Linux内存管理:回收页面page reclaim
- 2026-07-04 03:01:15
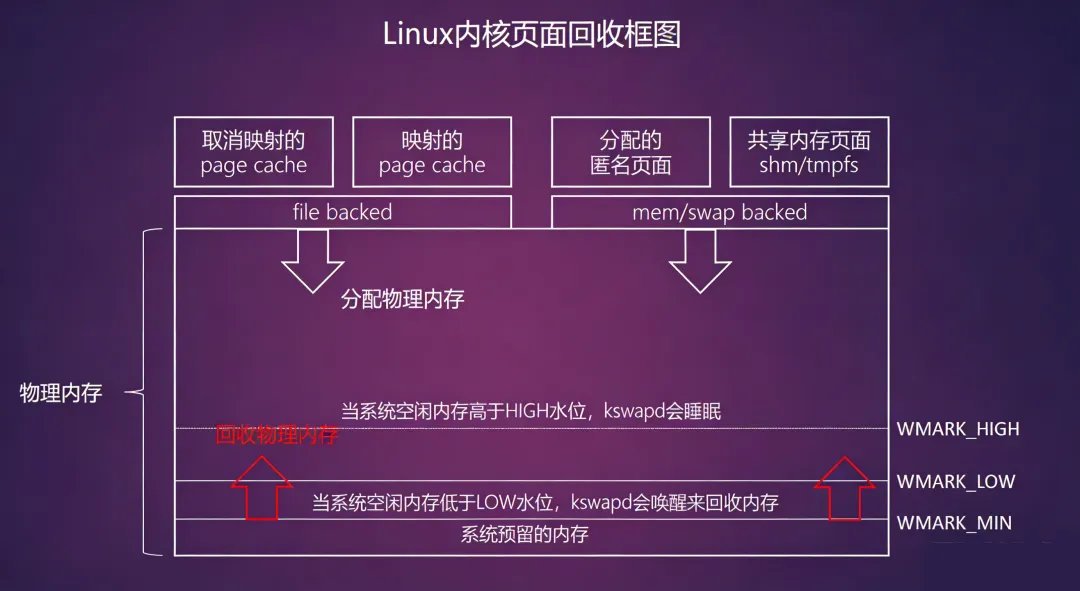
所以回收页面的三种机制:
(1)对未修改的文件缓存页面可以直接丢弃。
(2)对被修改的文件缓存页面需要会写到存储设备中。
(3)很少使用的匿名页面交换到swap分区,以便释放出物理内存,这个机制称为页交换(swapping)。
LRU链表)是页面回收操作的基础,kswapd内核线程是页面回收的入口,每个NUMA内存节点都会创建一个"kswapd%d"的内核线程。
下面的函数分析按照内存节点-->Zone-->LRU Active/Inactive层级展开:
balance_pgdat函数是页面回收的主函数,对应的内存层次是一个内存节点;
shrink_zone函数用于扫描zone中的所有可回收页面,对应的内存层次是一个zone;
然后shrink_active_list函数扫描活跃页面,看看有哪些活跃页面可以迁移到不活跃页面链表中;shrink_inactive_list函数扫描不活跃页面链表并且回收页面。
最后跟踪LRU活动情况介绍了页面被释放,LRU是如何知道并且更新链表的;以及Refault Distance算法对文件缓存页面回收的优化。
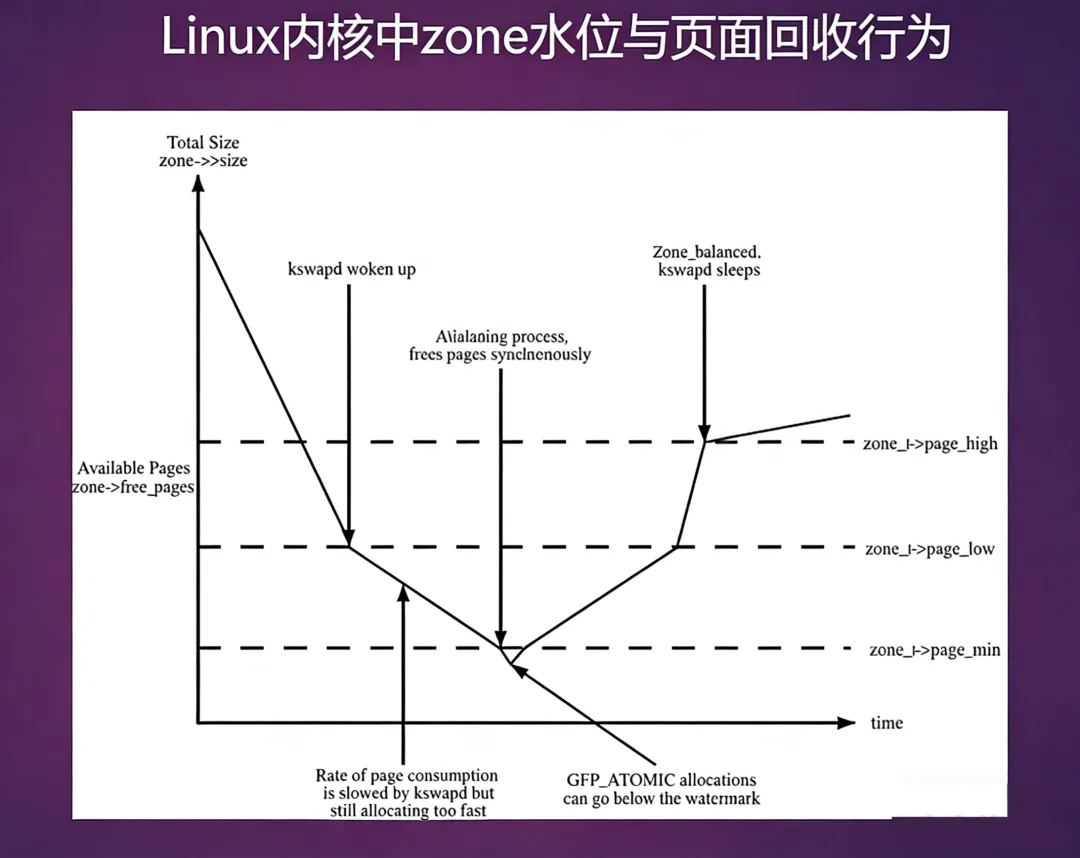
将kswapd的核心活动列出可以看出kswapd基本脉络,下面的章节逐步展开介绍:
kswapd_init---------------------------------------kswapd模块的初始化函数kswapd_run--------------------------------------创建内核线程kswapdkswapd----------------------------------------kswapd内核线程的执行函数kswapd_try_to_sleep-------------------------睡眠并且让出CPU,等待wakeup_kswapd()唤醒。♥balance_pgdat-------------------------------回收页面的主函数,多zonekswapd_shrink_zone------------------------单独处理某个zone的扫描和页面回收shrink_zone-----------------------------扫描zone中所有可回收的页面shrink_lruvec-------------------------扫描LRU链表的核心函数shrink_list-------------------------处理各种LRU链表shrink_active_list----------------查看哪些活跃页面可以迁移到不活跃页面链表中isolate_lru_pages---------------从LRU链表中分离页面shrink_inactive_list--------------扫描inactive LRU链表尝试回收页面,并且返回已经回收页面的数量。shrink_page_list----------------扫描page_list链表的页面并返回已回收的页面数量shrink_slab---------------------------调用内存管理系统中的shrinker接口来回收内存pgdat_balanced----------------------------判断内存节点是否处于平衡状态,即处于高水位zone_balanced---------------------------判断内存节点中的zone是否处于平衡状态
一、LRU链表
LRU(Least Recently Used)是最近最少使用的意思,内核假定最近不适用的页在较短的时间内也不会频繁使用。
在内存不足时,这些页面优先成为被换出的候选者。
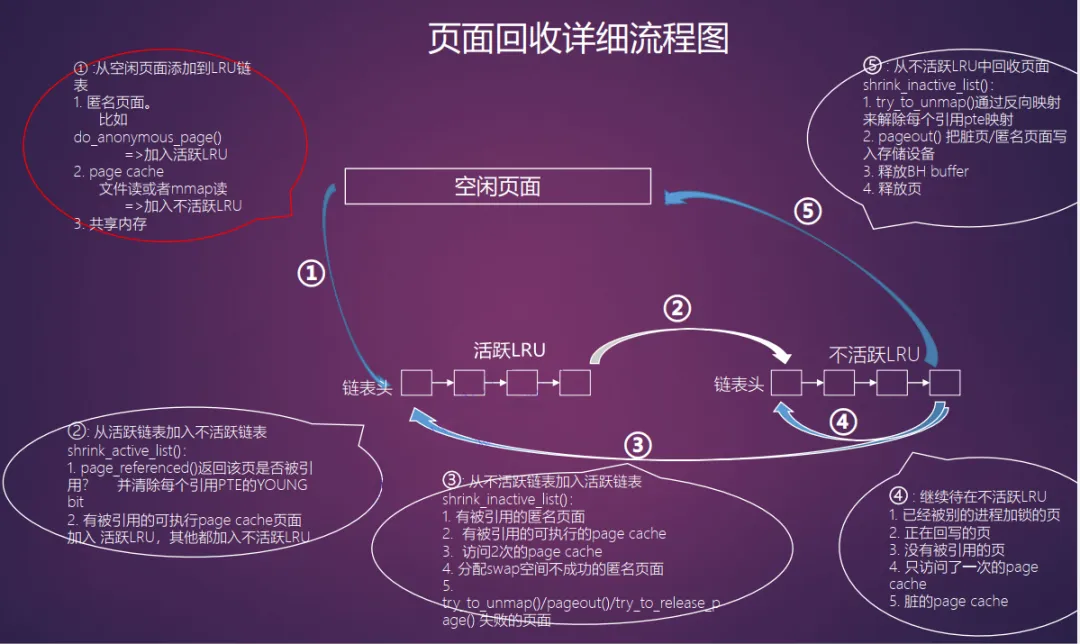
1.1 LRU链表
LRU是双向链表,内核根据页面类型(匿名和文件)与活跃性(活跃和不活跃),分成5种类型LRU链表:
#define LRU_BASE 0#define LRU_ACTIVE 1#define LRU_FILE 2enum lru_list {LRU_INACTIVE_ANON = LRU_BASE,--------------------------不活跃匿名页面链表,需要交换分区才能回收LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,---------------活跃匿名页面链表LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,---------------不活跃文件映射页面链表,最优先回收LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,----活跃文件映射页面链表LRU_UNEVICTABLE,---------------------------------------不可回收页面链表,禁止换出NR_LRU_LISTS};struct lruvec {struct list_head lists[NR_LRU_LISTS];struct zone_reclaim_stat reclaim_stat;#ifdef CONFIG_MEMCGstruct zone *zone;#endif};struct zone {.../* Fields commonly accessed by the page reclaim scanner */spinlock_t lru_lock;struct lruvec lruvec;...}
从zone可以找到各种LRU链表,遍历成员,所以页面回收是按照zone来进行的;到Linux v4.8开始改为基于node的LRU链表。
LRU链表是如何实现页面老化的?
将页面加入LRU链表的常用API是lru_cache_add()。
lru_cache_add()-->__lru_cache_add()-->
/* 14 pointers + two long's align the pagevec structure to a power of two */#define PAGEVEC_SIZE 14struct pagevec {unsigned long nr;unsigned long cold;struct page *pages[PAGEVEC_SIZE];-------批处理一次14个页面};static void __lru_cache_add(struct page *page){struct pagevec *pvec = &get_cpu_var(lru_add_pvec);page_cache_get(page);if (!pagevec_space(pvec))-------------判断pagevec是否还有空间,如没有调用__pagevec_lru_add()将原有的page加入到LRU链表中__pagevec_lru_add(pvec);pagevec_add(pvec, page);--------------加入到struct pagevec中put_cpu_var(lru_add_pvec);}
void __pagevec_lru_add(struct pagevec *pvec){pagevec_lru_move_fn(pvec, __pagevec_lru_add_fn, NULL);}static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec,void *arg){int file = page_is_file_cache(page);int active = PageActive(page);enum lru_list lru = page_lru(page);-------------------------------------------判断page的LRU类型VM_BUG_ON_PAGE(PageLRU(page), page);SetPageLRU(page);add_page_to_lru_list(page, lruvec, lru);update_page_reclaim_stat(lruvec, file, active);trace_mm_lru_insertion(page, lru);}
add_page_to_lru_list()根据获取的lru,将page加入到lruvec->lists[lru]中。
lru_to_page()和list_del()组合实现从LRU链表摘取页面。lru_to_page()从链表末尾摘取页面,LRU采用FIFO算法,最先进入LRU链表的页面,在LRU中时间越长,老化时间越长。
最不常用的页面将慢慢移动到不活跃LRU链表末尾,这些页面是最适合的候选者。
lru_cache_add:用于将页面加入到LRU链表中。
lru_to_page:用于从LRU链表末尾获取页面。
list_del:可以将page从LRU链表中移除。
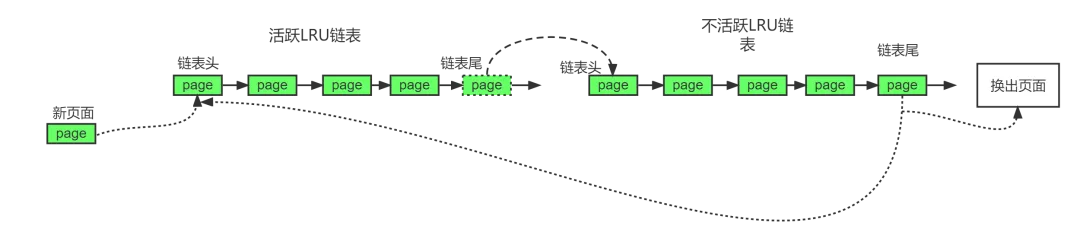
1.2 第二次机会法
第二次机会(second chance)算法为了避免把经常使用的页面置换出去。
当选择置换页面时,依然和LRU算法一样,选择最早置入链表的页面,即在链表末尾的页面。
二次机会法设置了一个访问状态位,如果访问位是0,就淘汰这页面;如果访问位是1,就给他第二次机会,并选择下一个页面来换出。
得到第二次机会的页面,它的访问位会被清0;如果该页在此期间再次被访问过,则访问位值为1。
Linux内核使用了PG_active和PG_referenced两个标志位来实现第二次机会法。
PG_active表示该页在活跃LRU中;PG_referenced表示该页是否被引用过。
1.3 mark_page_accessed()
从函数开头可以看出,PG_active和PG_referenced有三种组合。
/** Mark a page as having seen activity.** inactive,unreferenced -> inactive,referenced-----1* inactive,referenced -> active,unreferenced---2* active,unreferenced -> active,referenced-----3** When a newly allocated page is not yet visible, so safe for non-atomic ops,* __SetPageReferenced(page) may be substituted for mark_page_accessed(page).*/void mark_page_accessed(struct page *page){if (!PageActive(page) && !PageUnevictable(page) &&PageReferenced(page)) {-----------------------inactive,referenced情况,置为active,unreferenced。对应情况2/** If the page is on the LRU, queue it for activation via* activate_page_pvecs. Otherwise, assume the page is on a* pagevec, mark it active and it'll be moved to the active* LRU on the next drain.*/if (PageLRU(page))activate_page(page);else__lru_cache_activate_page(page);ClearPageReferenced(page);if (page_is_file_cache(page))workingset_activation(page);} else if (!PageReferenced(page)) {--------------------inactive,unreferenced和active,unreferenced两种情况,置为inactive/active,referenced。对应情况1,3SetPageReferenced(page);}}
