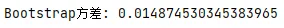在前几节中,我们的推断依赖:
但一个关键问题是:
如果分布未知、小样本、或模型复杂怎么办?
👉 Bootstrap 给出统一解决方案:
用数据本身近似分布
1核心思想
设原始样本:
Bootstrap步骤:
👉 用经验分布近似:
2数学本质
经验分布函数:
👉 Bootstrap 本质:
👉 即:
用样本分布替代真实分布
3直觉解释
可以理解为:
“假设我们当前数据就是整个世界”
然后反复“模拟采样”
4Python实现(均值分布)
# file: bootstrap_mean.pyimport numpy as npimport matplotlib.pyplot as pltdefmain(): np.random.seed(0) data = np.random.exponential(scale=1, size=50) B = 5000 means = []for _ in range(B): sample = np.random.choice(data, size=len(data), replace=True) means.append(np.mean(sample)) means = np.array(means) print("原始均值:", np.mean(data)) print("Bootstrap均值:", np.mean(means)) plt.hist(means, bins=30) plt.title("Bootstrap Distribution of Mean") plt.show()if __name__ == "__main__": main()
执行结果如下:
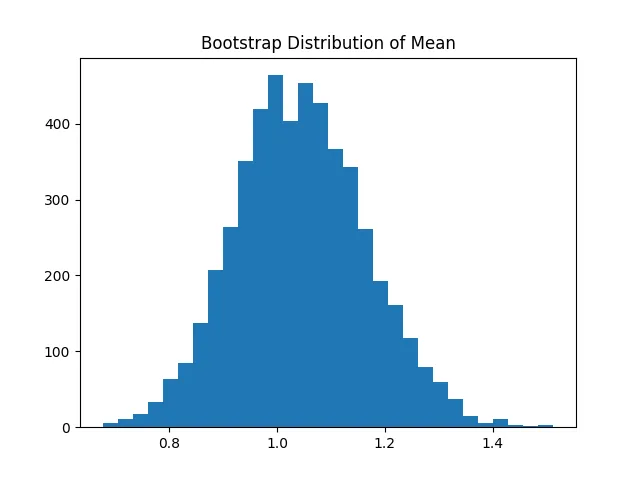
5结果解释
👉 说明:
Bootstrap成功恢复统计量分布
6Bootstrap置信区间
方法1:百分位法(Percentile)
# file: bootstrap_ci.pyimport numpy as npdefmain(): np.random.seed(0) data = np.random.exponential(1, 50) B = 5000 means = []for _ in range(B): sample = np.random.choice(data, len(data), replace=True) means.append(np.mean(sample)) lower = np.percentile(means, 2.5) upper = np.percentile(means, 97.5) print("Bootstrap CI:", lower, upper)if __name__ == "__main__": main()
执行结果如下: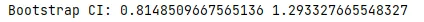
7与CLT对比
# file: bootstrap_vs_clt.pyimport numpy as npdefmain(): np.random.seed(0) data = np.random.exponential(1, 50)# CLT mean = np.mean(data) std = np.std(data, ddof=1) clt_lower = mean - 1.96 * std / np.sqrt(len(data)) clt_upper = mean + 1.96 * std / np.sqrt(len(data))# Bootstrap B = 5000 means = []for _ in range(B): sample = np.random.choice(data, len(data), replace=True) means.append(np.mean(sample)) boot_lower = np.percentile(means, 2.5) boot_upper = np.percentile(means, 97.5) print("CLT CI:", clt_lower, clt_upper) print("Bootstrap CI:", boot_lower, boot_upper)if __name__ == "__main__": main()
执行结果如下:结果解释
8Bootstrap方差估计
# file: bootstrap_variance.pyimport numpy as npdefmain(): np.random.seed(0) data = np.random.exponential(1, 50) B = 5000 means = []for _ in range(B): sample = np.random.choice(data, len(data), replace=True) means.append(np.mean(sample)) print("Bootstrap方差:", np.var(means))if __name__ == "__main__": main()
执行结果如下:9回归中的Bootstrap
# file: bootstrap_regression.pyimport numpy as npdefmain(): np.random.seed(0) x = np.linspace(0,10,100) y = 2 + 3*x + np.random.normal(0,2,100) B = 1000 betas = []for _ in range(B): idx = np.random.choice(len(x), len(x), replace=True) x_s = x[idx] y_s = y[idx] beta1 = np.cov(x_s,y_s)[0,1] / np.var(x_s) betas.append(beta1) print("beta1均值:", np.mean(betas)) print("beta1标准差:", np.std(betas))if __name__ == "__main__": main()
执行结果如下:10工程意义
Bootstrap适用于:
👉 特别重要:
11局限性
12本节总结
13下期预告(终章)
下一讲将进行全内容总结。
📌 点赞 + 转发,完成《统计学入门》核心章节