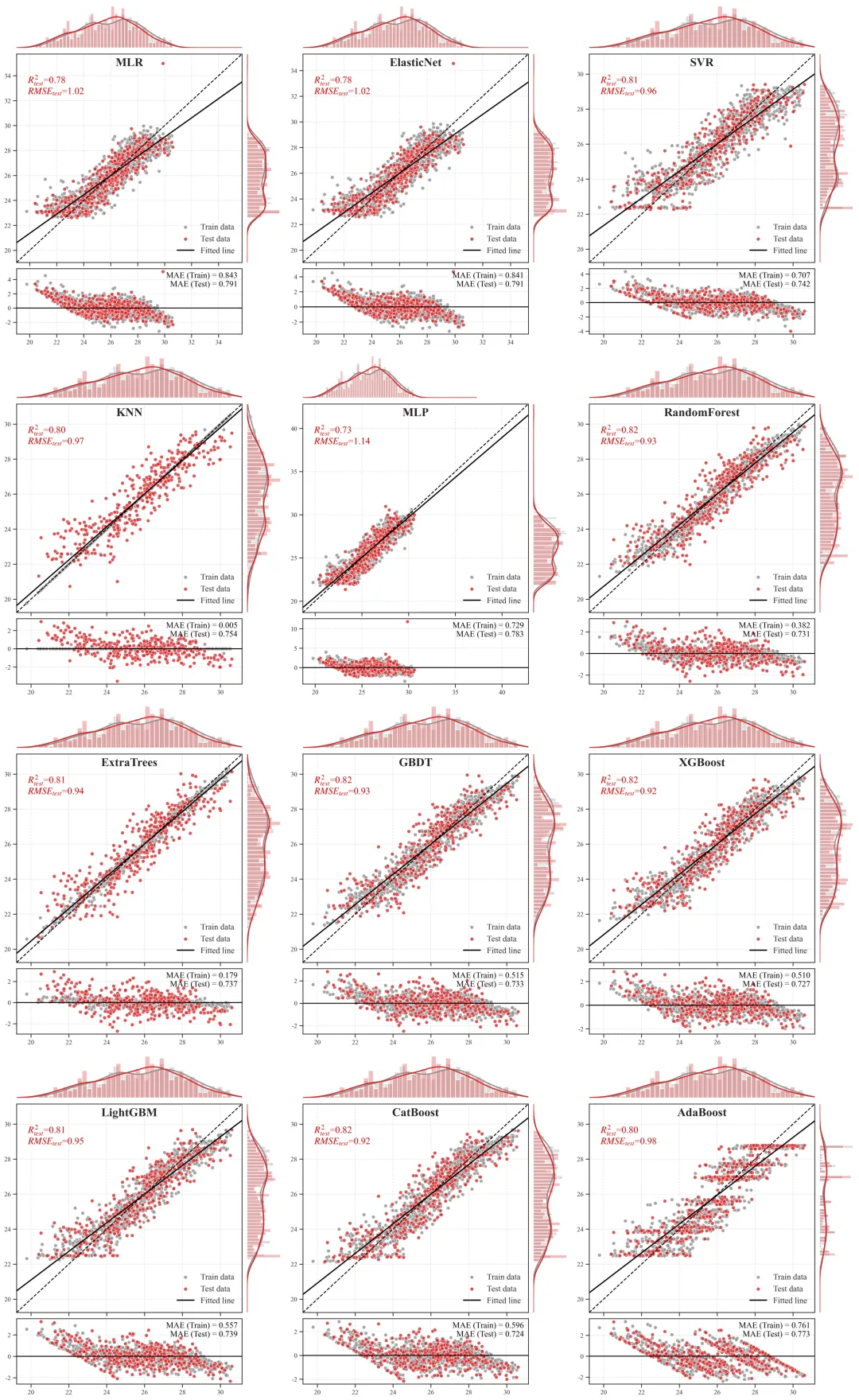
12个机器学习模型包括:AdaBoost、CatBoost、ElasticNet、ExtraTrees、GBDT、KNN、LightGBM、MLP、MLR、RandomForest、SVR、XGBoost
在处理复杂的非线性数据时,我们经常面临海量的、具有极强异质性的数据特征。传统的单一统计模型往往难以捕捉这些深层映射规律。
这套代码是一个全自动化的高阶机器学习沙箱,它主要解决了以下三个核心科研痛点:
1、消除算法选择困难症:一次性自动运行并横向对比 12 