在上一篇《EEGLAB+MNE-Python:高效全流程分析EEG数据》中,我们介绍了EEGLAB与MNE-Python在EEG数据分析流程中的基本特点以及各自的优势。本篇将进一步聚焦于批量读取与处理EEG数据这一常见需求,对比EEGLAB与MNE-Python在数据组织方式、程序逻辑以及实现方法上的差异。
在实际科研工作中,EEG数据通常来自多个被试和多个实验条件,因此如何高效地批量读取数据、组织分析结构并进行条件平均,是数据处理流程中的关键步骤。EEGLAB与MNE-Python在这一方面采用了不同的设计理念:前者更依赖MATLAB矩阵和脚本结构,而后者则强调基于Python对象和数据结构的模块化处理。
本文将通过具体示例代码的对比,来展示两种工具在批量处理经过预处理(如坏导处理、电极定位、滤波、ICA、分段等)后Epoch数据的实现方式与逻辑特点,希望能够帮助读者更好地理解两者的设计思路,并在实际研究中根据需要灵活选择或结合使用EEGLAB与MNE-Python。
一、批量读取数据并按指定结构储存
在ERP数据分析中,实验通常包含多个被试、多个实验条件以及多个电极通道和时间点。如果逐个手动读取数据并进行处理,不仅效率低,而且容易出现操作错误。因此,在正式分析之前,首先需要通过脚本批量读取所有数据,并按照统一的数据结构进行组织和存储。
1.EEGLAB中按被试和条件提取ERP并生成四维数据结构
一个规范的数据结构能够大大简化后续的统计分析。例如,在基于EEGLAB进行ERP研究时,常见的做法是将数据整理为四维数组:
被试 × 条件 × 通道 × 时间点(subjects × conditions × channels × timepoints)
这样的结构既方便进行条件平均、被试平均,也便于后续进行重复测量方差分析、点对点统计或时空统计分析。
在EEGLAB中,可以通过脚本自动读取每个被试的.set数据文件,然后按照实验条件提取对应的ERP,并将结果存储到四维数组中。这样,在完成批量读取后,所有数据都会被统一整理到一个变量中,后续分析只需针对该数据结构进行操作即可。
下面的代码示例展示了如何在EEGLAB中完成这一过程。
clear; clc; eeglab; % 清空工作区变量和命令窗口,并启动EEGLAB工具箱Subj=[1:10]; % 定义被试编号,这里共有10名被试Cond={'L1' 'L2' 'L3' 'L4'}; % 定义4种实验条件的marker类型(字符串形式)file_path='D:\weicg\EEG\test_data2\'; % 指定EEGLAB数据文件(.set)所在的路径for i=1:length(Subj) % 外层循环:遍历所有被试 file_name=[num2str(Subj(i)) '_LH.set'] % 根据被试编号生成对应的数据文件名,例如“1_LH.set” for j=1:length(Cond) % 内层循环:遍历所有实验条件 EEG= pop_loadset('filename',file_name,'filepath',file_path); % 读取当前被试的EEGLAB数据集 EEG = pop_selectevent( EEG, 'type',{Cond{j}},'deleteevents','off','deleteepochs','on', 'invertepochs','off'); % 从当前数据集中筛选指定条件的epoch(试次) % type指定事件类型,即条件marker % deleteepochs='on' 表示删除不属于该条件的epoch,只保留当前条件的epoch % deleteevents='off' 表示保留事件信息 % invertepochs='off' 表示不反向选择epoch data(i,j,:,:)=squeeze(mean(EEG.data,3)); % 计算当前被试在该条件下的ERP平均波形 % EEG.data的维度为:channel × timepoints × epochs % mean(EEG.data,3) 表示在第三维(trial/epoch)上求平均,即被试内平均 % squeeze() 用于去掉单一维度 % 最终data形成四维数组:subject × condition × channel × timepoints end endtepoch=EEG.times; chanloc=EEG.chanlocs;% 提取时间轴信息和电极位置信息,用于后续ERP绘图EEG=[]; EEG.times=tepoch; EEG.chanlocs=chanloc; % 重新创建EEG结构体,仅保留时间信息和电极位置信息,以便后续绘图使用save 'D:\weicg\EEG\test_data2\data' data EEG % 将结果保存到指定路径并命名为data% 保存内容包括:% data:四维ERP数据(被试 × 条件 × 通道 × 时间点)% EEG:包含时间轴和电极位置的结构体% 以后进行统计分析或绘图时可以直接加载该文件,无需重新运行前面的数据提取过程
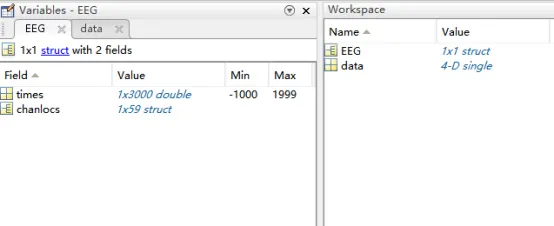
图一:data为四维数据(被试 × 条件 × 通道 × 时间点),EEG为包含时间轴和电极位置的结构体
2.使用MNE-Python批量读取EEGLAB Epoch数据并以列表形式储存
在进行ERP数据分析之前,首先需要将EEGLAB预处理后的数据导入到MNE-Python中。MNE-Python支持直接读取EEGLAB的.set文件,并自动将其转换为Epochs数据结构。Epochs是MNE中用于存储分段后的试次数据(epoch data)的核心对象,其中包含每个试次的EEG信号、时间信息、事件信息以及通道位置信息等。
2.1 读取单个EEGLAB Epoch
下面的代码演示如何读取一个EEGLAB的Epoch数据文件:
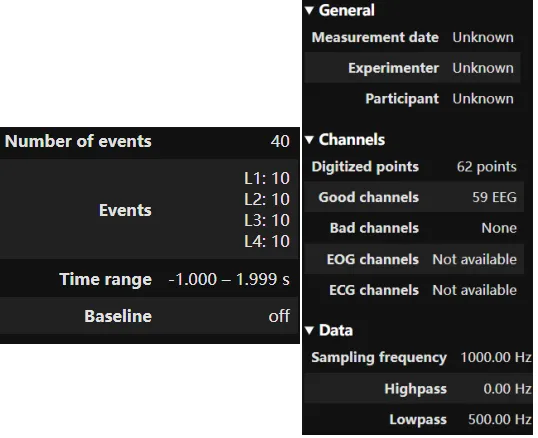
import mneimport matplotlibmatplotlib.use('Qt5Agg') # 设置Matplotlib绘图后端为Qt5Agg,使MNE的交互式绘图功能正常工作(如点击通道、缩放等)import osfile = r"D:\weicg\EEG\test_data2\1_LH.set"# 指定需要读取的EEGLAB数据文件路径,该文件为预处理并分段后的Epoch数据epoch = mne.read_epochs_eeglab(file)# 使用MNE函数读取EEGLAB的.set文件,并转换为MNE中的Epochs对象epoch #/epoch.info 输出Epochs对象的信息,包括:事件数量、种类、时间段、基线校正等。
运行上述代码后,Python会显示Epochs对象的基本信息,例如试次数量、通道数、时间范围以及事件类型等。这些信息可以帮助研究者快速确认数据是否被正确读取。
图二:读取并输出Epoch相关信息
2.2 批量读取EEGLAB Epochs
MNE-Python 提供了对 EEGLAB 数据格式的良好支持,能够直接读取 .set 文件,包括已经分段(Epochs)的数据。下面代码通过循环逐个读取 .set 文件,并将它们转换为 MNE 中的 Epochs 对象。这样,所有被试的数据就可以被统一存储和管理,为后续的 条件平均、ERP 绘制以及统计分析打下基础。
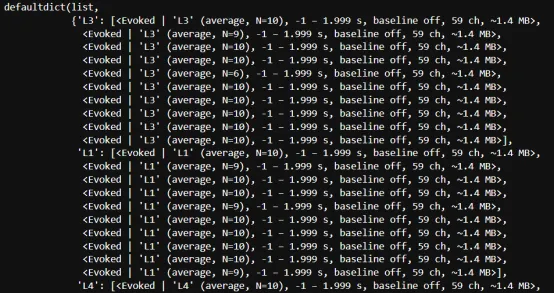
files = [f for f in os.listdir(data_dir) if f.endswith("LH.set")]# 获取该目录下所有以 "LH.set" 结尾的文件名# 这些文件通常对应不同被试的数据文件,例如:1_LH.set、2_LH.set等from collections import defaultdictsubjects = range(1, 11)file_path = r'D:\weicg\EEG\test_data2' # 定义数据所在文件夹路径all_evokeds = defaultdict(list) # 创建一个字典,用于存储每个条件的 ERP(Evoked)结果for subj in subjects: # 循环遍历每一个被试 fname = os.path.join(file_path, f'{subj}_LH.set') epochs = mne.read_epochs_eeglab(fname) # 自动读取条件名 conds = list(epochs.event_id.keys()) for cond in conds: # 遍历每一个实验条件 evoked = epochs[cond].average() all_evokeds[cond].append(evoked) # 将当前被试该条件的 ERP 结果加入字典all_evokeds
图三:MNE批量读取并保存EEGLAB Epochs数据(部分)
通过这种方式,可以方便地将EEGLAB处理后的数据导入到MNE-Python环境中,为后续的ERP波形绘制、统计分析以及头皮地形图可视化等步骤奠定基础。
二、波形图
在完成EEG数据的整理并构建好统一的数据结构之后,就可以根据研究目的有针对性地提取特定维度的数据进行进一步分析或可视化。在ERP研究中,绘制波形图是最基础也是最重要的步骤之一。通过波形图可以直观观察不同条件或不同被试在各时间点上的电位变化,从而初步判断ERP成分的出现时间、波形形态以及不同条件之间可能存在的差异。因此,在正式进行统计分析之前,通常需要先绘制并检查ERP波形,以确保数据质量并获得对实验效应的整体认识。
1.使用EEGLAB画波形图
以下代码通过对所有被试和所有实验条件的数据进行平均,得到一个总体平均ERP波形(grand average ERP)。这种总平均波形能够反映实验任务中整体的脑电反应趋势,通常用于观察主要ERP成分的大致位置,例如 N1、P2、N2 或 P3 等成分的大致时间范围,为后续更精细的条件比较和统计分析提供参考。
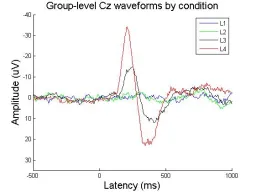
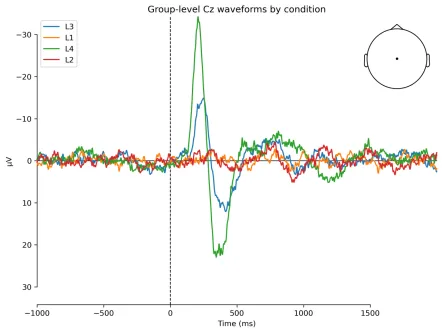
% 以Cz电极为例进行ERP波形绘制% 在本数据中Cz的物理电极编号为13,因此在data数组的通道维度选择13%% 各个条件Cz波形图figure; % 新建图形窗口hold on; % 允许在同一坐标轴上叠加绘图set(gca,'YDir','reverse'); % 设置负电位向上% xlim([-500 1000]); % 可选:设置X轴范围% ylim([-15 10]); % 可选:设置Y轴范围axis([-500 1000 -40 35]); % 设置绘图显示范围(时间范围和振幅范围)plot(EEG.times, squeeze(mean(data(:,1,13,:),1)),'-b'); % L1条件在Cz上的组平均ERPplot(EEG.times, squeeze(mean(data(:,2,13,:),1)),'-g'); % L2条件在Cz上的组平均ERPplot(EEG.times, squeeze(mean(data(:,3,13,:),1)),'-k'); % L3条件在Cz上的组平均ERPplot(EEG.times, squeeze(mean(data(:,4,13,:),1)),'-r'); % L4条件在Cz上的组平均ERP% mean(data(:,cond,13,:),1):对所有被试进行平均,得到组平均ERPlegend('L1','L2','L3','L4'); % 添加图例说明各条件title('Group-level Cz waveforms by condition','fontsize',16); % 图标题xlabel('Latency (ms)','fontsize',16); % X轴名称ylabel('Amplitude (uV)','fontsize',16); % Y轴名称
图四:EEGLAB绘出的Cz电极各条件组平均ERP波形2.使用MNE-Python画波形图
import matplotlib.pyplot as pltmne.viz.plot_compare_evokeds( all_evokeds, picks=['Cz'], # 选择要绘制的电极,这里选择 Cz 电极 ci=False, # 不绘制置信区间(confidence interval) # 如果设为 True,则会显示平均波形周围的误差带 invert_y=True, # 将 Y 轴反转,使负电位朝上 time_unit='ms', # 将时间单位显示为毫秒(ms) title='Group-level Cz waveforms by condition', # 设置图的标题 show=False # 为保存图片先不要显示 )fig = plt.gcf() # 获取当前图像对象(current figure)fig.savefig('Cz_waveforms_by_condition.png', dpi=300, bbox_inches='tight') # 保存图像
图五:MNE绘出的Cz电极各条件组平均ERP波形
三、绘制地形图
地形图(Topographic Map)是ERP研究中常用的一种可视化方式,用于展示某一特定时间点或时间窗口内头皮电位在不同电极上的空间分布情况。通过将各电极记录到的电位值按照其在头皮上的实际空间位置进行插值和颜色编码,可以直观地观察脑电活动在头皮上的分布模式。例如,在ERP研究中常常会选择某些典型成分的峰值潜伏期(如 N2、P2、P3 等),并绘制这些时间点的地形图,从而分析不同实验条件下脑电活动的空间分布差异。
通常情况下,研究者会先通过ERP波形图确定感兴趣成分的大致潜伏期,然后选取对应的时间点或时间窗口绘制地形图。在本示例中,根据前面绘制的Cz电极波形图,观察到N2和P2成分的峰值潜伏期分别约为207ms和374ms。因此,可以以这两个时间点为代表,绘制所有被试与所有条件平均后的头皮电位分布图。
1.EEGLAB绘制
在EEGLAB中,可以使用topoplot函数绘制ERP地形图。首先需要确定对应峰值的时间点索引,然后提取该时间点所有电极的平均电位值并进行可视化。
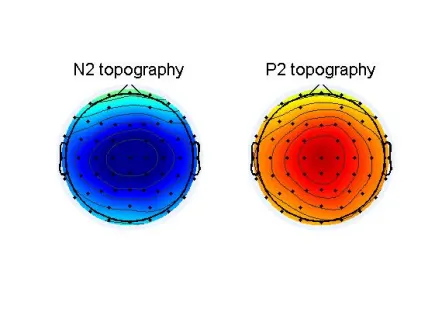
N2_peak=find(EEG.times==207); P2_peak=find(EEG.times==374); %% 所有条件总平均N2/P2地形图figure; subplot(121); topoplot(squeeze(mean(mean(data(:,:,:,N2_peak),1),2)),EEG.chanlocs);% 提取N2时间点所有被试和所有条件的平均电位分布% data(:,:,:,N2_peak):N2时间点的所有数据% mean(...,1):被试平均% mean(...,2):条件平均caxis([-10 10]); % 设置颜色刻度范围title('N2 topography','fontsize',16); % N2头皮分布图subplot(122); topoplot(squeeze(mean(mean(data(:,:,:,P2_peak),1),2)),EEG.chanlocs); caxis([-10 10]); % 设置颜色刻度范围title('P2 topography','fontsize',16); % P2头皮分布图
图六:EEGLAB绘制的所有条件总平均N2/P2地形图
除了绘制所有条件总体平均的地形图之外,也有必要分别绘制不同条件下的地形分布图。这样可以更直观地比较各实验条件在头皮空间分布上的差异,判断效应是否具有稳定的空间模式,并为后续电极选择或统计分析提供依据。下面给出使用EEGLAB实现N2分析与绘图的示例代码。
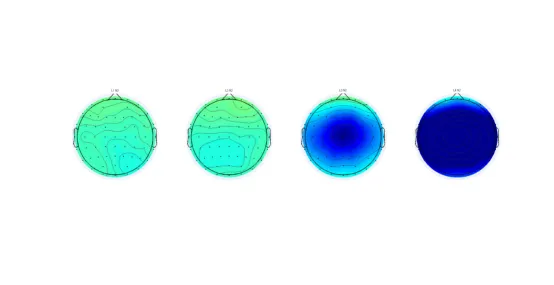
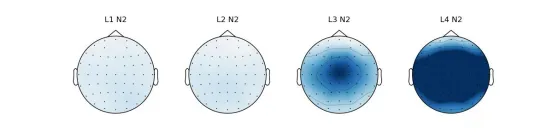
%% 各条件N2时间点的地形图% 由于L1和L2条件的N2峰不明显,这里为每个条件大致估计一个潜伏期N2_timepoints = [316, 310, 249, 208]; % 每个条件的N2时间点(ms)figure;for i = 1:length(Cond) % 遍历所有条件subplot(1, length(Cond), i); % 在同一窗口按条件排列子图condition_data = squeeze(mean(data(:, i, :, find(EEG.times==N2_timepoints(i))))); % 提取当前条件在指定N2时间点的数据% mean(data(:,i,:,:),1):先对被试平均% find(...):找到对应时间点索引topoplot(condition_data, EEG.chanlocs, 'maplimits', [-15 15]); % 绘制该条件N2时刻的头皮地形图,并统一颜色范围title(sprintf('%s N2', Cond{i})); % 添加子图标题(条件名称)End
图七:EEGLAB绘制的四种条件下N2地形图
2.MNE-Python绘制
类似地,MNE-Python也可以方便地实现上述分析与可视化功能。与EEGLAB相比,MNE-Python更加依赖清晰的数据结构(如Epochs、Evoked等对象)以及相应的函数接口来完成数据处理与绘图。因此,在使用MNE-Python时,需要特别注意数据的组织方式以及不同对象之间的转换关系。在理解这些基本结构之后,实现各条件ERP的平均、峰值时间点提取以及头皮地形图绘制都会非常直接。下面通过一段示例代码演示如何在MNE-Python中完成相同的分析过程。
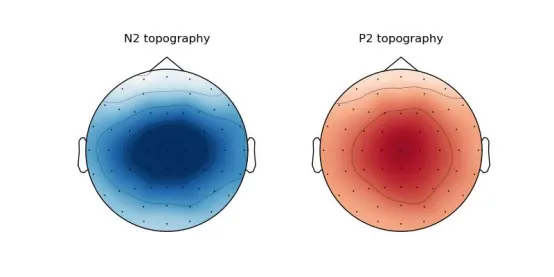
import matplotlib.pyplot as pltgrand_avg = {} # 计算每个条件的 group average(所有被试平均)for cond, evks in all_evokeds.items(): grand_avg[cond] = mne.grand_average(evks) # 再把所有条件平均(所有条件+所有被试)grand_all = mne.grand_average(list(grand_avg.values()))N2_peak = 0.207P2_peak = 0.374fig, axes = plt.subplots(1,2, figsize=(8,4))grand_all.plot_topomap(times=N2_peak, axes=axes[0], vlim=(-10,10), colorbar=False, time_unit='s')axes[0].set_title('N2 topography')grand_all.plot_topomap(times=P2_peak, axes=axes[1], vlim=(-10,10), colorbar=False, time_unit='s')axes[1].set_title('P2 topography')plt.show()
图八:MNE绘制的所有条件总平均N2/P2地形图
由上例可以看出,在MNE-Python中可以使用字典结构来组织不同条件下的ERP数据。例如,all_evokeds以字典的形式存储各实验条件对应的Evoked对象列表,每个条件下的列表包含来自不同被试的平均结果。在此基础上,可以利用MNE提供的内置函数mne.grand_average()对这些Evoked对象进行进一步平均,从而得到各条件的群体平均结果grand_avg,以及所有条件合并后的整体平均结果grand_all。随后,通过plot_topomap()等可视化函数即可方便地绘制ERP成分在头皮上的空间分布。下面将进一步介绍如何使用MNE-Python绘制不同实验条件下的头皮地形分布图。
# 定义每个条件对应的 N2 时间点(单位:秒)# Matlab 中是毫秒 [316,310,249,208],这里换算成秒N2_timepoints = [0.316,0.310,0.249,0.208]# 定义实验条件名称conditions=['L1', 'L2', 'L3', 'L4']# 创建一个画布,1行4列子图,每个条件一个topomap# figsize 控制图的整体大小fig, axes = plt.subplots(1, len(conditions), figsize=(12,3))# 循环遍历每个条件for i, cond in enumerate(conditions): # 从 grand_avg 字典中取出当前条件的 group average Evoked 对象 evk = grand_avg[cond] # 绘制该条件在指定时间点的头皮电位分布图(topomap) evk.plot_topomap( times=N2_timepoints[i], # 当前条件的 N2 时间点 axes=axes[i], # 指定绘制在哪个子图 vlim=(-15,15), # 颜色范围,对应 Matlab maplimits [-15 15] colorbar=False, # 不显示单独的 colorbar time_unit='s' # 时间单位为秒 ) # 设置子图标题,例如 "L1 N2" axes[i].set_title(f'{cond} N2')# 显示图像plt.show()
图九:MNE-Python绘制的四种条件下N2地形图
四、小结
通过以上示例可以看到,EEGLAB与MNE-Python在批量读取、组织和处理EEG数据时虽然采用了不同的实现方式,但其核心前提是一致的:数据必须按照清晰、规范的结构进行组织与保存。无论是MATLAB中的多维矩阵,还是Python中的对象化数据结构,研究者都必须要明确数据的维度含义、层级关系以及调用方式,才能正确完成数据读取、平均、统计和可视化等分析步骤。这一点在进行批量处理和自动化分析时尤为重要,也是保证分析流程可靠与可重复的基础。
在实现逻辑上,EEGLAB更依赖MATLAB的矩阵结构和脚本流程,数据通常以被试 × 条件 × 电极 × 时间点等多维数组的形式组织,计算和操作过程直观清晰,并结合GUI与插件体系,能够帮助研究者快速完成常规ERP分析和结果可视化。相比之下,MNE-Python则采用更加明确的对象化数据结构,通过Epochs、Evoked等数据对象来组织分析流程,再借助字典、列表等Python容器实现批量管理和处理,例如本文示例中使用all_evokeds、grand_avg和grand_all来逐层完成条件平均与总体平均。
在可视化和统计分析方面,EEGLAB和MNE-Python都提供了丰富的内置函数,让脑电数据处理变得更高效、更直观。EEGLAB利用MATLAB的图形界面和函数,可以轻松绘制ERP波形、头皮地形图、功率谱或时频分析图,同时支持常用统计检验和多被试平均操作。MNE-Python则通过Python的对象化数据结构(如Epochs、Evoked等)结合灵活的函数接口,实现条件平均、峰值检测、地形图绘制,甚至簇类置换检验等复杂统计分析,而且可以无缝融入Python的科学计算生态(NumPy、SciPy、Pandas等)。这些内置功能不仅提高了分析效率,也让研究者能够在不同条件下快速探索脑电活动的空间和时间特征,为后续分析和结果展示提供可靠支持。
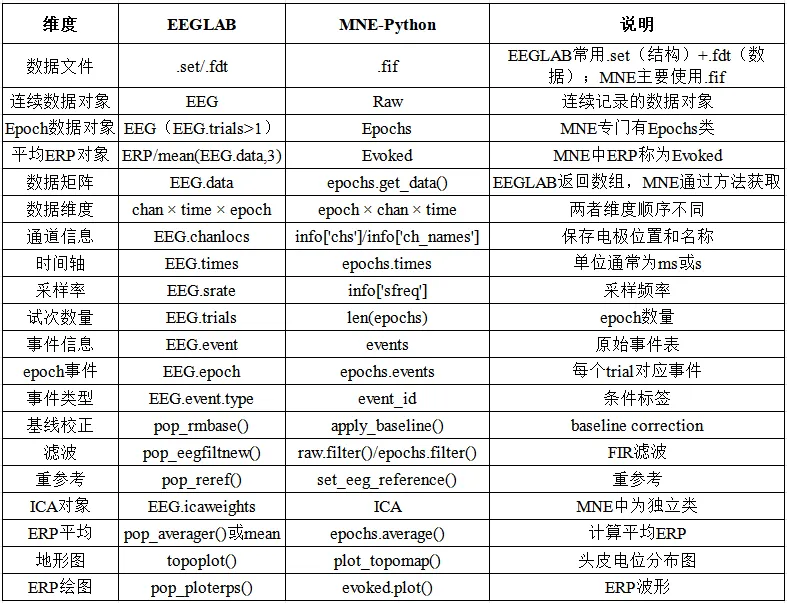
表一:EEGLAB与MNE-Python在脑电数据分析中的核心维度对照
从实践角度看,EEGLAB的优势在于操作直观、学习曲线较低、插件资源丰富,非常适合入门和快速开展EEG分析;而MNE-Python需要具备一定的Python基础,但掌握后可依托Python强大的科学计算生态,在批量处理、自动化分析、统计建模以及可重复研究等方面具有优势。理解两者在数据结构和实现逻辑上的差异,不仅有助于更高效地使用各自工具,也为在实际研究中将二者结合使用提供了思路,从而构建更加灵活、高效的EEG数据分析流程。
五、致谢
特别感谢胡理研究员提供的实验数据、EEGLAB处理代码以及专业指导。
(文中内容为作者个人观点,仅供参考)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
