相关性分析(基于Python)3—— 协方差的定义与性质
- 2026-07-02 19:38:26
在上一节中,我们将协方差定义为去中心化后的随机变量在希尔伯特空间中的内积。这个定义为我们提供了一个极具启发性的几何视角,使得我们能够将概率分布的形态与向量空间的夹角联系起来。
然而,在实际的理论推导和工程计算中,我们更频繁使用的是协方差的代数性质——协方差算子 ,它在概率论的代数结构中扮演着类似于普通乘法的角色,遵循着一套极其严密且优美的运算规则。
本节我们将从协方差的基础定义出发,系统推导它的各项代数性质。这些性质是后续推导皮尔逊相关系数、主成分分析(PCA)等理论及各类应用的基础。
1协方差的基础代数性质
我们再次写下协方差的原始定义。对于任意两个具有有限二阶矩的随机变量 和 ,它们的协方差定义为:
基于这个定义以及数学期望的线性性质,我们可以推导出协方差的四个基础代数性质。
性质1:对称性(Symmetry)
由于实数乘法满足交换律,即 ,对其两边同时取期望,显然有:
这个性质在上一节讨论协方差矩阵时已经提及,它保证了协方差矩阵必然是一个对称矩阵。
性质2:与自身的协方差退化为方差
当我们计算一个随机变量 与它自身的协方差时,将 替换为 代入定义式:
等式最右侧恰好是方差的定义。因此:
这说明方差本质上是协方差在单一变量上的特例。在多维空间中,方差度量了变量在自身维度上的离散程度,而协方差度量了变量在交叉维度上的协同离散程度。
性质3:平移不变性(Translation Invariance)
假设我们对变量 和 分别加上常数 和 ,构造新的随机变量 和 。我们来计算 和 的协方差。
首先求 和 的期望:
接着计算它们去中心化后的偏差:
将这两个偏差代入协方差定义:
因此我们得到:
平移不变性是一个非常重要的物理性质。它表明,协方差只关注变量的波动(即偏离均值的程度),而完全忽略变量的绝对水平(即均值本身)。
性质4:尺度同变性(Scale Equivariance)
现在我们对变量 和 分别乘以常数 和 ,构造 和 。
同样先求期望:
计算偏差:
代入协方差定义:
由于 和 是常数,可以提取到期望算子外部:
尺度同变性揭示了协方差对量纲的敏感性。如果我们将身高的单位从米换成厘米(乘以100),协方差的数值就会放大100倍。这也是我们在上一节推导皮尔逊相关系数时,必须除以标准差进行标准化的根本原因。
2双线性与和的方差公式
双线性意味着协方差算子在它的每一个参数位置上,都表现出线性函数的特征。具体来说,对于任意随机变量 以及常数 ,协方差满足分配律:
我们可以通过期望的线性性质来严格推导这个等式。为了书写简洁,我们令 ,,。
首先处理左边的第一项 的去中心化形式:
将其代入协方差定义:
推导完成。由于协方差具有对称性,这个分配律对第二个参数同样适用:
双线性性质将协方差的运算规则与多项式乘法完全统一了起来。基于双线性,我们可以推导出现代统计学中最重要、应用最广泛的公式之一:两个随机变量之和的方差公式。
假设我们要计算随机变量 的方差。根据性质2,方差等于变量与自身的协方差:
利用双线性性质,我们可以像展开多项式 一样展开这个协方差:
根据对称性 ,以及性质2 ,我们得到最终公式:
这个公式的物理意义极其深远。它告诉我们,两个信号叠加后的总波动(方差),并不等于它们各自波动的简单相加。总波动还取决于这两个信号之间是如何协同变化的(协方差)。
如果 和 呈正相关(),意味着当 出现正向波动时, 也倾向于出现正向波动,两者的波动会相互叠加放大,导致总方差大于各自方差之和。 如果 和 相互独立或不相关(),总方差恰好等于各自方差之和。 如果 和 呈负相关(),意味着当 出现正向波动时, 倾向于出现负向波动,两者的波动会相互抵消,导致总方差小于各自方差之和。
我们通过一段Python代码,模拟这三种不同的协方差场景,并可视化两个随机变量相加后,其概率密度分布形态(即方差大小)的显著变化。
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子np.random.seed(42)n_samples = 10000# 定义边缘分布的参数:期望均为0,方差均为1mu_X = 0mu_Y = 0var_X = 1.0var_Y = 1.0# 场景1:正相关 (Cov > 0)cov_pos = 0.8cov_matrix_pos = [[var_X, cov_pos], [cov_pos, var_Y]]data_pos = np.random.multivariate_normal([mu_X, mu_Y], cov_matrix_pos, n_samples)sum_pos = data_pos[:, 0] + data_pos[:, 1]# 场景2:不相关 (Cov = 0)cov_zero = 0.0cov_matrix_zero = [[var_X, cov_zero], [cov_zero, var_Y]]data_zero = np.random.multivariate_normal([mu_X, mu_Y], cov_matrix_zero, n_samples)sum_zero = data_zero[:, 0] + data_zero[:, 1]# 场景3:负相关 (Cov < 0)cov_neg = -0.8cov_matrix_neg = [[var_X, cov_neg], [cov_neg, var_Y]]data_neg = np.random.multivariate_normal([mu_X, mu_Y], cov_matrix_neg, n_samples)sum_neg = data_neg[:, 0] + data_neg[:, 1]# 创建图表fig, axes = plt.subplots(1, 3, figsize=(18, 5), sharey=True, sharex=True)fig.suptitle('和的方差公式:$Var(X+Y) = Var(X) + Var(Y) + 2Cov(X,Y)$', fontsize=16)scenarios = [ (axes[0], sum_pos, cov_pos, '正相关 (波动放大)', '#d73027'), (axes[1], sum_zero, cov_zero, '不相关 (波动独立)', '#4575b4'), (axes[2], sum_neg, cov_neg, '负相关 (波动抵消)', '#1a9850')]x_grid = np.linspace(-6, 6, 500)for ax, sum_data, cov_val, title, color in scenarios:# 绘制 X+Y 的直方图 ax.hist(sum_data, bins=60, density=True, alpha=0.5, color=color, edgecolor='white')# 计算理论方差 theoretical_var = var_X + var_Y + 2 * cov_val# 绘制理论上的正态分布概率密度曲线 pdf = stats.norm.pdf(x_grid, loc=0, scale=np.sqrt(theoretical_var)) ax.plot(x_grid, pdf, color='black', linewidth=2, linestyle='--')# 绘制基准线:独立的 X 和 Y 的分布 (方差为1) pdf_base = stats.norm.pdf(x_grid, loc=0, scale=1) ax.plot(x_grid, pdf_base, color='gray', linewidth=1.5, linestyle=':', label='单一变量 X 或 Y')# 添加统计信息文本 actual_var = np.var(sum_data) info_text = f"Cov(X,Y) = {cov_val}\n理论 Var(X+Y) = {theoretical_var:.1f}\n实际 Var(X+Y) = {actual_var:.2f}" ax.text(0.05, 0.95, info_text, transform=ax.transAxes, fontsize=11, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.8)) ax.set_title(title, fontsize=14) ax.set_xlabel('取值 (X+Y)', fontsize=12) ax.grid(True, linestyle=':', alpha=0.6)if ax == axes[0]: ax.set_ylabel('概率密度', fontsize=12) ax.legend(loc='upper right')plt.tight_layout(rect=[0, 0.03, 1, 0.95])plt.show()执行结果如下:
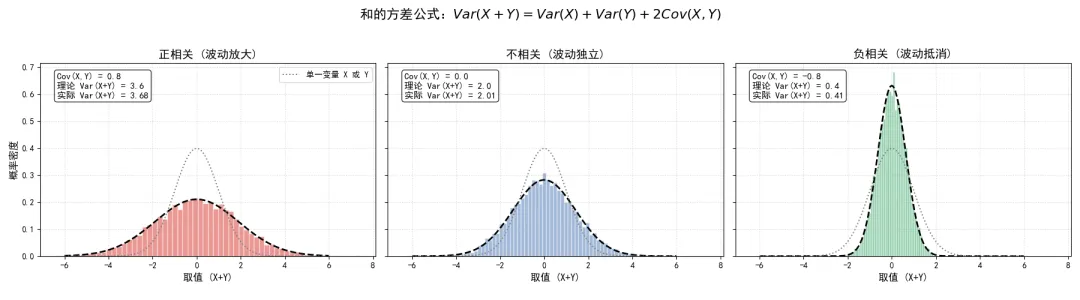
三幅图表清晰地展示了协方差对方差叠加的控制作用。
在左图中,由于 和 高度正相关(),它们相加后的分布变得非常宽广。理论方差为 。红色的直方图比灰色的单一变量基准线扁平得多,这说明系统处于高波动、高风险状态。
在中图中, 和 不相关(),总方差严格等于 。这是经典统计学中最常见的独立同分布(i.i.d)假设下的叠加状态。
在右图中,由于 和 高度负相关(),它们相加后的分布变得极其陡峭和集中。理论方差骤降至 。绿色的直方图远比灰色的基准线高耸,说明大部分波动在相加的过程中被内部抵消了,系统变得极其稳定。
这个简单的代数公式 ,正是现代金融学中风险对冲和资产配置的绝对核心。
3多变量扩展与协方差矩阵的二次型
我们将双变量的方差公式推广到 个随机变量的线性组合。假设我们有 个随机变量 ,以及对应的常数权重 。我们定义一个新的随机变量 ,它是这 个变量的加权和:
我们来计算 的方差。根据方差等于自身协方差的性质,以及协方差的双线性展开:
利用分配律,将这个双重求和展开:
这个公式可以进一步拆分为两部分:当 时,是各个变量自身的方差项;当 时,是不同变量之间的协方差项。由于 ,交叉项是对称出现的:
这个公式在代数形式上显得有些冗长。如果我们引入线性代数的矩阵表示法,整个公式会变得极其优雅。
令 为权重向量, 为随机向量。那么加权和可以写成向量内积 。
令 为这 个变量的协方差矩阵,其中 。
根据我们已推导的协方差矩阵性质,加权和 的方差可以直接写成一个二次型(Quadratic Form):
这个简洁的矩阵乘法公式 封装了 个变量自身的所有方差以及它们之间两两的所有协方差。
4协方差的工程应用案例
在上述三小节分析中,我们得出,对于 个随机变量的线性组合 ,其总方差 。
这个公式在纯数学领域只是一个代数恒等式,在金融工程中,我们把 看作是第 个金融资产(如股票、债券)在未来某个时期的收益率。由于未来的收益是未知的, 本质上是一个随机变量。 我们用资产收益率的数学期望 来衡量该资产的预期收益。 我们用资产收益率的方差 或标准差 来衡量该资产的风险(即收益的不确定性或波动率)。
假设我们有 个可供选择的资产,我们打算将资金按比例分配到这些资产中。权重向量 代表了我们在每个资产上的投资比例。为了保证资金全部投出,权重之和必须为1,即 。
我们构建的投资组合(Portfolio)的总收益率 ,就是各个资产收益率的加权和:
根据期望的线性性质,投资组合的预期总收益 是各个资产预期收益的加权平均:
到这里为止,一切都非常符合直觉。但当我们计算投资组合的总风险(即总方差 )时,根据我们推导的二次型公式:
这个公式深刻地揭示了投资界那句古老谚语——“不要把所有鸡蛋放在同一个篮子里”——背后的严格数学原理。
公式的第一部分 是各个资产自身方差的加权和。由于权重 是小于1的小数,其平方 会变得更小。这意味着,只要我们分散投资,单只股票的剧烈波动对整体组合的影响就会被极大地稀释。