1.4 page_check_references()
在扫描不活跃LRU链表时,page_check_referenced()会被调用,返回值是一个page_referenced的枚举类型。
enum page_references {PAGEREF_RECLAIM,-------------------表示该页面可以被尝试回收PAGEREF_RECLAIM_CLEAN,-------------表示该页面可以被尝试回收PAGEREF_KEEP,----------------------表示该页面会继续保留在不活跃链表中PAGEREF_ACTIVATE,------------------表示该页面会迁移到活跃链表};staticenum page_references page_check_references(struct page *page,struct scan_control *sc){int referenced_ptes, referenced_page;unsigned long vm_flags;referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,&vm_flags);-------------------------------------------------检查该页是否被pte访问引用,通过rmap_walk查找该页被多少个pte引用。referenced_page = TestClearPageReferenced(page);------------------------------页面是否被置位PG_referenced,如果是就给第二次机会。/** Mlock lost the isolation race with us. Let try_to_unmap()* move the page to the unevictable list.*/if (vm_flags & VM_LOCKED)return PAGEREF_RECLAIM;if (referenced_ptes) {---------------------------------------------------------页面被pte引用if (PageSwapBacked(page))return PAGEREF_ACTIVATE;-----------------------------------------------匿名页面,加入活跃链表/** All mapped pages start out with page table* references from the instantiating fault, so we need* to look twice if a mapped file page is used more* than once.** Mark it and spare it for another trip around the* inactive list. Another page table reference will* lead to its activation.** Note: the mark is set for activated pages as well* so that recently deactivated but used pages are* quickly recovered.*/SetPageReferenced(page);if (referenced_page || referenced_ptes > 1)return PAGEREF_ACTIVATE;--------------------------------------------最近第二次访问的page cache或shared page cache,加入活跃链表。/** Activate file-backed executable pages after first usage.*/if (vm_flags & VM_EXEC)return PAGEREF_ACTIVATE;--------------------------------------------可执行文件的page cache,加入活跃链表return PAGEREF_KEEP;----------------------------------------------------保留在不活跃链表中}/* Reclaim if clean, defer dirty pages to writeback */if (referenced_page && !PageSwapBacked(page))-------------------------------第二次访问的page cache页面,可以释放return PAGEREF_RECLAIM_CLEAN;return PAGEREF_RECLAIM;-----------------------------------------------------页面没有被pte引用,可以释放}
1.5 page_referenced()
page_referenced()函数判断page是否被访问引用过,返回访问引用pte的个数,即访问和引用这个页面的用户进程空间虚拟页面的个数。
核心思想是利用反响映射系统来统计访问引用pte的用户个数。
page_referenced()主要工作如下:
利用RMAP系统遍历所有映射该页面的pte。
对每个pte,如果L_PTE_YOUNG比特位置位,说明之前被访问过,referenced计数加1;然后清空L_PTE_YOUNG。对ARM32来说,会清空硬件页表项内容,人为制造一个缺页中断,当再次访问该pte时,在缺页中断中设置L_PTE_YOUNG比特位。
返回referenced计数,表示该页有多少个访问引用pte。
/*** page_referenced - test if the page was referenced* @page: the page to test* @is_locked: caller holds lock on the page* @memcg: target memory cgroup* @vm_flags: collect encountered vma->vm_flags who actually referenced the page** Quick test_and_clear_referenced for all mappings to a page,* returns the number of ptes which referenced the page.*/intpage_referenced(struct page *page,int is_locked,struct mem_cgroup *memcg,unsigned long *vm_flags){int ret;int we_locked = 0;struct page_referenced_arg pra = {.mapcount = page_mapcount(page),.memcg = memcg,};struct rmap_walk_control rwc = {.rmap_one = page_referenced_one,.arg = (void *)&pra,.anon_lock = page_lock_anon_vma_read,};*vm_flags = 0;if (!page_mapped(page))----------------------------------判断page->_mapcount引用计数是否大于等于0.return 0;if (!page_rmapping(page))--------------------------------判断page->mapping是否有地址空间映射。return 0;if (!is_locked && (!PageAnon(page) || PageKsm(page))) {we_locked = trylock_page(page);if (!we_locked)return 1;}/** If we are reclaiming on behalf of a cgroup, skip* counting on behalf of references from different* cgroups*/if (memcg) {rwc.invalid_vma = invalid_page_referenced_vma;}ret = rmap_walk(page, &rwc);---------------------------遍历该页面所有映射的pte,然后调用struct rmap_walk_control的成员rmap_one。*vm_flags = pra.vm_flags;if (we_locked)unlock_page(page);return pra.referenced;}
page_referenced()中调用page_referenced_one()进行referenced和mapcount计数处理。
staticintpage_referenced_one(struct page *page, struct vm_area_struct *vma,unsigned long address, void *arg){struct mm_struct *mm = vma->vm_mm;spinlock_t *ptl;int referenced = 0;struct page_referenced_arg *pra = arg;if (unlikely(PageTransHuge(page))) {...} else {pte_t *pte;/** rmap might return false positives; we must filter* these out using page_check_address().*/pte = page_check_address(page, mm, address, &ptl, 0);--------------根据mm和address获取pteif (!pte)return SWAP_AGAIN;if (vma->vm_flags & VM_LOCKED) {pte_unmap_unlock(pte, ptl);pra->vm_flags |= VM_LOCKED;return SWAP_FAIL; /* To break the loop */}if (ptep_clear_flush_young_notify(vma, address, pte)) {-----------判断pte最近是否被访问过,/** Don't treat a reference through a sequentially read* mapping as such. If the page has been used in* another mapping, we will catch it; if this other* mapping is already gone, the unmap path will have* set PG_referenced or activated the page.*/if (likely(!(vma->vm_flags & VM_SEQ_READ)))-------------------顺序读的page cache是被回收的最佳后选者,其余情况都会当做pte被引用,增加计数。referenced++;}pte_unmap_unlock(pte, ptl);}if (referenced) {pra->referenced++;-------------------------------------------------pra->referenced增加计数pra->vm_flags |= vma->vm_flags;}pra->mapcount--;-------------------------------------------------------pra->mapcount减少计数if (!pra->mapcount)return SWAP_SUCCESS; /* To break the loop */return SWAP_AGAIN;}
