Python进阶:函数、类、NumPy、Pandas一网打尽
- 2026-06-28 00:19:26
2.4 函数、类与模块化编程
2.4.1 函数:代码复用的基本单元
# 第2章/python
# 基本函数
def count_tokens(text: str) -> int:
"""粗略估算文本的 Token 数(中文约每1.5字一个Token)"""
chinese_chars = sum(1 for c in text if '\u4e00' <= c <= '\u9fff')
english_words = len(text.split()) - chinese_chars // 2
return int(chinese_chars / 1.5 + english_words)
# 带默认参数的函数
def build_prompt(question: str,
system: str = "你是AI助手",
temperature: float = 0.7) -> dict:
"""构建 API 请求消息体"""
return {
"messages": [
{"role": "system", "content": system},
{"role": "user", "content": question}
],
"temperature": temperature
}
# 调用
result = build_prompt("什么是大模型?")
result = build_prompt("什么是大模型?", temperature=0.2) # 指定参数
# *args 和 **kwargs(在框架源码中常见)
def flexible_function(*args, **kwargs):
print(f"位置参数: {args}")
print(f"关键字参数: {kwargs}")
flexible_function(1, 2, 3, name="AI", version=4)
# 位置参数: (1, 2, 3)
# 关键字参数: {'name': 'AI', 'version': 4}
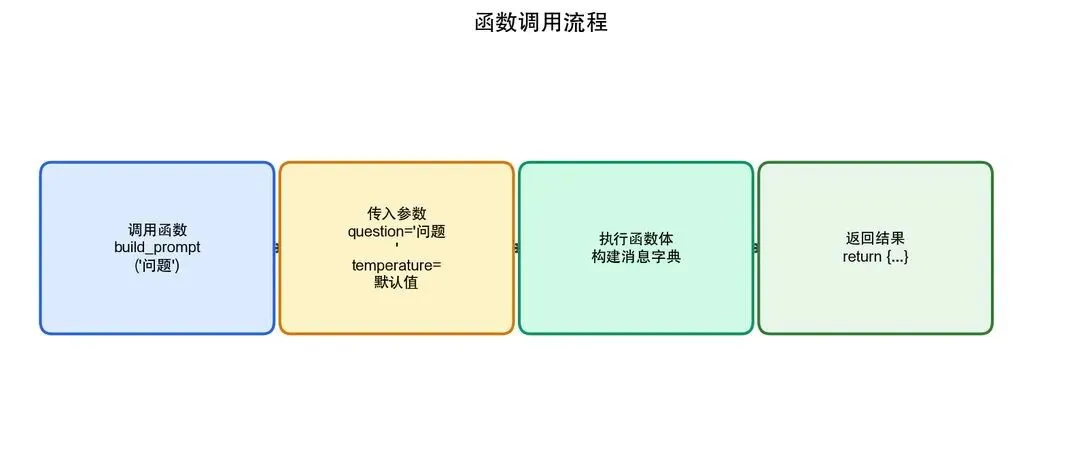
图2-9
2.4.2 类:面向对象编程
在 AI 项目中,类通常用来封装模型调用、数据处理管道等组件:
# 第2章/python
class ChatBot:
"""一个简单的聊天机器人类"""
def __init__(self, model_name: str, api_key: str):
"""初始化方法,创建对象时自动调用"""
self.model_name = model_name
self.api_key = api_key
self.history = [] # 对话历史
def chat(self, user_message: str) -> str:
"""发送消息并获取回复"""
self.history.append({"role": "user", "content": user_message})
# 实际项目中这里调用 API
reply = f"[{self.model_name}] 收到你的消息:{user_message}"
self.history.append({"role": "assistant", "content": reply})
return reply
def get_history(self) -> list:
"""获取对话历史"""
return self.history.copy()
def clear_history(self):
"""清空对话历史"""
self.history.clear()
def __repr__(self):
return f"ChatBot(model={self.model_name}, history_len={len(self.history)})"
# 使用
bot = ChatBot("deepseek-chat", "sk-xxx")
print(bot.chat("你好")) # [deepseek-chat] 收到你的消息:你好
print(bot.chat("什么是AI?")) # [deepseek-chat] 收到你的消息:什么是AI?
