能把“你脑中隐含的排障套路”显式化,并用最短路径把证据补齐。
你说:现在可以获取 jvm 信息不
Agent 输出(摘要化展示):
运行时环境:JDK 版本、启动时间、CPU 核数与负载;
内存:-Xms/-Xmx、堆/非堆使用、Metaspace 指标;
GC:G1GC 的 Young/Concurrent/Old 次数与耗时、GC 日志路径;
线程:线程数、守护线程、死锁检查结论;
没有 AI 时你可能也能跑出 jvm,但“读懂它、总结成可行动结论”往往要再花 10 分钟。Agent 把这 10 分钟省掉,并告诉你下一步应该把火力用在哪个方向。
3.3 一句话:在线读取 Spring 配置 server.port
(不改代码、不重启)
你说:获取 spring 配置 server.port 值
3.3.1 没有 AI 时,你很容易绕路
这件事看起来简单,但经常会踩坑:
你去翻配置文件:application.yml/application.properties,但线上可能来自配置中心/环境变量/启动参数覆盖;
你去看启动参数:-Dserver.port=...,但容器/启动脚本可能又做了二次注入;
你去看监听端口:netstat/ss,但应用可能有多个 connector,或者端口被 sidecar/代理转发;
换句话说:你想要的不是“文件里写了什么”,而是运行时 Spring Environment 里最终生效的值。
3.3.2 来看看 AI 能不能做到:Skill-first 的标准剧本
在真实历史记录里,Agent 的推进是:
识别这是 Spring 上下文配置排查;
匹配到内置 Skill(排障剧本),并先读取 skill 文档再行动(保证安全与正确性);
使用 vmtool 获取 ApplicationContext,调用 getEnvironment().getProperty("server.port") 拿到最终生效值;
解释“这个值可能来自哪些配置源”;如果你要追溯来源,它会给出下一步(查来源)的命令建议;
3.4 一句话:
getstatic 读取“静态字段/嵌套字段”,并做对比分析
你说:getstatic com.example.ConfigRepo configuration 'defaultRatio'(示例)
Agent 的处理要点:
这类需求在排查“开关/灰度/采样比例/动态配置”时非常常见:你只要说出类与字段,Agent 帮你把结果读出来并解释它意味着什么。
3.5 一句话:watch 只观察“特定类型/特定场景”的调用(OGNL 条件过滤)
你说:watch 方法怎么限制只针对特定类型使用?
Agent 给出:
示例:
# 只看第一个参数是某个类型的调用watch com.example.Service doSomething '{params, returnObj}' -c 'params[0].class.name == "com.example.User"' -n 5# 只看参数实现某接口watch com.example.Handler handle '{params}' -c 'params[0] instanceof @com.example.MyInterface@class' -n 5
你不再需要记住 OGNL 语法细节,告诉它你想“过滤什么”,它给你一条能直接复制执行的命令。
3.6 长流程示例:CPU 飙高排查
(从“哪个线程”到“哪段代码”)
我们构造了一个由于正则表达式递归导致的CPU增高场景。看看Arthas能不能找到原因。
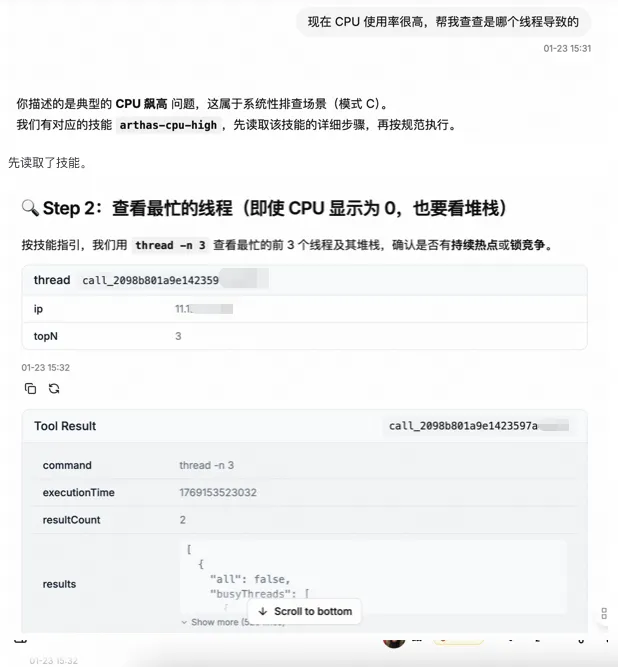
你说:现在 CPU 使用率很高,帮我查查是哪个线程导致的?