二、kswapd内核线程
kswapd负责在内存不足的情况下回收页面,kswapd内核线程初始化时会为系统中每个NUMA内存节点创建一个名为"kswapd%d"的内核线程。
2.1 kswapd_wait等待队列
setup_arch()-->paging_init()-->bootmem_init()-->zone_sizes_init()-->free_area_init_node()-->free_area_init_core,kswapd_wait等待队列在free_area_init_core中进行初始化,每个内存节点一个。
等待队列用于使进程等待某一事件发生,而无需频繁轮询,进程在等待期间睡眠。在某事件发生时,由内核自动唤醒。
kswapd内核线程在kswapd_wait等待队列上等待TASK_INTERRUPTIBLE事件发生。
staticvoid __paginginit free_area_init_core(struct pglist_data *pgdat,unsigned long node_start_pfn, unsigned long node_end_pfn,unsigned long *zones_size, unsigned long *zholes_size){...init_waitqueue_head(&pgdat->kswapd_wait);init_waitqueue_head(&pgdat->pfmemalloc_wait);pgdat_page_ext_init(pgdat);...}
2.2 创建kswapd内核线程
kswapd内核线程负责在内存不足的情况下进行页面回收,每NUMA内存节点配置一个。
其中kswapd函数是内核线程kswapd的入口。
staticint __init kswapd_init(void){int nid;swap_setup();for_each_node_state(nid, N_MEMORY)-----------------------------------------每个内存节点创建一个kswapd内核线程kswapd_run(nid);hotcpu_notifier(cpu_callback, 0);return 0;}intkswapd_run(int nid){pg_data_t *pgdat = NODE_DATA(nid);-----------------------------------------获取内存节点对应的pg_data_t指针int ret = 0;if (pgdat->kswapd)return 0;pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);---------------kswapd函数,pgdat作为参数传入kswapd函数。if (IS_ERR(pgdat->kswapd)) {/* failure at boot is fatal */BUG_ON(system_state == SYSTEM_BOOTING);pr_err("Failed to start kswapd on node %d\n", nid);ret = PTR_ERR(pgdat->kswapd);pgdat->kswapd = NULL;}return ret;}staticintkswapd(void *p){unsigned long order, new_order;unsigned balanced_order;int classzone_idx, new_classzone_idx;int balanced_classzone_idx;pg_data_t *pgdat = (pg_data_t*)p;-----------------------------------------从kswapd_run传入的内存节点数据结构pg_data_t。struct task_struct *tsk = current;struct reclaim_state reclaim_state = {.reclaimed_slab = 0,};const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);lockdep_set_current_reclaim_state(GFP_KERNEL);if (!cpumask_empty(cpumask))set_cpus_allowed_ptr(tsk, cpumask);current->reclaim_state = &reclaim_state;/** Tell the memory management that we're a "memory allocator",* and that if we need more memory we should get access to it* regardless (see "__alloc_pages()"). "kswapd" should* never get caught in the normal page freeing logic.** (Kswapd normally doesn't need memory anyway, but sometimes* you need a small amount of memory in order to be able to* page out something else, and this flag essentially protects* us from recursively trying to free more memory as we're* trying to free the first piece of memory in the first place).*/tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;set_freezable();order = new_order = 0;balanced_order = 0;classzone_idx = new_classzone_idx = pgdat->nr_zones - 1;balanced_classzone_idx = classzone_idx;for ( ; ; ) {bool ret;/** If the last balance_pgdat was unsuccessful it's unlikely a* new request of a similar or harder type will succeed soon* so consider going to sleep on the basis we reclaimed at*/if (balanced_classzone_idx >= new_classzone_idx &&balanced_order == new_order) {new_order = pgdat->kswapd_max_order;new_classzone_idx = pgdat->classzone_idx;pgdat->kswapd_max_order = 0;pgdat->classzone_idx = pgdat->nr_zones - 1;}if (order < new_order || classzone_idx > new_classzone_idx) {/** Don't sleep if someone wants a larger 'order'* allocation or has tigher zone constraints*/order = new_order;classzone_idx = new_classzone_idx;} else {kswapd_try_to_sleep(pgdat, balanced_order,---------------------------在此处睡眠,等待wakeup_kswapd来唤醒。balanced_classzone_idx);order = pgdat->kswapd_max_order;classzone_idx = pgdat->classzone_idx;--------------------------------pgdata->kswapd_max_order和pgdat->classzone_id已经在wakeup_kswapd中进行了更新。new_order = order;new_classzone_idx = classzone_idx;pgdat->kswapd_max_order = 0;pgdat->classzone_idx = pgdat->nr_zones - 1;}ret = try_to_freeze();if (kthread_should_stop())break;/** We can speed up thawing tasks if we don't call balance_pgdat* after returning from the refrigerator*/if (!ret) {trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);balanced_classzone_idx = classzone_idx;balanced_order = balance_pgdat(pgdat, order,------------------------进行页面回收的主函数。&balanced_classzone_idx);}}tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);current->reclaim_state = NULL;lockdep_clear_current_reclaim_state();return 0;}