种当前最主流的回归算法,涵盖传统线性模型、距离模型、神经网络,以及横扫数据科学竞赛的树类 Boosting 集成模型,用客观的泛化数据筛选出最适合当前非线性特征的解释器。
2、防范过拟合与数据泄露:内置严格的 K 折交叉验证(K-Fold CV)与自动化超参数寻优(网格搜索/随机搜索),确保模型不仅在已知样本上表现好,在面对未知空间数据或未来时间序列时,依然具备强大的稳健性。
3.实现出版级可视化的一键生成:打破了过去需要借助多种软件反复导出、拼接图表的繁琐流程,直接通过底层渲染出信息密度极高的“散点-边缘密度-残差”联合诊断大图,直接对接顶级期刊对数据解释深度的严苛要求。
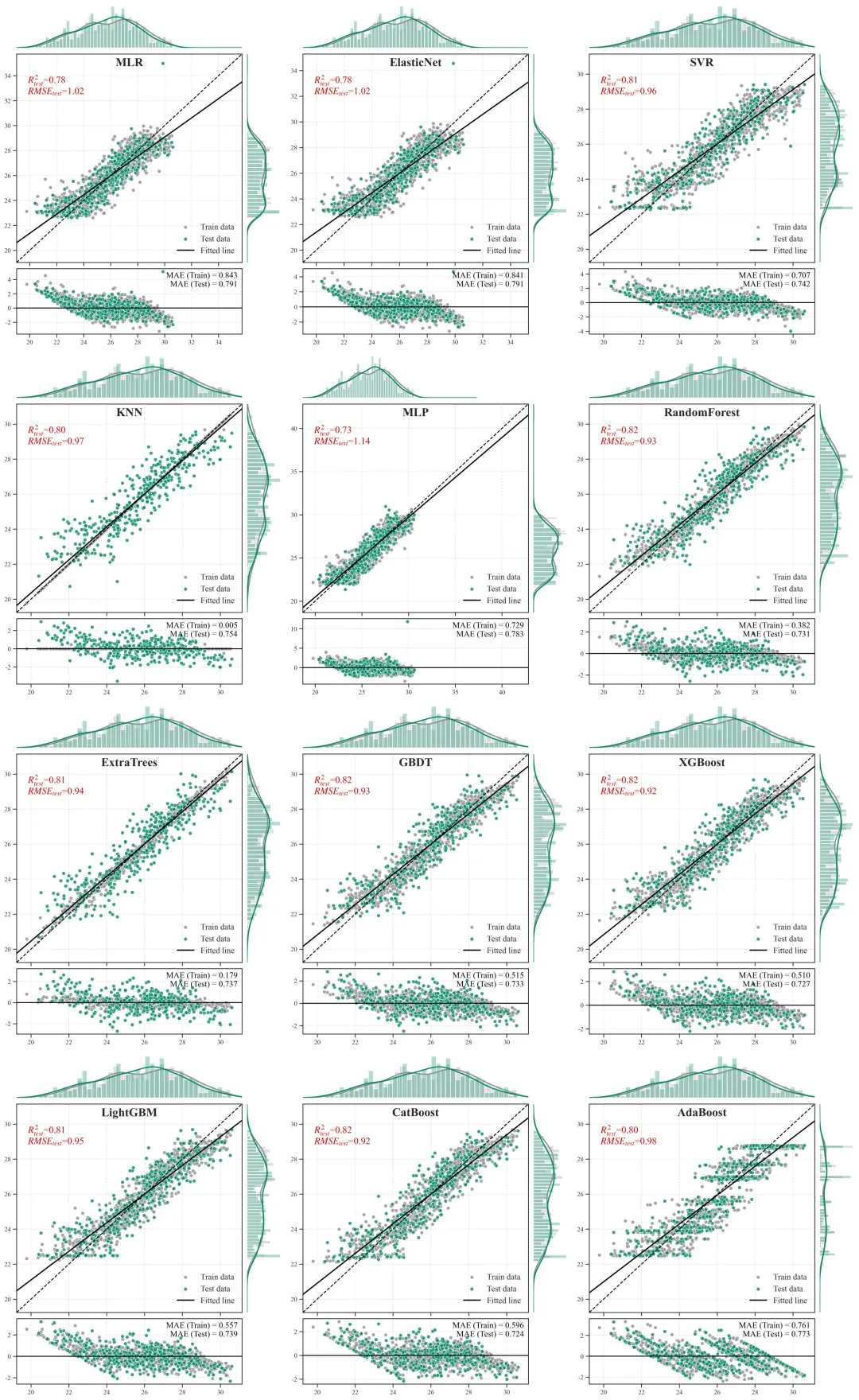