print(bot) # ChatBot(model=deepseek-chat, history_len=4)
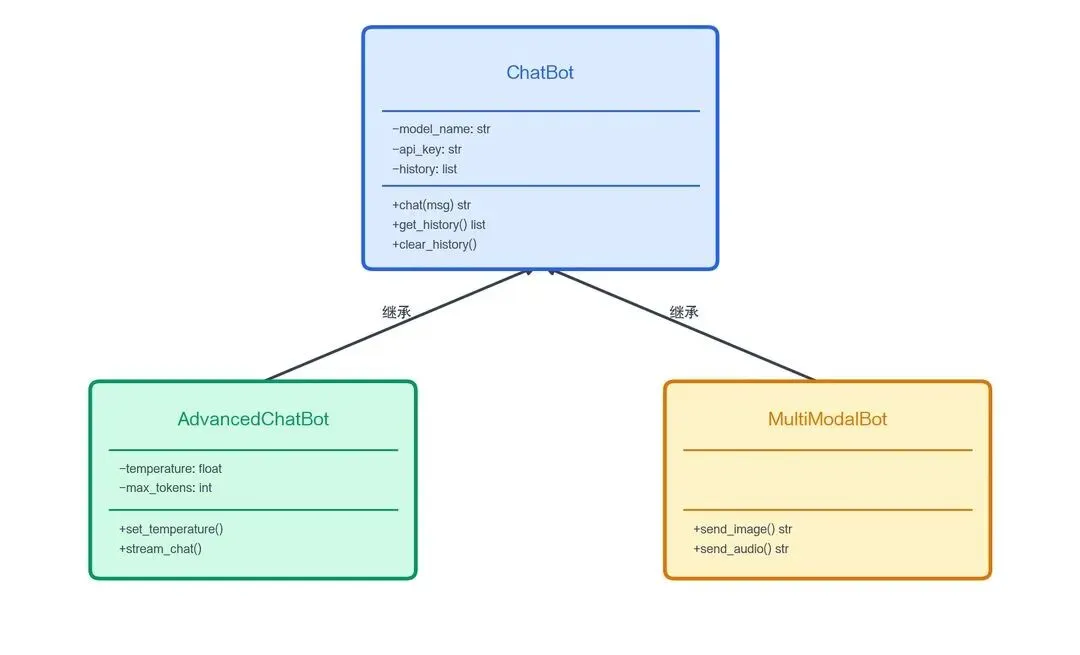
图2-10
2.4.3 模块化编程
良好的项目结构是大型 AI 项目的基础:
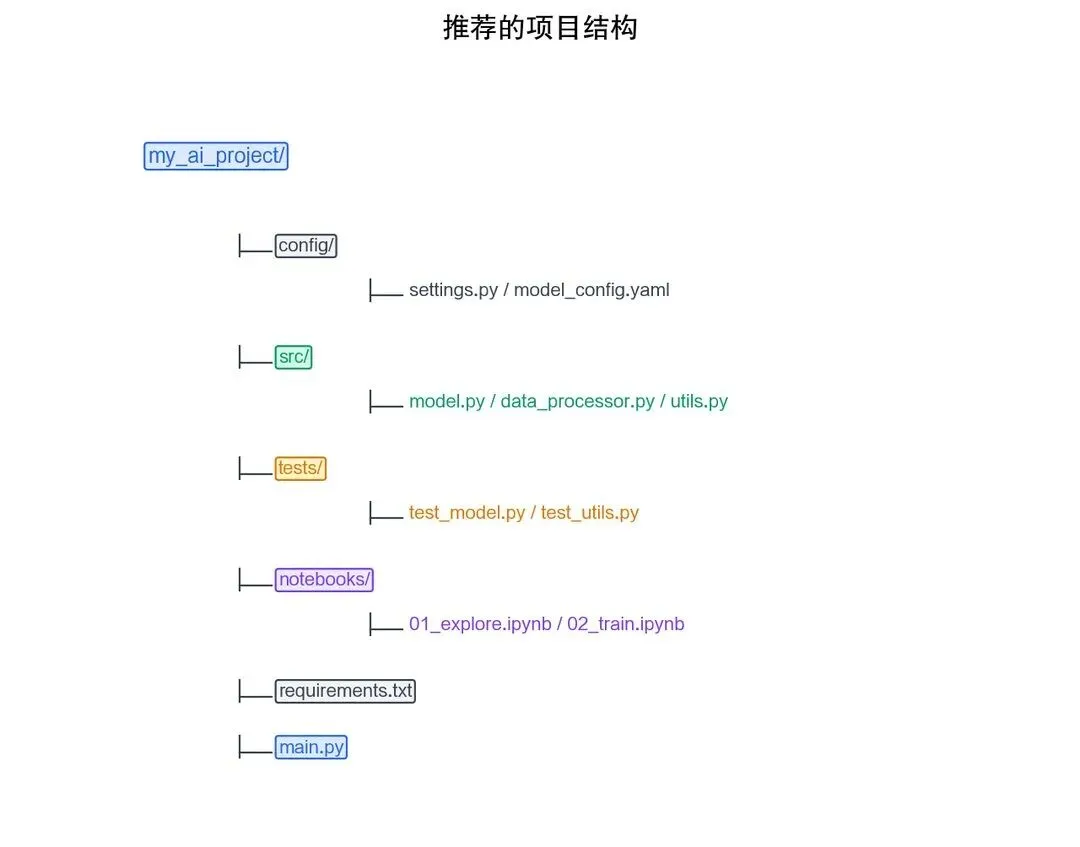
图2-11
# 第2章/python
# src/utils.py - 工具模块
def count_tokens(text: str) -> int:
"""估算 Token 数"""
return len(text) // 2 # 简化估算
def load_config(path: str) -> dict:
"""加载配置文件"""
import json
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
