Linux系统DMA技术详解
- 2026-07-03 03:38:51
在Linux驱动开发中,DMA(直接内存访问)是提升I/O性能的核心技术之一——它允许外设跳过CPU,直接与系统内存进行双向数据传输,将CPU从繁重的I/O数据搬运中解放出来,大幅提升系统吞吐率。尤其在嵌入式设备、高性能存储、网络传输等场景中,DMA的优化直接决定了设备的响应速度和并发能力。本文将结合Linux 6.6内核特性,从原理、Cache一致性、编程实践到内核新特性,全面拆解Linux下的DMA技术,助力开发者快速掌握并落地DMA编程。
一、DMA核心原理:摆脱CPU的I/O搬运工
首先要明确一个关键认知:DMA并非一种“外设”,而是一种硬件机制,与系统硬件体系结构(尤其是外设总线技术)深度绑定。其核心作用是“旁路CPU”,实现外设与内存的直接数据交互,具体工作流程如下:
驱动程序发起DMA请求,告知DMA控制器(DMAC)传输的源地址、目的地址和数据长度;
DMAC接管数据传输任务,在传输期间,CPU可并发执行其他计算任务,无需等待I/O完成;
DMA传输完成后,DMAC通过中断通知CPU,CPU执行中断服务程序,完成数据后处理(如校验、通知应用层等)。
这种机制的优势的是显而易见的——对于高频、大量的数据传输(如Camera采集图像、网卡接收报文、磁盘读写),若依赖CPU中断轮询或直接搬运,会占用大量CPU资源,导致系统响应迟缓。而DMA的介入,能让CPU专注于核心计算任务,实现“计算与I/O并行”,这也是嵌入式Linux设备性能优化的关键突破口。
需要注意的是,Linux 6.6内核对DMA控制器的兼容性进一步提升,支持更多主流架构(如ARM、x86、RISC-V)的DMAC,同时优化了DMA通道的调度算法,减少了通道竞争带来的延迟,尤其适配了嵌入式设备中多外设(GPU、Camera、HDMI)同时使用DMA的场景。
二、核心痛点:DMA与Cache一致性问题
重点强调了Cache与DMA的一致性问题,这也是DMA编程中最容易踩坑、最难以定位的问题——很多初学者写完驱动后,程序逻辑无错,但数据传输异常,根源往往在于忽略了Cache一致性。
1. 为什么会出现一致性问题?
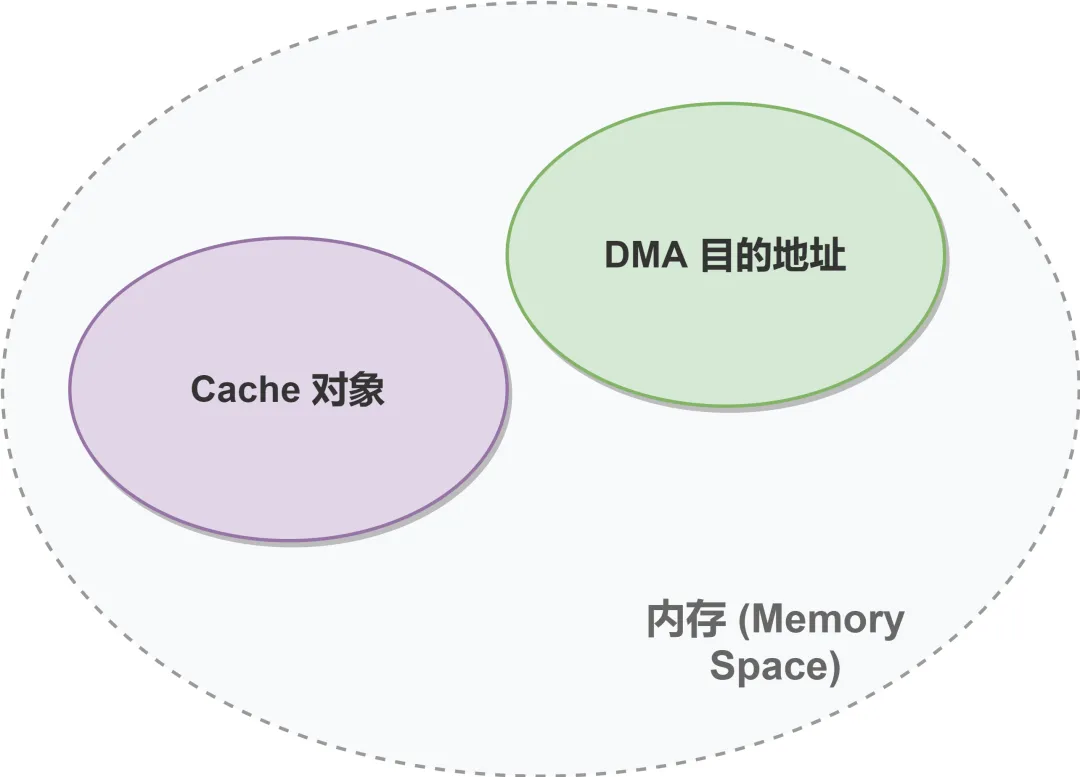
Cache的核心作用是缓存CPU频繁访问的内存数据,利用程序的空间局部性和时间局部性,减少CPU与慢速内存的交互,提升访问速率;而DMA是外设与内存直接交互,数据不经过CPU,自然也不会经过Cache。这就导致:
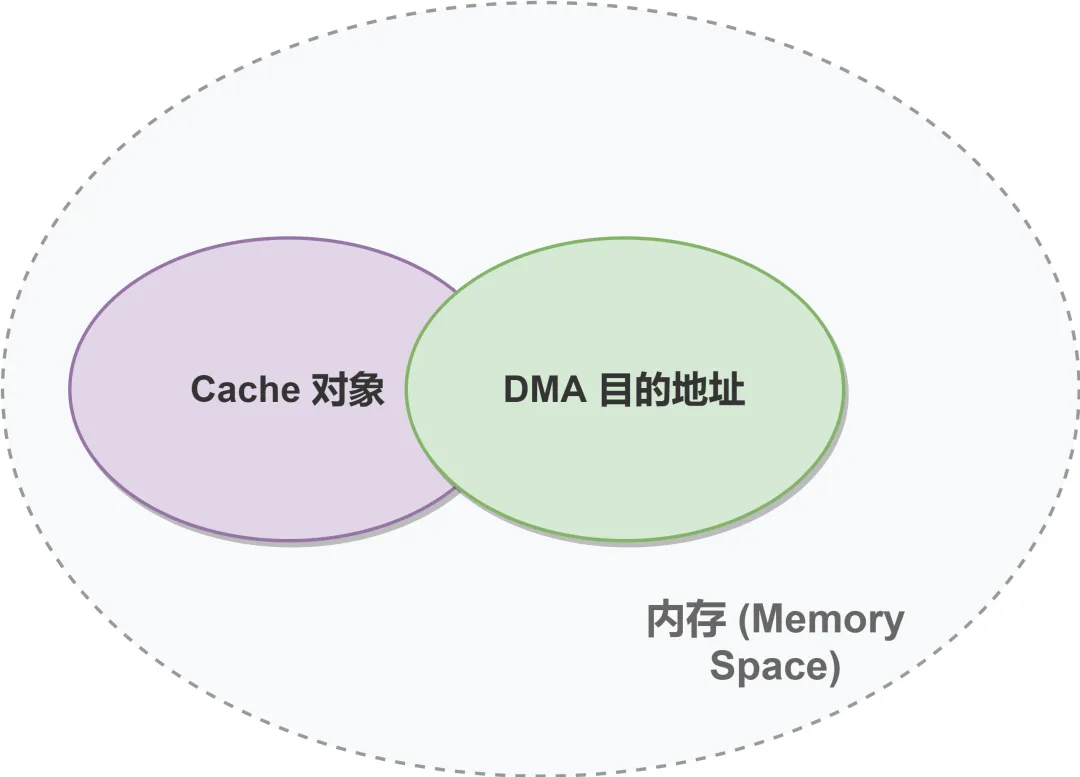
当DMA向内存写入数据时,Cache中可能还缓存着该内存地址的旧数据,CPU读取时会优先读取Cache中的旧数据,导致“数据不一致”;反之,当CPU向Cache写入数据后,若未同步到内存,DMA从内存读取时会得到旧数据,同样引发异常。
当DMA目的地址与Cache对象重叠时,一致性问题必然出现;即使不重叠,若Cache未及时同步,也可能导致数据错误。更隐蔽的是,这种问题不仅出现在DMA传输场景,在Cache使能/关闭、MMU开启等场景中也可能触发——例如arm64处理器开启MMU前,必须先置Cache无效,否则会出现地址映射异常,