不同配色效果:
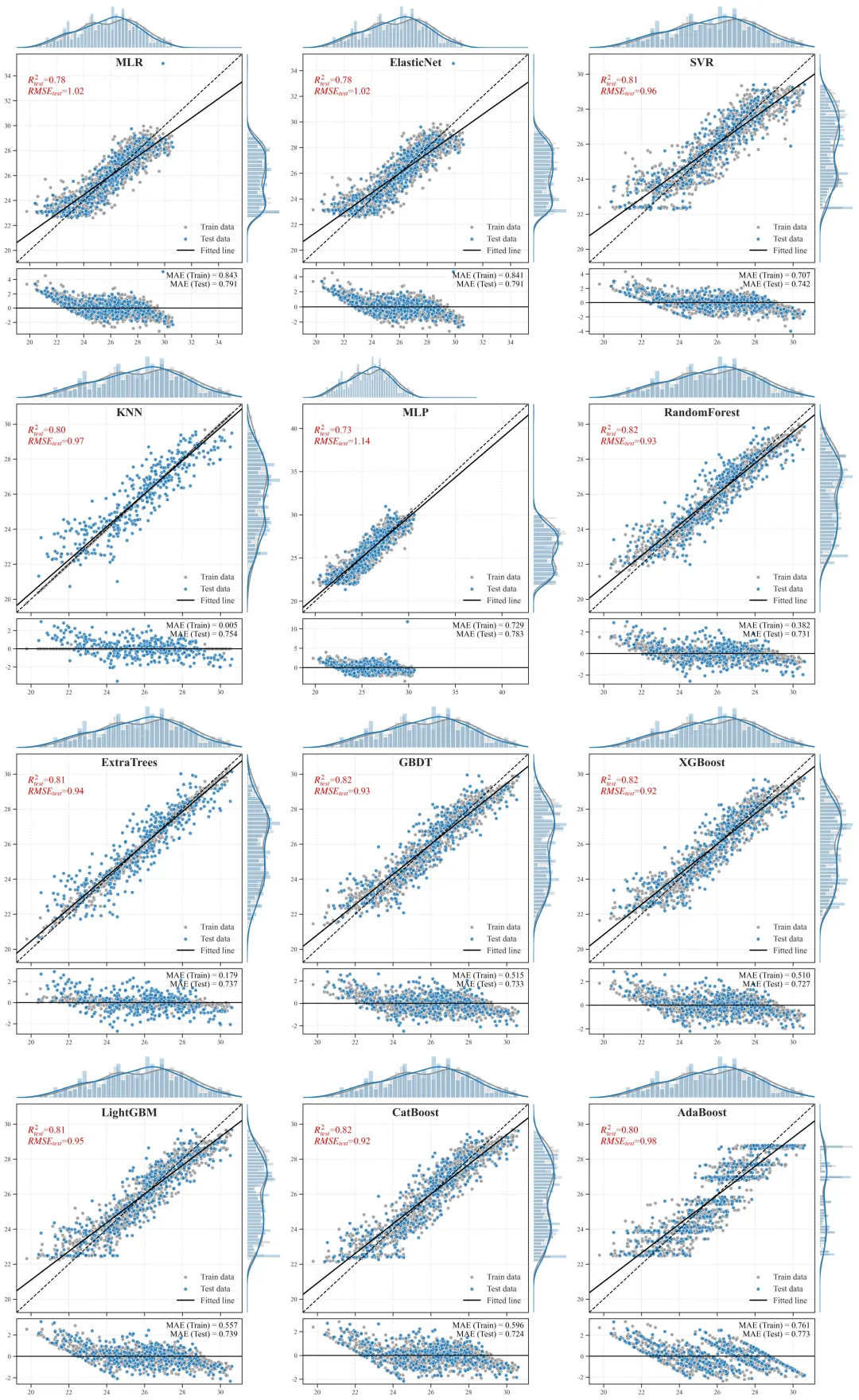
输出结果解析
代码运行结束后,会产出两类核心科研凭证:量化评估表格与高维联合图像。
1.量化评估表
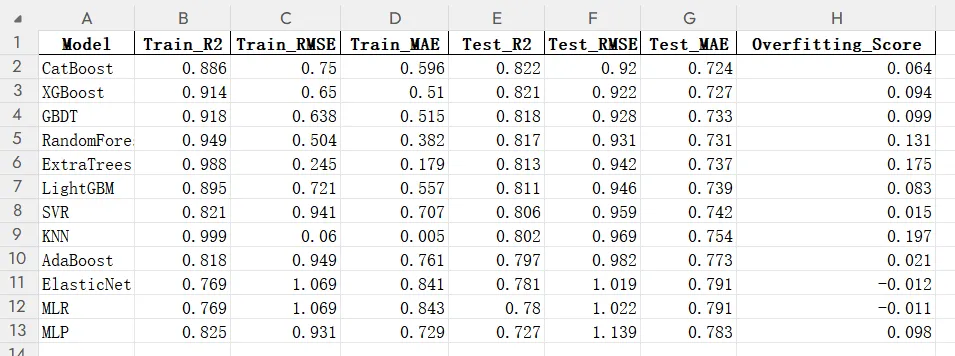
R2(决定系数):评估模型对现象的解释力度(取值极大概率为 0~1)。测试集 R2 越高,证明我们选取的特征集合越能精准解析目标变量的空间或时间异质性。RMSE / MAE (误差指标):衡量预测值与真实值绝对偏差的量级。例如在预测地表温度时,它可以直接反映模型预测的平均绝对误差究竟是1摄氏度还是3摄氏度。
