📋 目录
🎯 什么是 Kernel Panic
定义
Kernel Panic 是 Linux 内核遇到无法恢复的致命错误时,为了防止系统进一步损坏而主动触发的系统崩溃机制。当 Panic 发生时,内核会:
停止所有 CPU 的执行
打印错误信息和调用栈
可选地生成内存转储(crash dump)
根据配置重启或停机
Panic 的严重性
为什么需要 Panic?
🔄 Panic 与 Oops 的区别
核心差异
| 特性 | Panic | Oops |
|---|
| 严重程度 | 致命,无法恢复 | 严重但可恢复 |
| 系统状态 | 立即停止 | 尝试继续运行 |
| 进程影响 | 影响整个系统 | 通常只影响当前进程 |
| 数据风险 | 防止进一步损坏 | 可能导致数据不一致 |
| 恢复方式 | 必须重启 | 杀死进程,系统继续 |
| 内存转储 | 可配置生成 | 通常不生成 |
从 Oops 到 Panic 的转换
实例对比
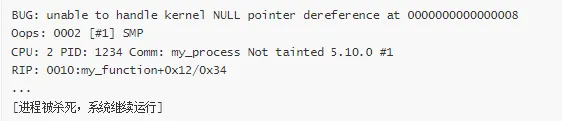
Oops 示例:
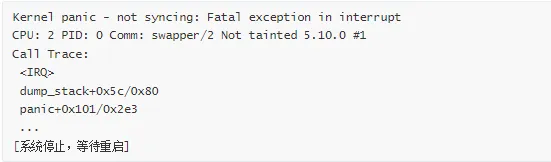
Panic 示例:
⚙️ Panic 的触发机制
触发 Panic 的方式
panic() 函数源码分析
源码位置:kernel/panic.c
/**
* panic - 触发内核 Panic
* @fmt: 格式化字符串
*
* 这个函数永不返回
*/
Panic 流程图
触发 Panic
│
▼
禁用本地中断
│
▼
检查递归 Panic
│
▼
停止其他 CPU
(smp_send_stop)
│
▼
打印 Panic 消息
│
▼
打印调用栈
(dump_stack)
│
▼
调用通知链
(panic_notifier_list)
│
▼
生成 crash dump
(kdump/kexec)
│
▼
同步文件系统
(可选)
│
▼
根据 panic_timeout 决定
│
├─ > 0: 延迟后重启
├─ < 0: 立即重启
└─ = 0: 停机等待
相关内核参数
# 查看 Panic 相关参数
sysctl -a | grep panic
# 常用参数配置
kernel.panic =10# Panic 后 10 秒重启
kernel.panic_on_oops =1# Oops 时触发 Panic
kernel.panic_on_warn =0# Warning 时不触发 Panic
kernel.panic_on_io_nmi =0# I/O NMI 时不触发 Panic
kernel.panic_on_unrecovered_nmi =0# 不可恢复的 NMI 时不触发
kernel.softlockup_panic =0# Soft Lockup 时不触发 Panic
kernel.hung_task_panic =0# Hung Task 时不触发 Panic
# 永久配置(/etc/sysctl.conf)
echo"kernel.panic = 10" >> /etc/sysctl.conf