/* arm64架构 使cache无效 */"mov x0, #0\n""dc ivac, x0\n" /* 使数据Cache无效 */"ic ivau, x0\n" /* 使指令Cache无效 */"dsb sy\n" /* 确保指令执行完成 */"isb\n" /* 刷新指令流水线 */2. Linux 6.6对Cache一致性的优化
Linux内核早已提供了完善的机制解决Cache一致性问题,而Linux 6.6进一步优化了一致性DMA缓冲区的分配效率,尤其针对嵌入式设备的内存约束场景做了适配:
一方面,内核保留了传统的一致性DMA缓冲区和流式DMA映射两种核心方案(后续会详细讲解),确保兼容性;另一方面,优化了CMA(连续内存分配器)的性能——CMA解决了嵌入式设备中“预留大量连续内存导致内存浪费”的痛点,平时内存可正常使用,当GPU、Camera等外设需要DMA连续内存时,再动态分配,且CMA对外提供标准的DMA一致性缓冲区API,无需开发者修改现有代码即可适配。
此外,Linux 6.6对IOMMU(输入输出内存管理单元)的支持更完善,IOMMU类似CPU的MMU,负责外设总线地址与内存物理地址的转换,不仅能解决总线地址与物理地址不统一的问题,还能通过地址映射,让SG(分散/聚集)模式下的不连续缓冲区,对外设呈现为连续地址,间接减少了Cache一致性问题的触发概率。
三、Linux 6.6 DMA编程实践:从基础到进阶
DMA编程的核心是“缓冲区分配+地址映射+通道管理”,Linux 6.6内核沿用了成熟的DMA编程接口,同时优化了部分API的性能和易用性。拆解最常用的编程场景和核心API,兼顾理论与实操。
1. 基础准备:DMA区域与地址类型
在进行DMA编程前,需先明确两个核心概念:DMA区域和地址类型,这是避免地址映射错误的前提。
(1)DMA区域:早期arm32系统的部分外设,DMA操作存在内存区域限制,因此申请缓冲区时需使用GFP_DMA标志;而现代arm64处理器(如Cortex-A53、Cortex-A76)的DMA操作可覆盖整个常规内存,无需刻意指定GFP_DMA标志。Linux 6.6内核中,get_dma_pages()函数已默认适配arm64架构,其本质是在申请标志中按需添加GFP_DMA,简化了arm64平台的DMA内存申请编程:
#define __get_dma_pages(gfp_mask, order) \ __get_free_pages((gfp_mask) | GFP_DMA,(order))若不想使用order(内存大小的对数)申请内存,可使用dma_mem_alloc()函数,自动计算order并申请DMA内存。
(2)地址类型:DMA编程中需区分三种地址,这是新手最容易混淆的点,Linux 6.6内核对地址转换的支持更灵活:
虚拟地址:CPU核视角看到的地址,用于内核代码访问(如驱动中的指针操作);
物理地址:CPU MMU外围视角看到的地址,对应内存的实际硬件地址;
