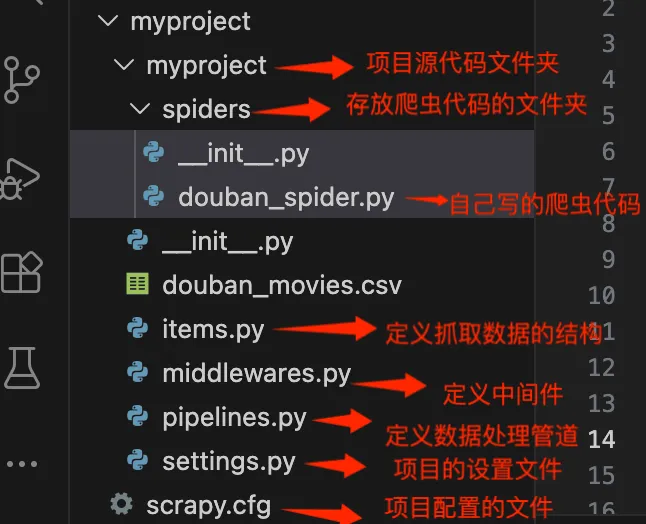
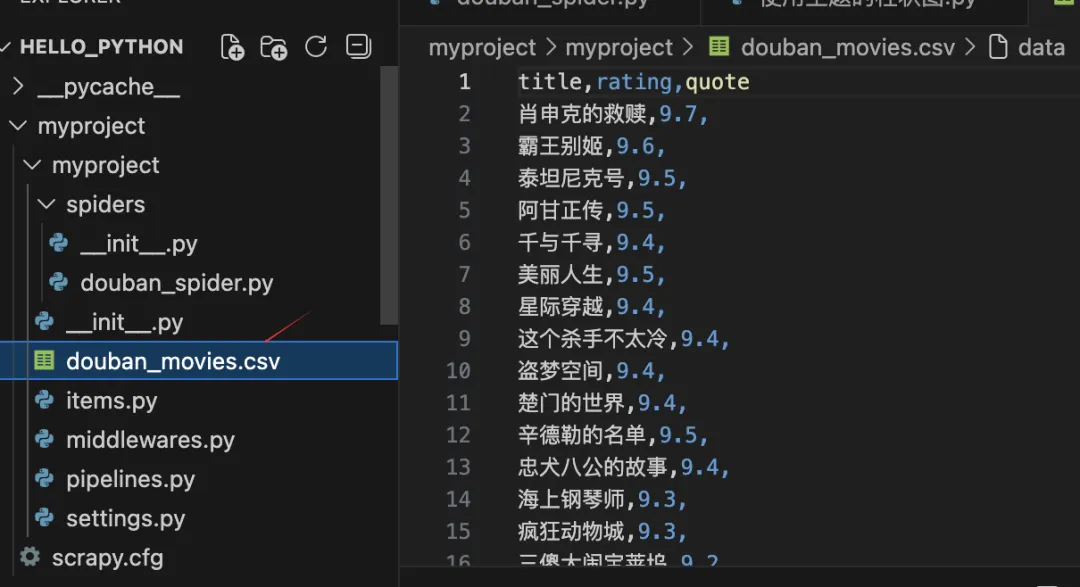
import scrapy #导入scrapyclass DoubanSpiderSpider(scrapy.Spider): #定义爬虫名称-唯一 name = "douban_spider" #限制爬虫的网页域名,防止爬到其他域名 allowed_domains = ["movie.douban.com"] #爬虫启始页地址 start_urls = ["https://movie.douban.com/top250"] def start_requests(self): #请求头 模拟真实的浏览器请求 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', 'Referer': 'https://movie.douban.com/top250', } for url in self.start_urls: yield scrapy.Request(url, headers=headers, callback=self.parse) def parse(self, response): #用 CSS 选择器查找所有 class="item" 的 div 元素(每部电影是一个 item) for movie in response.css('div.item'): yield { #提取第一个 <span class="title"> 的文本内容 'title': movie.css('span.title::text').get(), #提取评分(<span class="rating_num">9.7</span> → "9.7") 'rating': movie.css('span.rating_num::text').get(), #提取经典台词(<span class="inq">希望让人自由。</span>) 'quote': movie.css('span.inq::text').get(), } # 处理分页 next_page = response.css('span.next a::attr(href)').get() if next_page is not None: yield response.follow(next_page, callback=self.parse) # def parse(self, response): # pass