# main.py - 主程序(导入并使用模块)
from src.utils import count_tokens, load_config
config = load_config("config/settings.json")
tokens = count_tokens("这是一段测试文本")
2.5 常用第三方库:NumPy、Pandas、Requests
2.5.1 库功能全景图
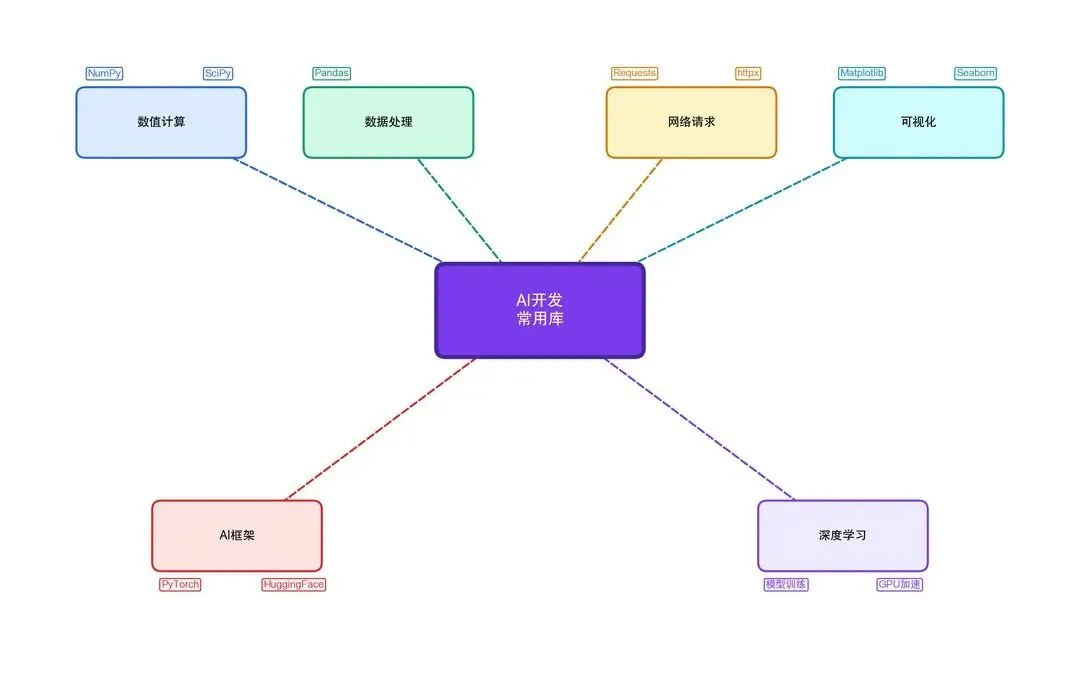
图2-12
2.5.2 NumPy:数值计算的基石
NumPy 是几乎所有 AI 库的底层依赖。理解 NumPy 就理解了 AI 中的数据表示方式。
# 第2章/python
import numpy as np
# 创建数组
a = np.array([1, 2, 3, 4, 5]) # 一维数组
b = np.array([[1, 2, 3], [4, 5, 6]]) # 二维数组(矩阵)
