从滑动窗口到拥塞控制 - 揭秘 TCP 可靠高效传输的秘密
系列:Linux 网络子系统源码剖析篇号:第 8 篇 内核版本:Linux 5.10 LTS重点模块:数据传输、滑动窗口、拥塞控制、快速重传
📋 本篇导读
你将学到
TCP 数据发送和接收的完整流程
滑动窗口机制的实现原理
拥塞控制算法(Reno、CUBIC、BBR)
快速重传和快速恢复机制
SACK 选择性确认的实现
TCP 性能优化技巧
实战案例和问题排查
前置知识
已阅读第 7 篇(TCP 连接管理)
了解 TCP 协议基础
理解网络拥塞概念
熟悉 socket 编程
阅读时间
约 90-100 分钟
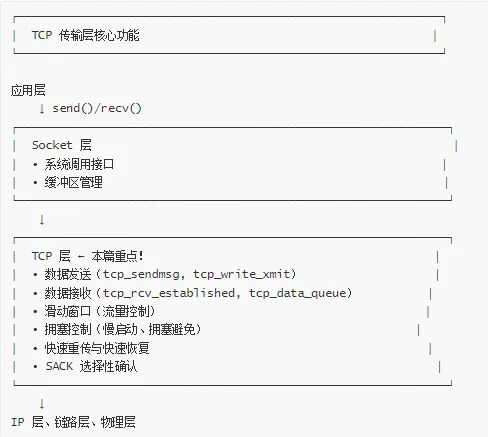
🎯 TCP 数据传输在协议栈中的位置
传输层职责
TCP 数据传输特点
📦 核心数据结构
tcp_sock 结构
源码位置:include/linux/tcp.h
TCP 状态变量关系
📤 TCP 数据发送流程
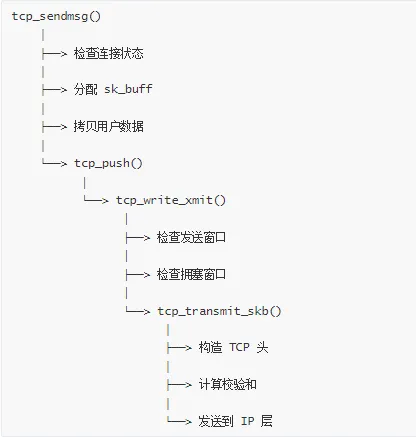
发送流程概览
tcp_sendmsg 实现
源码位置:net/ipv4/tcp.c
/**
* tcp_sendmsg - 发送 TCP 数据
* @sk: socket
* @msg: 消息
* @size: 数据大小
*
* 应用层发送数据的入口函数
*/
代码解析:
检查连接状态:只有 ESTABLISHED 和 CLOSE_WAIT 状态可以发送数据
获取 MSS:根据 PMTU 和对方通告的 MSS 计算实际 MSS
分配 skb:尝试追加到现有 skb,否则分配新的
拷贝数据:从用户空间拷贝数据到 skb
推送数据:根据 Nagle 算法和 PSH 标志决定是否立即发送
tcp_write_xmit 实现
源码位置:net/ipv4/tcp_output.c
/**
* tcp_write_xmit - 发送队列中的数据
* @sk: socket
* @mss_now: 当前 MSS
* @nonagle: Nagle 算法标志
* @push_one: 是否只发送一个包
* @gfp: 内存分配标志
*
* 从发送队列取出数据并发送
*/
代码解析:
检查发送窗口:确保不超出对方接收窗口
检查拥塞窗口:确保不超出拥塞窗口限制
TSO 分段:如果数据包过大,进行 TSO 分段
发送数据包:调用 tcp_transmit_skb() 发送
更新统计:更新发送统计和拥塞控制状态
设置定时器:设置重传定时器
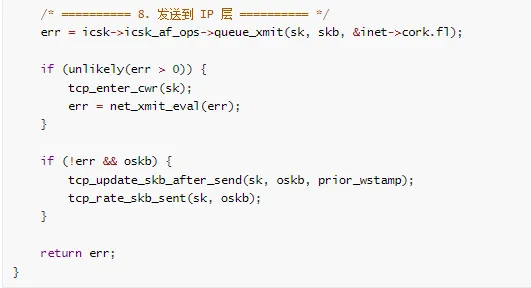
tcp_transmit_skb 实现
/**
* tcp_transmit_skb - 发送 TCP 数据包
* @sk: socket
* @skb: 数据包
* @clone_it: 是否克隆 skb
* @gfp_mask: 内存分配标志
*
* 构造 TCP 头并发送数据包
*/
发送流程总结:
📥 TCP 数据接收流程
接收流程概览
tcp_rcv_established 实现
源码位置:net/ipv4/tcp_input.c
/**
* tcp_rcv_established - 处理 ESTABLISHED 状态的数据包
* @sk: socket
* @skb: 数据包
*
* ESTABLISHED 状态的快速路径和慢速路径
*/
代码解析:
快速路径:按序数据,无选项,直接处理
慢速路径:乱序数据或有选项,需要额外处理
纯 ACK:没有数据,只处理 ACK
有数据:放入接收队列,更新 rcv_nxt
发送 ACK:根据延迟 ACK 策略发送确认
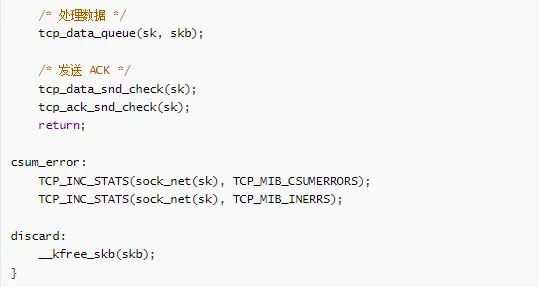
tcp_data_queue 实现
