别说你会写 Linux 程序,先懂 ELF 文件怎么跑起来
- 2026-06-28 19:39:23
很多 Linux 开发者,每天敲着代码、编译运行,却始终没搞懂一个核心问题:你写的 C/C++代码,经编译器生成的 ELF 文件,到底是怎么从磁盘上的静态文件,变成内存中正在运行的进程的?我们习惯了用 gcc 编译、./xxx 执行,却对背后的底层逻辑一知半解,甚至误以为“能写出可运行的程序,就是懂 Linux 开发”。
其实,ELF 文件就是 Linux 程序运行的“灵魂载体”,从编译链接后的二进制文件,到被操作系统加载、解析、执行,每一步都藏着 Linux 内核的底层逻辑。不懂 ELF,你就无法真正理解程序的启动流程、内存布局,更谈不上排查程序崩溃、优化运行性能。别再只停留在“会写代码”的表面,今天就从 ELF 文件入手,搞懂它怎么跑起来,才算真正入门 Linux 程序开发。
一、先搞懂:什么是 ELF 文件?
面试题写作模版
首先明确一个基础:在 Linux 系统中,你编译生成的可执行文件(比如 gcc 编译后默认的 a.out)、目标文件(.o 文件)、动态库(.so 文件),本质上都是 ELF 格式文件——ELF(Executable and Linkable Format)就是 Linux 下统一的“可执行/可链接文件格式”,内核只认这种格式的文件,才能加载运行。
举个最简单的例子:你写一个简单的 C 程序 test.c:
#include<stdio.h>intmain(){printf("Hello Linux\n");return 0;}
用 gcc test.c 编译后,生成 a.out,执行 file a.out 命令,会看到这样的输出:a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=xxx, for GNU/Linux 3.2.0, not stripped
这段输出里,每一个关键词都和 ELF 的运行有关,后面我们逐一拆解。简单说:ELF 文件就是把你的源代码,经过预处理、编译、汇编、链接四个步骤后,包装成内核能识别的“结构化文件”,里面包含了程序运行所需的所有指令、数据和配置信息。
二、ELF 文件格式详解
面试题写作模版
2.1 ELF 文件整体结构
(1)文件头:ELF 文件头位于文件的开头,是整个 ELF 文件的核心元数据区域,其作用是提供关于文件的基本属性和组织结构的关键信息。文件头通常包含魔数(Magic Number)、文件类型、版本号、目标体系结构、入口地址等字段。其中,魔数是一个固定的 4 字节序列,用于标识文件是否为 ELF 格式;文件类型则定义了该文件的具体用途,例如可执行文件、共享对象或重定位文件等。版本号记录了 ELF 文件格式的版本信息,以确保兼容性。
目标体系结构字段指定了文件所针对的硬件平台,如 x86、ARM 或其他架构。入口地址则指向程序执行时的第一条指令在内存中的位置。这些信息共同构成了 ELF 文件的基本属性,使得操作系统能够快速识别并正确处理该文件。通过对文件头的解析,不仅可以验证文件的合法性,还可以为后续的链接和加载过程提供必要的上下文信息。
(2)节头表与程序头表:节头表(Section Header Table)和程序头表(Program Header Table)是 ELF 文件中两个至关重要的数据结构,它们分别从静态视角和动态视角描述了文件的内部组织结构和程序执行时的视图。节头表列出了文件中各个节(Section)的详细信息,包括节的名称、类型、大小、偏移量以及属性等。每个节在 ELF 文件中扮演不同的角色,例如 .text 节存储代码,.data 节存储已初始化的全局变量,而 .bss 节存储未初始化的全局变量。节头表的主要作用是在静态分析工具(如 readelf 和 objdump)中提供对文件内部结构的深入洞察,帮助开发者理解文件的组成和布局。
相比之下,程序头表则关注于文件在运行时如何被加载到内存中。程序头表中的每个条目描述了文件中的一个段(Segment),这些段在加载时被映射到进程的虚拟地址空间中。例如,一个典型的 ELF 可执行文件可能包含多个段,如代码段、数据段和动态链接段等。程序头表的存在使得操作系统能够在加载过程中根据段的信息进行内存分配和权限设置。尽管节头表和程序头表在功能上有所区别,但它们之间存在密切的联系。例如,某些段可能直接对应于一个或多个节,这种映射关系在文件加载和执行过程中起到了桥梁作用。通过综合分析这两个表的内容,可以更全面地理解 ELF 文件的静态特性和动态行为。
2.2 重要节的解读