echo"kernel.panic_on_oops = 1" >> /etc/sysctl.conf
sysctl -p
📖 如何读懂 Panic 信息
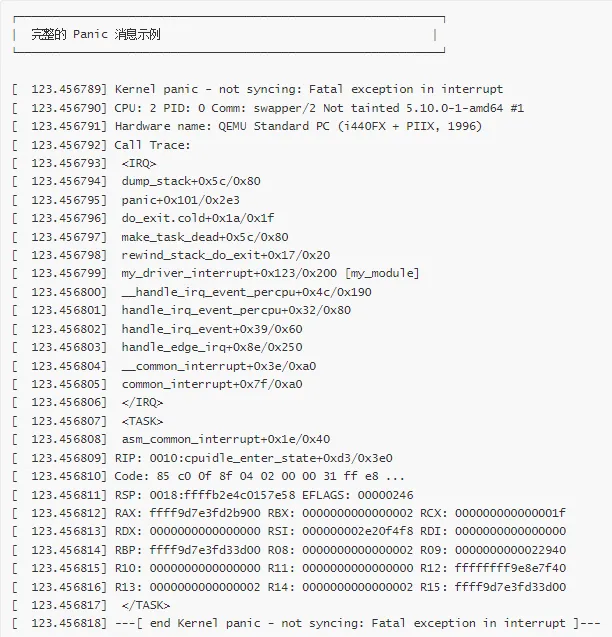
典型 Panic 消息结构
消息解读
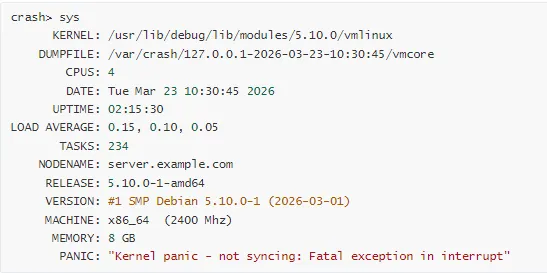
1. Panic 头部信息
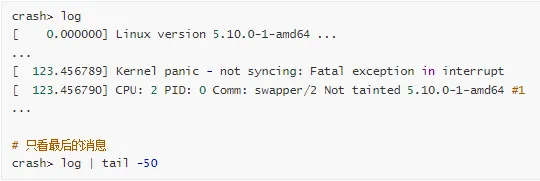
常见 Panic 原因:
Fatal exception in interrupt - 中断处理中的致命错误
Attempted to kill init! - 尝试杀死 init 进程
VFS: Unable to mount root fs - 无法挂载根文件系统
Out of memory: Kill process - 内存耗尽
Kernel stack overflow - 内核栈溢出
BUG: soft lockup - 软锁定
BUG: unable to handle kernel paging request - 内核页面请求错误
2. CPU 和进程信息
Tainted 状态解读:
P - 专有模块已加载
F - 模块被强制加载
S - SMP 内核在非 SMP 硬件上运行
R - 模块被强制卸载
M - 机器检查异常
B - 页面释放函数报告错误
U - 用户空间应用程序请求
D - 内核最近死亡(Oops 或 BUG)
A - ACPI 表被覆盖
W - 内核发出警告
C - 加载了 staging 驱动
I - 加载了平台固件错误的驱动
O - 加载了外部模块
E - 实验性补丁已应用
L - 发生了 soft lockup
K - 内核已被实时补丁
X - 辅助 taint,由 distro 定义
T - 内核使用 randstruct 构建
3. 硬件信息
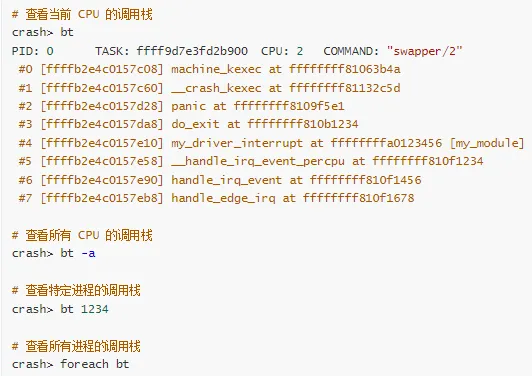
4. 调用栈(Call Trace)
调用栈解读技巧:
从下往上看:最底部是入口,最顶部是出错点
关注模块名:[my_module] 表示问题可能在该模块
注意上下文:<IRQ> 表示中断,<TASK> 表示进程
查看偏移:+0x123/0x200 表示在函数中的位置
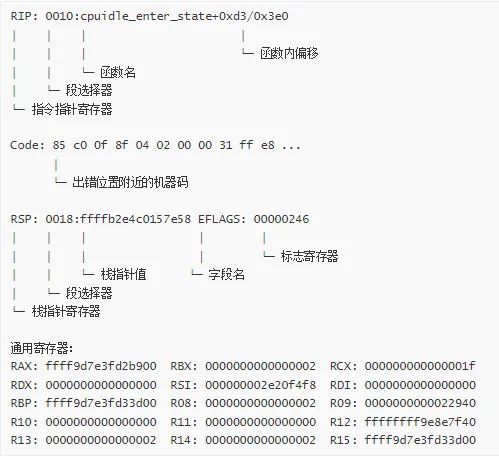
5. 寄存器状态
寄存器分析要点:
EFLAGS 标志位:
Bit Flag 含义
0 CF 进位标志
2 PF 奇偶标志
4 AF 辅助进位标志
6 ZF 零标志
7 SF 符号标志
8 TF 陷阱标志
9 IF 中断使能标志
10 DF 方向标志
11 OF 溢出标志
🔍 常见 Panic 场景分析
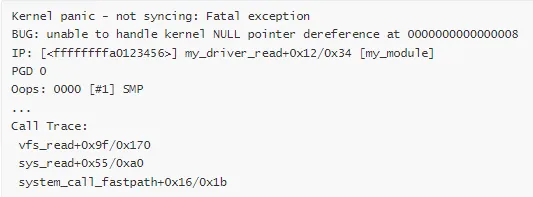
场景 1:空指针解引用导致的 Panic
Panic 消息:
原因分析:
// 问题代码
struct my_device *dev=NULL;
int value=dev->register_value; // 空指针解引用!
