在很多实际业务中,经常会遇到这样一种 Excel 数据统计问题:
如果用 Excel 手工统计,不仅麻烦,还容易出错。
今天用 Python + Pandas,只需要 20 行代码,就可以自动完成整个统计流程。
一、问题示例
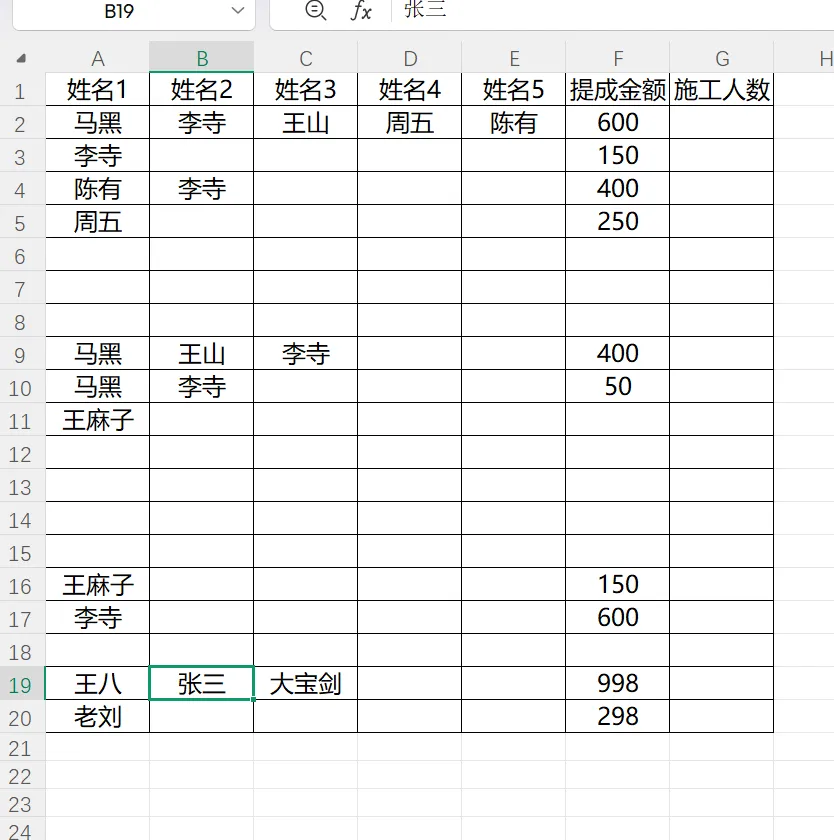
假设有这样一份 Excel 数据:
统计规则:
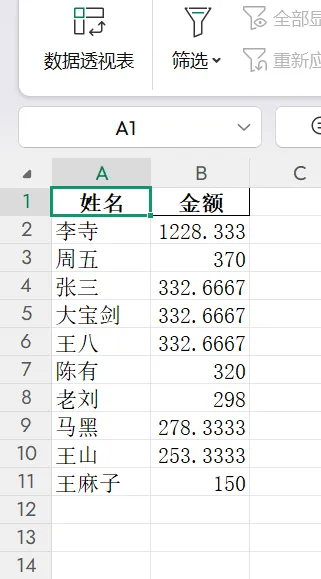
最终结果:
二、解决思路
整个统计过程可以拆成 4 步:
1 读取 Excel
使用 Pandas 读取数据。
df = pd.read_excel("20260316.xlsx")
2 自动识别姓名列
Excel 中姓名列可能是:
姓名1姓名2姓名3...
我们可以自动获取:
name_cols = df.filter(like="姓名").columns
这样无论有多少个姓名列,程序都能自动识别。
3 计算每行平均提成
核心逻辑:
例如:
马黑 李寺 王山提成:600
人数:3
每人:
600 / 3 = 200
4 汇总所有人金额
使用 Python 字典累计:
姓名 -> 总金额
例如:
{ "李寺":1228.33, "周五":370}
三、完整代码(20行版)
import pandas as pd# 读取Exceldf = pd.read_excel("20260316.xlsx")# 自动识别姓名列name_cols = df.filter(like="姓名").columnsresult = {}for _, r in df.iterrows():if pd.isna(r["提成金额"]):continue names = [str(x).strip() for x in r[name_cols]if pd.notna(x) and str(x).strip() notin ["", "0"]]ifnot names:continue share = r["提成金额"] / len(names)for n in names: result[n] = result.get(n, 0) + shareout = pd.DataFrame(result.items(), columns=["姓名","金额"])out["金额"] = out["金额"].apply(lambda x: int(x) if x==int(x) else round(x,6))out = out.sort_values("金额", ascending=False)print(out)out.to_excel("提成统计结果.xlsx", index=False)
四、代码亮点
1 自动识别姓名列
无需写死:
姓名1 姓名2 姓名3 ...
代码自动处理。
2 自动过滤脏数据
程序自动忽略:
避免统计错误。
3 自动格式化金额
如果金额是整数:
370.000000
自动变为:
370
小数则保留 6 位。
4 自动生成结果 Excel
运行后会生成:
提成统计结果.xlsx
直接可用。
五、运行方式
安装依赖:
pip install pandas openpyxl
运行脚本:
python ticheng.py
即可生成统计结果。
六、性能说明
这段代码可以轻松处理:
对于日常业务统计完全足够。
用 Python 处理 Excel 数据的优势:
一个原本需要 几十分钟甚至几小时的手工统计,现在只需要:
20 行 Python 代码 + 1 秒运行时间。
获取和交流
需要本章或其他文章的源码和数据的同学,关注+三连,在对应文章下评论“6666“,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