处理接收到的数据,包括按序数据和乱序数据。
/**
* tcp_data_queue - 将数据加入接收队列
* @sk: socket
* @skb: 数据包
*
* 处理按序和乱序数据
*/
乱序队列处理
/**
* tcp_data_queue_ofo - 处理乱序数据
* @sk: socket
* @skb: 数据包
*
* 将乱序数据加入红黑树
*/
接收队列结构:
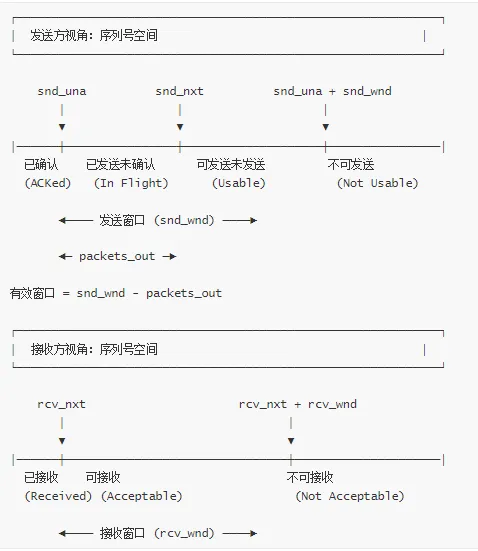
🪟 滑动窗口机制
滑动窗口是 TCP 流量控制的核心机制,用于控制发送速率,防止接收方缓冲区溢出。
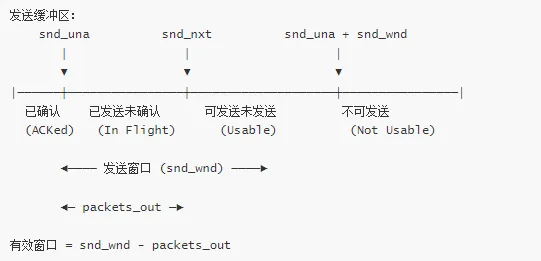
发送窗口
发送窗口计算:
/**
* tcp_snd_wnd_test - 检查发送窗口
* @tp: TCP socket
* @skb: 数据包
* @cur_mss: 当前 MSS
*
* 检查是否可以发送数据
*/
发送窗口示意图:
接收窗口
接收窗口计算:
/**
* tcp_select_window - 计算通告的接收窗口
* @sk: socket
*
* 返回要通告给对方的接收窗口大小
*/
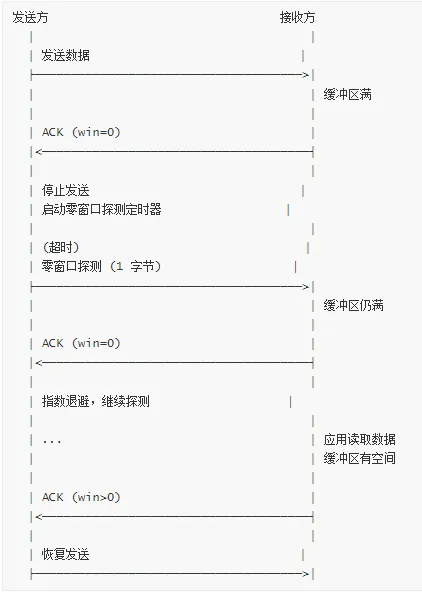
零窗口探测
当接收方通告零窗口时,发送方需要定期探测窗口是否恢复。
/**
* tcp_send_probe0 - 发送零窗口探测
* @sk: socket
*
* 发送 1 字节数据探测接收窗口
*/
零窗口探测流程:
🚦 拥塞控制算法
拥塞控制是 TCP 最重要的机制之一,用于防止网络拥塞,保证网络的稳定性和公平性。
拥塞控制状态机
拥塞控制状态:
/**
* TCP 拥塞控制状态
*/
enum tcp_ca_state {TCP_CA_Open=0, /* 正常状态 */
TCP_CA_Disorder, /* 检测到轻微丢包(重复 ACK)*/
TCP_CA_CWR, /* 拥塞窗口减小(Congestion Window Reduced)*/
TCP_CA_Recovery, /* 快速恢复 */
TCP_CA_Loss, /* 丢包恢复(超时重传)*/
};
状态转换图:
拥塞控制算法框架
Linux 支持多种拥塞控制算法,通过统一的接口实现。
源码位置:include/net/tcp.h
/**
* struct tcp_congestion_ops - 拥塞控制算法接口
*
* 定义拥塞控制算法的操作函数
*/
Reno 算法实现
Reno 是经典的 TCP 拥塞控制算法,包括慢启动、拥塞避免、快速重传和快速恢复。
源码位置:net/ipv4/tcp_cong.c
/**
* tcp_reno_cong_avoid - Reno 拥塞避免算法
* @sk: socket
* @ack: ACK 序列号
* @acked: 确认的段数
*
* 实现慢启动和拥塞避免
*/
/**
* tcp_slow_start - 慢启动算法
* @tp: TCP socket
* @acked: 确认的段数
*
* 返回:剩余未处理的 ACK 数
*/
Reno 算法流程图:
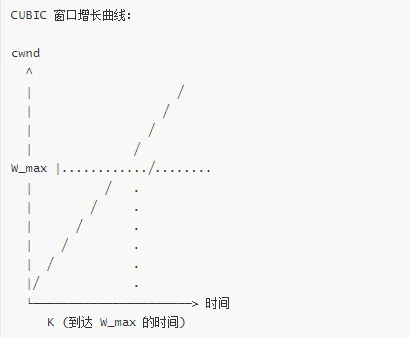
CUBIC 算法实现
CUBIC 是 Linux 默认的拥塞控制算法,针对高带宽延迟网络优化。
源码位置:net/ipv4/tcp_cubic.c
CUBIC 算法特点:
特点:
1. 凹区域(t < K):快速增长,接近 W_max
2. 凸区域(t > K):探测更高带宽
3. 与 RTT 无关:适合高延迟网络
4. TCP 友好:不会比标准 TCP 慢
BBR 算法简介
BBR (Bottleneck Bandwidth and RTT) 是 Google 开发的新一代拥塞控制算法。