解决方案:
// 修复代码
struct my_device*dev=get_device();
if (!dev) {pr_err("Device not found\n");return -ENODEV;
}
int value=dev->register_value; // 安全访问
预防措施:
始终检查指针是否为 NULL
使用静态分析工具(sparse、coccinelle)
启用 KASAN 检测
代码审查
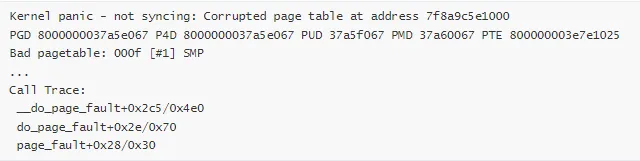
场景 2:内存损坏导致的 Panic
Panic 消息:
常见原因:
缓冲区溢出
char buffer[10];
strcpy(buffer, very_long_string); // 溢出!
Use-After-Free
kfree(ptr);
ptr->value=123; // 使用已释放的内存!
Double Free
kfree(ptr);
kfree(ptr); // 重复释放!
调试方法:
# 启用 KASAN(内核地址消毒器)
CONFIG_KASAN=y
CONFIG_KASAN_INLINE=y
# 启用 SLUB 调试
CONFIG_SLUB_DEBUG=y
slub_debug=FZPU
# 启用页面所有者跟踪
CONFIG_PAGE_OWNER=y
解决方案:
// 使用安全的字符串函数
strncpy(buffer, source, sizeof(buffer) -1);
buffer[sizeof(buffer) -1] ='\0';
// 释放后置空指针
kfree(ptr);
ptr=NULL;
// 使用引用计数
kref_get(&obj->refcount);
// ... 使用对象 ...
kref_put(&obj->refcount, obj_release);
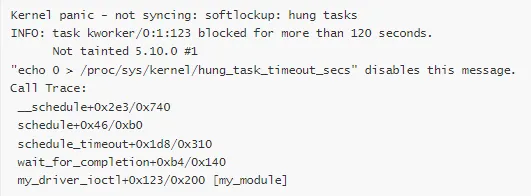
场景 3:死锁导致的 Panic
Panic 消息:
死锁类型:
自死锁(Self-Deadlock)
spin_lock(&my_lock);
// ... 一些代码 ...
spin_lock(&my_lock); // 死锁!
AB-BA 死锁
// 线程 1
spin_lock(&lock_a);
spin_lock(&lock_b); // 等待 lock_b
// 线程 2
spin_lock(&lock_b);
spin_lock(&lock_a); // 等待 lock_a
循环死锁
线程 A 持有锁 1,等待锁 2
线程 B 持有锁 2,等待锁 3
线程 C 持有锁 3,等待锁 1
检测工具:
# 启用 lockdep 死锁检测
CONFIG_PROVE_LOCKING=y
CONFIG_LOCK_STAT=y
CONFIG_DEBUG_LOCK_ALLOC=y
# 查看锁统计
cat /proc/lock_stat
# 查看死锁信息
dmesg | grep-i deadlock
解决方案:
// 1. 统一锁顺序
// 始终按照 lock_a -> lock_b 的顺序获取
// 2. 使用 trylock
if (spin_trylock(&lock_b)) {// 获取成功
spin_unlock(&lock_b);
} else {// 获取失败,释放已持有的锁
spin_unlock(&lock_a);
// 重试或返回错误
}
// 3. 使用 RCU 无锁编程
rcu_read_lock();
ptr=rcu_dereference(global_ptr);
// 使用 ptr
rcu_read_unlock();
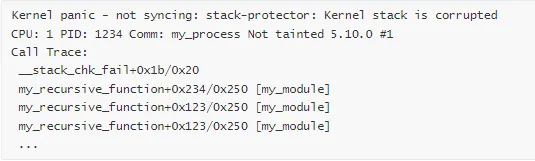
场景 4:栈溢出导致的 Panic
Panic 消息:
常见原因:
递归过深
栈上分配大数组
嵌套调用过深
function_a() -> function_b() -> function_c() -> ... -> function_z()
检测方法:
# 启用栈保护
CONFIG_STACKPROTECTOR=y
CONFIG_STACKPROTECTOR_STRONG=y
# 检查栈使用
CONFIG_DEBUG_STACK_USAGE=y
# 查看栈使用情况
cat /proc/<pid>/stack
解决方案:
💾 kdump 配置与使用
什么是 kdump?
