图解 Linux I/O 模型:同步、异步、阻塞、非阻塞,一篇搞懂五种 I/O 模式
- 2026-07-04 12:14:45
作者:小康,C/C++编程博主
关键词:阻塞 I/O、非阻塞 I/O、I/O 多路复用、信号驱动、异步 I/O、epoll、aio
前言
学过 epoll,用过 read(),但面试被问到:
"阻塞 I/O 和同步 I/O 是一回事吗?epoll 到底是同步的还是异步的?异步 I/O 又和它们有什么区别?"
很多人在这里卡壳。这几个概念确实容易混淆,因为它们来自两个不同的维度,不是同一个坐标轴上的东西。
这篇文章,我们把这两个维度分开讲清楚,然后把五种 I/O 模型逐一图解,最后给出选型建议。
一、先搞清楚两个维度
在谈具体 I/O 模型之前,必须先把两个维度拆分清楚:
维度一:阻塞 vs 非阻塞(关注"等待数据时的行为")
阻塞:发起 I/O 调用后,如果数据没准备好,调用方挂起等待,什么都不能做 非阻塞:发起 I/O 调用后,如果数据没准备好,调用立刻返回错误码,调用方可以继续做其他事
维度二:同步 vs 异步(关注"数据从内核拷贝到用户空间时,谁来做")
同步:数据从内核拷贝到用户缓冲区这个动作,由调用方自己完成(不管之前是阻塞还是非阻塞等待的) 异步:内核负责把数据拷贝到用户缓冲区,完成后通知调用方,调用方全程不参与
这个区分点非常关键——epoll 是同步的,因为 epoll_wait 告诉你"数据到了"之后,你还得自己调 read() 把数据从内核拷出来,这个拷贝过程你是同步参与的。
记住这两个维度,下面五种模型就全部能对号入座。
二、五种 I/O 模型全景图
Linux 中有五种 I/O 模型,来看全景图:

这张全景图是本文的核心,建议保存截图。五种模型的本质区别只在两点:等待数据时谁在等、拷贝数据时谁来做。
三、模型一:阻塞 I/O(Blocking I/O)
最古老、最简单的模型。read()、recv() 默认就是阻塞的。
// 一个完整的阻塞读char buf[4096];int n = read(sockfd, buf, sizeof(buf)); // 数据没来?进程在这里睡着,啥也干不了// 数据来了,内核拷贝到 buf,read() 才返回printf("收到 %d 字节\n", n);在只有一个连接的情况下,阻塞 I/O 没什么问题。问题在于多连接:一个线程只能 read 一个 fd,于是有了"一连接一线程"的方案,但线程数一多,上下文切换开销就吃不消了。
四、模型二 & 三:非阻塞 I/O + I/O 多路复用
非阻塞 I/O 的做法是把 fd 设置成 O_NONBLOCK,read() 不会阻塞,数据没准备好就立刻返回 EAGAIN,你再轮询。
但轮询太耗 CPU:一直空转检查,100% CPU 啥活也没干。
真正有价值的是把非阻塞 fd 配合 I/O 多路复用使用——用一个调用(select/poll/epoll)同时监视多个 fd,哪个就绪再去处理哪个。

