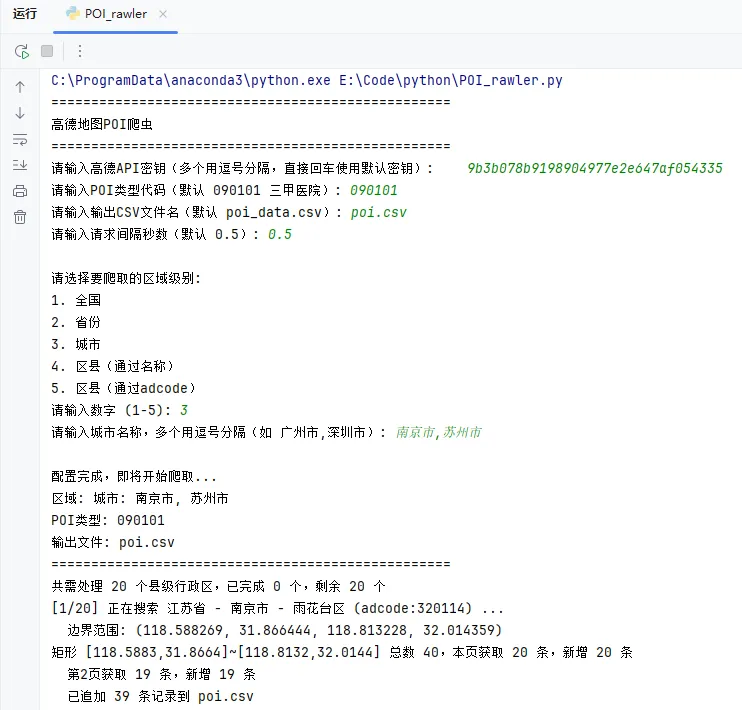
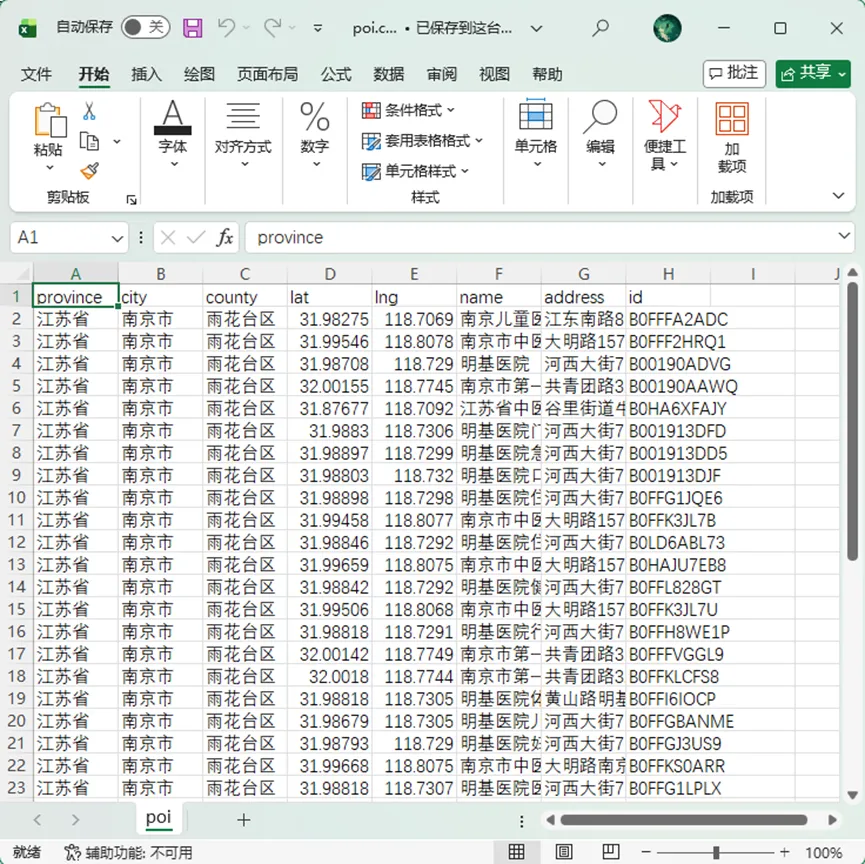
import requestsimport timeimport csvimport jsonimport osimport argparsefrom typing import List, Dict, Tuple, Optional, Set, Union# ================== 默认配置 ==================DEFAULT_KEYS = ["bc70789750b08a935ef862eeca703582", # 请替换为你的有效密钥]DEFAULT_INTERVAL = 0.5 # 请求间隔(秒)DEFAULT_OUTPUT = "poi_data.csv"DEFAULT_PROGRESS = "progress.json"DEFAULT_PAGE_SIZE = 20DEFAULT_MAX_COUNT_THRESHOLD = 200 # 超过此值切分矩形DEFAULT_POI_TYPES = "090101"# 默认三甲医院DISTRICT_API = "https://restapi.amap.com/v3/config/district"PLACE_API = "https://restapi.amap.com/v3/place/polygon"# =============================================class RegionSpec:"""区域规格:支持全国、省份、城市、区县""" def __init__(self, level: str, names: List[str] = None, adcodes: List[str] = None):""" :param level: 'country', 'province', 'city', 'county' :param names: 名称列表(与 adcodes 二选一) :param adcodes: adcode 列表(与 names 二选一) """ self.level = level self.names = names or [] self.adcodes = adcodes or [] @classmethod def country(cls):return cls('country') @classmethod def from_provinces(cls, names: List[str]):return cls('province', names=names) @classmethod def from_cities(cls, names: List[str]):return cls('city', names=names) @classmethod def from_counties(cls, names: List[str] = None, adcodes: List[str] = None):return cls('county', names=names, adcodes=adcodes) def __str__(self):if self.level == 'country':return"全国"elif self.level == 'province':return f"省份: {', '.join(self.names)}"elif self.level == 'city':return f"城市: {', '.join(self.names)}"else:if self.names:return f"区县: {', '.join(self.names)}"else:return f"区县(adcode): {', '.join(self.adcodes)}"class AmapPOICrawler: def __init__(self, keys: List[str] = None, poi_types: str = DEFAULT_POI_TYPES, output_file: str = DEFAULT_OUTPUT, progress_file: str = DEFAULT_PROGRESS, request_interval: float = DEFAULT_INTERVAL, page_size: int = DEFAULT_PAGE_SIZE, max_count_threshold: int = DEFAULT_MAX_COUNT_THRESHOLD):""" :param keys: 高德 API 密钥列表 :param poi_types: POI 类型代码(如 200300 公共厕所) :param output_file: 输出 CSV 文件路径 :param progress_file: 进度记录文件 :param request_interval: 请求间隔(秒) :param page_size: 每页大小(最大20) :param max_count_threshold: 矩形内 POI 数量阈值,超过则切分 """ self.keys = keys or DEFAULT_KEYSif not self.keys or self.keys[0] == "你的高德API密钥1": raise ValueError("请提供有效的高德 API 密钥") self.poi_types = poi_types self.output_file = output_file self.progress_file = progress_file self.interval = request_interval self.page_size = page_size self.threshold = max_count_threshold self.current_key_index = 0 self.total_requests = 0 self.seen_ids = set() # 全局去重 ID 集合 self._load_existing_ids() # 从已有 CSV 加载 ID# ---------- 请求封装 ---------- def _get_next_key(self):"""轮换到下一个 API 密钥""" self.current_key_index = (self.current_key_index + 1) % len(self.keys)return self.keys[self.current_key_index] def _request(self, method: str, url: str, params: dict, max_retries=5, base_wait=5) -> Optional[dict]:"""带密钥切换和重试的请求"""for attempt in range(max_retries): try: params['key'] = self.keys[self.current_key_index] time.sleep(self.interval) resp = requests.request(method, url, params=params, timeout=10) self.total_requests += 1 data = resp.json()if data.get('status') == '1':return data info = data.get('info', '')if'DAILY_QUERY_OVER_LIMIT'in info or 'INVALID_USER_KEY'in info:print(f" 密钥 {self.keys[self.current_key_index]} 配额超限或无效,切换密钥") self._get_next_key() time.sleep(base_wait)continueelse:print(f" API错误: {info}")return data except Exception as e:print(f" 请求异常: {e},切换密钥") self._get_next_key() time.sleep(base_wait)continueprint(" 超过最大重试次数,请检查网络或密钥")return None# ---------- 行政区划相关 ---------- def fetch_all_counties(self) -> List[Dict[str, str]]:"""获取全国所有县级行政区""" params = {"keywords": "中国","subdistrict": "3","extensions": "base" } data = self._request('GET', DISTRICT_API, params)if not data or data["status"] != "1": raise Exception(f"获取行政区划失败: {data.get('info') if data else '无响应'}") country = data["districts"][0] provinces = country["districts"] county_list = []for p in provinces: province = p["name"] cities = p["districts"]for c in cities: city = c["name"] counties = c.get("districts", [])if not counties: # 直筒子市 county_list.append({"province": province,"city": city,"county": city,"adcode": c["adcode"] })else:for county in counties: county_list.append({"province": province,"city": city,"county": county["name"],"adcode": county["adcode"] })return county_list def fetch_counties_by_names(self, level: str, names: List[str]) -> List[Dict[str, str]]:""" 根据名称列表获取县级行政区 :param level: 'province', 'city', 'county' :param names: 名称列表 :return: 包含 province, city, county, adcode 的字典列表 """# 先获取全国所有县级数据 all_counties = self.fetch_all_counties() result = []if level == 'province': result = [c for c in all_counties if c['province'] in names]elif level == 'city': result = [c for c in all_counties if c['city'] in names]elif level == 'county': result = [c for c in all_counties if c['county'] in names]else: raise ValueError(f"不支持的 level: {level}")return result def fetch_counties_by_adcodes(self, adcodes: List[str]) -> List[Dict[str, str]]:"""根据 adcode 列表获取县级行政区""" all_counties = self.fetch_all_counties()return [c for c in all_counties if c['adcode'] in adcodes] def get_county_boundary(self, adcode: str) -> Optional[Tuple[float, float, float, float]]:"""获取县级行政区的外包矩形""" params = {"keywords": adcode,"subdistrict": "0","extensions": "all" } data = self._request('GET', DISTRICT_API, params)if not data or data["status"] != "1" or not data["districts"]:print(f" 获取边界失败 (adcode:{adcode}): {data.get('info') if data else '无响应'}")return None district = data["districts"][0] polyline = district.get("polyline")if not polyline:print(f" 该区县无边界数据 (adcode:{adcode})")return None min_lng, min_lat = float('inf'), float('inf') max_lng, max_lat = float('-inf'), float('-inf') polygons = polyline.split('|')for polygon in polygons: points = polygon.split(';')for point in points:if not point:continue lng, lat = map(float, point.split(',')) min_lng = min(min_lng, lng) min_lat = min(min_lat, lat) max_lng = max(max_lng, lng) max_lat = max(max_lat, lat)if min_lng == float('inf'):return Nonereturn (min_lng, min_lat, max_lng, max_lat)# ---------- 递归爬取 ---------- @staticmethod def _split_rectangle(rect: Tuple[float, float, float, float]) -> List[Tuple[float, float, float, float]]:"""将矩形切分为4个小矩形""" lng1, lat1, lng2, lat2 = rect mid_lng = (lng1 + lng2) / 2 mid_lat = (lat1 + lat2) / 2return [ (lng1, lat1, mid_lng, mid_lat), (mid_lng, lat1, lng2, mid_lat), (lng1, mid_lat, mid_lng, lat2), (mid_lng, mid_lat, lng2, lat2) ] def _process_rectangle(self, rect: Tuple[float, float, float, float], province: str, city: str, county: str, depth: int = 0) -> List[Dict]:""" 递归处理单个矩形,返回该矩形内所有未在 seen_ids 中的 POI。 """ indent = " " * depth lng1, lat1, lng2, lat2 = rect polygon_param = f"{lng1},{lat1};{lng2},{lat1};{lng2},{lat2};{lng1},{lat2};{lng1},{lat1}"# 请求第一页 params = {"types": self.poi_types,"polygon": polygon_param,"offset": self.page_size,"page": 1,"output": "JSON" } data = self._request('GET', PLACE_API, params)if not data or data["status"] != "1":print(f"{indent}矩形API错误,跳过")return [] total_count = int(data.get("count", 0))if total_count == 0:print(f"{indent}矩形无POI")return [] first_page = data.get("pois", [])# 补充行政区信息for poi in first_page: poi["province"] = province poi["city"] = city poi["county"] = county# 去重 new_pois = [p for p in first_page if p['id'] not in self.seen_ids]for p in new_pois: self.seen_ids.add(p['id']) result = new_poisprint(f"{indent}矩形 [{lng1:.4f},{lat1:.4f}]~[{lng2:.4f},{lat2:.4f}] 总数 {total_count},本页获取 {len(first_page)} 条,新增 {len(new_pois)} 条")if total_count > self.threshold:# 超过阈值,切分后递归print(f"{indent} 总数超过阈值({self.threshold}),切分...") sub_rects = self._split_rectangle(rect)for sub_rect in sub_rects: sub_pois = self._process_rectangle(sub_rect, province, city, county, depth + 1) result.extend(sub_pois)else:# 总数在阈值内,继续翻页获取剩余数据if total_count > self.page_size: pages = (total_count + self.page_size - 1) // self.page_sizefor page in range(2, pages + 1): params['page'] = page data = self._request('GET', PLACE_API, params)if not data or data["status"] != "1":print(f"{indent} 翻页失败,停止")break pois_page = data.get("pois", [])if not pois_page:breakfor poi in pois_page: poi["province"] = province poi["city"] = city poi["county"] = county new = [p for p in pois_page if p['id'] not in self.seen_ids]for p in new: self.seen_ids.add(p['id']) result.extend(new)print(f"{indent} 第{page}页获取 {len(pois_page)} 条,新增 {len(new)} 条")if len(pois_page) < self.page_size:breakreturn result# ---------- 进度和存储 ---------- def _load_existing_ids(self):"""从已有CSV中加载所有POI的ID"""if not os.path.exists(self.output_file):return with open(self.output_file, 'r', encoding='utf-8-sig') as f: reader = csv.reader(f) header = next(reader, None)if not header:return try: id_idx = header.index('id') except ValueError:print("警告:CSV文件中没有id列,无法加载历史ID,可能导致重复。")returnfor row in reader:if len(row) > id_idx: self.seen_ids.add(row[id_idx])print(f"已加载 {len(self.seen_ids)} 个历史POI ID") def _save_progress(self, adcode: str):"""记录已完成的adcode到进度文件""" completed = set()if os.path.exists(self.progress_file): with open(self.progress_file, 'r', encoding='utf-8') as f: completed = set(json.load(f)) completed.add(adcode) with open(self.progress_file, 'w', encoding='utf-8') as f: json.dump(list(completed), f) def _load_progress(self) -> set:"""加载已完成的adcode集合"""if os.path.exists(self.progress_file): with open(self.progress_file, 'r', encoding='utf-8') as f:returnset(json.load(f))returnset() def _append_to_csv(self, pois: List[Dict]):"""将POI列表追加到CSV文件""" file_exists = os.path.exists(self.output_file) with open(self.output_file, "a", encoding="utf-8-sig", newline="") as f: writer = csv.writer(f)if not file_exists: writer.writerow(["province", "city", "county", "lat", "lng", "name", "address", "id"])for r in pois: loc = r.get("location", "")if loc: lng, lat = loc.split(",")else: lng, lat = "", "" writer.writerow([ r["province"], r.get("city", ""), r.get("county", ""), lat, lng, r.get("name", ""), r.get("address", ""), r.get("id", "") ])# ---------- 对外接口 ---------- def crawl(self, region_spec: Union[RegionSpec, str, List[Dict]]):""" 主爬取方法 :param region_spec: 区域规格,可以是 RegionSpec 对象,或 '全国' 字符串,或直接传入行政区列表(如从 fetch_all_counties 获得) """if isinstance(region_spec, str) and region_spec == "全国": counties = self.fetch_all_counties()elif isinstance(region_spec, RegionSpec):if region_spec.level == 'country': counties = self.fetch_all_counties()elif region_spec.level in ('province', 'city', 'county') and region_spec.names: counties = self.fetch_counties_by_names(region_spec.level, region_spec.names)elif region_spec.level == 'county' and region_spec.adcodes: counties = self.fetch_counties_by_adcodes(region_spec.adcodes)else: raise ValueError("无效的 RegionSpec")elif isinstance(region_spec, list): counties = region_spec # 直接使用传入的列表else: raise TypeError("region_spec 类型不支持")# 过滤已完成的 completed = self._load_progress() remaining = [c for c in counties if c['adcode'] not in completed]print(f"共需处理 {len(counties)} 个县级行政区,已完成 {len(completed)} 个,剩余 {len(remaining)} 个") total_counties = len(remaining)for idx, item in enumerate(remaining, 1): province = item["province"] city = item["city"] county = item["county"] adcode = item["adcode"]print(f"[{idx}/{total_counties}] 正在搜索 {province} - {city} - {county} (adcode:{adcode}) ...") bounds = self.get_county_boundary(adcode)if not bounds:print(f" 无法获取边界,跳过该区县") self._save_progress(adcode) # 标记为已完成(无数据)continueprint(f" 边界范围: {bounds}") pois = self._process_rectangle(bounds, province, city, county)if pois: self._append_to_csv(pois)print(f" 已追加 {len(pois)} 条记录到 {self.output_file}")else:print(f" 该县未获取到POI") self._save_progress(adcode)if idx % 10 == 0:print(f"\n进度:已完成 {idx} 个县,累计写入 {self.output_file}\n")print(f"\n完成!所有指定区域处理完毕。")print(f"总API请求次数: {self.total_requests}")def interactive_input():"""交互式输入,返回 RegionSpec 对象和爬虫参数"""print("=" * 50)print("高德地图POI爬虫")print("=" * 50)# API密钥 keys_input = input("请输入高德API密钥(多个用逗号分隔,直接回车使用默认密钥): ").strip()if keys_input: keys = [k.strip() for k in keys_input.split(',') if k.strip()]else: keys = DEFAULT_KEYSprint(f"使用默认密钥: {keys[0]}...")# POI类型 poi_types = input(f"请输入POI类型代码(默认 {DEFAULT_POI_TYPES} 三甲医院): ").strip()if not poi_types: poi_types = DEFAULT_POI_TYPES# 输出文件 output_file = input(f"请输入输出CSV文件名(默认 {DEFAULT_OUTPUT}): ").strip()if not output_file: output_file = DEFAULT_OUTPUT# 请求间隔 interval_str = input(f"请输入请求间隔秒数(默认 {DEFAULT_INTERVAL}): ").strip() interval = float(interval_str) if interval_str else DEFAULT_INTERVAL# 区域选择print("\n请选择要爬取的区域级别:")print("1. 全国")print("2. 省份")print("3. 城市")print("4. 区县(通过名称)")print("5. 区县(通过adcode)") choice = input("请输入数字 (1-5): ").strip() region = Noneif choice == '1': region = RegionSpec.country()elif choice == '2': names_input = input("请输入省份名称,多个用逗号分隔(如 北京市,上海市): ").strip()if not names_input:print("未输入省份名称,退出")return None names = [n.strip() for n in names_input.split(',') if n.strip()] region = RegionSpec.from_provinces(names)elif choice == '3': names_input = input("请输入城市名称,多个用逗号分隔(如 广州市,深圳市): ").strip()if not names_input:print("未输入城市名称,退出")return None names = [n.strip() for n in names_input.split(',') if n.strip()] region = RegionSpec.from_cities(names)elif choice == '4': names_input = input("请输入区县名称,多个用逗号分隔(如 朝阳区,海淀区): ").strip()if not names_input:print("未输入区县名称,退出")return None names = [n.strip() for n in names_input.split(',') if n.strip()] region = RegionSpec.from_counties(names=names)elif choice == '5': adcodes_input = input("请输入区县adcode,多个用逗号分隔(如 110105,110108): ").strip()if not adcodes_input:print("未输入adcode,退出")return None adcodes = [a.strip() for a in adcodes_input.split(',') if a.strip()] region = RegionSpec.from_counties(adcodes=adcodes)else:print("无效选择,退出")return Noneprint("\n配置完成,即将开始爬取...")print(f"区域: {region}")print(f"POI类型: {poi_types}")print(f"输出文件: {output_file}")print("=" * 50)return {'keys': keys,'poi_types': poi_types,'output_file': output_file,'interval': interval,'region': region }def main():# 尝试解析命令行参数,如果无参数则进入交互模式 parser = argparse.ArgumentParser(description="高德地图POI爬虫(多边形搜索)") parser.add_argument("--keys", nargs='+', help="API密钥列表") parser.add_argument("--types", help="POI类型代码,默认090101(三甲医院)") parser.add_argument("--output", help="输出CSV文件路径") parser.add_argument("--progress", default=DEFAULT_PROGRESS, help="进度记录文件") parser.add_argument("--interval", type=float, help="请求间隔(秒)") parser.add_argument("--threshold", type=int, default=DEFAULT_MAX_COUNT_THRESHOLD, help="矩形切分阈值") parser.add_argument("--region", choices=["全国", "省份", "城市", "区县"], help="区域级别") parser.add_argument("--names", nargs='+', help="区域名称列表(与区域级别配合)") parser.add_argument("--adcodes", nargs='+', help="区县adcode列表(与区域级别=区县配合)") args = parser.parse_args()# 如果没有提供任何参数,进入交互模式if len(sys.argv) == 1: config = interactive_input()if config is None:return keys = config['keys'] poi_types = config['poi_types'] output_file = config['output_file'] interval = config['interval'] region = config['region'] threshold = DEFAULT_MAX_COUNT_THRESHOLD # 使用默认阈值 progress_file = DEFAULT_PROGRESSelse:# 使用命令行参数 keys = args.keys or DEFAULT_KEYS poi_types = args.types or DEFAULT_POI_TYPES output_file = args.output or DEFAULT_OUTPUT interval = args.interval or DEFAULT_INTERVAL threshold = args.threshold progress_file = args.progress# 构建区域规格if args.region == "全国": region = RegionSpec.country()elif args.region == "省份":if not args.names:print("错误:省份级别需要提供 --names")return region = RegionSpec.from_provinces(args.names)elif args.region == "城市":if not args.names:print("错误:城市级别需要提供 --names")return region = RegionSpec.from_cities(args.names)elif args.region == "区县":if args.names: region = RegionSpec.from_counties(names=args.names)elif args.adcodes: region = RegionSpec.from_counties(adcodes=args.adcodes)else:print("错误:区县级别需要提供 --names 或 --adcodes")returnelse:# 默认全国 region = RegionSpec.country()# 创建爬虫并运行 crawler = AmapPOICrawler( keys=keys, poi_types=poi_types, output_file=output_file, progress_file=progress_file, request_interval=interval, max_count_threshold=threshold ) crawler.crawl(region)if __name__ == "__main__": import sys main()