kdump 是 Linux 内核的崩溃转储机制,当系统 Panic 时,它会:
启动一个预留的"捕获内核"(capture kernel)
将崩溃时的内存状态保存到文件(vmcore)
重启到正常内核
正常运行
│
▼
发生 Panic
│
▼
kexec 启动捕获内核
(使用预留内存)
│
▼
捕获内核启动
│
▼
保存内存转储
(vmcore 文件)
│
▼
重启到正常内核
│
▼
分析 vmcore
(使用 crash 工具)
kdump 安装配置
1. 安装 kdump 工具
# RHEL/CentOS/Fedora
yum install kexec-tools crash
# Ubuntu/Debian
apt-get install kdump-tools crash
# SUSE
zypper install kdump crash
2. 配置内核参数
编辑 GRUB 配置:
# 编辑 /etc/default/grub
vi /etc/default/grub
# 添加 crashkernel 参数
GRUB_CMDLINE_LINUX="... crashkernel=auto"
# 或手动指定大小(推荐)
# 内存 < 2GB: crashkernel=128M
# 内存 2-8GB: crashkernel=256M
# 内存 > 8GB: crashkernel=512M
GRUB_CMDLINE_LINUX="... crashkernel=256M"
# 更新 GRUB
grub2-mkconfig -o /boot/grub2/grub.cfg # RHEL/CentOS
update-grub # Ubuntu/Debian
验证预留内存:
# 查看预留的 crash 内存
cat /proc/iomem | grep-i crash
# 输出示例:
# 32000000-3fffffff : Crash kernel
# 查看 crashkernel 参数
cat /proc/cmdline | grep crashkernel
3. 配置 kdump 服务
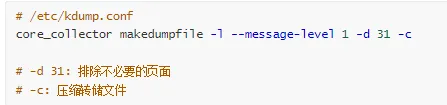
编辑 kdump 配置:
vi /etc/kdump.conf
# 配置转储路径
path /var/crash
# 配置转储级别(排除哪些内存)
core_collector makedumpfile -l--message-level1-d31
# 配置转储目标
# 本地文件系统
path /var/crash
# 网络存储(NFS)
nfs server.example.com:/export/crash
# SSH 远程存储
ssh user@server.example.com
# 配置默认动作
default reboot
makedumpfile 过滤级别:
-d 1 : 排除零页面
-d 2 : 排除缓存页面
-d 4 : 排除缓存私有页面
-d 8 : 排除用户空间页面
-d 16 : 排除空闲页面
-d 31 : 排除所有不必要的页面(推荐)
4. 启动 kdump 服务
# 启动 kdump
systemctl start kdump
# 设置开机自启
systemctl enable kdump
# 检查状态
systemctl status kdump
# 验证 kdump 是否就绪
kdumpctl status
测试 kdump
⚠️ 警告:以下操作会导致系统崩溃,仅在测试环境执行!