I/O 多路复用的核心优势:一个线程管理成千上万个连接,哪个连接有数据了就处理哪个,没数据就安静等待。这正是 Nginx、Redis 单线程能扛高并发的根本原因。
代码骨架(以 epoll 为例):
int epfd = epoll_create1(0);// 注册 fdstructepoll_eventev = { .events = EPOLLIN, .data.fd = sockfd };epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev);structepoll_eventevents[64];while (1) {int n = epoll_wait(epfd, events, 64, -1); // 阻塞等,有就绪才返回for (int i = 0; i < n; i++) { read(events[i].data.fd, buf, sizeof(buf)); // 自己完成拷贝(同步) handle(buf); }}注意最后一步:epoll_wait 告诉你"有数据了",但数据从内核拷贝到 buf 这一步,还是你自己调 read() 完成的——这就是为什么 epoll 属于同步 I/O。
五、模型四:信号驱动 I/O
信号驱动 I/O 的思路是:注册一个 SIGIO 信号处理函数,数据就绪时内核发信号通知你,你再去 read()。
signal(SIGIO, sigio_handler); // 注册信号处理函数fcntl(sockfd, F_SETOWN, getpid()); // 告诉内核通知我fcntl(sockfd, F_SETFL, O_ASYNC); // 开启异步通知// ... 进程继续干其他事 ...voidsigio_handler(int sig){ read(sockfd, buf, sizeof(buf)); // 数据就绪,自己来拷贝(仍是同步)}等待阶段是非阻塞的,但拷贝阶段还是自己做——仍属于同步。
实际上信号驱动 I/O 在工程里很少使用,因为信号处理函数有诸多限制(异步安全问题),并发高时信号可能丢失。了解即可,重点放在其他模型上。
六、模型五:异步 I/O(真正的异步)
前四种模型,都需要进程在某个时刻"亲自"参与数据拷贝。异步 I/O 彻底不同:
你告诉内核"帮我读,读完放到我指定的缓冲区,放好了通知我",然后就去干别的事了。内核把一切都做完,才通知你来取结果。
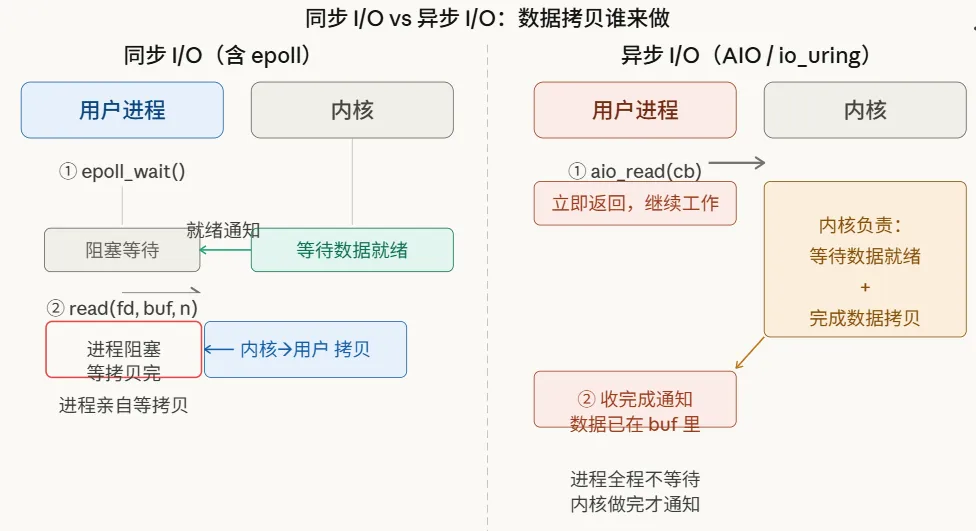
Linux 的 POSIX AIO(aio_read/aio_write)是异步 I/O 的早期实现,但有不少限制,工程上用得不多。
真正让异步 I/O 大规模落地的,是 Linux 5.1 引入的 io_uring——一套全新的异步 I/O 接口,通过共享内存环形队列在内核和用户空间之间传递请求,避免了系统调用开销,性能甚至能超过 epoll,且适用范围远不止网络 I/O。
七、五种模型横向对比
八、选型指南
连接数少(< 100),逻辑简单 └→ 阻塞 I/O + 多线程,代码最简单连接数多(C10K 问题),追求高并发 └→ epoll(I/O 多路复用)+ 非阻塞 fd + 事件循环 这是 Nginx、Redis、Netty 的核心模型追求极致性能(网络 + 文件 I/O 混合) └→ io_uring(Linux 5.1+,现代内核推荐)需要跨平台 └→ libuv(Node.js 底层)/ libevent 等封装库九、高频面试题精析
Q:epoll 是同步还是异步的?
同步。epoll_wait 通知你某个 fd 可读后,你还必须自己调 read() 把数据从内核拷贝到用户空间。这个拷贝过程是同步的,进程要等它完成。真正的异步 I/O 是连这个拷贝都由内核完成,进程全程不参与。
Q:非阻塞 I/O 和 I/O 多路复用的关系是什么?
两者常常配合使用。非阻塞 I/O 解决的是"调用不挂起"的问题,但靠轮询浪费 CPU;I/O 多路复用解决的是"监视多个 fd,哪个就绪处理哪个"的问题。epoll 告诉你哪个 fd 就绪,你再用非阻塞方式 read() 它,读到 EAGAIN 为止——两者组合才是高效方案。
Q:select、poll、epoll 三者的核心区别?
核心是性能和原理上的区别:select 和 poll 每次调用都把全量 fd 拷入内核,返回后还需 O(n) 遍历找就绪的;epoll 用红黑树维护注册 fd(一次注册),用就绪链表直接返回就绪的 fd,O(1) 获取结果,连接越多优势越明显(详见 epoll 那篇)。
Q:io_uring 比 epoll 快在哪里?
两个方向:第一,epoll 通知你就绪后你还要调 read() 系统调用来拷贝数据,每次系统调用都有用户态/内核态切换开销;io_uring 用共享内存环形队列批量提交请求,内核批量完成,大幅减少系统调用次数。第二,io_uring 可以用 IORING_SETUP_SQPOLL 开启内核轮询线程,做到零系统调用提交。
结语
把本文核心用一句话总结:
阻塞/非阻塞描述"等待时的姿态",同步/异步描述"拷贝时谁来做",这是两个独立维度。
理解了这两个维度,你就能准确回答"epoll 是同步的"、"select 是同步阻塞"、"io_uring 才是真异步"这些问题,而不是靠死记硬背。
这也是为什么 Redis 单线程 + epoll 能跑出如此高的吞吐——I/O 多路复用用好了,一个线程足以管理数万连接。
📌 还在打基础?从这里出发
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急——三门入门课程帮你打好地基:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
🚀 基础扎实了?来做工业级项目
如果你已经有一定基础,想冲击更高的天花板,这些工业级 C++ 项目正是为你准备的:
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
对C++项目实战课程感兴趣的朋友,可以扫下方二维码添加小康微信(或微信搜索:jkfwdkf ) 备注「 项目实战 」

觉得有收获,点赞、推荐、转发支持下哦~ 🙏

