最近上信号处理课,老师让用Librosa绘语谱图,之前绘制过,但用的是Scipy,因而看看这两者有什么不同。
在数字信号处理课程中通常会接触到 短时傅里叶变换(Short-Time Fourier Transform, STFT)。STFT 的一个重要应用就是生成 语谱图(Spectrogram)。语谱图能够同时展示信号在时间和频率两个维度上的变化情况,因此在语音处理、通信信号分析、声学信号检测以及机器学习音频特征提取等领域被广泛使用。
而在 Python 的音频处理生态中,最常见的两个工具是 Scipy 和 Librosa。Scipy 是一个通用科学计算库,其中的 scipy.signal 模块提供了大量经典数字信号处理函数;而 Librosa 则是一个专门面向音频分析与音乐信息检索的库,在语音识别和音频机器学习中使用非常广泛。虽然这两个库都能够绘制语谱图,但其设计思路和使用方式存在明显差异。
先从信号处理原理上来看,语谱图的生成通常包括几个步骤:首先将连续时间信号进行分帧,然后对每一帧信号乘以窗函数,接着计算每一帧的FFT。最后将各帧的频谱幅值按照时间顺序排列,就形成了二维的时频表示。我认为是一种特殊的热力图。
在 Scipy 中,语谱图的计算通常使用 scipy.signal.spectrogram() 函数。这个函数本质上是对 STFT 的一种封装,它会直接返回频率轴、时间轴以及对应的功率谱密度矩阵。Scipy 的设计风格比较接近传统数字信号处理工具,如 MATLAB 的 spectrogram 函数,因此在通信信号分析或工程信号处理场景中非常常见。其优点是接口简单、计算过程清晰,而且参数含义与 DSP 理论中的概念基本一致,例如帧长 nperseg、重叠长度 noverlap 等。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import spectrogram
from scipy.io import wavfile
fs, x = wavfile.read('example_audio.wav')
f, t, Sxx = spectrogram(x, fs)
plt.figure(figsize=(10, 6))
plt.pcolormesh(t, f, 10 * np.log10(Sxx), shading='auto')
plt.title('Spectrogram using SciPy')
