Python 还是 Stata?AI时代似乎不用二选一
最近看到徐轶青老师在推特上说,自己将停止维护 Stata 包,转向更开放的 R 和 Python。Python还是Stata是从我上大一就一直在问/被人在问的问题。六年下来,我越来越觉得,这个问题本身就问偏了。真正该问的不是“选哪门语言”,而是:你到底在做工程,还是在做推断?你要的是“写得快”,还是“结果能被信任”?
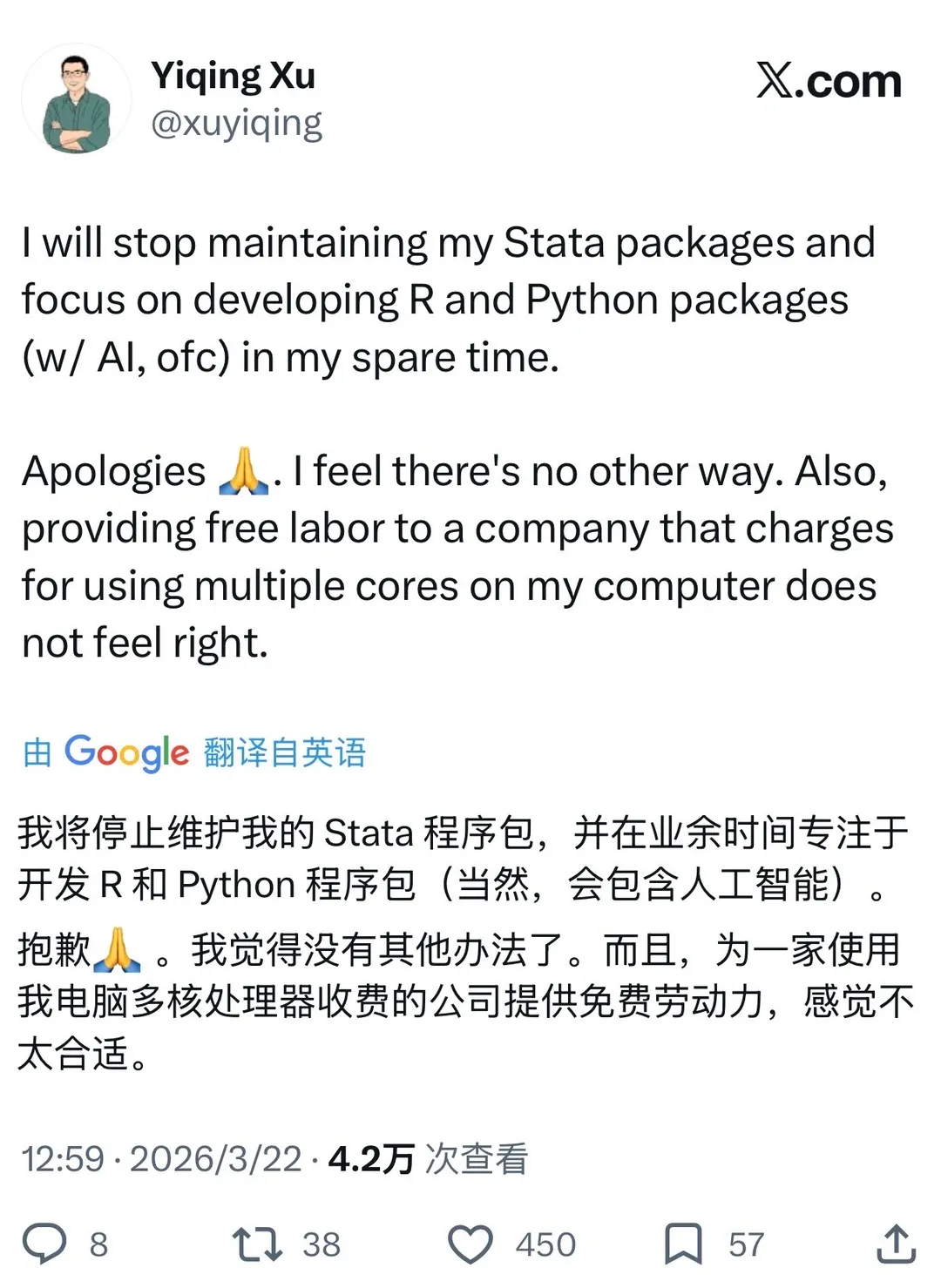
我的答案越来越明确:数据清理、爬虫、文本处理、自动化、TeX 表格整理,用 Python;核心统计推断、回归估计、标准误、固定效应、政策评估,用 Stata 或 R。不是因为 Python 不强,而是因为在实证研究里,很多人以为自己跑的是“同一个模型”,实际上跑的只是“看起来名字一样的模型”。
一、同样叫回归,不代表真的是同一个回归
很多初学者第一次用 Python 做回归时,会有一种错觉: “我都把 (y) 和 (X) 喂进去了,系数也差不多,那不就等于复现了吗?”