3.6.1 没有 AI 时,资深同学会怎么推进(典型 10~20 分钟链路)
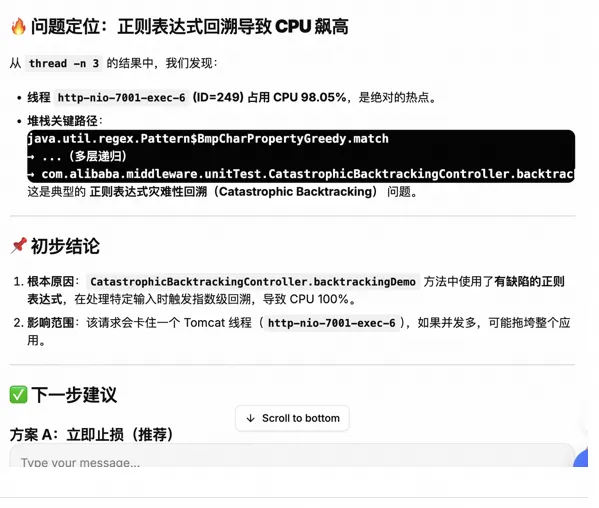
CPU 高的排查,真正难的不是“找到 CPU 高”,而是从“现象”收敛到“能改的代码点”。常见的专家流程是:
如果堆栈在序列化/正则/日志格式化 → 计算型热点;
如果堆栈大量 BLOCKED → 锁竞争/排队型热点;
如果堆栈看起来“很正常但 CPU 仍高” → 可能是热点在 native/或采样点没踩中,需要更精确观察;
3.6.2 来看看 AI 能不能做到:一条问题触发 arthas-cpu-high 剧本
Arthas Agent 会把这类问题自动匹配到内置 Skill:arthas-cpu-high,并按Skill内容推进:
4. 我们为什么说:这是“最懂 Java”的诊断 Agent
不是因为它会背命令,而是因为它把 Java 线上诊断里的关键难点做成了“产品能力”。
懂排障节奏:先低风险取证(dashboard/thread/jvm),再逐步收敛到 trace/watch/tt
懂工程边界:默认限量、避免刷屏;高影响命令必须明确授权
懂 Spring 体系:优先只读验证(contains/beanNames/type/environment),避免 getBean() 触发副作用
懂链路定位:把“拿 traceId + 看慢点在哪”合并成一条可执行路径(Skill 剧本)
懂上下文管理:用 log_reader 子 Agent 专门做“长日志/堆栈”分析,避免主对话被噪声淹没
再补一句“工程同学最关心的”:它不会上来就乱跑。
信息不足时它会先问清楚;需要高影响操作时会先解释风险并要求明确授权;默认每轮只推进 1~2 个低风险步骤,避免线上被“刷屏式诊断”二次伤害。
那么这么好用的AI Agent在哪里可以用到呢?
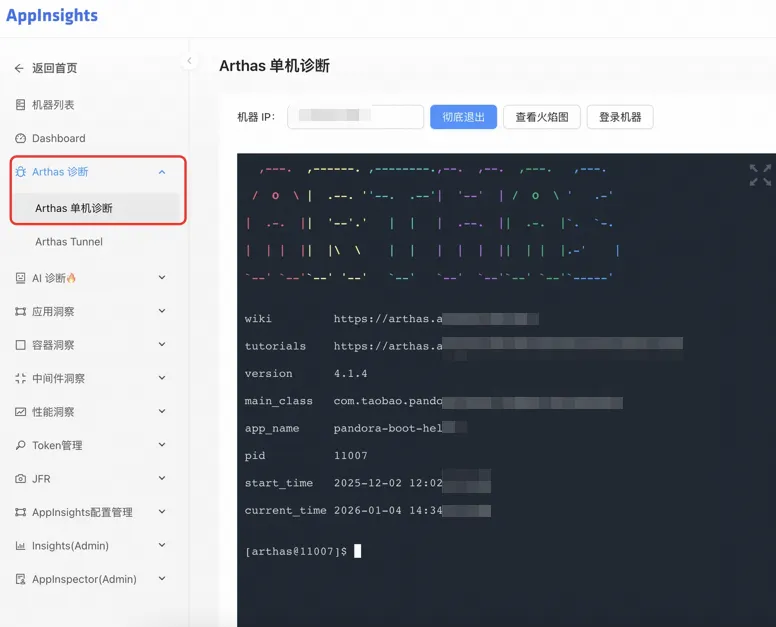
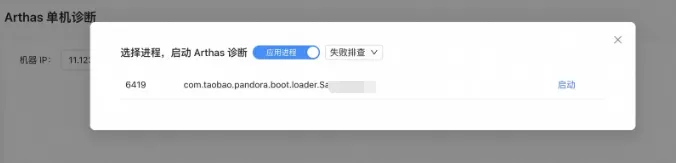
打开Arthas在线诊断网页,再选择IP,Attach 之后就可以直接提问。
一般推荐两段式:
你可以像与同事交谈一样与 Copilot 对话。以下是几种典型的提问模式:
A. 明确指令型
当你清楚知道要做什么,但记不住具体命令参数时:
B. 现象咨询型(推荐)
当你遇到线上问题,需要排查思路时:
CPU 问题:“现在 CPU 使用率很高,帮我查查是哪个线程导致的?”
性能问题:“queryUserInfo 这个接口偶尔特别慢,怎么排查是卡在哪里了?”
死锁问题:“服务好像卡住了,没反应,是不是死锁了?”
逻辑问题:“代码里的 if (user.vip) 分支好像一直没进去,帮我看看运行时的变量值。”
C. 模糊查询型
当你不知道具体的类全名时:
(注:Agent 会先尝试通过安全的方式探测类名,然后引导你进一步操作)
Agent 可能会询问:“是否授权我执行?”
或建议你:“请执行以下命令,并将结果贴给我。”
6. 小建议:让 Agent 更快更准的 4 条信息
如果你愿意多给一点点上下文,排障速度会明显提升:
目标范围:应用主包名(例如 com.mycompany)、模块名、接口名;
现象时间:大概从什么时候开始、是否持续、是否能复现;
影响面:影响的接口/用户比例、是否伴随错误码/异常栈;
你最关心的结论:要根因、临时止血方案、还是长期治理建议;
7. 结语:把“会用 Arthas”变成“每个人都能用好 Arthas”
Arthas 让我们能在生产环境里“看见运行中的 Java”。
Arthas Agent 则让这种能力从“少数专家的手艺”变成“每个工程师都能复用的流程”:
你说现象,它给路径
你给线索,它补证据
你要结论,它写报告
如果你愿意,把你最常见的排障场景告诉我们:我们会把它们沉淀成新的 Skills,让下一次“一句话排障”覆盖更多问题。









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