zeros = np.zeros((3, 4)) # 3x4 的全零矩阵
ones = np.ones((2, 3)) # 2x3 的全一矩阵
rand = np.random.randn(3, 3) # 3x3 的随机矩阵
# 数组属性
print(b.shape) # (2, 3) - 形状
print(b.dtype) # int64 - 数据类型
print(b.ndim) # 2 - 维度数
# 数组运算(逐元素运算,不需要写循环!)
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
print(x + y) # [5 7 9]
print(x * y) # [4 10 18]
print(x ** 2) # [1 4 9]
print(np.dot(x, y)) # 32(点积/内积)
# 矩阵运算(AI 中最核心的运算)
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
print(A @ B) # 矩阵乘法
# [[19 22]
# [43 50]]
# 广播机制(Broadcasting)—— NumPy 的强大之处
matrix = np.array([[1, 2, 3], [4, 5, 6]]) # (2, 3)
vector = np.array([10, 20, 30]) # (3,)
print(matrix + vector) # vector 自动扩展到每一行
# [[11 22 33]
# [14 25 36]]
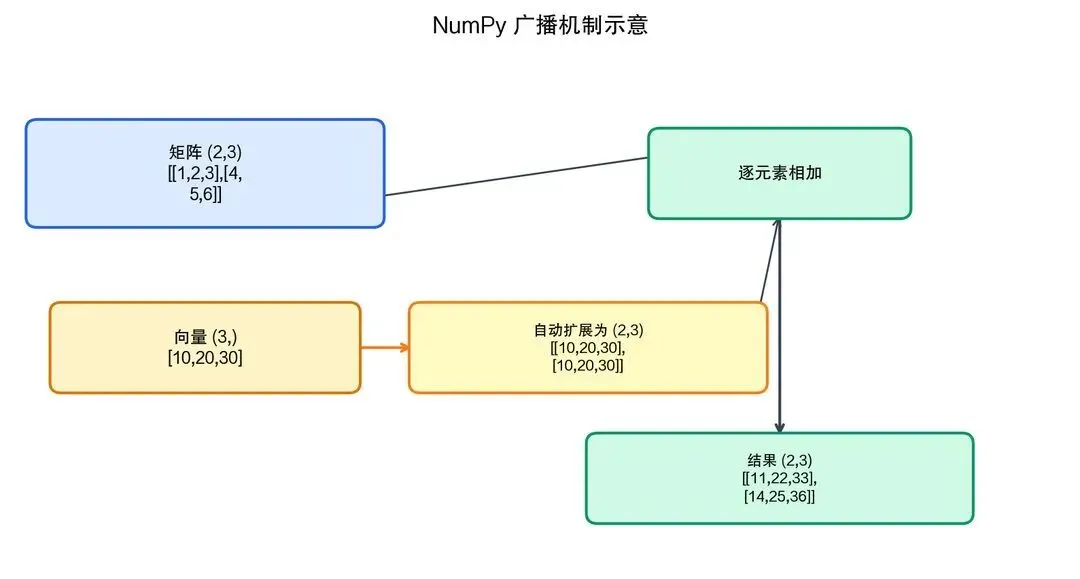
图2-13
2.5.3 Pandas:数据处理利器
# 第2章/python
import pandas as pd
# 创建 DataFrame(最核心的数据结构)
data = {
"模型": ["GPT-4o", "Claude 3.5", "DeepSeek-V3", "Qwen-Max"],
"厂商": ["OpenAI", "Anthropic", "DeepSeek", "阿里"],
"评分": [95, 93, 91, 89],
"开源": [False, False, True, False],
"价格_每百万Token": [2.5, 3.0, 0.27, 0.8]
}
df = pd.DataFrame(data)
# 基本查看
print(df.head()) # 前5行
print(df.describe()) # 统计摘要
print(df.info()) # 列信息
# 筛选与过滤
top_models = df[df["评分"] >= 93] # 评分>=93的模型
cheap_models = df[df["价格_每百万Token"] < 1.0] # 便宜的模型
open_source = df[df["开源"] == True] # 开源模型
# 排序
df_sorted = df.sort_values("评分", ascending=False)
# 新增列
df["性价比"] = df["评分"] / df["价格_每百万Token"]
# 读写文件
df.to_csv("model_comparison.csv", index=False, encoding="utf-8-sig")
df_loaded = pd.read_csv("model_comparison.csv")
2.5.4 Requests:网络请求与 API 调用
# 第2章/python
import requests
import json
# GET 请求
response = requests.get("https://api.github.com/users/octocat")
print(response.status_code) # 200
print(response.json()) # 解析 JSON 响应