核心思想:
测量瓶颈带宽:通过发送速率测量网络瓶颈带宽
测量 RTT:测量最小 RTT(无队列延迟)
控制发送速率:pacing_rate = BtlBw × gain
控制在途数据:cwnd = BtlBw × RTprop × gain
BBR 状态机:
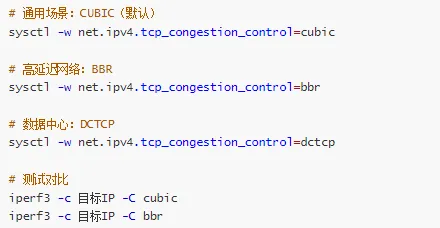
配置拥塞控制算法:
# 查看可用算法
sysctl net.ipv4.tcp_available_congestion_control
# net.ipv4.tcp_available_congestion_control = reno cubic bbr
# 查看当前算法
sysctl net.ipv4.tcp_congestion_control
# net.ipv4.tcp_congestion_control = cubic
# 设置默认算法
sysctl -w net.ipv4.tcp_congestion_control=bbr
# 查看连接使用的算法
ss -ti | grep-i cubic
⚡ 快速重传与快速恢复
快速重传和快速恢复是 TCP 的重要优化机制,用于快速检测和恢复丢包。
快速重传
当发送方收到 3 个重复 ACK 时,立即重传丢失的数据包,而不等待超时。
源码位置:net/ipv4/tcp_input.c
/**
* tcp_fastretrans_alert - 快速重传检测
* @sk: socket
* @prior_snd_una: 之前的 snd_una
* @num_dupack: 重复 ACK 数量
* @flag: 标志
*
* 检测是否需要快速重传
*/
快速恢复
进入快速恢复后,调整拥塞窗口并继续发送数据。
/**
* tcp_enter_recovery - 进入快速恢复状态
* @sk: socket
* @ece_ack: 是否收到 ECE ACK
*
* 设置快速恢复状态
*/
/**
* tcp_init_cwnd_reduction - 初始化拥塞窗口减小
* @sk: socket
*
* 设置 ssthresh 和 cwnd
*/
快速重传和快速恢复流程:
🎯 SACK 机制
SACK (Selective Acknowledgment) 允许接收方告知发送方哪些数据已经收到,哪些数据丢失,提高重传效率。
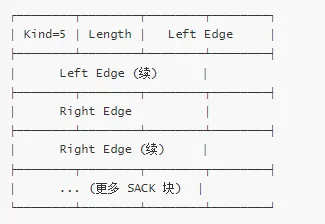
SACK 选项格式
TCP SACK 选项:
Kind: 5 (SACK)
Length: 10 + 8 × n (n 个 SACK 块)
Left Edge: SACK 块的起始序列号
Right Edge: SACK 块的结束序列号
示例:
发送序列:100, 200, 300, 400, 500
接收情况:100 ✓, 200 ✗, 300 ✓, 400 ✓, 500 ✗
SACK 选项:
块 1: [300, 500) 表示 300-499 已收到
发送方知道:
- 100-199: 已确认
- 200-299: 丢失(需要重传)
- 300-499: 已收到(不需要重传)
- 500+: 未知
SACK 实现
源码位置:net/ipv4/tcp_input.c
/**
* tcp_sacktag_write_queue - 处理 SACK 信息
* @sk: socket
* @ack_skb: ACK 包
* @prior_snd_una: 之前的 snd_una
* @state: SACK 标记状态
*
* 根据 SACK 信息更新发送队列
*/
/**
* tcp_mark_skb_sacked - 标记被 SACK 的数据包
* @tp: TCP socket
* @start_seq: SACK 块起始序列号
* @end_seq: SACK 块结束序列号
*
* 标记发送队列中被 SACK 的数据包
*/
/**
* tcp_xmit_retransmit_queue - 重传队列中的数据
* @sk: socket
*
* 根据 SACK 信息重传丢失的数据包
*/
SACK 重传示例:
发送序列:100, 200, 300, 400, 500, 600
接收情况:100 ✓, 200 ✗, 300 ✗, 400 ✓, 500 ✓, 600 ✗
不使用 SACK(传统快速重传):
1. 收到 3 个重复 ACK (ACK=200)
2. 重传 seq=200
3. 收到 ACK=300
4. 重传 seq=300
5. 收到 ACK=600
6. 重传 seq=600
总共:3 次重传,3 个 RTT
使用 SACK:
1. 收到 SACK: [400, 600)
2. 知道 200-399 丢失
3. 同时重传 seq=200 和 seq=300
4. 收到 ACK=600
5. 重传 seq=600
总共:3 次重传,2 个 RTT(更快)
启用 SACK:
# 启用 SACK
sysctl -w net.ipv4.tcp_sack=1
# 查看 SACK 统计
netstat -s | grep-i sack
# TCPSACKReorder: 10
# TCPSACKReneging: 0
# TCPSACKDiscard: 0
🚀 TCP 性能优化
发送端优化
1. Nagle 算法
减少小包发送,提高网络效率。
/**
* Nagle 算法规则:
* 1. 如果有足够数据(>= MSS),立即发送
* 2. 如果没有未确认的数据,立即发送
* 3. 否则,等待更多数据或 ACK
*/
/* 禁用 Nagle 算法(实时应用)*/
int flag=1;
setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(flag));
2. TCP Cork
累积数据后一次性发送,减少包数量。
/* 启用 TCP_CORK */
int flag=1;
setsockopt(sockfd, IPPROTO_TCP, TCP_CORK, &flag, sizeof(flag));
/* 发送数据 */
write(sockfd, data1, len1);
write(sockfd, data2, len2);
write(sockfd, data3, len3);
/* 禁用 TCP_CORK,立即发送 */
flag=0;
setsockopt(sockfd, IPPROTO_TCP, TCP_CORK, &flag, sizeof(flag));
3. TSO (TCP Segmentation Offload)
将分段工作交给网卡,减少 CPU 负载。
# 查看 TSO 状态
ethtool -k eth0 | grep tcp-segmentation-offload
# 启用 TSO
ethtool -K eth0 tso on
# 查看 TSO 统计
ethtool -S eth0 | grep tso
4. 发送缓冲区调优
# 设置发送缓冲区大小
sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216"
# 最小 默认 最大
# 设置总内存限制
sysctl -w net.ipv4.tcp_mem="786432 1048576 1572864"
# 低水位 压力 高水位
# 应用层设置
int sndbuf =1024 * 1024; // 1MB
setsockopt(sockfd, SOL_SOCKET, SO_SNDBUF, &sndbuf, sizeof(sndbuf));
接收端优化
1. GRO (Generic Receive Offload)
合并接收的小包,减少协议栈处理次数。
# 启用 GRO
ethtool -K eth0 gro on
# 查看 GRO 统计
ethtool -S eth0 | grep gro
2. 接收缓冲区调优
# 设置接收缓冲区大小
sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"
# 最小 默认 最大
# 启用窗口缩放
sysctl -w net.ipv4.tcp_window_scaling=1
# 设置最大接收窗口
sysctl -w net.core.rmem_max=16777216
3. 延迟 ACK
减少 ACK 包数量,提高效率。
# 延迟 ACK 时间(毫秒)
sysctl -w net.ipv4.tcp_delack_min=40
# 快速 ACK 模式(收到乱序包立即 ACK)
# 内核自动处理
4. 接收队列优化
# 增加网卡接收队列长度
ifconfig eth0 txqueuelen 10000
# 增加 softirq 处理预算
sysctl -w net.core.netdev_budget=600
sysctl -w net.core.netdev_budget_usecs=8000
RTT 测量优化
1. 时间戳选项
提供精确的 RTT 测量。
# 启用时间戳
sysctl -w net.ipv4.tcp_timestamps=1
2. RTT 计算
/**
* tcp_rtt_estimator - 更新 RTT 估计
* @sk: socket
* @mrtt_us: 测量的 RTT(微秒)
*
* 使用 Jacobson/Karels 算法
*/
💼 实战案例
案例 1:优化高延迟网络传输
问题现象:
跨国传输速度慢
RTT 200ms,带宽 100Mbps
实际吞吐量只有 5Mbps
问题分析:
# 1. 查看当前窗口大小
ss -ti dst 目标IP
# cwnd:10 ssthresh:20 rtt:200ms
# 2. 计算带宽延迟积(BDP)
# BDP = 带宽 × RTT
# BDP = 100Mbps × 200ms = 2.5MB
# 3. 当前窗口太小
# 窗口 = 10 × 1460 = 14.6KB << 2.5MB
解决方案:
# 1. 增加初始拥塞窗口
ip route change default via 网关 initcwnd 30
# 2. 增加接收窗口
sysctl -w net.ipv4.tcp_rmem="4096 87380 33554432"# 32MB
sysctl -w net.core.rmem_max=33554432
# 3. 增加发送窗口
sysctl -w net.ipv4.tcp_wmem="4096 65536 33554432"# 32MB
sysctl -w net.core.wmem_max=33554432
# 4. 启用窗口缩放
sysctl -w net.ipv4.tcp_window_scaling=1
# 5. 使用 BBR 拥塞控制
sysctl -w net.ipv4.tcp_congestion_control=bbr
# 6. 验证效果
iperf3 -c 目标IP -t60
# 吞吐量应该接近 100Mbps
案例 2:排查丢包和重传
问题现象:
排查步骤:
# 1. 查看重传统计
netstat -s | grep -i retrans
# 1234 segments retransmitted
# 567 fast retransmits
# 89 retransmits in slow start
# 2. 查看丢包统计
netstat -s | grep -i loss
# 456 packets lost
# 123 loss events
# 3. 实时监控连接
ss -ti dst 目标IP
# rto:400 rtt:100/50 ato:40 cwnd:20 ssthresh:15
# bytes_sent:1000000 bytes_retrans:50000 (5% 重传率)
# 4. 使用 tcpdump 抓包分析
tcpdump -i eth0 -nn 'tcp and host 目标IP' -w capture.pcap
# 5. 分析重传原因
# - 超时重传:RTO 过小或网络拥塞
# - 快速重传:乱序或丢包
# - SACK 重传:选择性重传
解决方案:
# 1. 如果是网络拥塞
# 调整拥塞控制算法
sysctl -w net.ipv4.tcp_congestion_control=cubic
# 2. 如果是 RTO 过小
# 增加最小 RTO
sysctl -w net.ipv4.tcp_rto_min=200# 200ms
# 3. 如果是乱序
# 增加重排序容忍度
sysctl -w net.ipv4.tcp_reordering=5
# 4. 启用 SACK
sysctl -w net.ipv4.tcp_sack=1
# 5. 启用 FACK(Forward ACK)
sysctl -w net.ipv4.tcp_fack=1
案例 3:优化小文件传输
问题现象:
问题分析:
传统 TCP 传输小文件:
1. 三次握手:1 RTT
2. 慢启动:cwnd 从 10 开始
3. 数据传输:可能需要多个 RTT
4. 四次挥手:1 RTT
总计:至少 3-4 个 RTT
对于 10KB 文件,RTT=50ms:
传输时间 = 3 × 50ms = 150ms
实际数据传输时间 << 150ms
解决方案:
# 1. 增加初始拥塞窗口
ip route change default via 网关 initcwnd 30
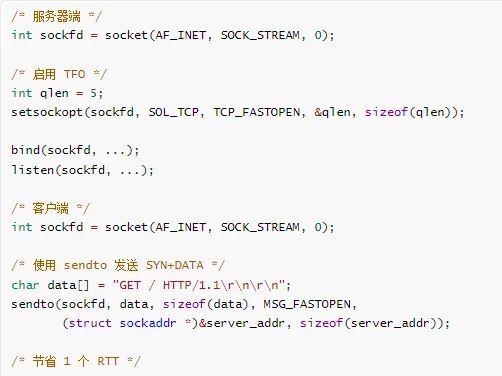
# 2. 启用 TCP Fast Open
sysctl -w net.ipv4.tcp_fastopen=3
# 3. 使用 HTTP/2 或 HTTP/3
# 多路复用,减少连接数
# 4. 应用层优化:连接池
# 复用 TCP 连接,避免频繁建立连接
# 5. 应用层优化:批量传输
# 将多个小文件打包传输
TCP Fast Open 示例:
📝 总结
本文深入剖析了 TCP 数据传输和拥塞控制的实现机制。
核心要点
数据传输流程:
滑动窗口机制:
发送窗口:min(拥塞窗口, 对方接收窗口)
接收窗口:动态调整,避免缩小
零窗口探测:指数退避
拥塞控制算法:
快速重传与 SACK:
性能优化建议
高延迟网络:增大窗口,使用 BBR
高丢包网络:启用 SACK,调整重排序容忍度
小文件传输:增大初始 cwnd,使用 TFO
大文件传输:启用 TSO/GRO,调整缓冲区
实时应用:禁用 Nagle,减小延迟 ACK
监控指标
# 关键指标
ss -ti# 连接详细信息
netstat -s# 协议统计
nstat -az# 实时统计
sar -n TCP 1# TCP 统计
# 重点关注
- 重传率:retrans / sent
- 拥塞窗口:cwnd
- RTT:rtt/rttvar
- 丢包率:loss / sent
下一篇预告
下一篇《Netfilter 与 iptables 源码解析》将深入分析:
Netfilter 框架架构
五个 Hook 点的实现
iptables 规则匹配
连接跟踪(conntrack)
NAT 实现机制
❓ 常见问题(FAQ)
Q1:为什么需要慢启动?
A:慢启动防止新连接立即发送大量数据导致网络拥塞。通过指数增长探测网络容量,快速达到合适的发送速率。
Q2:CUBIC 比 Reno 好在哪里?
A:
窗口增长与 RTT 无关,公平性更好
三次函数增长,更适合高带宽网络
快速恢复到丢包前的窗口大小
Linux 默认算法,经过广泛验证
Q3:什么时候使用 BBR?
A:
高延迟网络(跨国、卫星)
缓冲区膨胀严重的网络
需要低延迟的应用
注意:可能对其他流量不公平
Q4:如何选择合适的拥塞控制算法?
A:
Q5:重传率多少算正常?
A:
< 1%:正常
1-3%:可接受
3-5%:需要关注
5%:严重问题,需要排查
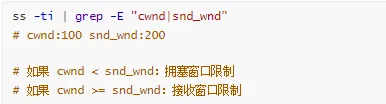
Q6:如何判断是拥塞窗口限制还是接收窗口限制?
A:
📚 参考资料
内核源码
net/ipv4/tcp.c - TCP 核心实现
net/ipv4/tcp_input.c - TCP 输入处理和拥塞控制
net/ipv4/tcp_output.c - TCP 输出处理
net/ipv4/tcp_cong.c - 拥塞控制框架
net/ipv4/tcp_cubic.c - CUBIC 算法实现
net/ipv4/tcp_bbr.c - BBR 算法实现
net/ipv4/tcp_timer.c - TCP 定时器
RFC 文档
RFC 793: Transmission Control Protocol
RFC 2001: TCP Slow Start, Congestion Avoidance, Fast Retransmit, and Fast Recovery
RFC 2018: TCP Selective Acknowledgment Options
RFC 2581: TCP Congestion Control
RFC 3168: The Addition of Explicit Congestion Notification (ECN) to IP
RFC 5681: TCP Congestion Control
RFC 6582: The NewReno Modification to TCP's Fast Recovery Algorithm
RFC 6937: Proportional Rate Reduction for TCP
RFC 7323: TCP Extensions for High Performance
RFC 8312: CUBIC for Fast Long-Distance Networks
论文
"CUBIC: A New TCP-Friendly High-Speed TCP Variant" - Sangtae Ha et al.
"BBR: Congestion-Based Congestion Control" - Neal Cardwell et al.
"TCP Congestion Control" - Van Jacobson, 1988
书籍推荐
《TCP/IP 详解 卷1:协议》- W. Richard Stevens
《深入理解 Linux 网络技术内幕》- Christian Benvenuti
《Linux 内核源代码情景分析》- 毛德操、胡希明
在线资源
Linux 内核文档:https://www.kernel.org/doc/html/latest/networking/
TCP 拥塞控制:https://www.ietf.org/proceedings/
BBR 论文:https://queue.acm.org/detail.cfm?id=3022184
作者:肇中