目录:
1、元字符之^与$
(1)元字符^
(2)元字符$
2、转义符 \
(1)赋予某些普通符号特殊功能
(2)取消特殊功能符号以普通化
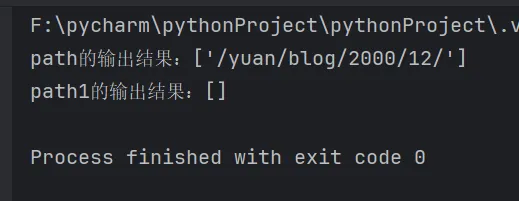
元字符^:叫开始边界符或开始锚点符,匹配一行的开头位置。
import repath = "/yuan/blog/2000/12/"path1 = "/www/yuan/blog/2000/12/"# 开头必须跟^后内容一样reg = "^/yuan/blog/[0-9]{4}/[0-9]{1,2}/"ret = re.findall(reg, path)ret1 = re.findall(reg, path1)print(f"path的输出结果:{ret}")print(f"path1的输出结果:{ret1}")
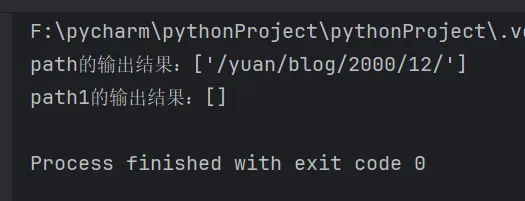
元字符$:叫结束边界符或结束锚点符,匹配一行的结束位置。
import repath = "/yuan/blog/2000/12/"path1 = "/yuan/blog/2000/12/aaa"# 结尾必须跟$前内容一样reg = "/yuan/blog/[0-9]{4}/[0-9]{1,2}/$"ret = re.findall(reg, path)ret1 = re.findall(reg, path1)print(f"path的输出结果:{ret}")print(f"path1的输出结果:{ret1}")
正则中的转义符和Python字符串的转义符相似,两个功能。
| |
| |
| 匹配一个非数字原子,等价于[^0-9]或[^\d] |
| 匹配一个包括下划线的单词原子,等价于[A-Za-z0-9_]。 |
| 匹配任何非单词字符。等价于[^A-Za-z0-9_] |
| |
| |
| 匹配一个任何空白字符原子,包括空格、制表符、换页符等等。 |
| |
| 匹配一个单词边界原子,也就是指单词和非单词原子符间的位置。 |
| |
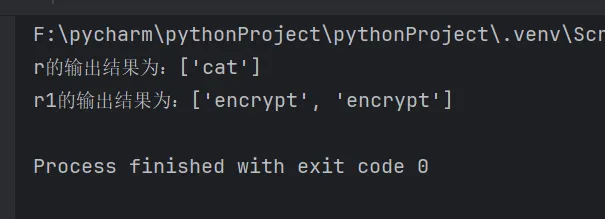
import res = "The cat sat on the caterpillar"reg = r"\bcat\b" #只匹配完整的"cat"r = re.findall(reg, s)print(f"r的输出结果为:{r}") # 输出:['cat']s1 = "encrypt JSencrypt AESencrypt encrypyData encrypt"r1 = re.findall(r"\bencrypt\b", s1)print(f"r1的输出结果为:{r1}")
import re# 取消特殊功能符号以普通化s = "https://wwwxxxbaidu.com/, https://www.ooaac.com/, https://www.youdao.com/"ret = re.findall(r"https?://www.[a-z]*?.com", s)ret1 = re.findall(r"https?://www\.[a-z]*?\.com", s)print(f"没加\的ret结果:{ret}")print(f"加\的ret1结果:{ret1}")
import retext = """Visit us at example.com for more information.You can also cheak out our partner site: partner-site.orgDon't forget about our blog at blog-example.com!For support, visit support.example.com"""# 正则表达式匹配以 .com 结尾的域名pattern = r'\b[a-zA-Z0-9._%+-]+\.com\b'# 查找所以匹配项matches = re.findall(pattern, text)#输出结果print(f"Matched .com domains: {matches}")
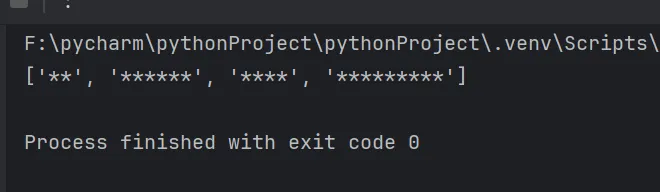
import retext = """Visit us at example.com for more information.You can also cheak ** out our partner site: partner-site.orgDon't forget about ****** our blog **** at blog-example.com!For support, ********* visit support.example.com"""ret = re.findall(r"\*+", text)print(ret)
import res = r"\user\yuan\apple.png,\user\yuan\banana.png,\user\yuan\peach.png,\user\rain\apple.png"ret = re.findall(r"\\user\\yuan\\\w+\.png", s)print(ret)











 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