# POST 请求(API 调用的标准方式)
url = "https://api.deepseek.com/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer your-api-key"
}
payload = {
"model": "deepseek-chat",
"messages": [
{"role": "user", "content": "你好"}
]
}
response = requests.post(url, headers=headers, json=payload)
result = response.json()
print(result["choices"][0]["message"]["content"])
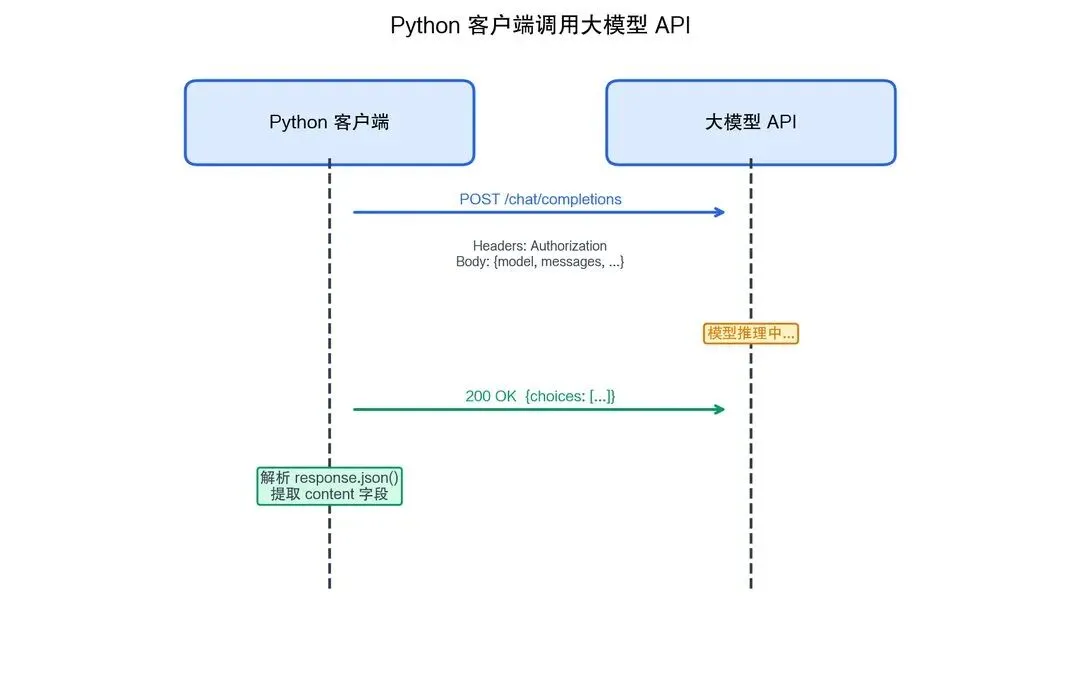
图2-14
2.6 Jupyter Notebook 使用技巧
2.6.1 什么是 Jupyter Notebook
Jupyter Notebook 是 AI 开发者最常用的交互式开发环境,它的核心理念是"边写边运行,边看结果":
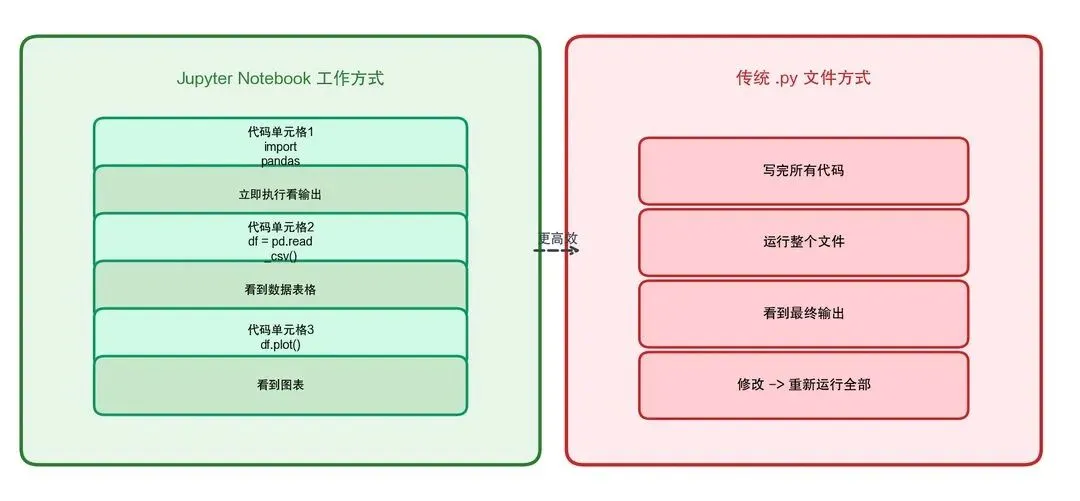
图2-15
2.6.2 安装与启动
# 第2章/bash
# 安装
pip install jupyter notebook
# 或安装更现代的 JupyterLab
pip install jupyterlab
# 启动
jupyter notebook # 经典版
jupyter lab # 现代版(推荐)
2.6.3 快捷键速查
表2-2
2.6.4 魔法命令
# 第2章/python
# 计时(优化性能时必用)
%time result = heavy_computation() # 单次计时
%timeit result = heavy_computation() # 多次计时取平均
# 查看变量信息
%whos # 列出所有变量
# 运行外部脚本
%run my_script.py
# 在 Notebook 中安装包
!pip install transformers
# 内联显示 Matplotlib 图表
%matplotlib inline
2.7 实战:编写你的第一个数据处理脚本
实战目标
编写一个完整的数据处理脚本,从 CSV 文件中读取大模型评测数据,进行清洗、分析和可视化。
实战架构
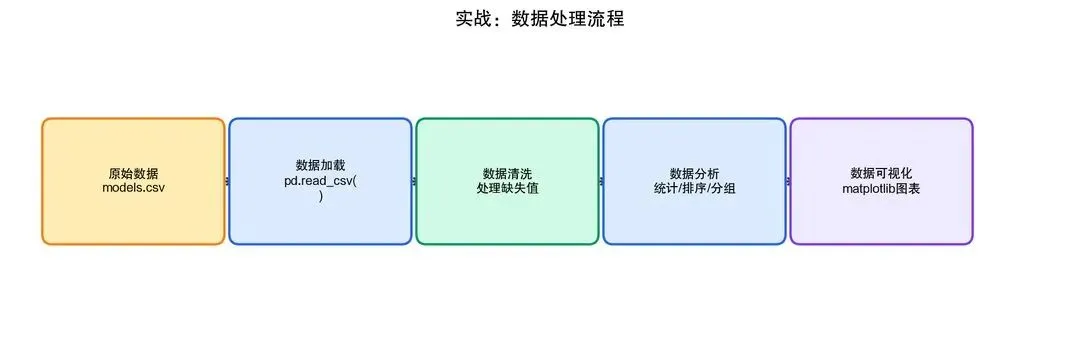
图2-16
完整代码
# 第2章/python
"""
第2章实战:大模型评测数据分析脚本
功能:
1. 生成模拟的大模型评测数据
2. 数据清洗与预处理
3. 统计分析
4. 可视化展示
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
# 设置中文字体(解决中文乱码问题)
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
matplotlib.rcParams['axes.unicode_minus'] = False
def generate_sample_data() -> pd.DataFrame:
"""生成模拟的大模型评测数据"""
np.random.seed(42)
models = [
"GPT-4o", "GPT-4o-mini", "Claude-3.5-Sonnet", "Claude-3-Haiku",
"Gemini-1.5-Pro", "Gemini-1.5-Flash", "DeepSeek-V3", "DeepSeek-R1",
"Qwen-Max", "Qwen-Plus", "GLM-4", "LLaMA-3.1-405B",
"LLaMA-3.1-70B", "Mistral-Large", "Yi-Large"
]
data = {
"模型名称": models,
"厂商": [
"OpenAI", "OpenAI", "Anthropic", "Anthropic",
"Google", "Google", "DeepSeek", "DeepSeek",