# 方法 1:使用 sysrq 触发 Panic
echo1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-trigger
# 方法 2:加载测试模块
modprobe lkdtm
echo PANIC > /sys/kernel/debug/provoke-crash/DIRECT
# 方法 3:手动触发(需要自定义模块)
insmod panic_test.ko
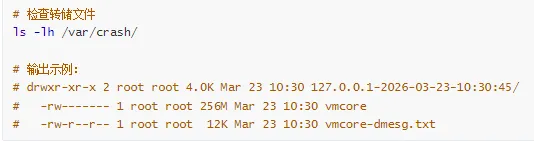
验证转储文件:
kdump 故障排查
常见问题:
kdump 服务启动失败
# 检查日志
journalctl -u kdump -xe
# 常见原因:
# - crashkernel 内存不足
# - initramfs 未正确生成
# - 内核不支持 kexec
没有生成 vmcore
# 检查配置
kdumpctl showmem # 查看预留内存
kdumpctl status # 查看服务状态
# 重新生成 initramfs
kdumpctl rebuild
vmcore 文件过大
# 调整过滤级别
vi /etc/kdump.conf
core_collector makedumpfile -l--message-level1-d31
# 压缩转储
core_collector makedumpfile -l--message-level1-d31-c
🔬 crash 工具深度分析
crash 工具简介
crash 是一个强大的内核崩溃转储分析工具,可以:
分析 vmcore 文件
查看内核数据结构
分析进程状态
检查内存使用
追踪函数调用
安装 crash
# RHEL/CentOS/Fedora
yum install crash
# Ubuntu/Debian
apt-get install crash
# 从源码编译
git clone https://github.com/crash-utility/crash.git
cd crash
make
make install
启动 crash
crash 基本命令
1. 系统信息
2. 查看 Panic 消息
3. 查看调用栈
4. 查看进程列表
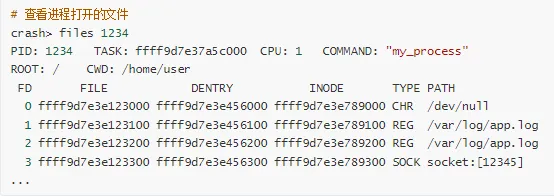
5. 查看文件描述符
6. 内存分析
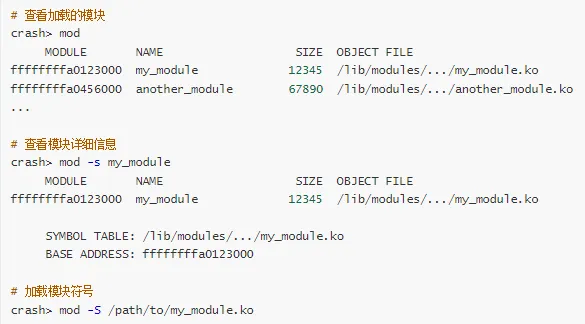
7. 模块信息
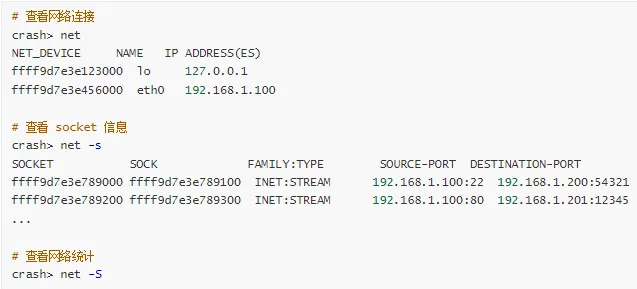
8. 网络信息
9. 中断信息
10. 数据结构分析
crash 高级技巧
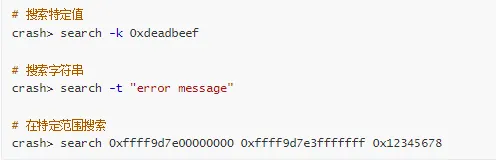
1. 搜索内存
2. 反汇编代码
3. 设置别名
# 在 .crashrc 中设置别名
alias psm ps-m
alias psr ps-r
alias psu ps-u
# 使用别名
crash> psm
4. 执行脚本
# 创建 crash 脚本 (analyze.crash)
log | tail -100
sys
bt
ps-u
kmem -i
# 执行脚本
crash> < analyze.crash
# 或在启动时执行
crash -i analyze.crash vmlinux vmcore
💡 实战案例
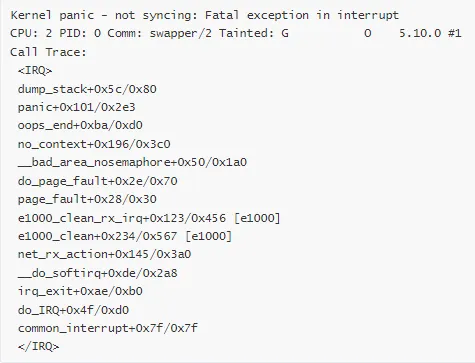
案例 1:网卡驱动导致的 Panic
场景描述:生产环境服务器突然 Panic,网络服务中断。
Panic 消息:
分析步骤:
启动 crash 分析
查看 Panic 原因
分析调用栈
查看出错代码
检查数据结构
crash> mod -s e1000
crash> struct e1000_rx_ring
# 发现 buffer_info 指针为 NULL
根本原因:网卡驱动在高负载下,rx_ring 的 buffer_info 未正确初始化就被访问。
解决方案:
// 修复代码
if (!rx_ring->buffer_info) {pr_err("buffer_info is NULL\n");return;
}
预防措施:
添加空指针检查