staticvoidkswapd_try_to_sleep(pg_data_t *pgdat, int order, int classzone_idx){long remaining = 0;DEFINE_WAIT(wait);if (freezing(current) || kthread_should_stop())return;prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);----------------------------------定义一个wait在kswapd_wait上等待,设置进程状态为TASK_INTERRUPTIBLE。/* Try to sleep for a short interval */if (prepare_kswapd_sleep(pgdat, order, remaining, classzone_idx)) {-------------------------------remaining为0,检查kswapd是否准备好睡眠。remaining = schedule_timeout(HZ/10);----------------------------------------------------------尝试短睡100ms,如果返回不为0,则说明没有100ms之内被唤醒了。finish_wait(&pgdat->kswapd_wait, &wait);prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);}/** After a short sleep, check if it was a premature sleep. If not, then* go fully to sleep until explicitly woken up.*/if (prepare_kswapd_sleep(pgdat, order, remaining, classzone_idx)) {-------------------------------如果短睡被唤醒,则没有必要继续睡眠。如果短睡美欧被唤醒,则可以尝试进入睡眠。trace_mm_vmscan_kswapd_sleep(pgdat->node_id);/** vmstat counters are not perfectly accurate and the estimated* value for counters such as NR_FREE_PAGES can deviate from the* true value by nr_online_cpus * threshold. To avoid the zone* watermarks being breached while under pressure, we reduce the* per-cpu vmstat threshold while kswapd is awake and restore* them before going back to sleep.*/set_pgdat_percpu_threshold(pgdat, calculate_normal_threshold);/** Compaction records what page blocks it recently failed to* isolate pages from and skips them in the future scanning.* When kswapd is going to sleep, it is reasonable to assume* that pages and compaction may succeed so reset the cache.*/reset_isolation_suitable(pgdat);if (!kthread_should_stop())schedule();------------------------------------------------------------------------------让出CPU控制权。set_pgdat_percpu_threshold(pgdat, calculate_pressure_threshold);} else {if (remaining)count_vm_event(KSWAPD_LOW_WMARK_HIT_QUICKLY);elsecount_vm_event(KSWAPD_HIGH_WMARK_HIT_QUICKLY);}finish_wait(&pgdat->kswapd_wait, &wait);---------------------------------------------------------设置进程状态为TASK_RUNNING。}
2.3 唤醒kswapd内核线程回收页面
触发内存回收的条件是,在内存分配路径上,低水位情况下内存分配失败。那么会通过调用wakeup_kswapd函数唤醒kswapd内核线程来回收页面,达到释放内存的目的。
在NUMA系统中,使用pg_data_t来描述物理内存布局,和kswapd相关参数有:
typedef struct pglist_data {...wait_queue_head_t kswapd_wait;----------------------------等待队列wait_queue_head_t pfmemalloc_wait;struct task_struct *kswapd; /* Protected bymem_hotplug_begin/end() */int kswapd_max_order;-------------------------------------enum zone_type classzone_idx;-----------------------------最合适分配内存的zone序号...} pg_data_t;
最主要的两个参数是kswapd_max_order和classzone_idx,这两个参数会在kswapd唤醒后读取并使用。
alloc_page()-->alloc_pages_nodemask()-->alloc_pages_slowpath()-->wake_all_kswapds()-->wakeup_kswapd()。
voidwakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx){pg_data_t *pgdat;if (!populated_zone(zone))return;if (!cpuset_zone_allowed(zone, GFP_KERNEL | __GFP_HARDWALL))return;pgdat = zone->zone_pgdat;if (pgdat->kswapd_max_order < order) {pgdat->kswapd_max_order = order;pgdat->classzone_idx = min(pgdat->classzone_idx, classzone_idx);-------------------------准备内存本节点的classzone_idx和kswapd_max_order两个参数。}if (!waitqueue_active(&pgdat->kswapd_wait))return;if (zone_balanced(zone, order, 0, 0))return;trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, zone_idx(zone), order);wake_up_interruptible(&pgdat->kswapd_wait);---------------------------------------------------唤醒kswapd_wait等待队列上的TASK_INTERRUPTIBLE线程。}
三、balance_pgdat函数
balance_pgdat()是回收页面的主函数。这是一个大循环,首先从高端zone往低端zone方向查找第一个处于不平衡状态end_zone;然后从最低端zone开始回收页面,直到end_zone;在大循环里检查从最低端zone到classzone_idx的zone是否处于平衡状态,然后不断加大扫描力度。
staticunsignedlongbalance_pgdat(pg_data_t *pgdat, int order,int *classzone_idx){int i;int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */unsigned long nr_soft_reclaimed;unsigned long nr_soft_scanned;struct scan_control sc = {.gfp_mask = GFP_KERNEL,.order = order,.priority = DEF_PRIORITY,-------------------------------------------------------------------成员初始扫描优先级,每次扫描的页面数为tatal_size>>priority。.may_writepage = !laptop_mode,.may_unmap = 1,.may_swap = 1,};count_vm_event(PAGEOUTRUN);do {unsigned long nr_attempted = 0;bool raise_priority = true;bool pgdat_needs_compaction = (order > 0);sc.nr_reclaimed = 0;/** Scan in the highmem->dma direction for the highest* zone which needs scanning*/for (i = pgdat->nr_zones - 1; i >= 0; i--) {-----------------------------------------------从ZONE_HIGHMEM往ZONE_NORMAL方向查找第一个不平衡状态的end_zone,即水位处于WMARK_HIGH之下的zone为止。struct zone *zone = pgdat->node_zones + i;if (!populated_zone(zone))continue;if (sc.priority != DEF_PRIORITY &&!zone_reclaimable(zone))continue;/** Do some background aging of the anon list, to give* pages a chance to be referenced before reclaiming.*/age_active_anon(zone, &sc);/** If the number of buffer_heads in the machine* exceeds the maximum allowed level and this node* has a highmem zone, force kswapd to reclaim from* it to relieve lowmem pressure.*/if (buffer_heads_over_limit && is_highmem_idx(i)) {end_zone = i;break;}if (!zone_balanced(zone, order, 0, 0)) {---------------------------------------------当前zone是否处于平衡状态,如果不平衡记录到end_zone中,然后跳出当前for循环。end_zone = i;break;} else {/** If balanced, clear the dirty and congested* flags*/clear_bit(ZONE_CONGESTED, &zone->flags);clear_bit(ZONE_DIRTY, &zone->flags);}}if (i < 0)goto out;for (i = 0; i <= end_zone; i++) {---------------------------------------------------------从ZONE_NORMAL往endzone方向进行扫描,开始页面回收。struct zone *zone = pgdat->node_zones + i;if (!populated_zone(zone))continue;/** If any zone is currently balanced then kswapd will* not call compaction as it is expected that the* necessary pages are already available.*/if (pgdat_needs_compaction &&zone_watermark_ok(zone, order,low_wmark_pages(zone),*classzone_idx, 0))-------------------------------------------------------在order大于0的情况下,pgdat_needs_compaction初始化为true;如果当前zone处于WMARK_LOW水位之上,则不需要内存规整。