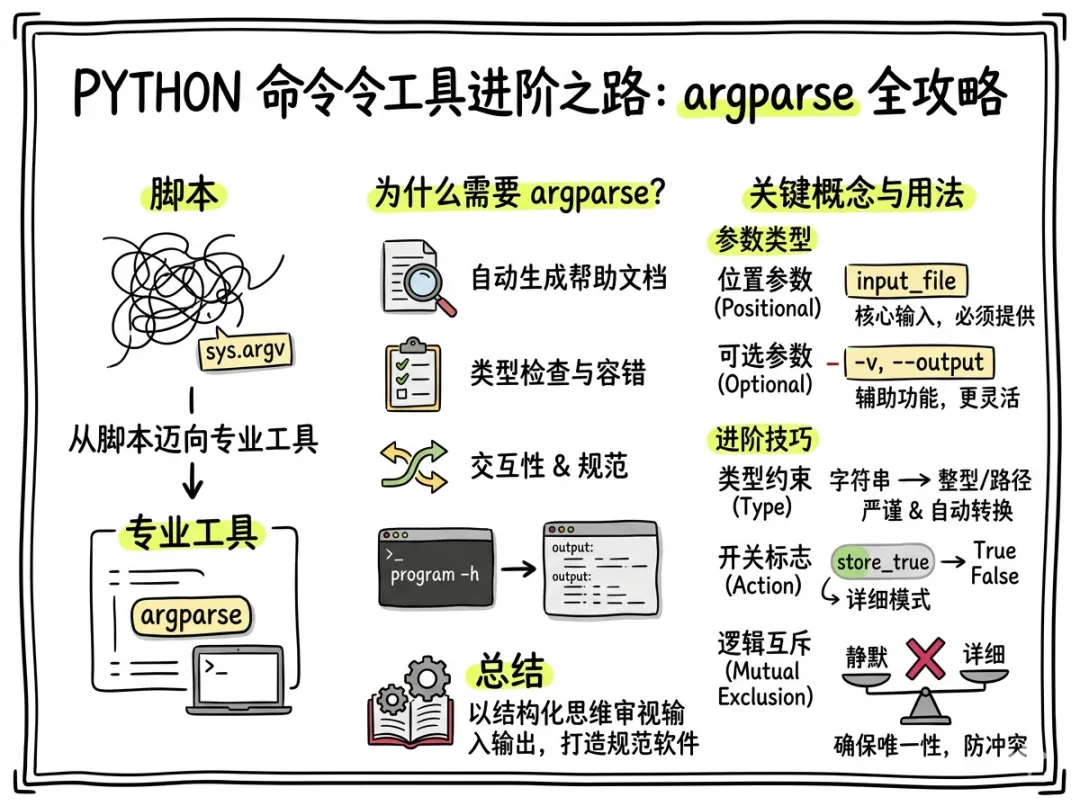
在日常编写代码的过程中,我经常发现,一个简单的脚本随着功能的迭代,往往会演变成一个复杂的工具。如果仅仅依靠 sys.argv 来解析命令行参数,代码会迅速变得难以维护且容错性极低。所以掌握 Python 标准库中的 argparse 模块,是每一位开发者从编写“脚本”向开发“专业工具”迈进的必修课。
为什么我们需要 argparse
一个优秀的命令行程序不仅要逻辑正确,更要具备良好的交互性。argparse 的核心价值在于它将参数解析、类型检查以及自动生成帮助文档集成在了一起。
当我们开始构建一个命令行工具时,首先需要创建一个 ArgumentParser 对象。这个对象就像是一个蓝图,规定了我们的程序能够接收哪些输入。
import argparse# 创建解析器parser = argparse.ArgumentParser(description="这是一个展示 argparse 基础用法的示例程序")# 解析参数args = parser.parse_args()
这段代码虽然目前什么都不做,但它已经为你提供了一个 -h 或 --help 的参数。当你运行程序并附带这个参数时,它会自动打印出你在 description 中定义的描述信息。
位置参数与可选参数
在我的日常编码经验中,参数通常被分为两类:必须要有的“位置参数”和起辅助作用的“可选参数”。
位置参数是不带前缀的参数,程序根据它们在命令行中出现的次序来识别。我认为这是处理核心输入最直观的方式。例如,如果你正在编写一个计算数值平方的工具,这个数值就是一个必须的位置参数。
parser.add_argument("echo", help="这里会显示你输入的字符串")args = parser.parse_args()print(args.echo)
然而,当我们需要控制程序的行为,比如开启调试模式或指定输出路径时,可选参数(Optional arguments)就显得尤为关键。它们通常以短横线 - 或 -- 开头。
parser.add_argument("--verbosity", help="提高输出的详细程度")
严谨的类型约束与自动转化
我一直认为,Python 的动态特性虽然灵活,但在处理命令行输入时,严格的类型检查能够规避绝大多数运行时错误。argparse 允许我们通过 type 参数直接定义输入的数据类型,它会在后台自动完成从字符串到指定类型的转换。
如果用户输入的类型不匹配,argparse 会直接报错并提示用户,而不需要我们在代码逻辑中手动写一堆 try-except。
# 指定参数为整数类型parser.add_argument("square", help="计算给定数字的平方", type=int)args = parser.parse_args()print(args.square**2)
这种自动化的处理方式,极大地提升了代码的严谨性。在处理复杂的数值计算或文件路径时,我强烈建议始终明确指定 type。
进阶操作
在追求用户体验的过程中,短选项(如 -v)和长选项(如 --verbose)的配合使用是非常必要的。此外,对于那些只需要“开启”或“关闭”的功能,使用 action="store_true" 是最优雅的方案。这意味着如果用户提供了这个参数,它的值就是 True,否则就是 False。
parser.add_argument("-v", "--verbose", action="store_true", help="显示详细日志")if args.verbose: print("详细模式已开启")
这种模式让命令行调用变得非常清爽,也符合大多数 Unix/Linux 工具的使用习惯。
确保参数的唯一性
在更复杂的场景下,我们可能会遇到互斥的参数需求。比如,一个程序不能同时既要求“静默模式”又要求“详细模式”。argparse 提供的 add_mutually_exclusive_group() 功能可以非常严谨地解决冲突问题。
这种防御性编程的思想应该贯穿始终。通过在解析层面就限制住不合理的组合,可以避免核心逻辑中出现难以排查的冲突状态。
总的来说,argparse 不仅仅是一个解析工具,它更像是一套关于命令行交互的规范。通过合理地配置位置参数、可选参数、类型约束以及互斥逻辑,我们可以让 Python 脚本呈现出专业软件的质感。
花一点时间阅读官方文档并将其应用到项目中,所带来的收益远超代码本身。它不仅让你的代码更易于他人使用,更重要的是,它强制你以一种结构化的思维去审视程序的输入与输出。