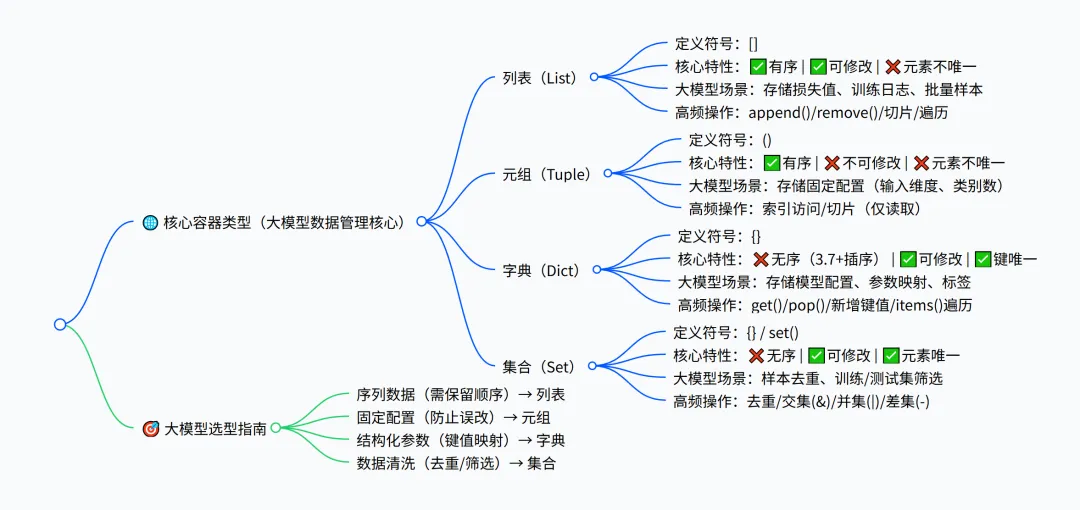
上一篇我们学会了用流程控制让代码 “动起来”,今天要攻克的容器数据类型,是处理大模型海量训练数据的核心武器!大模型需要批量存储参数、训练样本、配置信息,单靠普通变量根本不够用,而列表、元组、字典、集合这 4 种容器,就像不同功能的 “数据仓库”,能高效管理和操作数据,为后续模型训练、数据清洗打下坚实基础一、列表(List):有序可变的 “数据清单”
列表是最常用的容器,用 [] 定义,有序、可修改、可重复,特别适合存储大模型的训练日志、损失值序列、批量样本等。
1. 基础定义与访问
# 存储大模型5轮训练的损失值(有序,可修改)loss_list = [0.32, 0.28, 0.25, 0.22, 0.19]# 访问元素:索引从0开始print("第1轮损失值:", loss_list[0]) # 输出:0.32print("最后1轮损失值:", loss_list[-1]) # 输出:0.19# 切片:获取前3轮损失值print("前3轮损失值:", loss_list[:3]) # 输出:[0.32, 0.28, 0.25]
2. 常用操作(大模型开发高频)
loss_list = [0.32, 0.28, 0.25]# 1. 添加元素:追加第4轮损失值loss_list.append(0.22)print("添加后:", loss_list) # 输出:[0.32, 0.28, 0.25, 0.22]# 2. 修改元素:修正第2轮损失值loss_list[1] = 0.27print("修改后:", loss_list) # 输出:[0.32, 0.27, 0.25, 0.22]# 3. 删除元素:移除异常数据loss_list.remove(0.32)print("删除后:", loss_list) # 输出:[0.27, 0.25, 0.22]# 4. 遍历列表:计算平均损失total_loss = 0for loss in loss_list: total_loss += lossavg_loss = total_loss / len(loss_list)print("平均损失:", avg_loss) # 输出:0.24666666666666667
大模型场景:存储多轮训练的损失值、准确率,用于可视化分析模型收敛趋势。二、元组(Tuple):有序不可变的 “只读清单”元组用 () 定义,有序、不可修改、可重复,适合存储固定不变的配置信息(比如模型输入维度、固定超参数)。# 存储大模型输入维度(不可修改,防止误操作)input_shape = (512, 768) # 序列长度512,隐藏维度768# 访问元素print("序列长度:", input_shape[0]) # 输出:512print("隐藏维度:", input_shape[1]) # 输出:768
input_shape = (512, 768)# 尝试修改会报错!# input_shape[0] = 1024 # TypeError: 'tuple' object does not support item assignment
大模型场景:存储模型固定参数(如输入维度、类别数),避免代码误改导致训练崩溃。三、字典(Dict):键值对的 “配置表”
字典用 {} 定义,键唯一、值可修改,是大模型开发中最核心的容器 —— 专门用来存储模型配置、参数映射、样本标签等结构化数据。
1. 基础定义与访问
# 大模型核心配置字典(键=参数名,值=参数值)llm_config = { "model_name": "Python-LLM-Base", "learning_rate": 0.001, "batch_size": 64, "train_epochs": 100, "is_finetune": True}# 访问值:通过键名获取print("模型名称:", llm_config["model_name"]) # 输出:Python-LLM-Baseprint("学习率:", llm_config.get("learning_rate")) # 更安全的获取方式
大模型场景:存储模型超参数、数据集路径、训练策略,是配置文件和参数传递的首选。四、集合(Set):无序唯一的 “去重工具”
集合用 {} 或 set() 定义,无序、元素唯一、不可重复,适合数据清洗中的去重、交集 / 并集计算。
1. 基础定义与去重
# 模拟训练数据中重复的样本IDsample_ids = [101, 102, 101, 103, 102, 104]# 转成集合自动去重unique_ids = set(sample_ids)print("去重后样本ID:", unique_ids) # 输出:{101, 102, 103, 104}
# 训练集样本IDtrain_ids = {101, 102, 103, 104}# 测试集样本IDtest_ids = {103, 104, 105, 106}# 交集:同时出现在训练集和测试集的样本(需剔除)common_ids = train_ids & test_idsprint("重复样本ID:", common_ids) # 输出:{103, 104}# 并集:所有样本IDall_ids = train_ids | test_idsprint("所有样本ID:", all_ids) # 输出:{101, 102, 103, 104, 105, 106}
大模型场景:数据清洗阶段去重样本、筛选训练 / 测试集不重叠数据。"""实战案例:大模型训练数据预处理功能:1. 用字典存储模型配置2. 用列表存储训练损失值3. 用集合去重样本ID4. 用元组固定输入维度"""# 1. 固定配置(元组)input_shape = (512, 768)# 2. 模型配置(字典)llm_config = { "model_name": "LLM_Data_Pre", "learning_rate": 0.001, "batch_size": 32, "max_epochs": 50}# 3. 训练损失值(列表)loss_history = [0.35, 0.31, 0.28, 0.26, 0.24]# 4. 样本ID去重(集合)raw_sample_ids = [201, 202, 201, 203, 202, 204]unique_sample_ids = set(raw_sample_ids)# 5. 输出结果print("===== 大模型数据预处理结果 =====")print(f"输入维度:{input_shape}")print(f"模型配置:{llm_config}")print(f"损失值历史:{loss_history},平均损失:{sum(loss_history)/len(loss_history):.2f}")print(f"去重后样本数:{len(unique_sample_ids)},样本ID:{unique_sample_ids}")
===== 大模型数据预处理结果 =====输入维度:(512, 768)模型配置:{'model_name': 'LLM_Data_Pre', 'learning_rate': 0.001, 'batch_size': 32, 'max_epochs': 50}损失值历史:[0.35, 0.31, 0.28, 0.26, 0.24],平均损失:0.29去重后样本数:4,样本ID:{201, 202, 203, 204}
总结
- 列表:有序可变,适合存储序列数据(损失值、日志);
- 元组:有序不可变,适合存储固定配置(输入维度);
- 字典:键值对结构,是大模型配置的核心载体;
- 集合:自动去重,适合数据清洗和集合运算。
今天我们掌握了 4 种核心容器数据类型,能高效管理大模型的配置、数据和训练日志。下一篇将讲解函数与模块:把重复的数据处理、模型训练逻辑封装成函数,再打包成模块,让代码更简洁、可复用,这是大模型工程化开发的关键一步!
如果在代码中遇到问题,评论区贴出你的代码和报错信息, 觉得干货有用,点赞 + 在看 + 转发,让更多想入门大模型的朋友一起学!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