pgdat_needs_compaction = false;}/** If we're getting trouble reclaiming, start doing writepage* even in laptop mode.*/if (sc.priority < DEF_PRIORITY - 2)sc.may_writepage = 1;/** Now scan the zone in the dma->highmem direction, stopping* at the last zone which needs scanning.** We do this because the page allocator works in the opposite* direction. This prevents the page allocator from allocating* pages behind kswapd's direction of progress, which would* cause too much scanning of the lower zones.*/for (i = 0; i <= end_zone; i++) {---------------------------------------------------------从ZONE_NORMAL到end_zone方向,开始回收内存。struct zone *zone = pgdat->node_zones + i;if (!populated_zone(zone))continue;if (sc.priority != DEF_PRIORITY &&!zone_reclaimable(zone))continue;sc.nr_scanned = 0;nr_soft_scanned = 0;/** Call soft limit reclaim before calling shrink_zone.*/nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(zone,order, sc.gfp_mask,&nr_soft_scanned);sc.nr_reclaimed += nr_soft_reclaimed;/** There should be no need to raise the scanning* priority if enough pages are already being scanned* that that high watermark would be met at 100%* efficiency.*/if (kswapd_shrink_zone(zone, end_zone,------------------------------------------------真正扫描和页回收函数,扫描的参数和结果存放在struct scan_control中。返回true表明回收了所需要的页面,不需要再提高扫描优先级。&sc, &nr_attempted))raise_priority = false;}/** If the low watermark is met there is no need for processes* to be throttled on pfmemalloc_wait as they should not be* able to safely make forward progress. Wake them*/if (waitqueue_active(&pgdat->pfmemalloc_wait) &&pfmemalloc_watermark_ok(pgdat))wake_up_all(&pgdat->pfmemalloc_wait);/** Fragmentation may mean that the system cannot be rebalanced* for high-order allocations in all zones. If twice the* allocation size has been reclaimed and the zones are still* not balanced then recheck the watermarks at order-0 to* prevent kswapd reclaiming excessively. Assume that a* process requested a high-order can direct reclaim/compact.*/if (order && sc.nr_reclaimed >= 2UL << order)------------------------------------------如果order不为0,并且sc.nr_reclaimed即已成功回收页面数量大于等于2^order。order = sc.order = 0;--------------------------------------------------------------这里设置order为0,为了避免碎片,方式kswapd过于激进地回收页面。/* Check if kswapd should be suspending */if (try_to_freeze() || kthread_should_stop())------------------------------------------判断kswapd是否需要停止或者睡眠,如果是则退出。break;/** Compact if necessary and kswapd is reclaiming at least the* high watermark number of pages as requsted*/if (pgdat_needs_compaction && sc.nr_reclaimed > nr_attempted)-------------------------判断是否需要进行内存规整,优化内存碎片。compact_pgdat(pgdat, order);------------------------------------------------------参照内存规整章节关于compact_pgdat的解释。/** Raise priority if scanning rate is too low or there was no* progress in reclaiming pages*/if (raise_priority || !sc.nr_reclaimed)sc.priority--;--------------------------------------------------------------------由于一次扫描的页面数为total_size>>priority,所以扫描页面数量逐渐加大。当kswapd_shrink_zone返回true,即成功回收了页面,才会将raise_priority置为false。} while (sc.priority >= 1 &&!pgdat_balanced(pgdat, order, *classzone_idx));out:/** Return the order we were reclaiming at so prepare_kswapd_sleep()* makes a decision on the order we were last reclaiming at. However,* if another caller entered the allocator slow path while kswapd* was awake, order will remain at the higher level*/*classzone_idx = end_zone;return order;}
pgdat_balanced用于检查一个内存节点上的物理页面是否处于平衡状态,从最低端zone开始,直到classzone_idx。
其中classzone_idx从wake_all_kswapds()传下来。
staticboolpgdat_balanced(pg_data_t *pgdat, int order, int classzone_idx){unsigned long managed_pages = 0;unsigned long balanced_pages = 0;int i;/* Check the watermark levels */for (i = 0; i <= classzone_idx; i++) {-----------------------------------------------从低到高遍历zonestruct zone *zone = pgdat->node_zones + i;if (!populated_zone(zone))continue;managed_pages += zone->managed_pages;/** A special case here:** balance_pgdat() skips over all_unreclaimable after* DEF_PRIORITY. Effectively, it considers them balanced so* they must be considered balanced here as well!*/if (!zone_reclaimable(zone)) {balanced_pages += zone->managed_pages;continue;}if (zone_balanced(zone, order, 0, i))------------------------------------------如果这个zone的空闲页面高于WMARK_HIGH水位,那么这个zone所有管理的页面可以看作balances_pages。balanced_pages += zone->managed_pages;else if (!order)---------------------------------------------------------------在order为0,即只分配一页的情况下,当前zone低于WMARK_HIGH水位。认为当前内存节点不平衡。return false;}if (order)return balanced_pages >= (managed_pages >> 2);---------------------------------order大于0,当所有从最低端zone到classzone_idx zone中所有balanced_pages大于managed_pages的25%,认为此节点处于平衡状态。elsereturn true;-------------------------------------------------------------------此处说明所有zone都是平衡的,那么在order为0情况下,这个节点是处于平衡的。}
zone_balances用于判断zone在分配order个页面之后的空闲页面是否处于WMARK_HIGH水位之上。返回true,表示zone处于WMARK_HIGH之上。
staticboolzone_balanced(struct zone *zone, int order,unsigned long balance_gap, int classzone_idx){if (!zone_watermark_ok_safe(zone, order, high_wmark_pages(zone) +balance_gap, classzone_idx, 0))return false;if (IS_ENABLED(CONFIG_COMPACTION) && order && compaction_suitable(zone,order, 0, classzone_idx) == COMPACT_SKIPPED)return false;return true;}
为什么页面回收的路径从ZONE_NORMAL到end_zone方向?