总线地址:外设视角看到的地址,是DMA实际使用的地址,部分架构(如PReP系统)中,总线地址与物理地址不同,需通过内核API转换。
注意:Linux 6.6已不推荐使用virt_to_bus()和bus_to_virt()函数进行地址转换,尤其在使用IOMMU或反弹缓冲区的场景下,这两个函数会失效。建议使用后续提到的DMA映射API,自动完成地址转换。
2. 核心编程:两种DMA映射方式
Linux内核提供两种DMA映射方式,分别对应不同的使用场景,Linux 6.6对这两种方式的API做了兼容性优化,确保在新架构下正常工作。
(1)一致性DMA缓冲区:适合驱动自主申请缓冲区
一致性DMA缓冲区的核心优势是“自动保证Cache一致性”,内核在分配缓冲区时,会确保Cache与内存的数据同步,适合驱动自己申请缓冲区、长期使用的场景(如设备的环形缓冲区)。
核心API(Linux 6.6完全兼容):
// 分配一致性DMA缓冲区,返回虚拟地址,通过handle输出总线地址void * dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);// 释放一致性DMA缓冲区voiddma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle);// 分配写合并(Writecombining)的一致性缓冲区(适合高频写入场景)void * dma_alloc_writecombine(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);补充说明:dma_alloc_xxx()函数虽以dma_alloc开头,但不一定从DMA区域申请内存——以arm64处理器为例,只有当coherent_dma_mask小于0xffffffffffffffff时,才会设置GFP_DMA标志,从DMA区域申请内存,Linux 6.6中该逻辑已优化,更适配arm64架构的内存管理机制。
对于arm64平台的PCIe设备,Linux 6.6保留了pci_alloc_consistent()和pci_free_consistent()专属API,用法与dma_alloc_coherent()类似,专门适配arm64架构下PCIe设备的DMA需求,同时优化了API与arm64 IOMMU的协同工作效率。
(2)流式DMA映射:适合缓冲区来自上层(如网络报文、块设备数据)
很多场景下,DMA缓冲区并非驱动申请,而是来自内核上层(如网卡驱动中的网络报文、块设备驱动中要写入磁盘的数据),这些缓冲区用普通kmalloc()申请,未考虑Cache一致性,此时需使用流式DMA映射,本质是通过Cache使无效/清除操作,解决一致性问题。
流式DMA映射的核心步骤(Linux 6.6通用):
映射:通过API将缓冲区映射为总线地址,同时处理Cache一致性;
传输:执行DMA数据传输;
去映射:传输完成后,解除映射,恢复缓冲区状态。
核心API及实操示例:
// 单个缓冲区流式映射,返回总线地址,direction指定传输方向dma_addr_tdma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction direction);// 单个缓冲区去映射voiddma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma_data_direction direction);// 若驱动需访问已映射的流式缓冲区,先获取所有权voiddma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);// 访问完成后,返还所有权给设备voiddma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);对于大型缓冲区,若设备支持SG(分散/聚集)模式,可申请多个不连续的小缓冲区,通过dma_map_sg()进行映射,Linux 6.6优化了sg_dma_address()和sg_dma_len()函数的性能,能快速获取SG缓冲区的总线地址和长度,减少映射延迟。scatterlist结构体是SG映射的核心数据结构,用于存储每个小缓冲区的页信息、偏移和总线地址。
3. 进阶:dmaengine标准API(Linux 6.6推荐)
Linux内核推荐使用dmaengine驱动架构编写DMA控制器驱动,外设驱动通过标准dmaengine API完成DMA准备、发起和回调,这种方式解耦了DMA控制器驱动与外设驱动,提升了代码复用性和可维护性,Linux 6.6进一步完善了dmaengine API的稳定性和兼容性。
核心流程及API:
申请DMA通道:通过dma_request_slave_channel()或__dma_request_channel()申请通道,使用完成后通过dma_release_channel()释放;
准备DMA描述符:通过dmaengine_prep_slave_single()准备传输描述符,设置传输地址、长度、方向和回调函数;
提交并发起DMA:通过dmaengine_submit()提交描述符,dma_async_issue_pending()发起传输;
传输完成回调:DMA完成后,回调函数自动执行,完成后处理。
dmaengine API实操示例,Linux 6.6中该示例完全适用,仅需根据具体外设调整传输方向、地址等参数即可。
4. 关键补充:DMA地址掩码
并非所有设备都能访问全部内存地址,若设备只能访问特定位数的地址(如24位地址),需通过dma_set_mask()函数设置DMA地址掩码,限制DMA的寻址范围,避免地址越界。Linux 6.6中,该函数的底层实现已适配多架构,本质是修改device结构体中的dma_mask成员:
// 示例:设置设备只能访问24位地址(0xffffff)dma_set_mask(dev, 0xffffff);注意:device结构体中还有coherent_dma_mask成员,专门用于一致性DMA缓冲区的寻址范围,与dma_mask不可混淆。
四、Linux 6.6 DMA内核新特性与优化
相比旧版本内核,Linux 6.6在DMA技术上的优化主要集中在嵌入式场景和性能提升,重点如下:
CMA性能优化:优化了CMA的内存分配算法,减少了外设申请连续内存时的等待时间,同时支持动态调整CMA区域大小,适配不同设备的内存需求,尤其适合GPU、Camera等对连续内存需求较大的外设;
dmaengine调度优化:改进了DMA通道的调度机制,支持通道优先级设置,避免高优先级外设(如实时采集设备)因通道竞争导致的传输延迟;
IOMMU兼容性提升:完善了IOMMU与DMA的协同工作逻辑,支持更多架构的IOMMU,同时优化了地址映射效率,减少了SG模式下的地址转换开销;
API易用性优化:简化了一致性DMA缓冲区的分配流程,同时提供了更详细的错误提示,方便开发者定位映射失败、地址错误等问题。
五、常见坑点与避坑指南
总结几个新手常踩的坑,帮助大家快速避坑:
坑点1:忽略Cache一致性,导致数据传输异常。解决方案:根据缓冲区来源,选择一致性DMA缓冲区或流式DMA映射,避免直接使用普通内存作为DMA缓冲区;
坑点2:混淆三种地址类型,使用虚拟地址直接作为DMA传输地址。解决方案:通过DMA映射API获取总线地址,确保DMA使用正确的地址;
坑点3:未释放DMA通道或缓冲区,导致内存泄漏。解决方案:在驱动卸载时,务必释放DMA通道、缓冲区和映射;
坑点4:未设置DMA地址掩码,导致设备无法访问内存。解决方案:根据设备的寻址能力,调用dma_set_mask()设置正确的地址掩码;
坑点5:使用废弃API(如virt_to_bus),导致跨架构兼容性问题。解决方案:Linux 6.6中优先使用dma_alloc_coherent、dma_map_single等推荐API。
六、总结与展望
DMA技术是Linux驱动开发中提升I/O性能的关键,尤其在嵌入式和高性能场景中,掌握DMA编程是高级驱动开发者的必备技能。本文结合DMA核心原理、Cache一致性、编程API,以及Linux 6.6内核的新特性,从基础到进阶,完整拆解了Linux下的DMA技术,同时给出了避坑指南和实操示例。
随着嵌入式设备性能需求的提升,DMA技术也在不断优化——Linux 6.6的CMA、dmaengine、IOMMU等优化,进一步降低了DMA编程的复杂度,提升了传输性能。未来,DMA将更注重多外设协同、低延迟和节能,尤其在物联网、工业控制等场景中,DMA的优化将直接影响设备的续航和响应速度。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python 入门之变量命名规则
- 别再用 print 调试了!Python 官方推荐的日志实践指南
- PHP 防 SQL 注入别瞎折腾!这 2 招我用了 5 年,从没踩坑
- 听写小助手3.0:小孩哥使用 Python 写出的(小学六年级学生作品,毕业纪念版)
- Python-EconML包:快速上手动态双重机器学习
- 【好书推荐】基于Python的因果推断 中国电力出版社 (巴西)马修斯·法库尔
- 我愿称之为: Python最伟大的网站(没有之一)
- Python程序设计基础笔记(第一弹)
- 【python每日一练】案例:8岁小孩绘制彩虹色螺旋线(趣味进阶)
- 瞬间对Python的兴趣达到了1000000%