但现实是,连最基础的 OLS,不同软件默认设定都可能不一样。
1. 设计矩阵就可能已经不一样了
statsmodels 的底层 OLS 接口默认不会自动加常数项,而且 missing 默认是 none;如果你想自动删缺失值,要显式写 missing='drop'。相反,Stata 的 regress 默认包含截距项;R 的公式接口也默认包含截距项。也就是说,你以为自己在“复现同一个回归”,实际上样本和设计矩阵可能第一步就已经不一致了。(Statsmodels)
这件事看起来很基础,但恰恰因为基础,最容易被忽略。很多人不是卡在多高深的方法上,而是卡在这种“默认值不一致”的细节上。
2. 标准误不是一个按钮,而是一整套选择
更大的坑在标准误。 在 statsmodels 里,稳健或聚类标准误不是一个“开/关”问题,而涉及 use_correction、df_correction 等设定。官方文档明确写了:聚类标准误下,如果开启 df_correction,推断统计量的自由度会从“总样本量减参数数”切换成“组数减一”;当 cluster 数不多时,p 值会明显变化。对于某些 GLM 和离散选择模型,statsmodels 甚至直接说明,可以通过额外的 scaling_factor=(n-1)/(n-k) 去把协方差缩放到更接近 Stata 的结果。(Statsmodels)
有意思的是,statsmodels 另一个页面又写到,它的单向 cluster 协方差在 UCLA 的示例里和 Stata 是一样的。这个细节恰恰说明问题的关键不是“Python 一定错、Stata 一定对”,而是:你不能把不同软件的默认推断选项当成天然等价。(Statsmodels)
相比之下,R 里像 fixest 这样的包,反而把这个问题讲得更明白:标准误由 vcov 和 ssc 两部分共同决定,官方 vignette 还专门讲“如何复刻其他软件的标准误”。这说明成熟的计量软件生态,并不是没有差异,而是把差异暴露出来,让你能精确控制。(lrberge.github.io)
3. 高维固定效应更不是“多加几个 dummy”那么简单
如果说前面的坑还只是“稳健标准误没对齐”,那高维固定效应就更能说明问题。
linearmodels 的 PanelOLS 文档写得很清楚:它最多支持两类 fixed effects;而且是否丢 singleton、是否删除 absorbed variables、是否检查 rank、自由度怎么计算,都需要你关注。官方示例还特别说明:auto_df 会根据你使用的协方差估计器决定 fixed effects 是否算作损失的自由度;比如按 entity clustering 时,处理方式就和经典协方差不同。(bashtage.github.io)
而 Stata 这边,无论是官方 HDFE 功能还是 reghdfe,处理逻辑都更接近实证研究者的常用工作流: 可以吸收多组高维分类变量,reghdfe 会迭代删除 singleton observations,并且在多组 fixed effects 下对损失的自由度给出保守近似,还支持 multi-way clustering。reghdfe 的帮助文档甚至直接把这些点写成了核心特性。(Stata)
所以很多人说“我在 Python 里也能跑 fixed effects”,这句话往往只说对了一半。 能跑,不等于和 Stata / fixest / reghdfe 在样本处理、自由度、标准误、单例组、被吸收变量、可支持的 fixed effects 维度上是同一件事。
二、为什么这些差异在论文里尤其致命?
因为在实证研究里,最危险的不是程序报错,而是程序安静地给你一个看起来很像、但其实不是同一个定义下的结果。
这也是我为什么一直不太信任“拿通用 Python 统计包就直接做计量”的做法。不是因为 Python 不能做,而是因为 Python 生态里太多包是先服务“可用性”和“通用性”,不是先服务“计量传统里的默认约定”。
工程世界更在意的是:接口统一、上手简单、能接生产。 研究世界更在意的则是:这个标准误到底是哪一种?finite-sample correction 有没有开?固定效应损失了多少自由度?单例组有没有被删?cluster 的维度到底怎么定义?最终这个结果是否和文献里那种“默认写法”一致?
这些问题,不是“运行成功”就自动解决的。
三、AI时代,是不是只有做研究才需要关注这些?