因为伙伴系统分配页面从ZONE_HIGHMEM到ZONE_NORMAL方向,页面回收恰好和其相反。
这样有利于减少锁的争用,提高效率。页面分配和页面回收可能争用zone->lru_lock锁。
四、shrink_zone函数
kswapd_shrink_zone在进行shrink_zone操作之前,进行了一些检查工作,以确保确实需要进行页面回收。
staticboolkswapd_shrink_zone(struct zone *zone,int classzone_idx,struct scan_control *sc,unsigned long *nr_attempted){int testorder = sc->order;unsigned long balance_gap;bool lowmem_pressure;/* Reclaim above the high watermark. */sc->nr_to_reclaim = max(SWAP_CLUSTER_MAX, high_wmark_pages(zone));-----------------------计算一轮扫描最多回收页面数/** Kswapd reclaims only single pages with compaction enabled. Trying* too hard to reclaim until contiguous free pages have become* available can hurt performance by evicting too much useful data* from memory. Do not reclaim more than needed for compaction.*/if (IS_ENABLED(CONFIG_COMPACTION) && sc->order &&compaction_suitable(zone, sc->order, 0, classzone_idx)!= COMPACT_SKIPPED)testorder = 0;/** We put equal pressure on every zone, unless one zone has way too* many pages free already. The "too many pages" is defined as the* high wmark plus a "gap" where the gap is either the low* watermark or 1% of the zone, whichever is smaller.*/balance_gap = min(low_wmark_pages(zone), DIV_ROUND_UP(zone->managed_pages, KSWAPD_ZONE_BALANCE_GAP_RATIO));----------------------------balance_gap增加了水位平衡难度/** If there is no low memory pressure or the zone is balanced then no* reclaim is necessary*/lowmem_pressure = (buffer_heads_over_limit && is_highmem(zone));if (!lowmem_pressure && zone_balanced(zone, testorder,balance_gap, classzone_idx))----------------------------------------需要判断当前水位是否高于WMARK_HIGH+balance_gap,如果成立,则直接返回true。不需要进行shrink_zone回收页面。return true;shrink_zone(zone, sc, zone_idx(zone) == classzone_idx);/* Account for the number of pages attempted to reclaim */*nr_attempted += sc->nr_to_reclaim;clear_bit(ZONE_WRITEBACK, &zone->flags);/** If a zone reaches its high watermark, consider it to be no longer* congested. It's possible there are dirty pages backed by congested* BDIs but as pressure is relieved, speculatively avoid congestion* waits.*/if (zone_reclaimable(zone) &&zone_balanced(zone, testorder, 0, classzone_idx)) {clear_bit(ZONE_CONGESTED, &zone->flags);clear_bit(ZONE_DIRTY, &zone->flags);}return sc->nr_scanned >= sc->nr_to_reclaim;---------------------------------------------扫描的页面数量大于等于待回收页面数量,表示扫描了足够多的页面。}
shrink_zone()用于扫描zone中所有可回收的页面,参数:
static bool shrink_zone(struct zone *zone, struct scan_control *sc, bool is_classzone)
zone表示即将要扫描的zone,sc表示扫描控制参数,is_classzone表示当前zone是否为balance_pgdat()刚开始计算的第一个处于非平衡状态的zone。
static bool shrink_zone(struct zone *zone, struct scan_control *sc,bool is_classzone){struct reclaim_state *reclaim_state = current->reclaim_state;unsigned long nr_reclaimed, nr_scanned;bool reclaimable = false;do {struct mem_cgroup *root = sc->target_mem_cgroup;struct mem_cgroup_reclaim_cookie reclaim = {.zone = zone,.priority = sc->priority,};unsigned long zone_lru_pages = 0;struct mem_cgroup *memcg;nr_reclaimed = sc->nr_reclaimed;nr_scanned = sc->nr_scanned;memcg = mem_cgroup_iter(root, NULL, &reclaim);do {unsigned long lru_pages;unsigned long scanned;struct lruvec *lruvec;int swappiness;if (mem_cgroup_low(root, memcg)) {if (!sc->may_thrash)continue;mem_cgroup_events(memcg, MEMCG_LOW, 1);}lruvec = mem_cgroup_zone_lruvec(zone, memcg);---------------------------取当前Memory CGroup的LRU链表数据结构,swappiness = mem_cgroup_swappiness(memcg);------------------------------获取系统中的vm_swappiness参数,表示swap活跃程度。scanned = sc->nr_scanned;shrink_lruvec(lruvec, swappiness, sc, &lru_pages);----------------------扫描LRU链表的核心函数,并进行页面回收。zone_lru_pages += lru_pages;if (memcg && is_classzone)shrink_slab(sc->gfp_mask, zone_to_nid(zone),------------------------调用内存管理系统中的shrinker接口,很多子系统会注册shrinker接口来回收内存。memcg, sc->nr_scanned - scanned,lru_pages);/** Direct reclaim and kswapd have to scan all memory* cgroups to fulfill the overall scan target for the* zone.** Limit reclaim, on the other hand, only cares about* nr_to_reclaim pages to be reclaimed and it will* retry with decreasing priority if one round over the* whole hierarchy is not sufficient.*/if (!global_reclaim(sc) &&sc->nr_reclaimed >= sc->nr_to_reclaim) {mem_cgroup_iter_break(root, memcg);break;}} while ((memcg = mem_cgroup_iter(root, memcg, &reclaim)));---------------------遍历Memory CGroup。/** Shrink the slab caches in the same proportion that* the eligible LRU pages were scanned.*/if (global_reclaim(sc) && is_classzone)shrink_slab(sc->gfp_mask, zone_to_nid(zone), NULL,sc->nr_scanned - nr_scanned,zone_lru_pages);if (reclaim_state) {sc->nr_reclaimed += reclaim_state->reclaimed_slab;reclaim_state->reclaimed_slab = 0;}vmpressure(sc->gfp_mask, sc->target_mem_cgroup,sc->nr_scanned - nr_scanned,sc->nr_reclaimed - nr_reclaimed);if (sc->nr_reclaimed - nr_reclaimed)reclaimable = true;} while (should_continue_reclaim(zone, sc->nr_reclaimed - nr_reclaimed,sc->nr_scanned - nr_scanned, sc));----------------------------------通过此轮回首页面数量和扫描数量来判断,扫描工作是否需要继续。return reclaimable;}
shrink_lruvec决定从哪个LRU链表中回收多少页面。两个重要参数是swappiness和sc->priority。
首先通过get_scan_count计算每个LRU链表中有多少应该扫描的页面数,然后开始循环LRU中每个类型页面链表。核心是使用shrink_list对LRU进行扫描,找出
staticvoidshrink_lruvec(struct lruvec *lruvec, int swappiness,struct scan_control *sc, unsigned long *lru_pages){unsigned long nr[NR_LRU_LISTS];unsigned long targets[NR_LRU_LISTS];unsigned long nr_to_scan;enum lru_list lru;unsigned long nr_reclaimed = 0;unsigned long nr_to_reclaim = sc->nr_to_reclaim;struct blk_plug plug;bool scan_adjusted;get_scan_count(lruvec, swappiness, sc, nr, lru_pages);------------------------------根据swappiness、sc->priority计算LRU4个链表中应该扫描的页面数,结果放在nr[]中。/* Record the original scan target for proportional adjustments later */memcpy(targets, nr, sizeof(nr));/** Global reclaiming within direct reclaim at DEF_PRIORITY is a normal* event that can occur when there is little memory pressure e.g.* multiple streaming readers/writers. Hence, we do not abort scanning* when the requested number of pages are reclaimed when scanning at* DEF_PRIORITY on the assumption that the fact we are direct* reclaiming implies that kswapd is not keeping up and it is best to* do a batch of work at once. For memcg reclaim one check is made to* abort proportional reclaim if either the file or anon lru has already* dropped to zero at the first pass.*/scan_adjusted = (global_reclaim(sc) && !current_is_kswapd() &&sc->priority == DEF_PRIORITY);blk_start_plug(&plug);while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||nr[LRU_INACTIVE_FILE]) {---------------------------------------------跳过LRU_ACTIVE_ANON类型,因为活跃的匿名页面不能直接被回收,匿名页面需要经过老化且加入到不活跃匿名页面LRU链表才能被回收。unsigned long nr_anon, nr_file, percentage;unsigned long nr_scanned;for_each_evictable_lru(lru) {----------------------------------------------------依次遍历四种LRU链表,shrink_list函数会具体处理各种LRU链表情况。if (nr[lru]) {nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);nr[lru] -= nr_to_scan;nr_reclaimed += shrink_list(lru, nr_to_scan,lruvec, sc);}}if (nr_reclaimed < nr_to_reclaim || scan_adjusted)-------------------------------已回收的页面数目小于待回收的页面数目,继续扫描下一个LRU链表。continue;/** For kswapd and memcg, reclaim at least the number of pages* requested. Ensure that the anon and file LRUs are scanned* proportionally what was requested by get_scan_count(). We* stop reclaiming one LRU and reduce the amount scanning* proportional to the original scan target.*/nr_file = nr[LRU_INACTIVE_FILE] + nr[LRU_ACTIVE_FILE];nr_anon = nr[LRU_INACTIVE_ANON] + nr[LRU_ACTIVE_ANON];/** It's just vindictive to attack the larger once the smaller* has gone to zero. And given the way we stop scanning the* smaller below, this makes sure that we only make one nudge* towards proportionality once we've got nr_to_reclaim.*/if (!nr_file || !nr_anon)--------------------------------------------------------匿名或者文件页面已经被扫描完毕,退出循环。break;...}...}