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [s]')
plt.colorbar(label='Intensity [dB]')
plt.show()
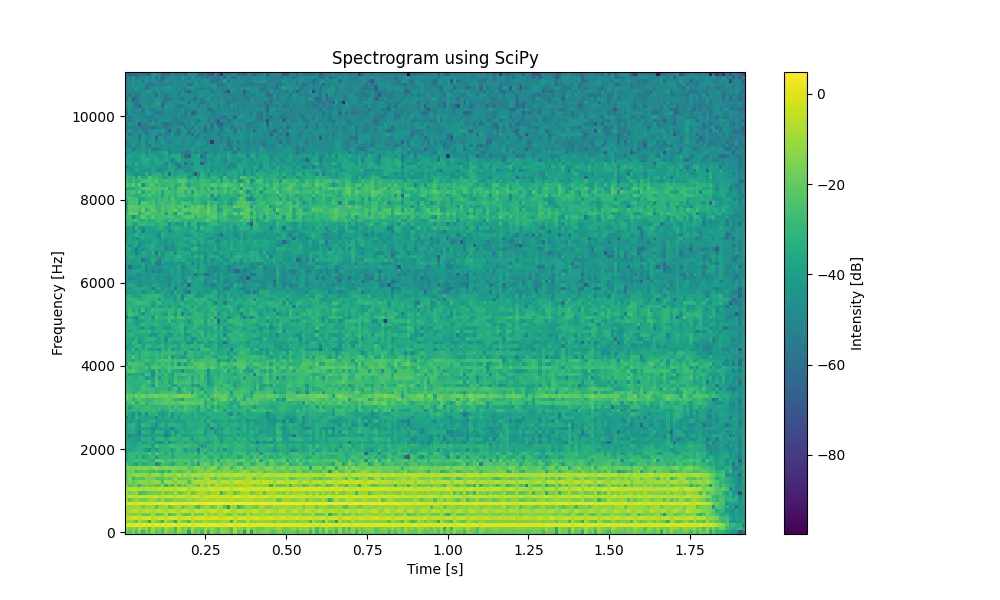
使用Scipy绘制语谱图结果如下:
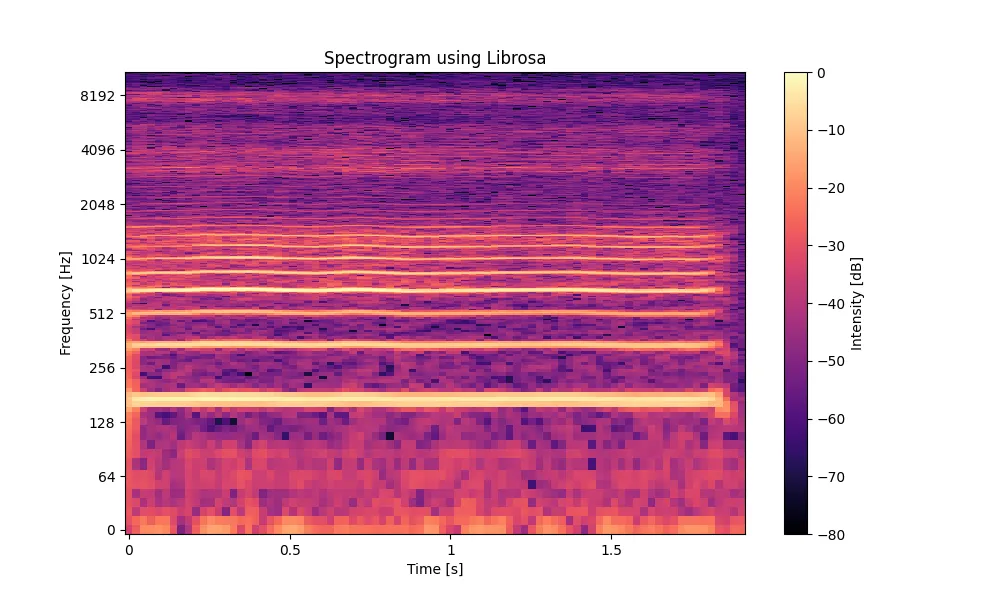
相比之下,Librosa 更强调音频分析的灵活性。在 Librosa 中,通常先使librosa.stft() 计算短时傅里叶变换,然后约定俗成通过 librosa.amplitude_to_db() 将幅度转换为分贝值,最后使用 librosa.display.specshow() 将结果可视化。与 Scipy 不同的是,Librosa 默认使用较大的 FFT 长度(通常为 2048),这样能够获得更高的频率分辨率。此外,Librosa 还提供了很多音频专用的坐标轴,例如 Mel 频率轴、对数频率轴以及音乐音符刻度,这些功能在语音识别或音乐分析中非常实用。
import librosa
import librosa.display
import matplotlib.pyplot as plt
y, sr = librosa.load('example_audio.wav')
# 计算短时傅里叶变换(STFT)
D = librosa.stft(y)
plt.figure(figsize=(10, 6))
librosa.display.specshow(librosa.amplitude_to_db(np.abs(D), ref=np.max), y_axis='log', x_axis='time', sr=sr)
plt.title('Spectrogram using Librosa')
plt.colorbar(label='Intensity [dB]')
plt.xlabel('Time [s]')
plt.ylabel('Frequency [Hz]')
plt.show()
综合来看,Scipy的语谱图使用了常规的频谱显示,其中Y轴是频率(Hz),X轴是时间(秒),色条代表强度(dB)。由于默认使用的是线性频率尺度,频谱的低频区域显得较为“密集”。Librosa绘制的语谱图支持对数频率轴(通过y_axis='log')和各种频率轴,适合分析特定频段的数字信号(比如语音),使得高频部分和低频部分具有更好的分辨率,更适合用于展示音频的细节。