"阿里", "阿里", "智谱AI", "Meta",
"Meta", "Mistral", "零一万物"
],
"语言理解": np.random.uniform(75, 98, len(models)).round(1),
"代码能力": np.random.uniform(70, 96, len(models)).round(1),
"数学推理": np.random.uniform(60, 95, len(models)).round(1),
"中文能力": np.random.uniform(65, 98, len(models)).round(1),
"多模态": np.random.uniform(50, 95, len(models)).round(1),
"价格_每百万Token": [2.5, 0.15, 3.0, 0.25, 1.25, 0.075,
0.27, 0.55, 0.8, 0.4, 1.0, None,
None, 2.0, 0.6],
"开源": [False, False, False, False, False, False,
True, True, False, False, False, True,
True, False, False]
}
return pd.DataFrame(data)
def clean_data(df: pd.DataFrame) -> pd.DataFrame:
"""数据清洗"""
print("=" * 50)
print("数据清洗")
print("=" * 50)
# 查看缺失值
print(f"\n缺失值统计:\n{df.isnull().sum()}")
# 处理缺失的价格(开源模型标记为0)
df["价格_每百万Token"] = df["价格_每百万Token"].fillna(0)
# 计算综合得分
score_columns = ["语言理解", "代码能力", "数学推理", "中文能力", "多模态"]
df["综合得分"] = df[score_columns].mean(axis=1).round(1)
print(f"\n清洗后数据形状: {df.shape}")
print(f"清洗后缺失值: {df.isnull().sum().sum()}")
return df
def analyze_data(df: pd.DataFrame):
"""数据分析"""
print("\n" + "=" * 50)
print("数据分析")
print("=" * 50)
# Top 5 模型
print("\n综合得分 Top 5:")
top5 = df.nlargest(5, "综合得分")[["模型名称", "综合得分", "厂商"]]
print(top5.to_string(index=False))
# 按厂商分组统计
print("\n各厂商平均综合得分:")
vendor_avg = df.groupby("厂商")["综合得分"].mean().sort_values(ascending=False)
print(vendor_avg.round(1).to_string())
# 开源 vs 闭源对比
print("\n开源 vs 闭源 平均得分:")
open_vs_closed = df.groupby("开源")["综合得分"].agg(["mean", "std", "count"])
open_vs_closed.index = ["闭源", "开源"]
print(open_vs_closed.round(1).to_string())
# 性价比分析(排除免费模型)
paid = df[df["价格_每百万Token"] > 0].copy()
paid["性价比"] = (paid["综合得分"] / paid["价格_每百万Token"]).round(1)
print("\n性价比 Top 5(得分/价格):")
print(paid.nlargest(5, "性价比")[["模型名称", "综合得分",