shrink_slab是对slab缓存进行进行收缩的函数,它会遍历shrinker_list列表。
内核很多子系统注册shrinker接口,shrinker->count_objects返回当前slabcache中有多少空闲缓存;shrinker->scan_objects会扫描空闲缓存并释放。
staticunsignedlongshrink_slab(gfp_t gfp_mask, int nid,struct mem_cgroup *memcg,unsigned long nr_scanned,unsigned long nr_eligible){struct shrinker *shrinker;unsigned long freed = 0;if (memcg && !memcg_kmem_is_active(memcg))return 0;...list_for_each_entry(shrinker, &shrinker_list, list) {------------------遍历shrinker_list列表,提取shrinker。struct shrink_control sc = {.gfp_mask = gfp_mask,.nid = nid,.memcg = memcg,};if (memcg && !(shrinker->flags & SHRINKER_MEMCG_AWARE))continue;if (!(shrinker->flags & SHRINKER_NUMA_AWARE))sc.nid = 0;freed += do_shrink_slab(&sc, shrinker, nr_scanned, nr_eligible);---以shrink_control和shrinker为参数进行slab缓存收缩操作。}up_read(&shrinker_rwsem);out:cond_resched();return freed;}
下面针对不同类型页面进行不同的处理,同时需要考虑是否打开SWAP分区的情况。在不活跃链表较少(即low)情况下,进行活跃链表的收缩。
staticunsignedlongshrink_list(enum lru_list lru, unsignedlong nr_to_scan,struct lruvec *lruvec, struct scan_control *sc){if (is_active_lru(lru)) {-----------------------------------------lru链表为LRU_ACTIVE_ANON、LRU_ACTIVE_FILE两种情况if (inactive_list_is_low(lruvec, lru))------------------------如果不活跃文件或者匿名页面为低,则收缩活跃列表。shrink_active_list(nr_to_scan, lruvec, sc, lru);return 0;}return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);---------收缩LRU的LRU_INACTIVE_ANON和LRU_INACTIVE_FILE两种页面}
下面两章节针对活跃和不活跃链表进行收缩处理。
五、shrink_active_list函数
shrink_active_list看看有哪些活跃页面可以迁移到不活跃页面链表中。
staticvoidshrink_active_list(unsignedlong nr_to_scan,struct lruvec *lruvec,struct scan_control *sc,enum lru_list lru){unsigned long nr_taken;unsigned long nr_scanned;unsigned long vm_flags;LIST_HEAD(l_hold); /* The pages which were snipped off */LIST_HEAD(l_active);LIST_HEAD(l_inactive);----------------------------------------------定义3个临时链表l_hold、l_active、l_inactive。struct page *page;struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;unsigned long nr_rotated = 0;isolate_mode_t isolate_mode = 0;int file = is_file_lru(lru);struct zone *zone = lruvec_zone(lruvec);lru_add_drain();if (!sc->may_unmap)isolate_mode |= ISOLATE_UNMAPPED;if (!sc->may_writepage)isolate_mode |= ISOLATE_CLEAN;---------------------------------设置isolate_modespin_lock_irq(&zone->lru_lock);nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &l_hold,&nr_scanned, sc, isolate_mode, lru);--------------通过isolate_mode限定将哪些页面从LRU链表移动到l_hold中。if (global_reclaim(sc))__mod_zone_page_state(zone, NR_PAGES_SCANNED, nr_scanned);reclaim_stat->recent_scanned[file] += nr_taken;__count_zone_vm_events(PGREFILL, zone, nr_scanned);__mod_zone_page_state(zone, NR_LRU_BASE + lru, -nr_taken);__mod_zone_page_state(zone, NR_ISOLATED_ANON + file, nr_taken);spin_unlock_irq(&zone->lru_lock);while (!list_empty(&l_hold)) {------------------------------------扫描临时l_hold链表中的页面,有些页面会添加到l_active中,有些会添加到l_inactive中,剩下部分可以直接释放。cond_resched();page = lru_to_page(&l_hold);list_del(&page->lru);-----------------------------------------将page从当前LRU链表l_hold中移除if (unlikely(!page_evictable(page))) {------------------------如果页面不可回收,则放回不可回收LRU链表中。继续下一个页面处理。putback_lru_page(page);continue;}if (unlikely(buffer_heads_over_limit)) {if (page_has_private(page) && trylock_page(page)) {if (page_has_private(page))try_to_release_page(page, 0);unlock_page(page);}}if (page_referenced(page, 0, sc->target_mem_cgroup,&vm_flags)) {nr_rotated += hpage_nr_pages(page);/** Identify referenced, file-backed active pages and* give them one more trip around the active list. So* that executable code get better chances to stay in* memory under moderate memory pressure. Anon pages* are not likely to be evicted by use-once streaming* IO, plus JVM can create lots of anon VM_EXEC pages,* so we ignore them here.*/if ((vm_flags & VM_EXEC) && page_is_file_cache(page)) {---可执行page cache页面保留在活跃链表中。list_add(&page->lru, &l_active);----------------------将page移入l_active中。continue;}}ClearPageActive(page); /* we are de-activating */list_add(&page->lru, &l_inactive);---------------------------将page移入l_inactive中。}/** Move pages back to the lru list.*/spin_lock_irq(&zone->lru_lock);/** Count referenced pages from currently used mappings as rotated,* even though only some of them are actually re-activated. This* helps balance scan pressure between file and anonymous pages in* get_scan_count.*/reclaim_stat->recent_rotated[file] += nr_rotated;move_active_pages_to_lru(lruvec, &l_active, &l_hold, lru);move_active_pages_to_lru(lruvec, &l_inactive, &l_hold, lru - LRU_ACTIVE);----将l_active和l_inactive移入对应的LRU链表中。__mod_zone_page_state(zone, NR_ISOLATED_ANON + file, -nr_taken);spin_unlock_irq(&zone->lru_lock);mem_cgroup_uncharge_list(&l_hold);free_hot_cold_page_list(&l_hold, true);---------------------------------l_hold中的链表是提出l_active和l_inactive剩下来部分,然后进行释放。}
isolate_lru_pages用于分离LRU链表中页面的函数。
nr_to_scan表示在这个链表中扫描页面的个数,lruvec是LRU链表集合,dst是临时存放的页面链表,nv_scanned是已经扫描的页面个数。
staticunsignedlongisolate_lru_pages(unsignedlong nr_to_scan,struct lruvec *lruvec, struct list_head *dst,unsigned long *nr_scanned, struct scan_control *sc,isolate_mode_t mode, enum lru_list lru){struct list_head *src = &lruvec->lists[lru];unsigned long nr_taken = 0;unsigned long scan;for (scan = 0; scan < nr_to_scan && !list_empty(src); scan++) {struct page *page;int nr_pages;page = lru_to_page(src);prefetchw_prev_lru_page(page, src, flags);VM_BUG_ON_PAGE(!PageLRU(page), page);switch (__isolate_lru_page(page, mode)) {----------------调用此函数来分离单个页面,0表示分离成功,并把页面迁移到dst临时链表中。case 0:nr_pages = hpage_nr_pages(page);mem_cgroup_update_lru_size(lruvec, lru, -nr_pages);list_move(&page->lru, dst);nr_taken += nr_pages;break;case -EBUSY:/* else it is being freed elsewhere */list_move(&page->lru, src);continue;default:BUG();}}*nr_scanned = scan;trace_mm_vmscan_lru_isolate(sc->order, nr_to_scan, scan,nr_taken, mode, is_file_lru(lru));return nr_taken;}
六、shrink_inactive_list函数
shrink_inactive_list函数扫描不活跃页面链表并且回收页面。
