大家好,我是小志。我们的口号是:学习、成长、应对未来风险。 书接上回 ---
了解DMA映射期间执行的操作
DMA 控制器 / 系统总线的「地址映射表项」是全局有限资源(比如 PCIe 总线的 DMA 地址转换表、ARM 的 IOMMU 页表项):🟠 流映射(如dma_map_single)会占用一个表项,把内存的物理地址转换成 DMA 可识别的总线地址;🟠 这些表项数量极少(比如几百个),如果传输完成后不解映射,表项会被永久占用,最终导致其他设备 / 驱动无法做 DMA 映射(资源泄漏);🟠 解映射(dma_unmap_single)的核心作用之一就是释放这个表项,归还给系统供其他场景使用。
流 DMA 映射的设计初衷是「精准适配单次传输」:比如 “硬盘读取一个文件到内存”,传输前映射→传输中保证一致性→传输完成后解映射;内存的 “DMA 专用状态” 只需要维持到传输结束,后续内存可能被用于其他场景(比如用户态读写、其他进程使用);不解映射会让内存一直被标记为 “DMA 在用”,既浪费资源,也可能导致其他操作访问出错(比如其他进程写这块内存时,DMA 突然又去读)。
一致性 DMA 映射(dma_alloc_coherent)会:直接分配一块 “DMA 专用内存”,并永久占用对应的总线地址表项(内核标记为 “长期使用”);这些内存从分配起就属于设备(比如网卡的收包缓冲区),直到驱动卸载前都不会被其他场景使用;频繁解映射 / 重新映射会重复占用 / 释放表项,增加不必要的开销(比如网卡每秒收上千个包,总不能每次都映射 / 解映射)。
一致性 DMA 映射的内存,缓存属性会被永久设置为 “缓存一致”(要么禁用缓存,要么硬件自动同步缓存):
比如 ARM 架构下,一致性内存会被标记为 “设备内存”,全程保持这个属性;如果中途解映射,会恢复默认缓存属性,导致后续 DMA 传输时缓存不一致(比如 DMA 读物理内存,CPU 写缓存,数据不同步);只有当驱动卸载、内存被释放(dma_free_coherent)时,缓存属性才会被清理 —— 这是 “一次性清理”,而非中途解映射。
流 DMA 的 “解映射”≠“释放内存”:解映射只是解除 DMA 属性,内存还在,后续可以用kfree释放;一致性 DMA 是 “释放内存时自动解映射”,无需单独调用解映射函数。
流 DMA 不解映射的后果:地址表项泄漏→系统 DMA 功能瘫痪;内存缓存属性异常→CPU 访问性能暴跌;一致性 DMA 中途解映射的后果:缓存一致性被破坏→DMA 和 CPU 数据不同步;设备传输出错→丢包 / 数据损坏。
处理DMA映射的主要头文件如下:
#include<linux/dma-mapping.h>
DMA映射:
(1)假设设备支持DMA,如果驱动程序使用kmalloc()设置缓冲区,则得到一个虚拟地址(称为X),该地址尚未指向任何地方。
(2)虚拟内存系统(借助MMU)将X映射到系统RAM中的物理地址(称为Y),假设仍有可用的空闲内存。因为DMA不通过虚拟内存系统流动,驱动程序此时可以使用虚拟地址X访问缓冲区,但设备本身无法访问。
(3)在一些简单的系统(没有I/O MMU的系统)中,设备可以直接对物理地址Y进行DMA。但在许多其他系统中,设备可以通过I/O MMU看到主存。因此,I/OMMU硬件可以将DMA地址转换为物理地址。
(4)映射相关API介入的地方如下:
🟠 驱动程序可以将虚拟地址X传递给dma_map_single()函数,该函数设置任何适当的I/O MMU映射并返回DMA地址Z。
🟠 驱动程序指示设备对地址Z进行DMA。
🟠 I/O MMU最终将它映射到系统RAM中物理地址Y的缓冲区中。
场景 1:无 I/O MMU 的简单系统(比如低端 ARM 嵌入式)
🟠 驱动调用kmalloc(4096, GFP_KERNEL),得到CPU 虚拟地址 X(比如 0xffffff00);
🟠 CPU 的 MMU 将 X 映射到系统 RAM 的物理地址 Y(比如 0x40000000)—— 此时 CPU 能通过 X 访问内存,但 DMA 不认虚拟地址 X;