(1) .text 节是 ELF 文件中最为关键的节之一,其主要功能是存储程序的机器代码指令。这些指令构成了程序的核心逻辑,并在运行时由处理器直接执行。由于 .text 节的内容通常是只读的,因此它在进程的虚拟地址空间中被映射为可执行但不可写的区域,以防止代码被意外修改。通过分析 .text 节中的机器代码,可以深入了解程序的执行流程和算法实现。例如,使用反汇编工具(如 objdump)可以将二进制机器码转换为汇编语言形式,从而便于人类阅读和理解。以下是一个简单的示例,展示了如何使用 objdump 查看 .text 节中的汇编代码:
objdump -d your_program | less上述命令将生成目标文件的反汇编输出,其中包含了 .text 节中每一条指令的汇编表示及其对应的机器码。通过阅读这些反汇编代码,开发者可以识别出函数入口点、控制流结构以及函数调用关系等关键信息。此外,.text 节的内容在静态分析中也有广泛应用,例如恶意代码检测和漏洞分析等领域。
研究表明,基于控制流图特征的方法能够有效提取 .text 节中的行为模式,从而用于恶意软件的分类和识别。因此,深入理解 .text 节的结构和作用对于掌握程序运行机制至关重要。
(2).data 节和 .bss 节在 ELF 文件中分别用于存储已初始化和未初始化的全局变量,它们在程序的内存分配和初始化过程中发挥着不同的作用。.data 节包含所有在编译时已显式初始化的全局变量和静态变量,这些变量的初始值在文件中被明确指定。由于这些变量需要占用实际的空间,.data 节在文件加载过程中会被映射到进程的虚拟地址空间中,并分配相应的物理内存。例如,一个初始化为非零值的全局数组将存储在 .data 节中,以确保程序启动时其内容已正确初始化。
相比之下,.bss 节则用于存储未初始化或初始化为零的全局变量和静态变量。与 .data 节不同,.bss 节本身不占用文件空间,因为其内容均为零值。在文件加载时,操作系统会根据 .bss 节的大小在进程的虚拟地址空间中分配一块零初始化的内存区域。这种设计显著减少了可执行文件的体积,同时提高了内存利用率。在程序运行过程中,.data 节和 .bss 节的内容均位于数据段中,但前者具有初始值,而后者则被初始化为零。这种区分不仅优化了文件存储效率,还为程序的内存管理提供了灵活性。通过理解这两个节的功能和差异,开发者可以更好地优化程序的内存使用并避免潜在的内存相关错误。
三、Linux 可执行文件生成过程
面试题写作模版
3.1 从源代码到 ELF 文件,经历了什么?
很多人只知道“gcc 编译生成可执行文件”,但不知道中间的过程,这也是不懂 ELF 运行逻辑的核心原因。其实从 test.c 到 a.out,要经过 4 个关键步骤,每一步都在为最终的运行做准备:
- 预处理:执行 gcc -E test.c -o test.i,主要是展开#include 头文件、替换#define 宏定义,生成预处理后的文本文件,此时还没有任何机器指令。
- 编译+汇编:执行 gcc -c test.i -o test.o,先把预处理后的代码翻译成机器指令,再汇编成目标文件 test.o——这时候的 test.o 已经是 ELF 格式(可重定位目标文件),但还不能直接运行,因为它缺少外部依赖(比如 printf 函数的实现)。
- 链接:执行 ld test.o -lc -o a.out(gcc 底层也是调用 ld 链接),把 test.o 和系统库(比如提供 printf 的 libc.so)合并,修正符号地址(重定位),最终生成可执行 ELF 文件 a.out。
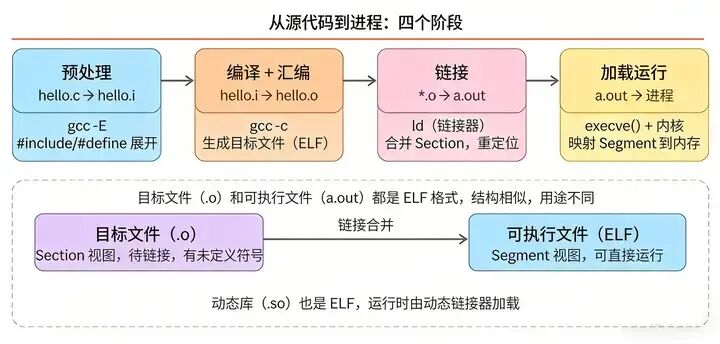
这里要注意:目标文件(.o)、可执行文件(a.out)、动态库(.so)都是 ELF 格式,但用途不同:.o 是中间文件,需要链接才能运行;.so 是动态库,供多个程序共享使用;a.out 是可执行文件,是最终能被内核加载的文件。
3.2 编译过程
在 Linux 环境中,可执行文件的生成首先依赖于编译过程,该过程将高级语言编写的源代码转换为机器可以执行的二进制指令。编译器在这一过程中扮演了核心角色,其主要任务是将源代码逐步翻译成目标文件。编译过程通常包括词法分析、语法分析、语义分析以及代码生成等多个阶段。词法分析阶段通过扫描源代码,将其分解为一个个具有独立意义的词法单元(Token),如关键字、标识符和运算符等。
随后,语法分析阶段根据编程语言的语法规则,将这些词法单元组织成语法树,以验证代码的结构合法性。语义分析则进一步检查语法树的语义正确性,例如变量类型的匹配性和作用域的定义。最后,在代码生成阶段,编译器将经过语义分析后的语法树转化为目标文件中的机器代码或汇编代码。目标文件通常采用 ELF 格式,其中包含了编译器生成的机器代码、数据以及重定位信息等,为后续的链接过程奠定了基础。