Overfitting Score (过拟合衰减差值):即 训练集R2-测试集 R2。差值越小,说明模型越稳健,在推演或反演其他未知空间网格时更为可靠。
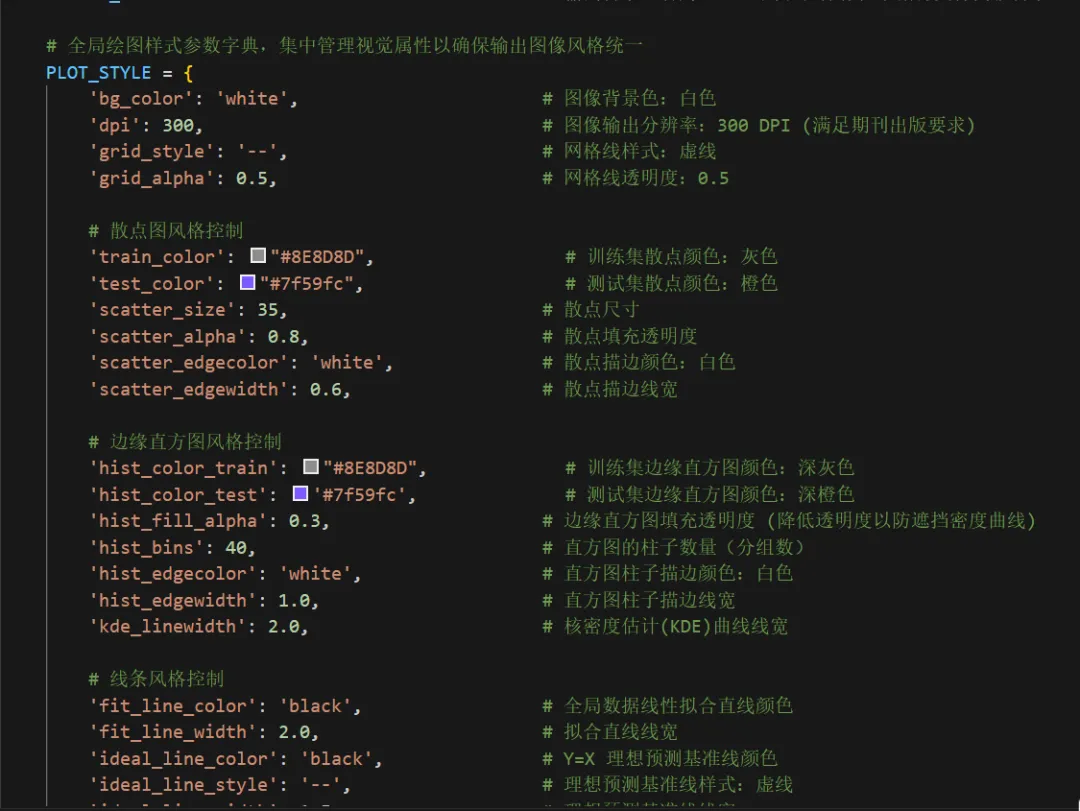
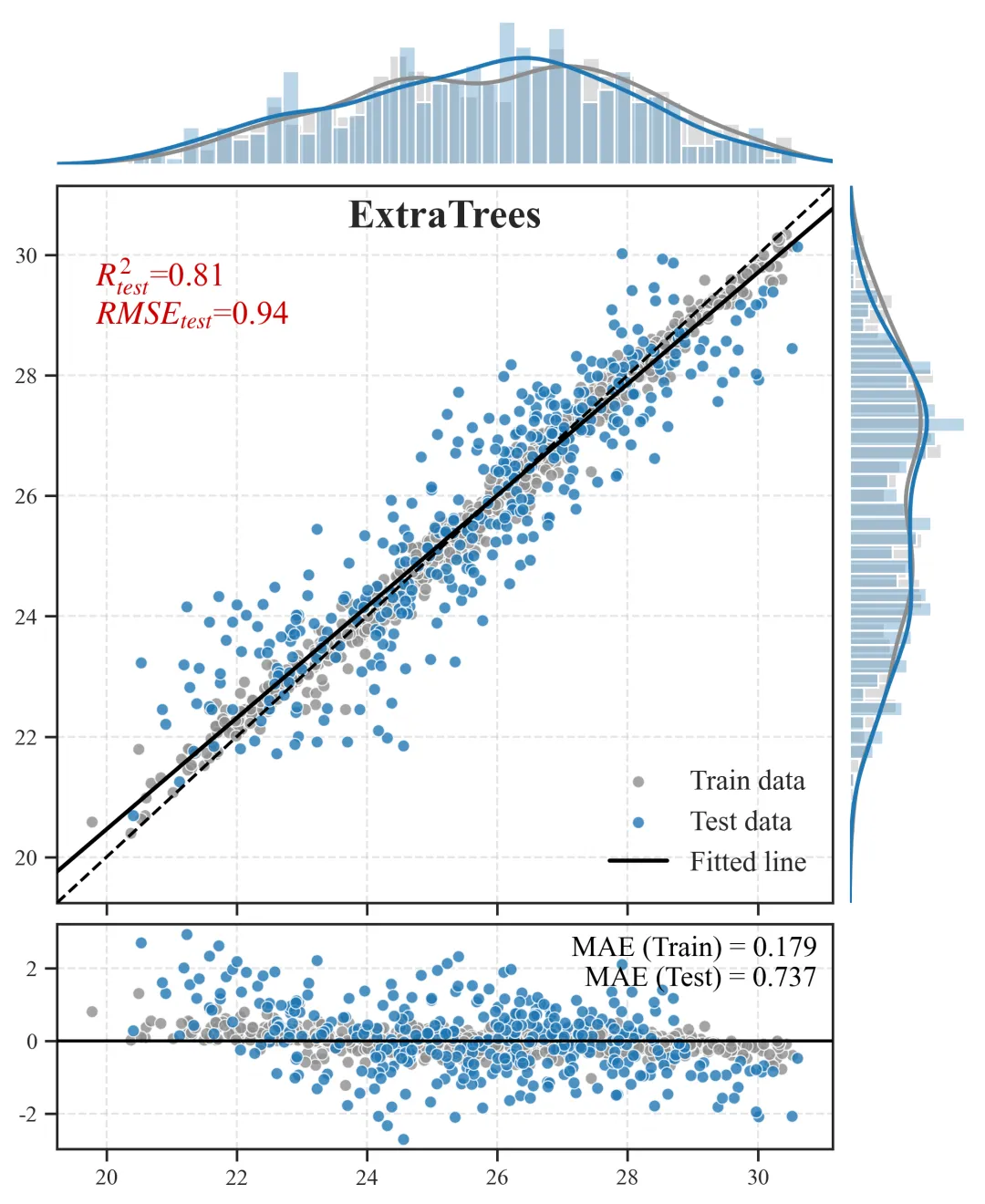
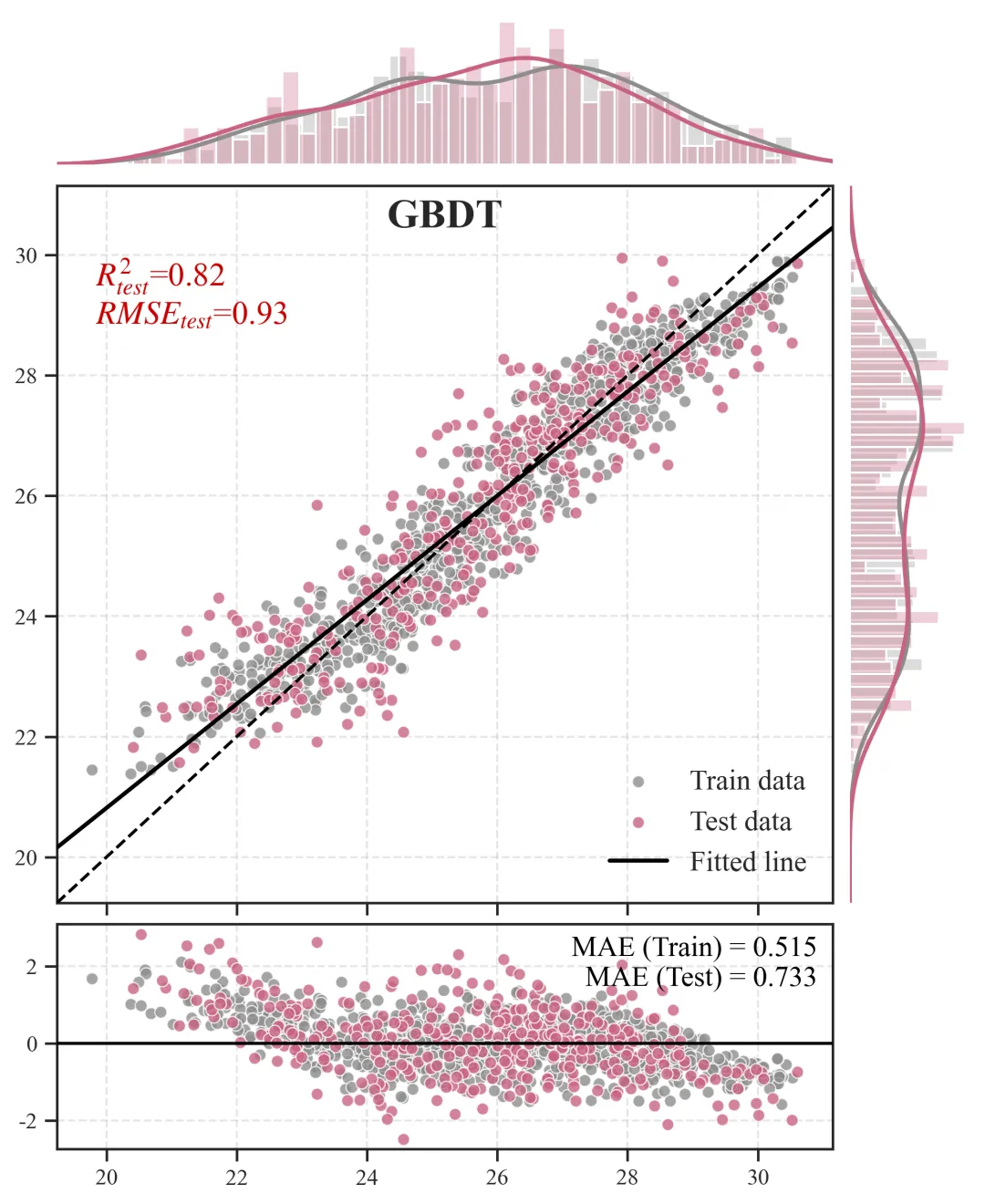
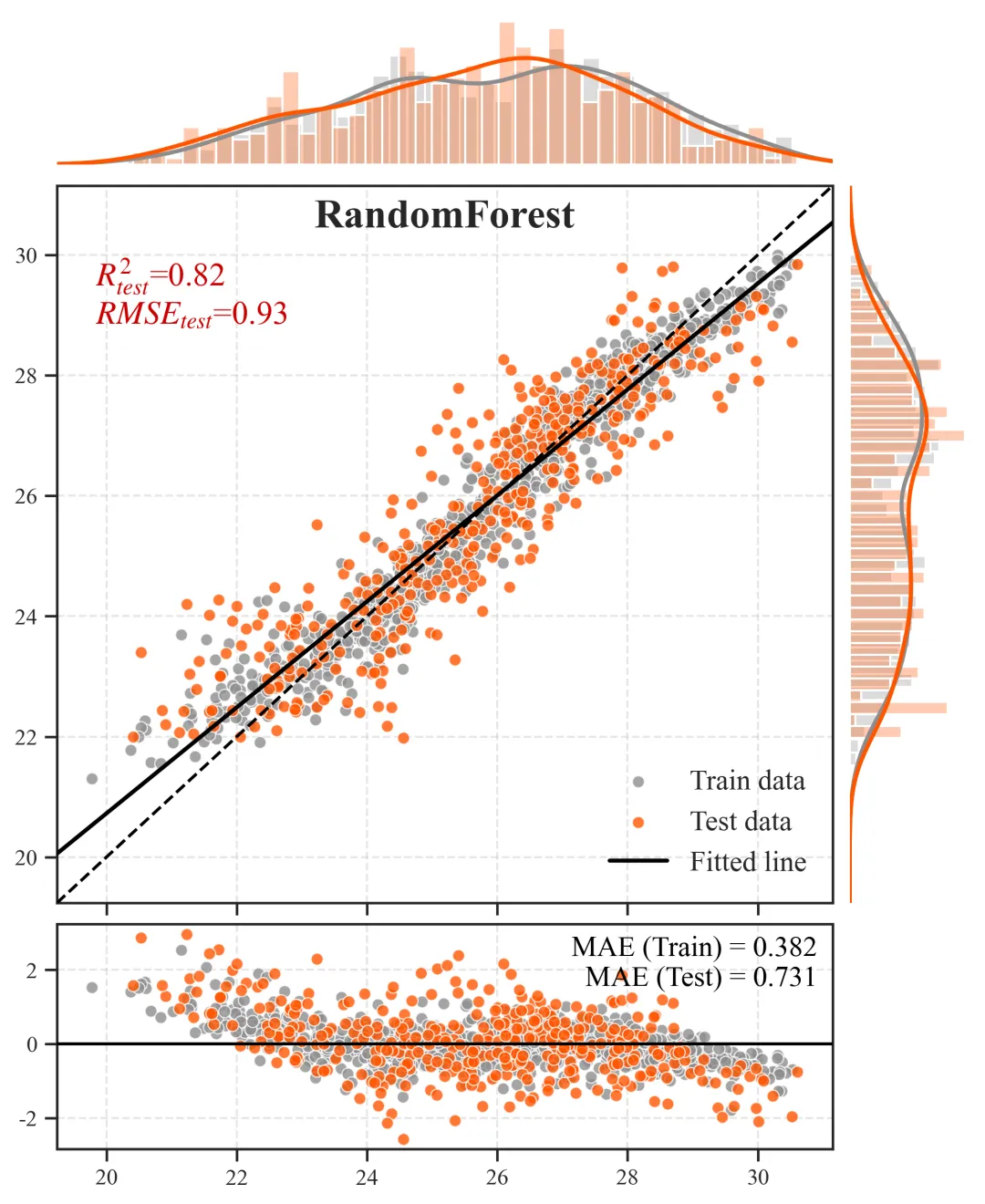
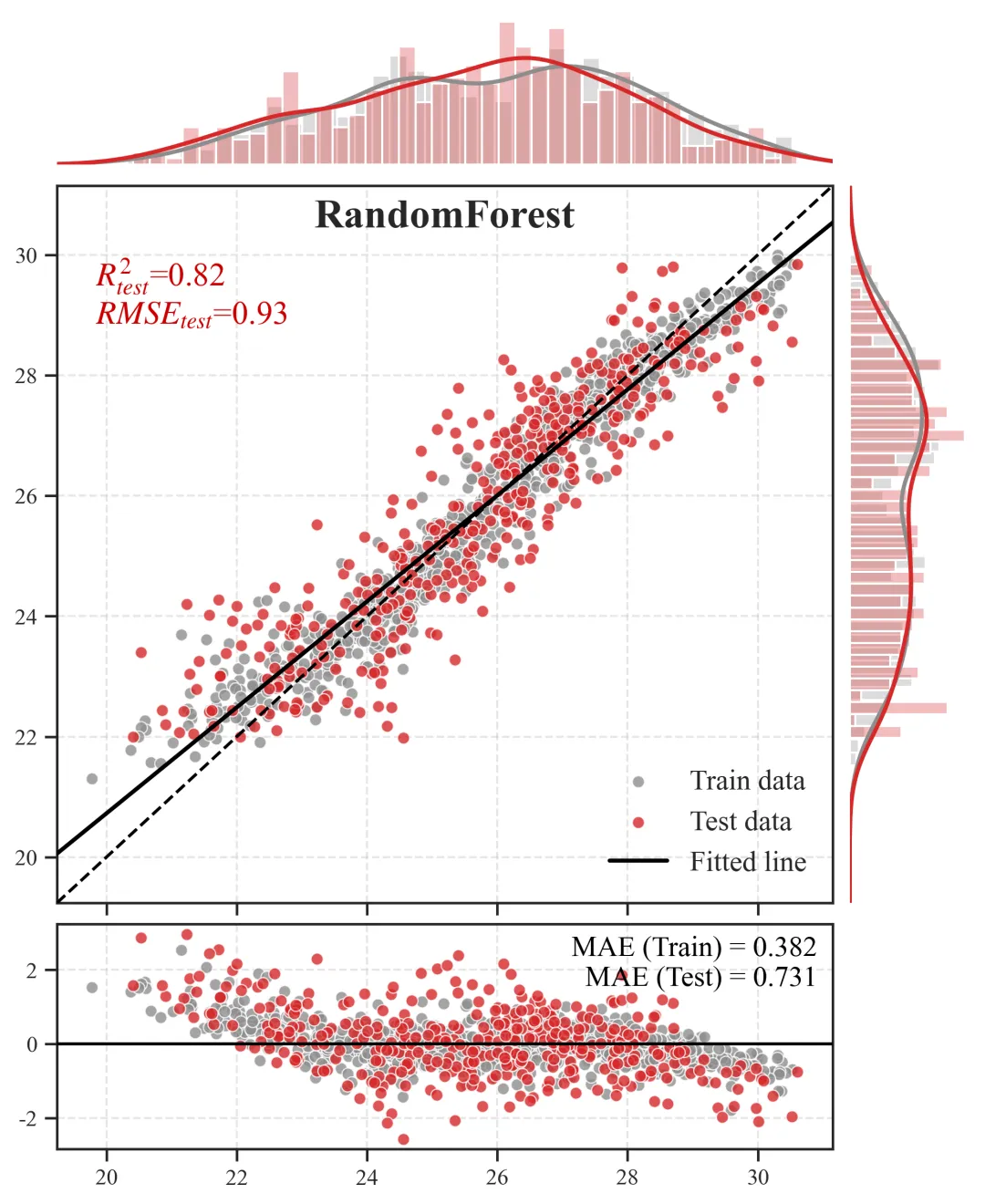
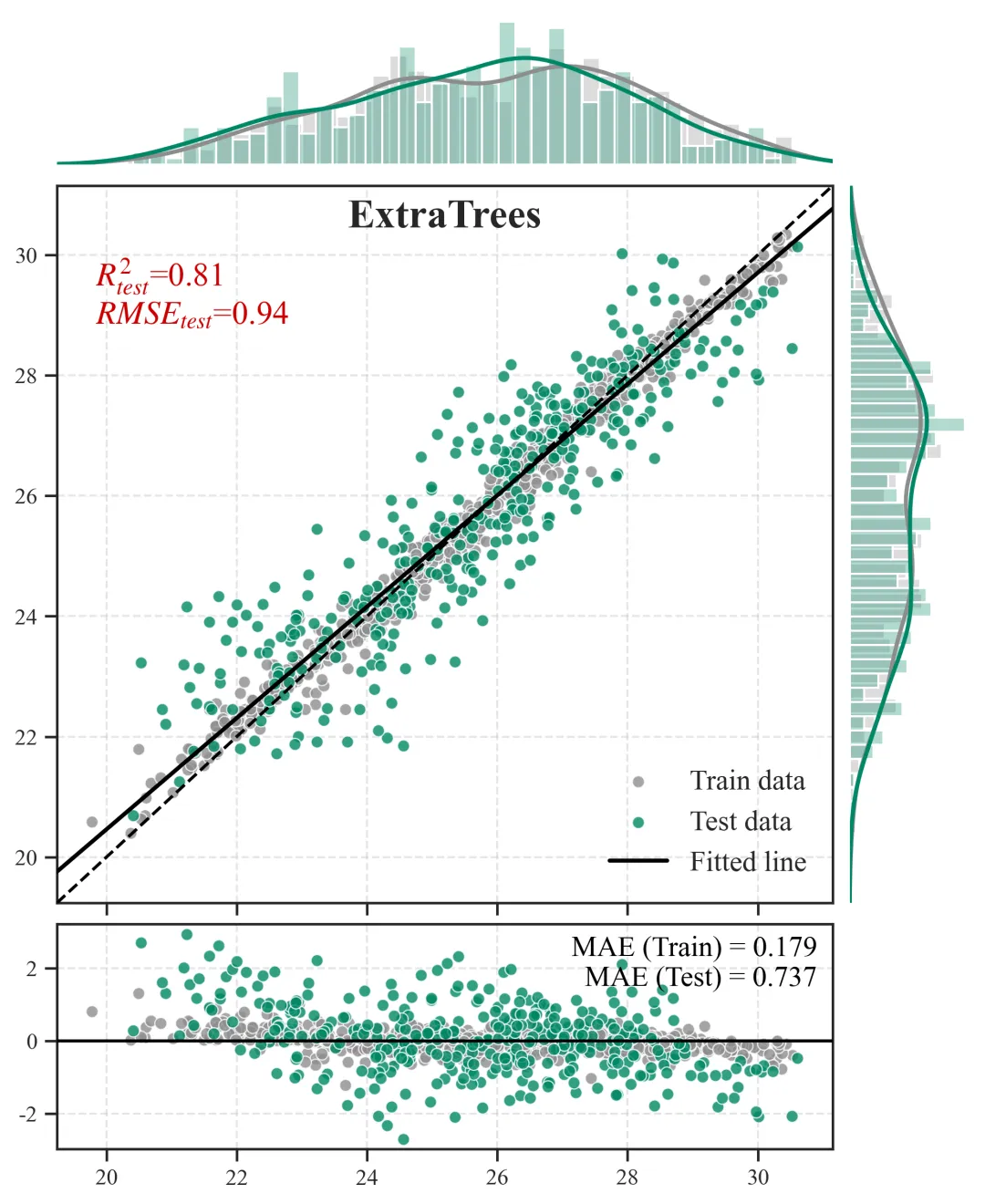
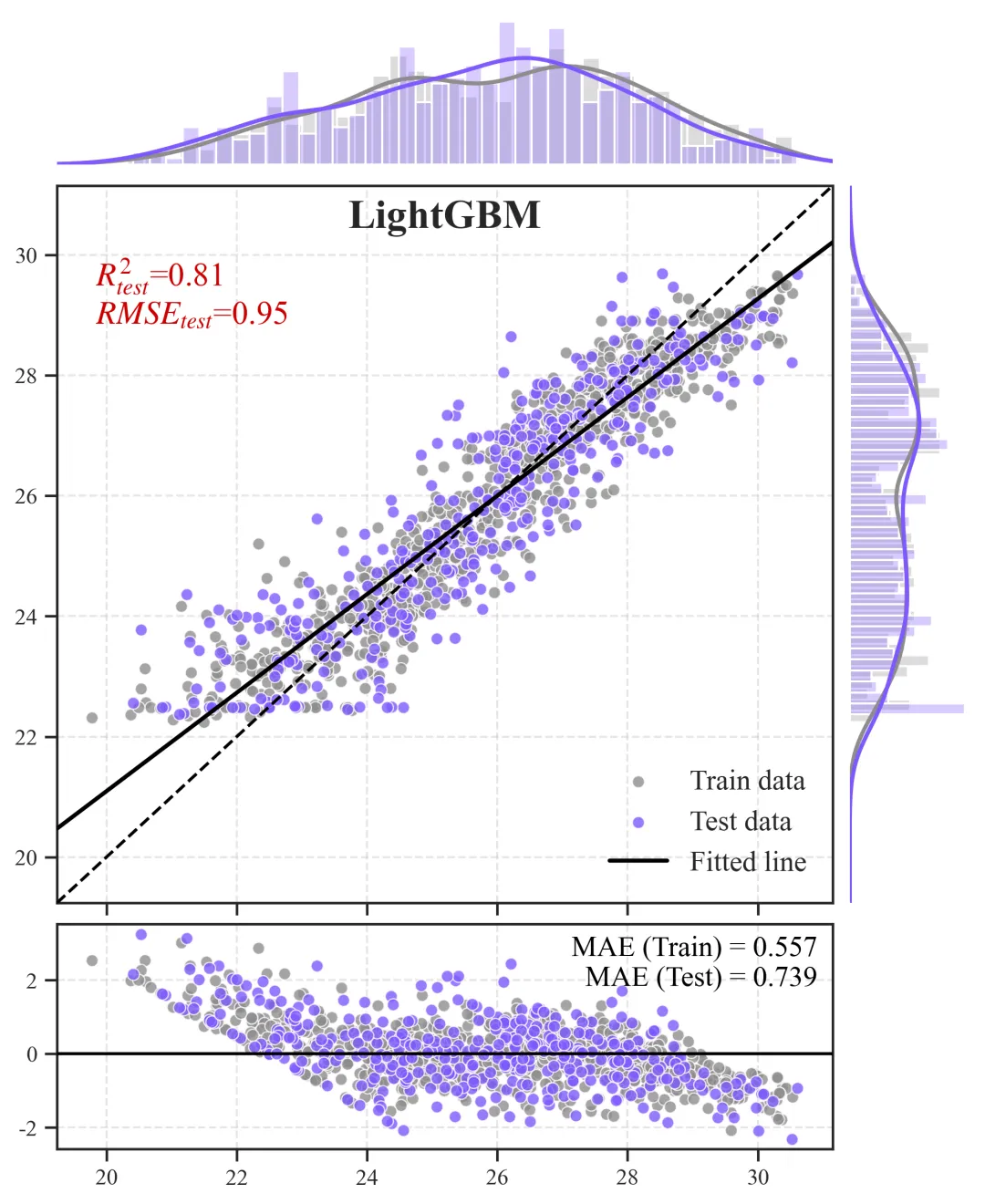
2.预测散点图+边缘分布图+残差图
主视区(中央散点组合图):
含义:X 轴为观测的真实值,Y 轴为模型推演的预测值。灰色点为训练集,橙色点为测试集。
科研解读:图中贯穿的那条虚线是y=x的“绝对真理参考线”。散点越紧密地聚拢在这条虚线周围,模型精度越高。黑色的实线则是当前所有点的拟合趋势线,如果黑色实线与虚线发生明显夹角偏离,说明模型存在系统性的高估或低估偏误。上/右边缘视区(核密度直方图):
含义:展示了数据在各自坐标轴上的物理分布密度形态。
科研解读:用于直观诊断“样本失衡”问题。如果在高值区间(图表的最右侧或最上方),密度曲线贴底且直方柱稀疏,说明我们收集到的极端样本太少,这也从侧面解释了为什么模型在极端区间的散点往往更容易发散。
底部视区(残差诊断图):
含义:X 轴依然是真实值,但 Y 轴变成了误差绝对量(预测值减去真实值)。科研解读:残差图是高阶期刊审稿人必看的诊断图。一条Y=0的黑色水平基准线横亘其中,理想状态下,残差散点应该像毫无规律的繁星一样,均匀地上下散布在水平线两侧。如果残差散点随着真实值变大而呈现出“喇叭状”发散,这在统计学上称为异方差性,强烈提示我们当前的特征工程可能遗漏了某个关键的空间互动阈值变量,导致模型在部分区间失去了约束力。
代码运行操作
这套代码被设计为“开箱即用”的傻瓜式工具。
第一步:模型库安装:运行代码前,需要先安装代码使用的模型库,可以在终端或者新建文件输入代码安装,安装代码如下:
pip install numpy pandas matplotlib seaborn Pillow scikit-learn xgboost lightgbm catboost openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
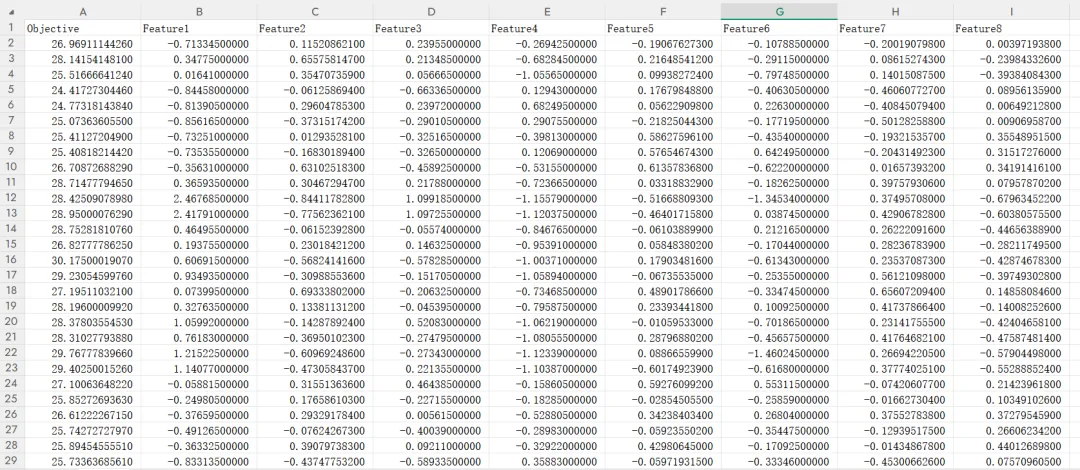