增加驱动压力测试
启用 KASAN 检测
代码审查
案例 2:内存泄漏导致的 OOM Panic
场景描述:系统运行一段时间后,内存逐渐耗尽,最终触发 OOM Killer 和 Panic。
Panic 消息:
分析步骤:
查看内存使用
crash> kmem -i
# 发现 SLAB 占用异常高
查看 slab 分配
crash> kmem -s | sort-k4-rn | head -20
# 发现某个 kmalloc-4096 缓存异常大
查找分配来源
crash> kmem -S kmalloc-4096
# 显示大量分配来自 my_module
分析模块代码
crash> mod -s my_module
crash> dis my_module_function
# 发现在循环中分配内存但未释放
根本原因:驱动模块在处理请求时分配内存,但在错误路径上忘记释放。
解决方案:
预防措施:
使用 kmemleak 检测
代码审查关注资源释放
使用 RAII 模式(如果可能)
添加内存使用监控
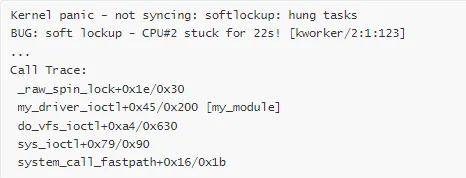
案例 3:死锁导致的 Soft Lockup Panic
场景描述:系统突然无响应,所有进程卡住,最终触发 soft lockup 检测。
Panic 消息:
分析步骤:
查看所有 CPU 状态
crash> bt -a
# 发现多个 CPU 都在等待锁
查看锁信息
crash> ps-u
# 显示多个进程处于 UN 状态(不可中断睡眠)
分析锁持有情况
crash> struct mutex 0xffffffffa0123456
# 查看锁的持有者和等待者
追踪死锁链
# CPU 0: 持有 lock_a,等待 lock_b
# CPU 1: 持有 lock_b,等待 lock_a
# 典型的 AB-BA 死锁
根本原因:两个不同的代码路径以不同的顺序获取相同的两个锁。
解决方案:
// 问题代码
// 路径 1
mutex_lock(&lock_a);
mutex_lock(&lock_b);
// 路径 2
mutex_lock(&lock_b);
mutex_lock(&lock_a);
// 修复代码:统一锁顺序
// 所有路径都按照 lock_a -> lock_b 的顺序
mutex_lock(&lock_a);
mutex_lock(&lock_b);
预防措施:
启用 lockdep 检测
定义明确的锁顺序规则
使用 trylock 避免死锁
代码审查关注锁的使用
🛡️ 预防措施
1. 代码质量保证
2. 内核调试选项
# 在开发/测试环境启用调试选项
CONFIG_DEBUG_KERNEL=y
CONFIG_DEBUG_INFO=y
CONFIG_DEBUG_STACK_USAGE=y
CONFIG_DEBUG_STACKOVERFLOW=y
CONFIG_DEBUG_ATOMIC_SLEEP=y
CONFIG_PROVE_LOCKING=y
CONFIG_LOCK_STAT=y
CONFIG_DEBUG_LOCK_ALLOC=y
CONFIG_KASAN=y
CONFIG_UBSAN=y
CONFIG_SLUB_DEBUG=y
3. 运行时检测
# 启用 lockdep
echo1 > /proc/sys/kernel/lock_stat
# 启用 hung task 检测
echo120 > /proc/sys/kernel/hung_task_timeout_secs
# 启用 soft lockup 检测
echo1 > /proc/sys/kernel/soft_watchdog
# 启用 hard lockup 检测
echo1 > /proc/sys/kernel/nmi_watchdog
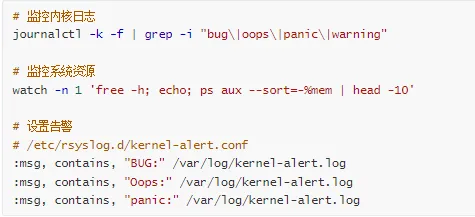
4. 监控和告警
5. 定期检查
# 检查内核日志
dmesg | grep-i"bug\|oops\|warning"
# 检查系统日志
journalctl -p err -b
# 检查硬件错误
mcelog --client
# 检查内存错误
edac-util -v
❓ FAQ 常见问题
Q1: Panic 后如何快速恢复服务?