"价格_每百万Token", "性价比"]].to_string(index=False))
def visualize_data(df: pd.DataFrame):
"""数据可视化"""
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
fig.suptitle("AI 大模型评测数据分析报告", fontsize=18, fontweight='bold')
# 图1:综合得分排名(水平柱状图)
ax1 = axes[0, 0]
df_sorted = df.sort_values("综合得分", ascending=True)
colors = ['#4CAF50' if x else '#2196F3' for x in df_sorted["开源"]]
ax1.barh(df_sorted["模型名称"], df_sorted["综合得分"], color=colors)
ax1.set_xlabel("综合得分")
ax1.set_title("各模型综合得分排名")
ax1.legend(["开源", "闭源"], loc="lower right")
# 图2:各维度得分对比(前5名模型)
ax2 = axes[0, 1]
top5 = df.nlargest(5, "综合得分")
dimensions = ["语言理解", "代码能力", "数学推理", "中文能力", "多模态"]
x = np.arange(len(dimensions))
width = 0.15
for i, (_, row) in enumerate(top5.iterrows()):
offset = (i - 2) * width
ax2.bar(x + offset, [row[d] for d in dimensions], width,
label=row["模型名称"])
ax2.set_xticks(x)
ax2.set_xticklabels(dimensions, rotation=15)
ax2.set_ylabel("得分")
ax2.set_title("Top5 模型各维度对比")
ax2.legend(fontsize=8)
# 图3:价格 vs 得分散点图
ax3 = axes[1, 0]
paid = df[df["价格_每百万Token"] > 0]
ax3.scatter(paid["价格_每百万Token"], paid["综合得分"],
s=100, alpha=0.7, c='#FF5722', edgecolors='black')
for _, row in paid.iterrows():
ax3.annotate(row["模型名称"],
(row["价格_每百万Token"], row["综合得分"]),
fontsize=7, ha='center', va='bottom')
ax3.set_xlabel("价格($/百万Token)")
ax3.set_ylabel("综合得分")
ax3.set_title("价格 vs 综合得分")
# 图4:厂商平均分对比
ax4 = axes[1, 1]
vendor_avg = df.groupby("厂商")["综合得分"].mean().sort_values(ascending=True)
ax4.barh(vendor_avg.index, vendor_avg.values, color='#9C27B0', alpha=0.7)
ax4.set_xlabel("平均综合得分")
ax4.set_title("各厂商平均综合得分")
plt.tight_layout()
plt.savefig("model_analysis_report.png", dpi=150, bbox_inches='tight')
print("\n图表已保存为 model_analysis_report.png")
plt.show()
def main():
"""主流程"""
# Step 1: 生成数据
print("Step 1: 生成模拟数据...")
df = generate_sample_data()
df.to_csv("models_raw.csv", index=False, encoding="utf-8-sig")
print(f"原始数据已保存,共 {len(df)} 条记录")
# Step 2: 数据清洗
df = clean_data(df)
# Step 3: 数据分析
analyze_data(df)
# Step 4: 可视化
print("\nStep 4: 生成可视化报告...")
visualize_data(df)
# Step 5: 保存清洗后的数据
df.to_csv("models_cleaned.csv", index=False, encoding="utf-8-sig")
print("\n清洗后数据已保存为 models_cleaned.csv")
print("\n全部完成!")
if __name__ == "__main__":
main()
本章小结
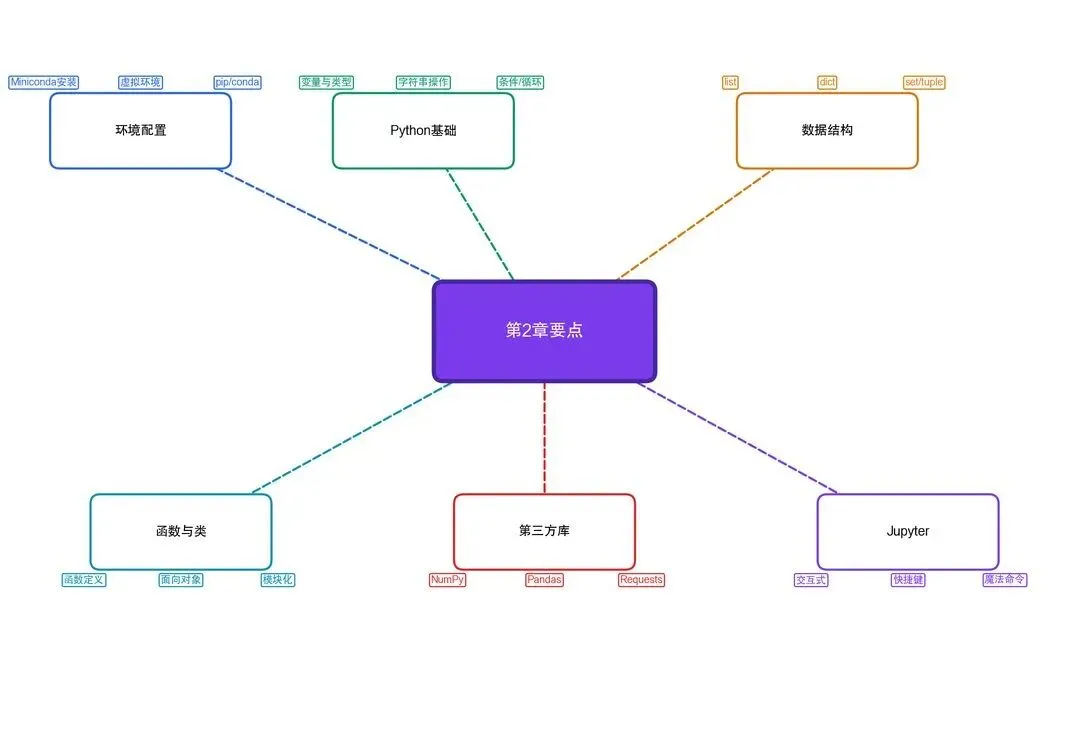
图2-17
下一章预告:有了 Python 基础,我们将正式进入深度学习的世界。第 3 章将带你理解神经网络的工作原理,并用 PyTorch 亲手实现一个手写数字识别模型。
觉得有帮助?点个 「在看」 支持一下吧