第二步:环境准备:您只需要准备好一个 Excel 数据表(第一列为需要预测的因变量(Y),后面所有列为自变量特征(X)。实例数据如下所示:
第三步:输入数据路径:在 Python 解释器中,将 EXCEL_PATH 变量修改为您本地的数据路径,直接点击运行。
第四步:点击运行
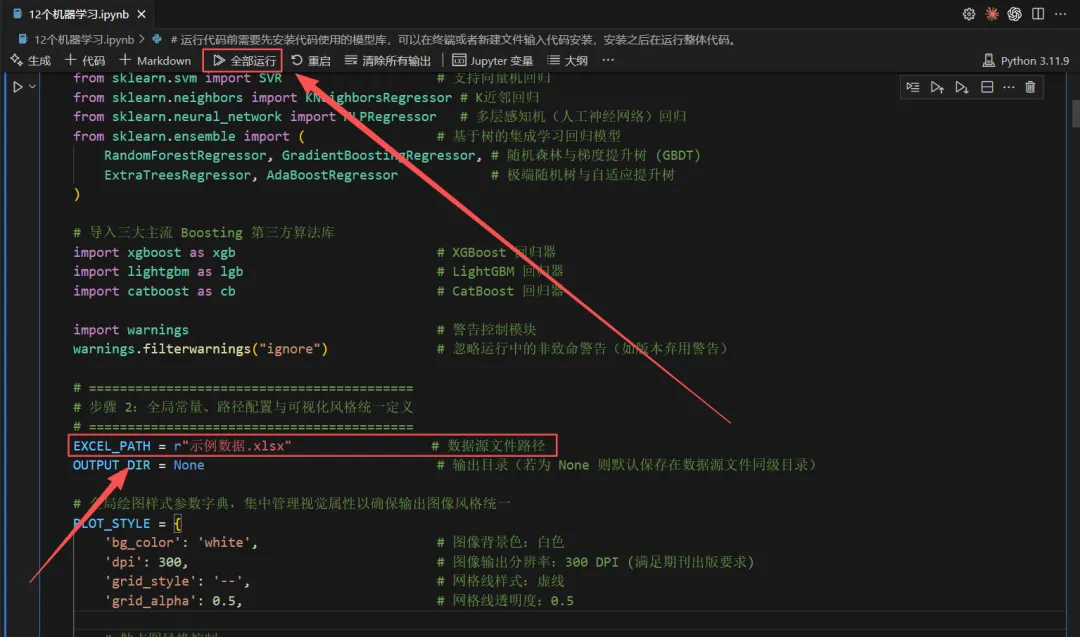
在这里可以修改颜色和风格样式。
多模型组合结果输出:
代码获取回复“12个机器学习模型”
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
