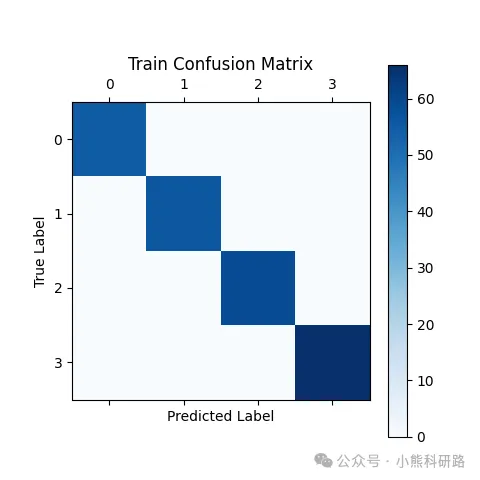
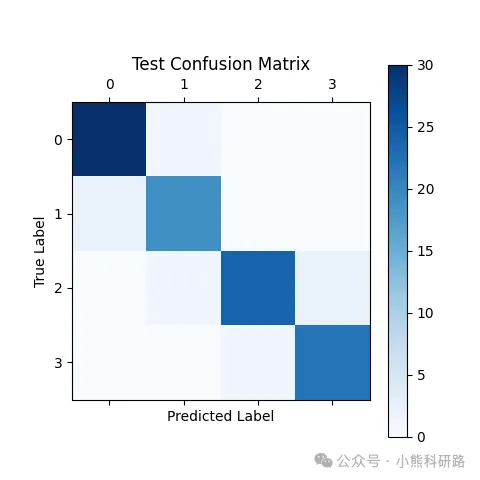
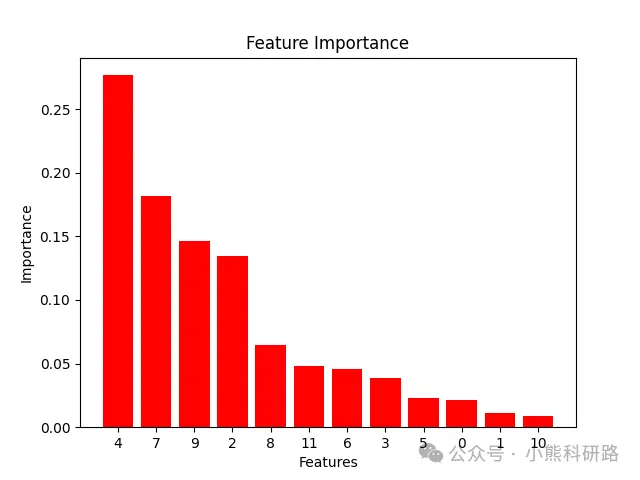
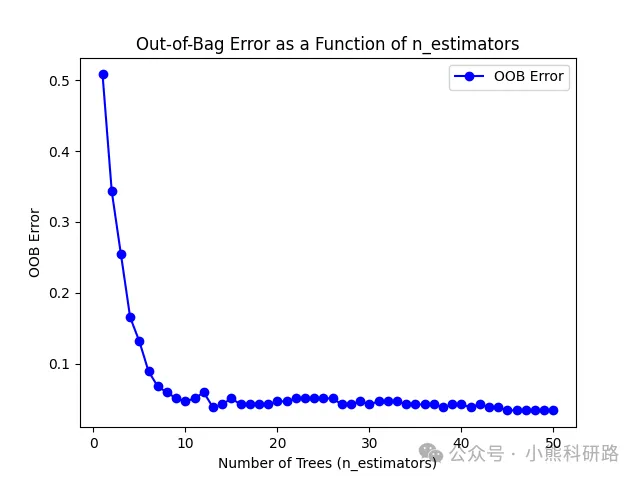
【RF分类 Python代码】基于随机森林(Random Forest)的故障诊断模型(出图多)
随机森林(Random Forest)原理基于集成学习思想,通过构建多棵决策树并集成它们的预测结果来提高模型的准确性和稳定性。具体来说,随机森林首先通过自助法(bootstrap)从原始数据集中随机抽取多个样本子集,并在每个样本子集上随机选择特征子集来构建决策树。这种随机性确保了每棵决策树都是基于不同的数据和特征进行训练的,从而减少了它们之间的相关性。在预测时,随机森林将多棵决策树的预测结果进行投票或平均,得到最终的预测结果。这种方法通过集成多个相对独立的决策树,有效降低了模型的偏差和方差,提高了预测准确性和泛化能力。以下是对随机森林的详细解释:随机森林是一个包含多个决策树的分类器,它的输出类别是由个别树输出的类别的众数决定。该方法结合了Leo Breiman的“Bootstrap aggregating”想法和Tin Kam Ho的“random subspace method”来构建决策树的集合。随机采样:从原始训练集中有放回地随机抽取多个样本,以形成多个不同的训练子集。随机选特征:对于每个训练子集,随机选择特征的一个子集来训练决策树。构建决策树:使用上述的样本子集和特征子集来构建多个决策树。集成预测:当进行预测时,每个决策树都会给出一个预测结果,随机森林通过投票(分类问题)或平均(回归问题)来决定最终的预测结果。高准确性:通过集成多个决策树,随机森林通常能够提供比单个决策树更高的预测准确性。抗过拟合:由于引入了随机性,随机森林能够减少过拟合的风险。处理大量特征:随机森林能够处理具有大量特征的数据集,且不需要进行特征降维。特征重要性评估:随机森林能够提供关于特征重要性的估计,有助于理解数据中哪些特征是影响预测结果的关键因素。计算效率高:在处理大规模数据集时,随机森林可以利用多核CPU进行并行计算,提高计算效率。计算复杂度高:由于需要训练多个决策树,因此计算复杂度相对较高。需要大量内存:由于需要存储多个决策树模型,因此需要大量内存。本文采用python编程,中文注释详细,逻辑清晰易懂,方便替换数据运行。提供x.py(pycharm平台)与x.ipynb(jiupter平台)两种文件,供您选择平台软件使用。代码获取方式
如需上述随机森林算法的多输入变量分类模型完整代码,可以点击文章下方“阅读原文”链接到代码下载网址。