3.3 链接过程
链接过程是将编译生成的目标文件与其他必要的库文件合并,最终生成可执行文件的关键步骤。根据链接方式的不同,链接过程可分为静态链接和动态链接两种类型,每种方式都具有独特的原理和特点。
(1)静态链接:静态链接是指在编译阶段将目标文件与所需的静态库文件合并,生成一个独立的可执行文件。链接器在静态链接过程中负责解析目标文件中的符号引用,并从静态库中提取相应的代码和数据,将其整合到最终的可执行文件中。具体而言,静态库通常以归档文件(Archive)的形式存在,其中包含了多个独立的目标文件。链接器通过遍历这些目标文件,解析未定义的符号引用,并将其与库中的符号定义进行匹配和合并。
这种方式的优点在于生成的可执行文件具有较高的独立性,能够在没有外部依赖的情况下运行,从而简化了程序的部署过程。然而,静态链接也存在明显的缺点。首先,由于所有代码和数据都被直接复制到可执行文件中,导致文件体积显著增大,占用了更多的磁盘空间和内存资源。其次,当多个程序使用相同的静态库时,每个程序的副本都会包含相同的库代码,造成了存储资源的浪费。此外,静态链接方式下,库函数的更新需要重新编译和链接整个程序,降低了软件的维护效率。
(2)动态链接:动态链接是一种更为灵活的链接方式,其核心思想是在程序运行时动态加载和链接共享库中的代码和数据。与静态链接不同,动态链接过程中,链接器并不会将库代码直接整合到可执行文件中,而是在可执行文件中记录对共享库的符号引用信息。当程序运行时,动态链接器根据这些引用信息,在系统中查找并加载相应的共享库,然后解析符号引用并完成链接操作。
动态链接的优势主要体现在空间利用和代码共享方面。首先,由于多个程序可以共享同一份库代码,显著减少了内存和磁盘空间的占用。其次,动态链接支持库的独立更新,无需重新编译和链接应用程序即可享受库函数的最新版本,从而提高了软件的维护性和扩展性。此外,动态链接还支持插件机制和延迟加载等高级特性,进一步增强了程序的灵活性和性能。然而,动态链接也存在一定的局限性,例如程序运行时对外部共享库的依赖性可能导致环境配置复杂化,且在某些情况下可能影响程序的启动性能。
四、ELF 文件的运行原理
面试题写作模版
我们依然沿用之前的 test.c 程序,先执行编译生成可执行 ELF 文件,后续步骤将围绕这个文件展开实操,代码示例及编译命令如下:
# 1. 编写 test.c 程序(同上,此处方便实操对照)cat > test.c << EOF#include<stdio.h>intmain() {printf("Hello Linux\n");return 0;}EOF# 2. 编译生成动态链接的 ELF 可执行文件 a.outgcc test.c -o a.out# 3. 查看 ELF 文件基本信息(确认生成合法 ELF)readelf -h a.out | grep -E "Magic|Entry|Type"# 4. 执行 ELF 文件(触发后续加载运行流程)./a.out
上述命令可直接在 Linux 终端执行,执行后会输出程序运行结果及 ELF 文件核心信息,结合这个实操示例,我们拆解 ELF 的加载运行步骤。
4.1 Shell 触发系统调用,请求加载 ELF
你在终端输入./a.out 时,当前运行的 Shell 进程(比如 bash)会先创建一个子进程,然后子进程调用 execve()系统调用,把./a.out 的路径传给内核,请求内核“替换当前子进程的内存空间,加载并运行这个 ELF 文件”——这是 ELF 运行的起点。
如果 ELF 文件没有执行权限(比如没加 chmod +x),内核会直接返回错误(Permission denied),程序无法启动。
4.2 内核验证 ELF 合法性,解析文件头
内核收到 execve()请求后,首先会读取 ELF 文件的“ELF 头”(文件最开头的部分),做两件关键验证:
验证魔数:ELF 头的前 4 个字节是 0x7F 45 4C 46(对应 ASCII 的 DEL E L F),这是 ELF 文件的“身份标识”,内核只有看到这个魔数,才会认为这是一个合法的 ELF 文件。 验证架构匹配:比如 x86_64 的 ELF 文件,不能在 ARM 架构的 Linux 系统上运行,内核会检查 ELF 头中的架构信息,不匹配则拒绝加载。
同时,ELF 头还会告诉内核:程序头表的位置、节头表的位置、程序的入口地址(不是 main 函数,后面会说)等关键信息——相当于 ELF 文件的“目录”,指引内核如何加载。
4.3 内核将 ELF 段映射到内存
ELF 文件内部有两种核心视角:链接时的“节(Section)”和运行时的“段(Segment)”。链接器关心节(比如.text 代码节、.data 数据节),而内核加载时只关心段——多个节会按权限合并成一个段,内核以段为单位,将 ELF 文件映射到进程的虚拟地址空间。最关键的两个段:
LOAD Segment 1:包含.text(机器指令)和.rodata(只读数据,比如字符串常量),权限是 r-x(读+执行,不可写),内核会把这部分映射到虚拟地址空间的“代码区”,供 CPU 执行指令。 LOAD Segment 2:包含.data(已初始化的全局/静态变量,比如 int x=42)和.bss(未初始化的全局/静态变量,比如 int y),权限是 rw-(读+写,不可执行),内核会把这部分映射到“数据区”,用于存储程序运行时的数据。
这里有个小细节:.bss 段在 ELF 文件中不占磁盘空间,只记录大小,内核加载时会为其分配虚拟地址空间,并自动清零——这样设计是为了节省文件体积,非常巧妙。可以用 readelf -l a.out 命令查看 ELF 的段信息,能清晰看到每个段的权限、虚拟地址和大小。
4.4 动态链接(如果是动态链接程序)
我们平时用 gcc 编译的程序,默认都是动态链接(不是静态链接),也就是说,程序依赖的外部函数(比如 printf),并没有被打包到 a.out 中,而是存放在系统的动态库(libc.so)中。这时候就需要“动态链接器”(ld-linux.so)来完成最后一步准备。
ELF 文件的.interp 节会指定动态链接器的路径(比如/lib64/ld-linux-x86-64.so.2),内核会先将动态链接器映射到进程的虚拟地址空间,然后把控制权交给动态链接器,由它完成:
解析依赖:读取 ELF 的.dynamic 节,找到程序依赖的动态库(比如 libc.so.6),从系统库路径(/lib64、/usr/lib64)中找到对应的动态库文件。 加载动态库:将动态库的代码段、数据段映射到进程的虚拟地址空间。 符号解析与重定位:通过 PLT(过程链接表)和 GOT(全局偏移表)机制,找到 printf 等函数在动态库中的真实地址,填入 GOT 中——这样程序调用 printf 时,就能直接找到对应的实现。
这里有个优化点:PLT+GOT 实现了“惰性绑定”,也就是第一次调用 printf 时才解析地址,后续调用直接使用 GOT 中存储的地址,既能加快程序启动速度,又能减少开销。这也是 LD_PRELOAD 能注入自定义函数的底层原理——通过替换 GOT 表项,让函数调用跳转到自定义实现。
可以用 ldd a.out 命令,查看程序依赖的所有动态库;用 readelf -h a.out | grep Entry,能看到程序的入口地址(不是 main 函数)。
4.5 从入口点执行,最终调用 main 函数
很多人误以为程序是从 main 函数开始执行的,其实不是——ELF 文件的真正入口是_start(由 C 运行时 CRT 提供),而不是 main。
当动态链接完成后,动态链接器会把控制权交给 ELF 文件的入口点(_start),_start 会做一些初始化工作:初始化栈、传入 argc(参数个数)、argv(参数数组)、envp(环境变量),然后调用__libc_start_main(),这个函数会进一步调用全局构造函数(比如 C++全局对象的构造),最后才调用我们写的 main 函数。
main 函数执行完成后,会返回一个值,__libc_start_main()会调用 exit()函数,终止进程,回收资源——这就是 ELF 文件从加载到运行结束的完整流程。
五、ELF 文件在 Linux 中的加载与执行
面试题写作模版
5.1 操作系统加载过程
当用户在 Linux 系统中执行可执行文件时,操作系统内核通过系统调用(如 execve())接管并开始加载过程。这一过程的核心目标是确保程序能够以正确的状态进入运行环境,同时保障系统的安全性和稳定性。内核在加载过程中的主要任务包括验证文件格式、分配内存空间以及初始化进程上下文等关键步骤。
首先,内核需要对 ELF 文件的格式进行验证,以确保其符合 ELF 规范的定义。这一步骤通过解析文件头中的魔数(Magic Number)、文件类型以及版本信息来完成。魔数作为 ELF 文件的标识字段,用于快速判断文件是否为有效的 ELF 格式;而文件类型则进一步指明该文件是可执行文件、共享库还是目标文件。此外,内核还会检查程序头表中的信息,以确认文件中是否包含可执行代码段和数据段等必要内容。
其次,内核为即将运行的进程分配虚拟内存空间,并根据 ELF 文件中的程序头表信息将相关段映射到进程的虚拟地址空间中。这一过程涉及到内存区域的预留和权限设置,例如代码段通常被标记为只读,而数据段则具有读写权限。值得注意的是,Linux 系统采用延迟分配策略,即在程序实际访问内存页面时才分配物理内存,从而优化系统资源利用率。
最后,内核初始化进程上下文,包括设置程序计数器(Program Counter, PC)的初始值、创建堆栈以及配置其他寄存器状态。这些操作为程序的执行奠定了基础,使得进程能够从 ELF 文件指定的入口点开始执行指令。通过上述一系列复杂但高效的操作,内核完成了从加载到准备运行的全过程,为程序的顺利执行提供了保障。
5.2 进程虚拟地址空间布局
ELF 文件在进程虚拟地址空间中的布局是其成功运行的关键因素之一,这种布局不仅反映了文件内部的组织结构,还直接影响程序执行过程中的内存访问效率。在 Linux 系统中,每个进程都拥有独立的虚拟地址空间,其范围通常从 0 到 4GB(对于 32 位系统),其中低 3GB 用于用户空间,高 1GB 保留给内核空间使用。ELF 文件的各个段根据其在程序头表中的定义被映射到用户空间的特定区域,形成了一种层次分明且功能明确的布局方式。
具体而言,ELF 文件的主要段在虚拟地址空间中的分布如下:代码段(.text)通常位于虚拟地址空间的较低位置,紧随其后的数据段(.data)和未初始化数据段(.bss)。代码段包含程序的机器指令,因此被映射为只读权限,以防止意外修改导致程序崩溃。数据段存储已初始化的全局变量和静态变量,而 .bss 段则用于存放未初始化或初始化为零的变量。由于 .bss 段的内容在程序启动前可以由内核清零,因此它在文件中实际不占用空间,仅在虚拟地址空间中保留一个映射区域。
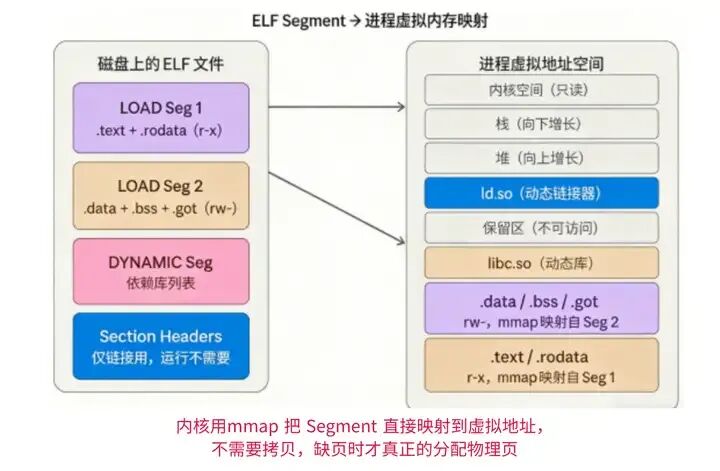
此外,堆(Heap)和栈(Stack)是进程虚拟地址空间中另外两个重要的组成部分。堆用于动态内存分配,其大小在程序运行过程中可以动态增长;栈则用于存储函数调用时的局部变量、返回地址以及参数传递等信息,其生长方向是从高地址向低地址扩展。这种布局方式不仅提高了内存管理的灵活性,还增强了程序的安全性,因为代码段和数据段的分离可以有效防止恶意代码通过篡改数据来执行非法操作。
从整体上看,ELF 文件在虚拟地址空间中的布局体现了模块化设计的思想,不同段的功能划分明确且相互协作,共同支撑程序的正常运行。这种设计不仅便于操作系统的内存管理,还为程序员提供了清晰的逻辑视图,有助于优化程序性能和排查潜在问题。
5.3 从加载到执行的流程
从操作系统加载 ELF 文件到程序开始执行的完整流程涉及多个关键步骤,包括设置程序计数器、初始化栈和堆、以及执行入口函数等操作。这一过程不仅是程序运行的基础,也是理解 Linux 系统底层机制的重要环节。通过结合流程图和示例代码,可以更直观地展示这一复杂流程的具体实现细节。
首先,当用户通过命令行输入可执行文件名并触发 execve() 系统调用时,内核开始执行加载操作。内核首先验证 ELF 文件的格式,并根据程序头表的信息将相关段映射到进程的虚拟地址空间中。在此过程中,内核会为代码段、数据段、堆和栈分配相应的内存区域,并设置适当的访问权限。随后,内核将程序计数器(PC)的值设置为 ELF 文件中指定的入口地址,通常这是 _start 函数的地址,该函数由链接器自动生成并负责初始化进程运行环境。
接下来,_start 函数执行一系列初始化操作,包括设置栈指针、初始化堆管理器以及调用 __libc_start_main() 函数。__libc_start_main() 函数是 C 语言运行时库的一部分,其职责是进一步初始化全局变量、注册信号处理函数,并最终调用用户定义的主函数 main()。这一过程确保了程序在进入主逻辑之前已完成所有必要的准备工作,例如环境变量的初始化和动态链接库的加载。
六、ELF 运行相关实践
面试题写作模版
6.1 使用 readelf 工具查看文件信息
在 Linux 系统中,readelf 是一个功能强大的工具,用于显示 ELF 文件的详细信息。通过 readelf,开发者可以深入了解 ELF 文件的内部结构,包括文件头、节头表和程序头表等关键内容。这些信息不仅有助于理解程序的运行机制,还为调试和优化提供了重要依据。
首先,readelf 的基本用法非常简单。例如,要查看一个 ELF 文件的整体信息,可以使用以下命令:
readelf -a <filename>这条命令会输出文件的全部信息,包括文件头、节头表、程序头表、符号表等。对于初学者而言,重点关注文件头、节头表和程序头表的内容尤为重要。文件头位于 ELF 文件的起始位置,包含了一些标识文件基本属性的信息,如魔数(Magic Number)、文件类型、版本号以及入口点地址等。通过读取文件头,我们可以确认该文件是否为有效的 ELF 文件,并初步判断其用途。例如,以下命令仅显示文件头信息:
readelf -h <filename>执行上述命令后,输出结果将展示文件头的具体字段及其值,其中魔数字段用于标识文件格式,而入口点地址则指示了程序开始执行的位置。
节头表和程序头表则分别描述了 ELF 文件的内部组织结构和程序执行视图。节头表列出了各个节(Section)的详细信息,如节名、类型、大小和偏移量等。通过分析节头表,开发者可以清晰地了解程序中各部分的存储布局,例如 .text 节中存储的机器代码、.data 节中保存的已初始化全局变量等。相比之下,程序头表更关注程序在运行时的情况,它定义了加载器如何将文件映射到内存中。以下命令分别用于查看节头表和程序头表:
readelf -S <filename> # 查看节头表readelf -l <filename> # 查看程序头表
通过实际案例分析,假设我们有一个名为 hello 的可执行文件,使用 readelf 查看其节头表信息:
readelf -S hello输出结果将显示多个节的信息,其中 .text 节通常位于较低地址区域,表示该节包含程序的指令代码;而 .data 节则位于较高地址区域,用于存放已初始化的全局变量。这种布局与程序虚拟地址空间的映射密切相关,进一步揭示了程序运行时的内存分配策略。
此外,readelf 还可以帮助开发者理解动态链接过程中共享库的加载机制。通过分析程序头表中的 PT_DYNAMIC 段,可以获取与动态链接相关的信息,例如动态链接器所需的符号表和重定位表等。这些信息对于排查程序运行时的兼容性问题具有重要意义,尤其是在涉及第三方库调用的场景下。
6.2 使用 objdump 工具反汇编
objdump 是另一个在 Linux 系统下广泛使用的工具,其主要功能是对 ELF 文件进行反汇编操作,将机器代码转换为人可读的汇编代码。这一功能使得开发者能够深入理解程序的底层实现细节,特别是在分析程序运行逻辑或排查错误时显得尤为重要。
要使用 objdump 进行反汇编,最基本的命令格式如下:
objdump -d <filename>上述命令会对指定文件进行反汇编,并输出相应的汇编代码。例如,对于一个名为 hello 的可执行文件,执行以下命令:
objdump -d hello输出结果将显示该文件中所有可执行节的汇编代码,通常包括 .text 节中的指令部分。通过阅读这些汇编代码,开发者可以直观地了解程序的控制流、函数调用以及数据操作等关键信息。例如,在 .text 节中,主函数 main 的入口点通常以一条跳转指令或函数调用开头,随后是一系列实现具体功能的指令序列。
结合前文对 ELF 文件结构的分析,反汇编结果能够进一步揭示汇编代码与 ELF 文件内部组织之间的关系。例如,\text 节中的每一条指令都对应于文件中的一个字节序列,而这些字节序列在加载过程中会被映射到进程虚拟地址空间的特定区域。因此,通过对比反汇编代码与节头表中的信息,开发者可以准确地定位某段代码在文件中的存储位置及其在内存中的映射关系。
此外,objdump 还支持多种选项,用于定制化反汇编输出的内容。例如,使用 -D 选项可以对整个文件进行反汇编,包括只读数据节(如 .rodata)和未初始化数据节(如 .bss);而使用 -M intel 选项则可以切换至 Intel 语法格式,使汇编代码更加易于阅读。以下命令展示了如何以 Intel 语法格式反汇编整个文件:
objdump -D -M intel <filename>通过实际案例分析,假设我们正在调试一个包含内存泄漏问题的程序。利用 objdump 生成的反汇编代码,我们可以逐行检查程序中对堆内存的分配和释放操作。例如,malloc 和 free 函数调用通常会在汇编代码中体现为对系统调用 brk 或 mmap 的间接引用。通过定位这些调用点,并结合程序头表中的相关信息,开发者可以快速找到可能导致内存泄漏的代码段。
值得注意的是,objdump 还可以与其他工具结合使用,以增强其功能。例如,将 objdump 与 readelf 配合使用,可以同时查看 ELF 文件的静态结构和动态行为。具体而言,可以先使用 readelf 分析文件的符号表和重定位信息,然后利用 objdump 生成反汇编代码,从而在符号级别上理解程序的运行逻辑。这种方法在处理复杂的二进制漏洞检测任务时尤为有效,例如基于控制流图特征的恶意代码检测方法中所提到的应用场景。
七、 基于 ELF 文件的程序调试
面试题写作模版
7.1 常见调试方法
在 Linux 系统中,基于 ELF 文件的程序调试是定位和解决软件问题的关键环节。GNU Debugger (GDB) 作为一款功能强大的调试工具,为开发者提供了多种高效的调试手段,包括设置断点、单步执行以及查看变量值等操作,这些方法在分析程序运行过程中的行为和状态方面具有重要作用。通过设置断点,开发者可以在程序执行到特定位置时暂停,并检查当前的内存状态、寄存器值以及栈信息,从而精确定位潜在的问题来源。
此外,单步执行功能允许开发者逐行分析源代码或汇编指令的执行过程,这对于理解复杂的控制流和逻辑判断尤为重要。同时,GDB 还支持对变量值的实时监控与修改,这不仅有助于验证程序的正确性,还可以在运行时动态调整参数以测试不同场景下的行为表现。这些调试方法的有效应用,能够显著提升程序故障排查的效率,尤其在处理涉及 ELF 文件格式相关的问题时,其作用更加突出。
除了上述基本功能外,现代调试工具还提供了对多线程程序和非确定性行为的支持。例如,在多线程环境中,GDB 允许开发者切换线程上下文并分别监控每个线程的执行状态,这对于诊断因线程同步或资源竞争引发的问题至关重要。同时,结合 ELF 文件中包含的符号表和调试信息,开发者可以更直观地理解程序的内部结构及其运行机制。值得注意的是,尽管这些高级功能增强了调试能力,但其使用也需要对 ELF 文件格式及调试工具的工作原理有深入理解,以便充分发挥其优势。
7.2 通过 ELF 信息定位问题
在实际开发过程中,利用 ELF 文件中蕴含的丰富信息来定位程序错误是一种高效且可靠的调试策略。ELF 文件不仅包含了可执行代码和静态数据,还嵌入了诸如符号表、重定位信息以及调试节等关键内容,这些信息为程序调试提供了坚实的基础。符号表记录了程序中定义的函数、变量及其对应的地址信息,使得调试器能够将运行时产生的地址映射回源代码中的具体位置,从而显著提升调试的准确性。例如,当程序崩溃时,核心转储文件会生成一个包含出错指令地址的堆栈跟踪,通过分析 ELF 文件中的符号表,开发者可以快速定位到引发异常的代码行,进而深入排查问题根源。
此外,ELF 文件中的调试信息节(如 .debug_info)存储了用于重建源代码级调试环境的元数据,包括类型定义、局部变量作用域以及源代码行号映射等。这些信息在配合调试工具使用时,能够以图形化界面展示程序的执行路径和变量状态,极大地简化了复杂问题的分析过程。例如,某实际案例中,一个由于堆溢出导致的内存损坏问题最初表现为随机崩溃,通过读取 ELF 文件中的调试信息并结合 GDB 进行反汇编分析,最终发现是某函数未能正确释放动态分配的内存所致。此类基于 ELF 信息的调试方法不仅适用于传统的内存泄漏和越界访问问题,还可用于解决由动态链接库加载失败或版本不匹配引发的运行时错误。
(1)简单崩溃程序示例代码如下:
//crash.c:手动制造空指针解引用崩溃#include<stdio.h>// 崩溃函数voidcause_crash(){// 空指针赋值,必然触发段错误 (Segmentation fault)int *ptr = NULL;*ptr = 100;}intmain(){printf("程序开始运行...\n");cause_crash(); // 调用崩溃函数printf("程序正常结束\n");return 0;}
编译命令(生成带调试信息的 ELF)
# 生成带调试信息+符号表的 ELF 可执行文件gcc -g crash.c -o crash_demo(2)程序崩溃 + 核心转储,定位崩溃代码行
①启用核心转储(Linux 默认关闭)
ulimit -c unlimited # 允许生成核心转储文件②运行程序触发崩溃
./crash_demo输出:
程序开始运行...Segmentation fault (core dumped) # 生成 core 文件③GDB 结合 ELF 调试信息定位崩溃位置
# 格式:gdb 可执行文件 核心转储文件gdb ./crash_demo core④GDB 关键命令(直接定位源码)
# 查看崩溃堆栈(核心!ELF 符号表把地址映射为函数+行号)bt# 查看崩溃所在的具体代码行list⑤执行效果
#0 0x0000000000401136 in cause_crash () at crash.c:7#1 0x0000000000401153 in main () at crash.c:13直接定位:崩溃在 crash.c 第 7 行,函数 cause_crash 内,完全对应你描述的符号表映射地址到源码。
(3)内存泄漏 / 堆溢出调试(结合 ELF 调试信息)
//堆内存未释放 + 溢出#include<stdio.h>#include<stdlib.h>// 内存泄漏 + 堆溢出函数voidmemory_bug(){// 分配 10 字节堆内存char *buf = (char*)malloc(10);if (buf == NULL) return;// 堆溢出:写入 20 字节,超出分配大小(内存损坏)for (int i = 0; i < 20; i++) {buf[i] = 'A';}// 关键问题:未释放内存,导致内存泄漏// free(buf);}intmain(){memory_bug();printf("程序执行完毕\n");return 0;}
编译 + GDB 调试
gcc -g mem_leak.c -o mem_demogdb ./mem_demo
GDB 调试命令(利用 ELF 调试信息)
# 运行程序run# 触发内存错误后,查看变量和源码print buf # 查看堆内存地址list # 定位到溢出/未释放的代码行
(4)读取 ELF 文件本身的信息(符号表 / 调试节):使用 readelf/objdump 直接解析 ELF,验证你描述的符号表、调试节。
①查看 ELF 符号表(函数 / 变量地址)
# 查看符号表(.symtab)readelf -s crash_demo
输出(关键部分):
34: 0000000000401122 20 FUNC GLOBAL DEFAULT 14 cause_crash39: 0000000000401148 23 FUNC GLOBAL DEFAULT 14 main
②查看 ELF 调试节(.debug_info)
# 查看调试节(验证调试信息存在)readelf -S crash_demo | grep debug
输出:
[28] .debug_info PROGBITS 0000000000000000 00004000[29] .debug_line PROGBITS 0000000000000000 00004020
.debug_info/.debug_line,支持源码行号、变量作用域调试。
(5)动态链接库错误调试(版本 / 加载失败)
①编写依赖动态库的代码 dyn_test.c
//依赖不存在的动态库,运行失败#include<stdio.h>// 声明外部库函数(实际不存在,模拟链接失败)externvoidnon_exist_func();intmain() {non_exist_func();return 0;}
②编译(动态链接)
gcc -g dyn_test.c -o dyn_demo -lnon_exist # 链接不存在的库③查看 ELF 动态链接信息
# 查看程序依赖的动态库(.dynamic 节)readelf -d dyn_demo
输出:
0x0000000000000001 (NEEDED) 共享库:[libnon_exist.so]0x0000000000000001 (NEEDED) 共享库:[libc.so.6]
直接定位:程序依赖 libnon_exist.so,运行时必然加载失败。
综上所述,ELF 文件中的符号表和调试信息为程序故障定位提供了强有力的支持。通过合理运用这些信息,开发者能够在较短时间内识别并修复潜在问题,从而提高软件的稳定性和可靠性。然而,这一过程同样要求开发者对 ELF 文件格式的细节有清晰的认识,并熟练掌握相关调试工具的使用技巧,以便在实际应用中取得最佳效果。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 零基础吃透Linux虚拟化(商场类比+图表详解版)
- Linux网络基础全攻略:OSI七层、子网划分、路由配置、排错实战
- 10 个超实用 Python 自动化脚本,覆盖 80% 办公高频场景!
- python巡检交换机并将巡检记录以邮件发送
- Abaqus迎来最重磅升级:Python 3.10 全面来袭,CAE自动化效率直接翻倍!
- python高阶:16、tkinter库(Text组件)
- 用Python+PyQt5打造高颜值短链接生成器
- Linux程序员的17年:和张雪峰老师一样遭遇心脏骤停,但捡回了一条命,守住爱与代码
- 这个网站我愿称之为: python 学习之光!
- 零基础学 Python 别乱找资料!这套鸿蒙团队力荐教程,400集干货免费领