在我小红书的评论区里,有位医药行业的朋友说得特别好:

高风险领域购买的从来不只是“一个软件”,而是一整套被验证过、出了问题有人负责的流程。
在医药监管里,ICH E9 明确写到:用于数据管理和统计分析的计算机软件应当是可靠的,并且应当有适当的软件测试程序文档。FDA 关于临床试验计算机系统的指导也强调,这些数据直接关系到对安全性和有效性的判断,因此必须具备最高质量和完整性。FDA 的技术一致性指南还要求在申报中说明所使用的软件,并提交生成分析结果的程序,目的就是为了理解分析算法并确认结果。2026 年 EMA 发布的 ICH M15 进一步把话说得更直:关键的用户自编代码、公式和计算应当被记录,并且能供监管机构审查;建模活动应使用可靠、可复现、可追踪的有效计算机系统。(U.S. Food and Drug Administration)
这意味着在医药里,“我这个包开源、很方便、社区很活跃”远远不够。真正重要的是:
四、金融和政策评估,其实也是同一个逻辑
金融行业经常被外行误解成“谁模型准就用谁”。但监管框架并不是这么想的。美联储和 OCC 的 SR 11-7 明确说,机构必须关注基于错误或被误用模型所做决策带来的后果,并通过稳健的模型开发、实施、验证和治理来管理模型风险。也就是说,在金融里,模型不是一个“跑分工具”,而是一个需要被验证、被治理、被审计的决策系统。(联邦储备银行)
政策评估也是一样。OECD 在讨论政策评估时强调,尤其在危机时期,要维持公众信任,决策者必须对“政策是否有效、是否对所有人有效”负责。英国政府的 Reproducible Analytical Pipelines 策略则直接把“可复现分析”当成分析治理的一部分,强调要把分析当作软件来管理。(OECD)
所以你会发现,医药、金融、政策评估这三个看似不同的领域,底层逻辑其实完全一样:当模型结果会影响药物审批、风险资本、财政支出、福利分配时,人们要的不是“能跑”,而是“能交代”。
五、所以 Stata 和 SAS 为什么短期内还不会被淘汰?
我依然认为,长期看,AI 会持续把生态推向开源。 因为 OpenAI、Anthropic 这类公司天然更愿意服务 R/Python 这样开放、更新快、语料多的语言生态;随着 AI 写 R/Python 的成本越来越低,很多过去只在 Stata 里好用的方法,未来会被更快地复刻到开源世界里。
但是,这不等于 Stata 和 SAS 会立刻消失。
原因很简单: 它们卖的从来不只是语法,而是机构信任、历史积累、审稿共识、培训成本、版本稳定性、审计便利性,以及“默认约定已经嵌进组织流程”的那种低摩擦。上面那些医药、金融、政策领域的监管文件,本质上都在推同一件事:可靠、可复现、可追踪、可审查。只要这些要求还在,能把这些要求打包成低交易成本工作流的软件,就不会轻易退出舞台。(European Medicines Agency (EMA))
所以我现在的判断是:
AI 会先淘汰“写代码的体力活”,不会先淘汰“验证结果的脑力活”。AI 会先削弱语言之间的使用门槛,不会立刻消灭高风险行业对“验证过的软件和流程”的偏好。 Stata / SAS 的护城河,短期内不在“更好写”,而在“更好交代”。
六、我自己的解决方案:让 Python 做外壳,让 Stata / R 做推断
所以我现在的做法很实用主义:
- 数据清理、爬虫、自动化、文本处理、表格整理、画图:Python
比如我会用 pystata,或者直接让 Python 调 Stata,把回归结果再交给 Python 去整理成论文表格、出图、做自动化检查。 这样做的好处是:
第一,我仍然待在自己熟悉的 Python 工作流里; 第二,我不需要为了“全栈统一”去牺牲已经被大量研究者反复使用和检验过的统计实现; 第三,我可以把 AI 最擅长的部分——自动化、脚本生成、表格整理、管线连接——都吃满。
七、给想用 Python 做计量的人几个建议
如果你坚持用 Python 做核心计量,我的建议不是“别用”,而是“别天真地用”。
至少要做几件事:
- 先对齐定义,再比较结果。截距、样本筛选、缺失值处理、权重、cluster 维度、自由度修正,必须逐项对齐。(Statsmodels)
- 优先选“面向计量”的包,而不是“通用统计”的包。例如
pyfixest 现在明确把目标写成尽可能镜像 R 的 fixest 默认设定,这就比“我随便拿个回归包先跑起来”更适合实证研究。(PyPI) - 保留一份 Stata / R 的基准结果。Python 跑出来以后,拿一个最小样本做 cross-check。不要一上来就相信“系数差不多所以应该没问题”。
- 把验证当成流程的一部分。AI 时代,代码会越来越便宜;真正昂贵的,是确认这段代码是不是在算你以为它在算的那个东西。
结语
所以,Python 还是 Stata? 我的答案是:AI 时代根本不需要二选一。
Python 负责把研究者从重复劳动里解放出来; Stata / R 负责把推断留在更稳定、更透明、约定更成熟的统计传统里。
真正的问题也从来不是“哪门语言更先进”,而是: 当你把一个结果写进论文、发给审稿人、提交给监管机构、拿去做政策建议时,你到底有没有能力证明:这个结果是可信的。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