static noinline_for_stack unsignedlongshrink_inactive_list(unsignedlong nr_to_scan, struct lruvec *lruvec,struct scan_control *sc, enum lru_list lru){LIST_HEAD(page_list);unsigned long nr_scanned;unsigned long nr_reclaimed = 0;unsigned long nr_taken;unsigned long nr_dirty = 0;unsigned long nr_congested = 0;unsigned long nr_unqueued_dirty = 0;unsigned long nr_writeback = 0;unsigned long nr_immediate = 0;isolate_mode_t isolate_mode = 0;int file = is_file_lru(lru);struct zone *zone = lruvec_zone(lruvec);struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;while (unlikely(too_many_isolated(zone, file, sc))) {congestion_wait(BLK_RW_ASYNC, HZ/10);/* We are about to die and free our memory. Return now. */if (fatal_signal_pending(current))return SWAP_CLUSTER_MAX;}lru_add_drain();if (!sc->may_unmap)isolate_mode |= ISOLATE_UNMAPPED;if (!sc->may_writepage)isolate_mode |= ISOLATE_CLEAN;spin_lock_irq(&zone->lru_lock);nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list,&nr_scanned, sc, isolate_mode, lru);--------------按照isolate_mode把不活跃页面分离到临时链表page_list中。__mod_zone_page_state(zone, NR_LRU_BASE + lru, -nr_taken);__mod_zone_page_state(zone, NR_ISOLATED_ANON + file, nr_taken);if (global_reclaim(sc)) {__mod_zone_page_state(zone, NR_PAGES_SCANNED, nr_scanned);if (current_is_kswapd())__count_zone_vm_events(PGSCAN_KSWAPD, zone, nr_scanned);else__count_zone_vm_events(PGSCAN_DIRECT, zone, nr_scanned);}spin_unlock_irq(&zone->lru_lock);if (nr_taken == 0)return 0;nr_reclaimed = shrink_page_list(&page_list, zone, sc, TTU_UNMAP,&nr_dirty, &nr_unqueued_dirty, &nr_congested,&nr_writeback, &nr_immediate,false);------------------------------------------------扫描page_list链表页面并返回已回收的页面数量。spin_lock_irq(&zone->lru_lock);reclaim_stat->recent_scanned[file] += nr_taken;if (global_reclaim(sc)) {if (current_is_kswapd())__count_zone_vm_events(PGSTEAL_KSWAPD, zone,nr_reclaimed);else__count_zone_vm_events(PGSTEAL_DIRECT, zone,nr_reclaimed);}putback_inactive_pages(lruvec, &page_list);-----------------------将满足条件的页面放回lru链表中__mod_zone_page_state(zone, NR_ISOLATED_ANON + file, -nr_taken);spin_unlock_irq(&zone->lru_lock);mem_cgroup_uncharge_list(&page_list);free_hot_cold_page_list(&page_list, true);------------------------page_list剩下部分的页面将被释放。/** If reclaim is isolating dirty pages under writeback, it implies* that the long-lived page allocation rate is exceeding the page* laundering rate. Either the global limits are not being effective* at throttling processes due to the page distribution throughout* zones or there is heavy usage of a slow backing device. The* only option is to throttle from reclaim context which is not ideal* as there is no guarantee the dirtying process is throttled in the* same way balance_dirty_pages() manages.** Once a zone is flagged ZONE_WRITEBACK, kswapd will count the number* of pages under pages flagged for immediate reclaim and stall if any* are encountered in the nr_immediate check below.*/if (nr_writeback && nr_writeback == nr_taken)set_bit(ZONE_WRITEBACK, &zone->flags);/** memcg will stall in page writeback so only consider forcibly* stalling for global reclaim*/if (global_reclaim(sc)) {/** Tag a zone as congested if all the dirty pages scanned were* backed by a congested BDI and wait_iff_congested will stall.*/if (nr_dirty && nr_dirty == nr_congested)set_bit(ZONE_CONGESTED, &zone->flags);/** If dirty pages are scanned that are not queued for IO, it* implies that flushers are not keeping up. In this case, flag* the zone ZONE_DIRTY and kswapd will start writing pages from* reclaim context.*/if (nr_unqueued_dirty == nr_taken)set_bit(ZONE_DIRTY, &zone->flags);/** If kswapd scans pages marked marked for immediate* reclaim and under writeback (nr_immediate), it implies* that pages are cycling through the LRU faster than* they are written so also forcibly stall.*/if (nr_immediate && current_may_throttle())congestion_wait(BLK_RW_ASYNC, HZ/10);}/** Stall direct reclaim for IO completions if underlying BDIs or zone* is congested. Allow kswapd to continue until it starts encountering* unqueued dirty pages or cycling through the LRU too quickly.*/if (!sc->hibernation_mode && !current_is_kswapd() &¤t_may_throttle())wait_iff_congested(zone, BLK_RW_ASYNC, HZ/10);trace_mm_vmscan_lru_shrink_inactive(zone->zone_pgdat->node_id,zone_idx(zone),nr_scanned, nr_reclaimed,sc->priority,trace_shrink_flags(file));return nr_reclaimed;}
七、跟踪LRU活动情况
如果在LRU链表中,页面被其他进程释放了,那么LRU链表如何知道页面已经被释放了?
LRU是一个双向链表,如何保护链表中的成员不被其它内核路径释放是在设计页面回收功能需要考虑的并发问题。
struct page数据结构中的__count引用计数起到重要作用。
以shrink_active_list()中分离页面到临时链表l_hold为例。
shrink_active_list()
->isolate_lru_pages()
->page = lru_to_page()
->get_page_unless_zero(page)
->ClearPageLRU(page)
这样从LRU链表中摘取一个页面时,就对该页page->_count引用计数减1。
把分离好的页面放回LRU链表的情况如下:
shrink_active_list()
->move_active_pages_to_lru()
->list_move(&page->lru, &lruvec->lists[lru])
->put_page_testzero(page)
这里对page->_count计数减1,如果减1等于0,说明这个page已经被其他进程释放,清除PG_LRU并从LRU链表删除该页。
八、Refault Distance算法
在Linux内核的页面回收机制中,Refault Distance算法是优化页面高速缓存(page cache)回收策略的关键,旨在更精准地识别“活跃”页面,避免频繁回收后又立即重新加载的“颠簸”(thrashing)现象。该算法由内核专家Johannes Weiner在Linux 3.5版本中引入,目前仅针对页面高速缓存类型的页面。
8.1 核心概念
要理解Refault Distance算法,需先明确以下几个关键时间点和概念:
Fault:第一次访问页面高速缓存中的页面,此时页面被加载到内存并加入LRU链表。
Eviction:页面因内存回收被移出LRU链表并释放的时刻,记为E。
Refault:页面被回收后,第二次访问该页面的时刻,记为R。此时页面需重新从存储介质加载到内存。
Refault Distance:在时间区间
[E, R]内,LRU链表中移动的页面总数(包括从inactive链表回收的页面和从inactive升级到active的页面)。
8.2 算法原理
Refault Distance算法的核心目标是:当页面发生Refault时,决定将其放入活跃LRU链表(active list)还是不活跃LRU链表(inactive list)。
若页面在被回收后很快再次被访问(Refault Distance较小),说明该页面属于“工作集”(working set),应放入active链表以避免再次被回收;若Refault Distance较大,则说明页面可能不那么活跃,放入inactive链表更合适。
算法通过以下推导确定决策逻辑:
假设页面想一直保持在LRU链表中,那么从第一次Fault到Refault的总“距离”(read_distance)不应超过内存中LRU链表的总长度(即NR_inactive + NR_active,其中NR_inactive是inactive链表长度,NR_active是active链表长度)。
read_distance的计算公式为:
read_distance = NR_inactive + (R - E)其中(R - E)即Refault Distance(时间区间内移动的页面数)。
若要求页面不被踢出LRU链表,则需满足:
NR_inactive + Refault Distance ≤ NR_inactive + NR_active化简后得到关键判断条件:
Refault Distance ≤ NR_active这意味着:当Refault Distance小于等于active链表的长度时,页面应放入active链表;否则放入inactive链表。
8.3 源码实现
Refault Distance算法的核心逻辑在mm/workingset.c中实现,关键步骤:
记录Eviction信息:当页面从inactive链表回收时,内核会在对应文件的地址空间(address_space)中留下“影子条目”(shadow entry),记录该页面被回收时的“年龄”(eviction timestamp)。
计算Refault Distance:当页面发生Refault时,内核通过影子条目获取该页面上次被回收的时间戳(eviction),并结合当前的“非居民年龄”(nonresident_age)计算Refault Distance:
refault = atomic_long_read(&eviction_lruvec->nonresident_age);refault_distance = (refault - eviction) & EVICTION_MASK;其中
EVICTION_MASK用于处理时间戳溢出问题。决策LRU链表:比较Refault Distance与active链表的长度,决定页面的去向:
若
refault_distance ≤ NR_active,将页面加入active链表;否则,加入inactive链表。
Refault Distance算法通过量化页面的“活跃程度”,解决了传统LRU算法中“频繁访问的页面因短暂不活跃被回收”的问题。例如,在文件服务器、数据库等场景中,工作集页面可能因内存压力被暂时回收,但Refault Distance能快速识别并将其重新放回active链表,从而大幅减少磁盘I/O,提升系统性能。
Linux内存管理系列文章:
原作者:ArnoldLu
原文地址:
https://www.cnblogs.com/arnoldlu/p/8335487.html
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux攻击型安全工具:一图看懂
- 紧急提醒:Linux服务器正遭疯狂攻击!8招自救指南,跟着做立刻安全
- 五分钟手把手带你在Linux上部署捕鱼达人在线小游戏
- 企业级运维必备技能:Linux硬盘在线扩容和LVM逻辑卷配置
- 内核传奇时刻!Linux 7.0 震撼发布:谷歌百万美元陈年 Bug 终结,Rust 正式转正,这次真的不一样!
- 零基础也能学会:一篇文章带你入门 Linux
- CLion嵌入式linux开发
- Linux 终端也能“图形化”:APTUI 软件管理工具来了
- python学习【140】真的热爱,是人类前进的动力:从Python字典看技术热爱的本质
- AI+Python爬取央行人民币汇率中间价