A: 配置自动重启
# 设置 Panic 后 10 秒自动重启
sysctl -w kernel.panic=10
# 永久配置
echo"kernel.panic = 10" >> /etc/sysctl.conf
Q2: 如何在 Panic 时保存更多信息?
A: 配置 kdump 和串口日志
# 1. 配置 kdump(见前文)
# 2. 启用串口控制台
# 在 GRUB 中添加:
console=ttyS0,115200 console=tty0
# 3. 配置网络日志
# /etc/rsyslog.conf
*.* @@remote-server:514
Q3: vmcore 文件太大怎么办?
A: 调整过滤级别
Q4: 如何在没有 kdump 的情况下分析 Panic?
A: 使用串口日志或拍照
# 1. 配置串口日志(见 Q2)
# 2. 或者拍照保存屏幕信息
# 3. 手动分析调用栈
addr2line -e vmlinux -f-i 0xffffffff81234560
Q5: 生产环境是否应该启用 panic_on_oops?
A: 取决于业务需求
优点:
- 防止系统在不稳定状态下继续运行
- 保证数据一致性
- 便于问题定位(保存现场)
缺点:
- 服务中断
- 可能影响可用性
建议:
- 关键业务系统:启用(数据一致性优先)
- 高可用系统:不启用(可用性优先)
- 测试环境:启用(便于调试)
Q6: 如何区分硬件故障和软件 Bug?
A: 检查多个指标
# 1. 检查硬件日志
mcelog --client
dmesg | grep-i"hardware error"
# 2. 检查 ECC 内存错误
edac-util -v
# 3. 检查 SMART 信息
smartctl -a /dev/sda
# 4. 运行硬件诊断
memtest86+# 内存测试
stress-ng # 压力测试
# 5. 查看 Panic 消息中的 MCE(Machine Check Exception)
Q7: 如何测试 kdump 配置?
A: 使用安全的测试方法
Q8: crash 工具无法打开 vmcore 怎么办?
A: 检查版本匹配
📚 参考资料
官方文档
Linux Kernel Documentation
https://www.kernel.org/doc/html/latest/
Documentation/admin-guide/kdump/kdump.rst
Documentation/admin-guide/bug-hunting.rst
crash Utility
kdump/kexec
书籍推荐
《深入理解 Linux 内核》(第三版)
《Linux 内核设计与实现》(第三版)
《Linux 设备驱动程序》(第三版)
工具和脚本
crash Extensions
SystemTap
eBPF Tools
🎓 总结
本文全面介绍了 Linux 内核 Panic 的方方面面:
理解 Panic:定义、触发机制、与 Oops 的区别
读懂信息:Panic 消息的完整解读
场景分析:常见 Panic 场景和解决方案
工具使用:kdump 配置和 crash 工具深度使用
实战案例:真实问题的分析和解决过程
预防措施:如何避免 Panic 的发生
掌握这些知识和技能,你将能够:
✅ 快速定位 Panic 原因
✅ 有效分析 vmcore 文件
✅ 解决各种内核崩溃问题
✅ 预防潜在的系统故障
记住:Panic 虽然可怕,但它是内核保护系统的最后一道防线。通过正确的配置和分析,我们可以将 Panic 转化为宝贵的调试信息,帮助我们构建更稳定的系统。
作者:肇中
相关文章: