網站中mp3獲取——用linux中shell中wget命令,結合python實現.
年前在和朋友喝大酒,一上頭就開始飄了。吐槽這個吐槽哪個,忽然有一個初中的哥們說:“上中學的時候,你就搗蛋的很,玩收音機收發,玩錄音機。你能不能給我下點mp3,我手機和車機沒有vip,每次只能聽幾十秒”。
不知不覺一個多月過去了,想到了這事。就有了下載mp3的想法。
說實話,這事難也不難。難的是得到mp3外聯的url,不難的是用python中的requests庫,或linux黑窗口中shel中的wget命令就可實現。
下面我就用使用來寫一下。
打開一個音樂web,找到試聽頁面。按F12
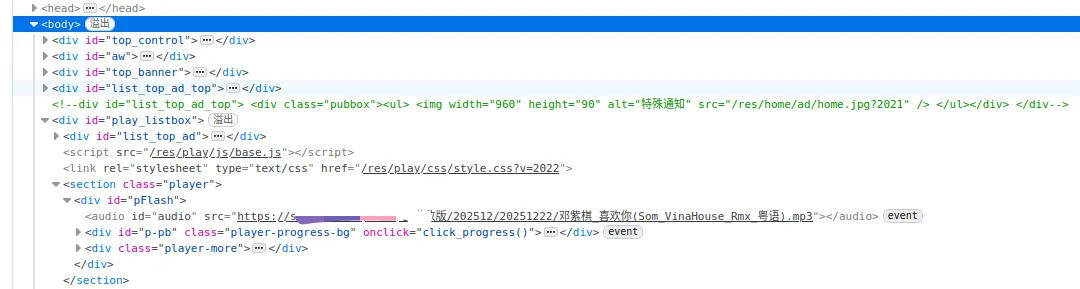
我們找到<audio></audio>的標簽,右鍵,在一個新頁面打開。如下所示
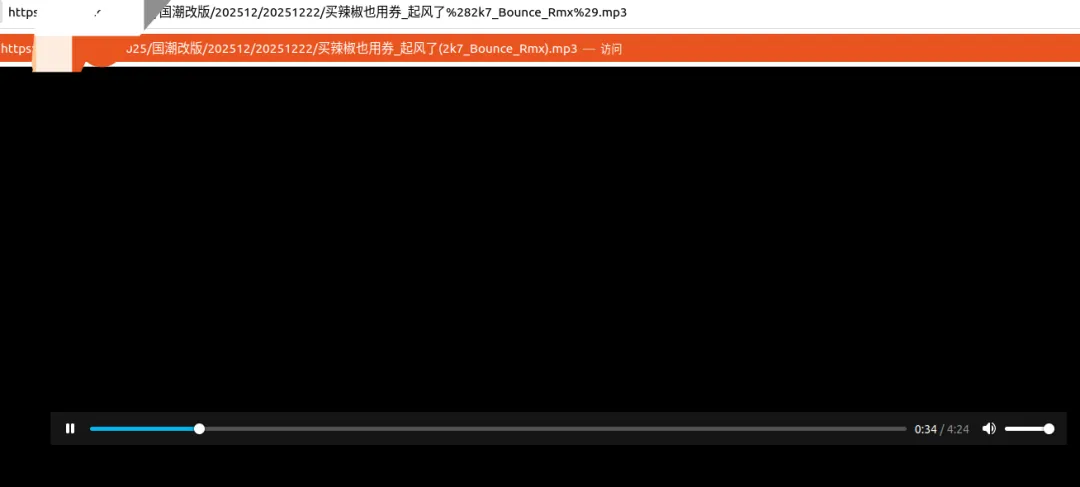
我們按F6,進入地址欄,copy all。
下來進入shell ,寫上"wget url",按回車。
顯示如下

大概看了一下,因為編碼的因素,可能是說和網站交換數據不能有“()”。我是非科班出身的理工男,關係計算機web設計課也沒有深入了解。
照著這個思路,我查了ascii ,40是(,41是“)”。看了看url中"%"后面的像是16進位(因為只url它們用到了0-9A-F),就把其中()換做%28%29,試一下。

嘿,還撞對了。mp3完成了download。
同樣的辦法,我又試了一下。不方便的是,次次寫入有'()'的url數據,都要做%替換,太不方便了。我又想到了,python字符串有一個replace的方法,可做替換。
我就又寫了一個python腳本。
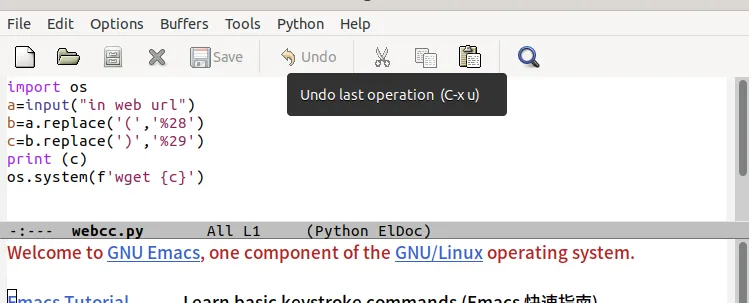
我寫入數據另一個url,試了一下。

顯示200,完整保存。
當然如果我們想連續寫入url,不退出程式下載。我們可以在上面代碼加一個while(1):,記得要縮進,就可以不斷的實現。
有一點要說的,寫入url不能間隔時間太短。一方面是不能給web服務器幹倒(給對方增加負載容易被瘋ip,我記得以前有一個人在綱8獲取資料,沒寫sleep,全網八的電腦都上不了網;達到破壞信息系統罪是要進去的),另一個方面可以不占用過多的帶寬(家內別人也要用流量)。
因為我找到的頁面有規律,只要加入for range,可以加入bs4和re等,實現一勞永逸,批量大規模獲取。
因為我的設備不行(2+32),就沒有進行實現。有興趣的,可以嘗個鮮。
本文章只做學會交流之用,不可拿來或更改用在不法路徑,如有操作,後果自負。
get數據要學法,守法,用法(刑法第286條,公民個人信息保擴,著作權的保擴等等)。不能因為一己私慾,而帶來鐵窗之淚。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