🟠 驱动调用dma_map_single(dev, X, 4096, DMA_TO_DEVICE):内核做两件事:① 刷 CPU 缓存(确保 X 对应的数据同步到物理内存 Y);② 计算总线地址(DMA 地址 Z)= 物理地址 Y(无 I/O MMU 时,总线地址 = 物理地址);
🟠 函数返回 Z(即 Y,0x40000000);
🟠 驱动把 DMA 地址 Z 写入设备的 DMA 寄存器,指示设备 “对 Z 做 DMA 传输”;
🟠 设备(DMA 控制器)直接访问总线地址 Z(= 物理地址 Y),和系统 RAM 完成数据传输(无地址转换,直接访问);
🟠 传输完成后,驱动调用dma_unmap_single(dev, Z, 4096, DMA_TO_DEVICE):恢复缓存属性,释放映射资源。
场景 2:有 I/O MMU 的复杂系统(比如 x86 服务器、高端 ARM64)
🟠 驱动调用kmalloc(4096, GFP_KERNEL),得到CPU 虚拟地址 X(比如 0xffffff00);
🟠 CPU 的 MMU 将 X 映射到系统 RAM 的物理地址 Y(比如 0x40000000)——CPU 能访问 X,但 DMA 不认;
🟠 驱动调用dma_map_single(dev, X, 4096, DMA_TO_DEVICE):
内核做三件事:
① 刷 CPU 缓存(同步数据到 Y);
② 向 I/O MMU 的页表中添加 “设备虚拟地址 Z → 物理地址 Y” 的映射项;
③ 返回DMA 地址 Z(设备虚拟地址,比如 0x90000000);
注意:此时 Z≠Y,Z 是 I/O MMU 给设备分配的 “虚拟地址”;
🟠 驱动把 DMA 地址 Z 写入设备的 DMA 寄存器,指示设备 “对 Z 做 DMA 传输”;
🟠 设备(DMA 控制器)发出访问 “DMA 地址 Z(0x90000000)” 的请求;
🟠 I/O MMU 拦截该请求,查自身页表,将 Z(0x90000000)转换成物理地址 Y(0x40000000);
🟠 最终设备通过 I/O MMU 的转换,访问到系统 RAM 的物理地址 Y,完成 DMA 传输;
🟠 传输完成后,驱动调用dma_unmap_single:删除 I/O MMU 的页表项,恢复缓存属性。
创建一致性DMA映射
用于长时间,双向的I/O缓冲区
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, gfp_t flag);
这个函数负责缓冲区的分配和映射,并返回缓冲区的内核虚拟地址,缓冲区大小为size字节,可由CPU访问。size参数可能让人产生误解,因为get_order()首先使用size来获取与之对应的页幂次order。因此,该映射至少是按页计算的,页数为2的幂。dev是设备结构。dma_handle是指向相关总线地址的输出参数。为映射分配的内存在物理上必须是连续的,flag决定了应该如何分配内存,通常为GFP_KERNEL或GFP_ATOMIC(在原子上下文中)。
创建流DMA映射
流DMA映射本身不分配内存,它只做DMA“属性加持”,必须先有一个已经动态分配好的缓冲区,比如说kmalloc/vmalloc/用户空间缓冲区,才能对他做流映射。
流DMA映射内存缓冲区通常在传输之前进行映射,传输之后取消映射。这种映射具有更多的约束条件,并且与一致性DMA映射不同,原因如下:
🟠 映射需要与之前动态分配的缓冲区一起使用。
🟠 映射可能接收多个分散的非连续缓冲区。
流映射内核提供dma_map_sg接口,能接受一个“分散-聚集表”,里面包含多个非连续的缓冲区。
① 内核会遍历 sg_table,把每个非连续的物理页,通过 IOMMU / 总线桥映射成连续的总线地址;
② DMA 控制器按 “连续的总线地址” 传输数据,内核自动把数据拆 / 合到多个非连续的物理缓冲区里;
③ 对 DMA 来说,看起来是 “连续传输”,但实际内存是零散的,不用 CPU 先把数据拷贝到连续缓冲区(省 CPU 资源)。
🟠 对于读取事务(从设备到CPU),缓冲区属于设备,不属于CPU。在CPU可以使用缓冲区之前,首先应该取消对缓冲区的映射(在调用 dma_sync_single_for_cpu() 和 dma_sync_sg_for_cpu() 之后),或者在这些缓冲区上调用dma_sync_single_for_cpu() 和 dma_sync_sg_for_cpu()。这样做的主要原因就是为了缓存。(数据从设备(比如SD卡)->DMA->内存,但CPU的缓存可能留着这块内存的旧数据,必须先取消缓存)
voiddma_sync_single_for_cpu(struct device *dev, dma_addr_t dma_handle, size_t size, enum dma_data_direction dir);// 分散 / 聚集表 voiddma_sync_sg_for_cpu(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction dir);
🟠 对于写入事务(从CPU到设备),驱动程序应在建立映射之前将数据放入缓冲区。(数据从CPU->内存->DMA->设备, CPU先把数据写到缓存,如果先映射再写数据,映射时内核会刷一次缓存,所以必须先写数据再映射)
🟠 必须指定传输方向,并且数据应该根据传输方向移动和使用。
流DMA映射有以下两种形式:
🟠 单缓冲区映射,允许对一个物理上连续的缓冲区进行映射。
🟠 分散/聚集映射,允许传递多个缓冲区(分散在内存中)。
“DMA 属性” 核心包含 3 类配置:
缓存属性:决定内存是否禁用缓存、是否需要刷缓存(流映射的核心);
地址映射属性:把内存的物理地址转成 DMA 能认的总线地址(dma_handle);
传输方向属性:指定数据是 “CPU→设备” 还是 “设备→CPU”(流映射必须指定,决定缓存怎么刷)。
对于这两种映射,传输方向应由dma_data_direction类型的枚举符号指定,该类型定义在include/linux/dma-direction.h中,如下:
enum dma_data_direction { DMA_BIDIRECTIONAL = 0, DMA_TO_DEVICE = 1, DMA_FROM_DEVICE = 2, DMA_NONE = 3,};
| 枚举值 | 数值 | 含义 |
|---|
DMA_BIDIRECTIONAL | 0 | 双向传输:CPU 和设备都可能读写这段内存,内核需做双向缓存同步 |
DMA_TO_DEVICE | 1 | 内存 → 设备(写操作):CPU 准备好数据后,设备读取,需同步 CPU 缓存到设备 |
DMA_FROM_DEVICE | 2 | 设备 → 内存(读操作):设备写入数据后,CPU 读取,需同步设备数据到 CPU 缓存 |
DMA_NONE | 3 | 无方向:仅用于调试或标记未初始化的 DMA 方向 |
一致性DMA映射隐含着一个针对DMA_BIDIRECTIONAL的方向属性设置。
单缓冲区映射(允许对一个物理上连续的缓冲区进行映射)
dma_addr_tdma_map_single(struct device *dev, void *ptr, size_t size, enum dma_data_direction direction);
当CPU充当源头(向设备写入数据)或目标(从设备读取数据)时,以及当映射的访问是双向(在一致性DMA映射中隐式使用)时,direction应分别为DMA_TO_DEVICE、DMA_FROM_DEVICE或DMA_BIDIRECTIONAL。dev是硬件设备的底层结构。ptr是输出参数,也是缓冲区的内核虚拟地址。该函数返回dma_addr_t类型的成员,它是由I/O MMU(如果存在的话)返回给设备的总线地址,以便设备可以进行DMA。应该使用dma_mapping_error()(如果没有错误发生,则必须返回0)来检查映射是否返回有效地址,如果出现错误,不要继续进行。
可以通过以下函数释放此类映射:
voiddma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma_data_direction direction);intdma_mapping_error(struct device *dev, dma_addr_t dma_addr);
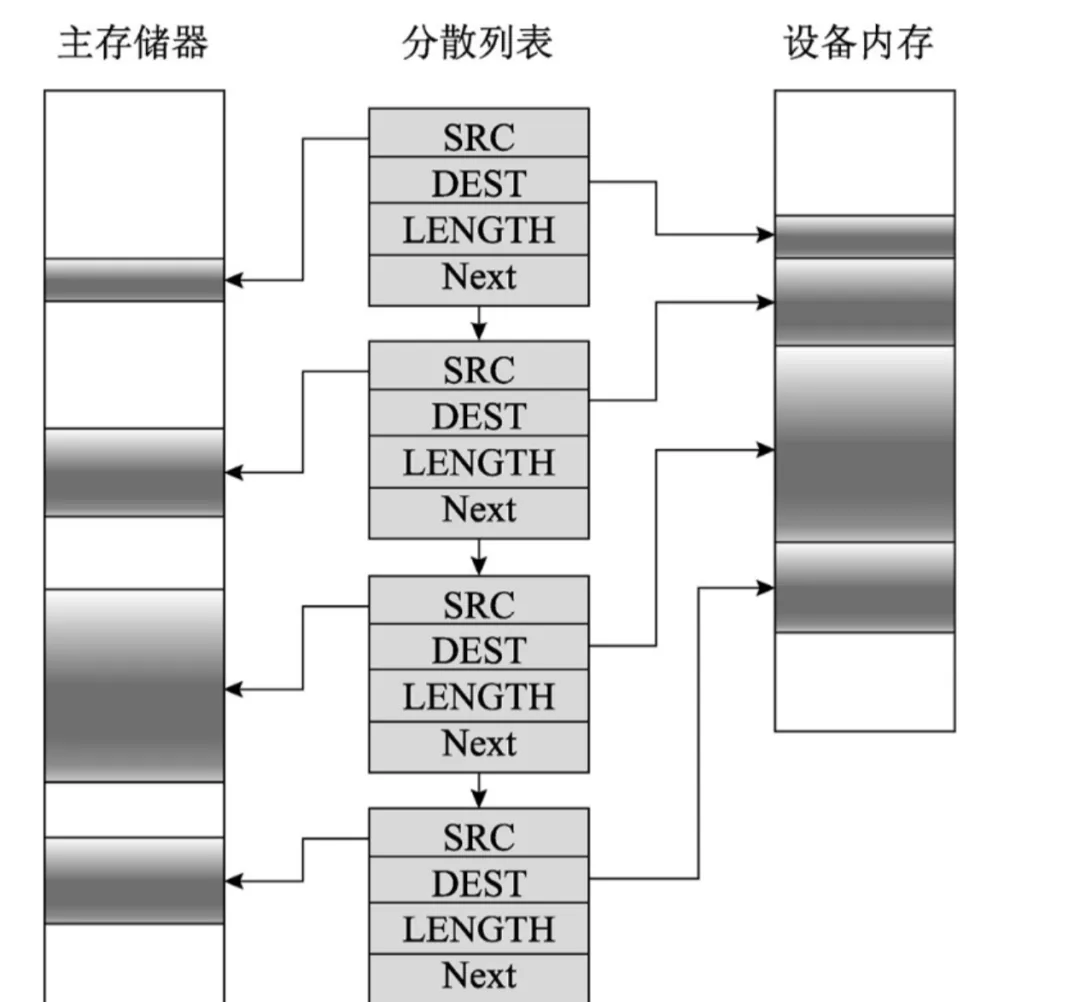
分散/聚集映射(允许传递多个缓冲区——分散在内存中)
分散/聚集映射是一种特殊类型的流DMA映射,它可以在一次操作中传输多个缓冲区,而不是单独映射每个缓冲区并逐个传输它们。假设有多个缓冲区,它们在物理上或许不是连续的,所有这些缓冲区都需要同时被传输到设备或从设备传出。此种情形可能由以下原因引起。🟠 readv()或writev()系统调用。(用户态程序要一次读写多个不连续的缓冲区)🟠 磁盘I/O请求。(页缓存往往是分散的)🟠 页的链表或vmalloc分配器分配的内存区域。
使用这样的映射之前必须建立分散的数组元素,每个元素描述一个单独缓冲区的映射情况。上述分散元素在内核中被抽象为scatterlist结构体实例,该结构体定义如下:
struct scatterlist { unsigned long page_link; unsigned int offset; unsigned int length; dma_addr_t dma_address; unsigned int dma_length;};
为了建立分散列表的映射,需要如下操作:
🟠 分配分散的缓冲区🟠 创建分散数据,使用sg_init_table()初始化数组,并使用sg_set_buf()分配内存填充该数据,每个分散元素必须是页大小(结尾除外)🟠 在分散数组上调用dma_map_sg()🟠 一旦完成DMA,就调用dma_unmap_sg()取消对分散数组的映射
虽然可以对多个缓冲区的内容分别进行DMA,但分散/聚集方式可以通过将分散数组的地址和长度(即分散数组中的元素数量)一起发送给设备,一次性地对整个分散列表进行DMA。
voidsg_init_table(struct scatterlist *sgl, unsignedint nents);voidsg_set_buf(struct scatterlist *sg, constvoid *buf, unsignedint buflen);intdma_map_sg(struct device *dev, struct scatterlist *sglist, int nents, enum dma_data_direction dir);
要取消映射列表,就必须使用dma_unmap_sg_ attrs()函数,该函数定义如下:
voiddma_unmap_sg_attrs(struct device *dev, struct scatterlist *sg, enum dma_data_direction dir, int nents);
其中,dev指向一个设备,该设备已用于映射;sg是要取消的映射列表(实际上是指向映射列表中第一个元素的指针);dir是DMA方向,它应该与映射方向对应;nents是分散数组中的元素数量。
流DMA映射的隐式和显式缓存一致性
隐式缓存一致性
定义:硬件(总线 / CPU 架构)自动维护缓存与 DMA 的一致性,不需要软件干预。
特点:
适用函数( 这些函数内部自动处理,驱动不用管缓存 ):
dma_map_single()dma_unmap_single()dma_map_sg()dma_unmap_sg()
显式缓存一致性
定义:硬件不支持自动一致性,驱动必须手动调用函数维护缓存。
特点:
必须手动调用的 API:
// 数据从CPU -> 设备(DMA读):CPU写完,刷缓存到内存dma_sync_single_for_device(dev, dma_addr, size, dir);// 数据从设备 -> CPU(DMA写):DMA完成,让CPU缓存失效dma_sync_single_for_cpu(dev, dma_addr, size, dir);
在流DMA映射中,dma_map_single()/dma_unmap_single()和dma_map_sg()/dma_unmap_sg()函数组合用于处理缓存一致性问题。对CPU到设备的情况(DMA_TO_DEVICE),由于在建立映射之前数据必须放在缓冲区中,因此dma_map_sg()/dma_map_single()将处理缓存一致性问题。对于设备到CPU的情况(设置了DMA_FROM_DEVICE方向标志),在CPU能够访问缓冲区之前,必须首先释放映射关系,这是因为dma_unmap_single()/dma_unmap_sg()会隐式地处理缓存一致性问题。
然而,如果需要多次使用相同的流式DMA区域,并且在DMA传输之间处理数据,则缓冲区必须正确地同步,以便设备和CPU看到DMA缓冲区的最新且正确的副本。为了避免缓存一致性问题,驱动程序必须在开始从RAM到设备的DMA传输之前调用dma_sync{single,sg}for_device()(在将数据放入缓冲区之后,在实际将缓冲区交给硬件之前)。如有必要,这个函数调用将刷新DMA缓冲区所对应的硬件缓存行。类似地,驱动程序不应该在完成从设备到RAM的DMA传输后立即访问内存缓冲区;相反,在读取缓冲区之前,驱动程序应该调用dma_sync{single,sg}for_cpu(),这将在必要时使相关的硬件缓存行无效。
voiddma_sync_sg_for_cpu(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction direction);voiddma_sync_sg_for_device(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction direction);voiddma_sync_single_for_cpu(struct device *dev, dma_addr_t addr, size_t size, enum dma_data_direction dir);voiddma_sync_single_for_device(struct device *dev, dma_addr_t addr, size_t size, enum dma_data_direction dir);
完成completion概念
在内核编程中,我们经常在当前线程之外启动一个活动,然后等待该活动完成。完成变量是使用等待队列实现的,他们与等待队列的唯一区别就是无须维护等待队列。使用完成变量之前需要包含如下头文件:
#include <linux/completion.h>
完成变量在内核中表示为completion结构体实例,该结构体可以静态初始化如下:
DECLARE_COMPLETION(my_comp);
动态分配时的初始化方式如下:
struct completion my_comp;init_completion(&my_comp);
当驱动程序启动工作(比如DMA事务)必须等待完成时,只需要将完成事件传递给wait_for_completion()函数即可
voidwait_for_completion(struct completion *comp);
当完成事件发生后,驱动程序可以使用以下API之一唤醒等待者:
voidcomplete(struct completion *comp);voidcomplete_all(struct completion *comp);
complete()只会唤醒一个等待任务,而complete_all()会唤醒等待该事件完成的所有任务。completion()是内核专为单次事件等待设计的同步机制,他的核心是记录“完成事件是否已经发生”,哪怕先调用complete()标记事件完成,再掉用wait_for_completion()等待事件完成,等待的线程也不会阻塞,会直接跳过等待逻辑继续执行。而普通等待队列如果先调用wake_up()再调用wait_event(),线程会无限睡眠(因为没抓到唤醒信号)。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