但真正决定组合风险的,是公式的第二部分:资产之间的协方差项 。 如果我们在组合中加入了大量高度正相关的资产(例如同时买入多只同行业的科技股),它们的协方差 都是正数,这会导致组合的总方差急剧膨胀,风险叠加。 相反,如果我们能够找到负相关的资产(例如在买入股票的同时买入避险的国债或黄金),它们的协方差为负数。这些负的交叉项会抵消掉第一部分的正方差,从而在不降低预期收益的前提下,大幅度降低组合的总风险。
这就是分散化(Diversification)的数学本质:通过利用资产之间不完全正相关的协方差结构,实现风险的内部对冲。
为了直观地展示协方差矩阵在投资组合优化中的威力,我们编写一段Python代码。我们将模拟三只具有不同期望收益、方差和协方差结构的股票。通过随机生成数千种不同的权重分配方案,我们将计算每种方案的组合收益和组合风险。
import numpy as npimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子以保证结果可复现np.random.seed(42)# 假设市场上有 3 只股票:A(科技股), B(消费股), C(公用事业股)# 1. 设定它们的预期年化收益率 E[X]expected_returns = np.array([0.15, 0.10, 0.06])# 2. 设定它们的年化波动率(标准差)sigmavolatilities = np.array([0.25, 0.15, 0.08])# 3. 设定它们之间的相关系数矩阵 R# A和B正相关(0.3),A和C负相关(-0.2),B和C微弱正相关(0.1)correlation_matrix = np.array([ [ 1.0, 0.3, -0.2], [ 0.3, 1.0, 0.1], [-0.2, 0.1, 1.0]])# 4. 根据相关系数和标准差,计算协方差矩阵 Sigma# Cov(X,Y) = corr(X,Y) * sigma_X * sigma_Y# 矩阵形式:Sigma = D * R * D,其中 D 是标准差的对角矩阵D = np.diag(volatilities)covariance_matrix = D @ correlation_matrix @ D# 模拟 10000 种不同的投资组合权重num_portfolios = 10000results = np.zeros((3, num_portfolios)) # 存储收益、风险、夏普比率weights_record = []# 假设无风险利率为 0.02risk_free_rate = 0.02for i in range(num_portfolios):# 随机生成权重,并归一化使其和为 1 weights = np.random.random(3) weights /= np.sum(weights) weights_record.append(weights)# 计算组合预期收益:w^T * E[X] portfolio_return = np.dot(weights, expected_returns)# 计算组合方差:w^T * Sigma * w portfolio_variance = np.dot(weights.T, np.dot(covariance_matrix, weights))# 组合标准差(风险) portfolio_std_dev = np.sqrt(portfolio_variance)# 计算夏普比率 (收益 - 无风险利率) / 风险 sharpe_ratio = (portfolio_return - risk_free_rate) / portfolio_std_dev# 记录结果 results[0,i] = portfolio_return results[1,i] = portfolio_std_dev results[2,i] = sharpe_ratio# 提取数据用于绘图returns = results[0,:]risks = results[1,:]sharpes = results[2,:]# 找到夏普比率最高的组合(最优风险调整收益)max_sharpe_idx = np.argmax(sharpes)max_sharpe_return = returns[max_sharpe_idx]max_sharpe_risk = risks[max_sharpe_idx]best_weights = weights_record[max_sharpe_idx]# 找到风险最小的组合(全局最小方差组合)min_risk_idx = np.argmin(risks)min_risk_return = returns[min_risk_idx]min_risk_risk = risks[min_risk_idx]# 创建图表fig, ax = plt.subplots(figsize=(12, 8))# 绘制所有模拟的投资组合散点,颜色代表夏普比率scatter = ax.scatter(risks, returns, c=sharpes, cmap='viridis', marker='o', s=10, alpha=0.6)cbar = plt.colorbar(scatter, ax=ax)cbar.set_label('夏普比率 (Sharpe Ratio)', fontsize=12)# 标记单只股票的位置stock_labels = ['股票A (高收益高风险)', '股票B (中等)', '股票C (低收益低风险)']colors = ['red', 'orange', 'blue']for i in range(3): ax.scatter(volatilities[i], expected_returns[i], color=colors[i], marker='D', s=100, edgecolor='black', zorder=5) ax.text(volatilities[i] + 0.005, expected_returns[i], stock_labels[i], fontsize=11, fontweight='bold')# 标记最优夏普比率组合ax.scatter(max_sharpe_risk, max_sharpe_return, marker='*', color='gold', s=300, edgecolor='black', zorder=6, label=f'最大夏普组合\n权重: A={best_weights[0]:.2f}, B={best_weights[1]:.2f}, C={best_weights[2]:.2f}')# 标记最小风险组合ax.scatter(min_risk_risk, min_risk_return, marker='X', color='red', s=150, edgecolor='black', zorder=6, label='全局最小风险组合')ax.set_title('马科维茨有效边界:协方差矩阵驱动的风险对冲', fontsize=16, fontweight='bold')ax.set_xlabel('预期风险 (年化标准差 $\sigma$)', fontsize=13)ax.set_ylabel('预期收益 (年化收益率 $E[R]$)', fontsize=13)ax.grid(True, linestyle=':', alpha=0.6)ax.legend(loc='upper left', fontsize=11)plt.tight_layout()plt.show()执行结果如下:
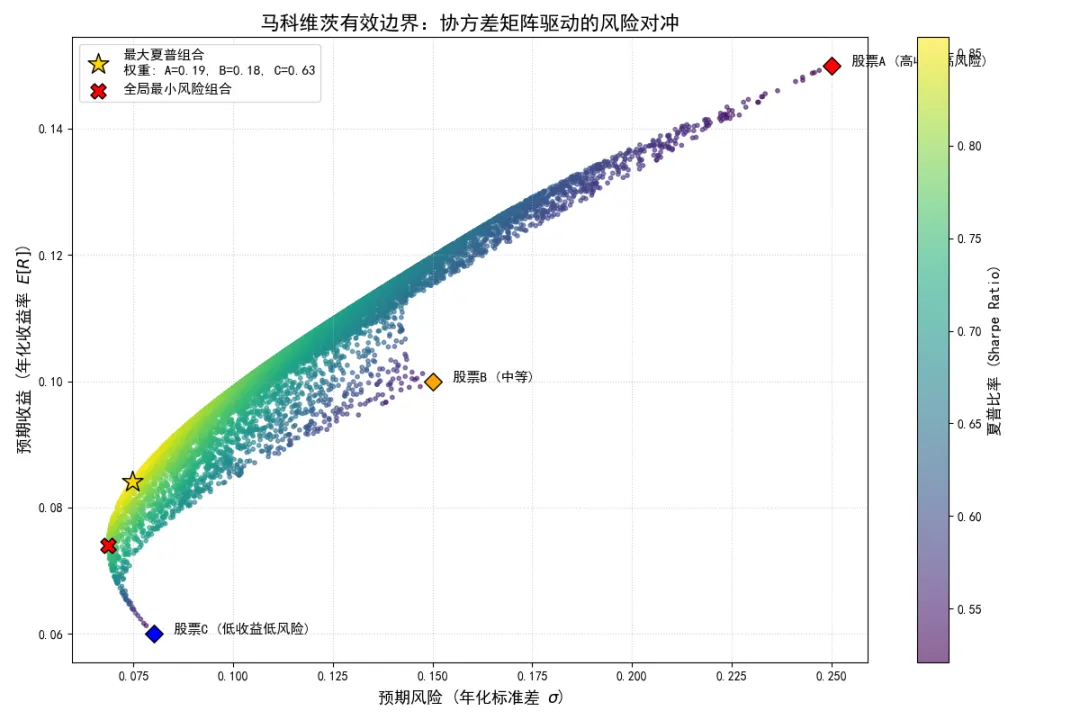
观察图表左侧的边缘,也就是“有效边界”(Efficient Frontier)。你会发现一个极其反直觉的现象:全局最小风险组合(红色的叉号)的风险,竟然低于组合中任何一只单一股票的风险(包括最稳健的股票C)。
这就是协方差矩阵中负相关项(股票A和股票C的负相关)发挥的对冲魔力。通过将资金按特定比例分配给波动剧烈的股票A和极其稳健的股票C,它们在相反方向上的波动相互抵消,使得整个组合的方差被压缩到了单只资产无法企及的极低水平。
同时,最大夏普比率组合(金色的五角星)向我们展示了如何在承担合理风险的前提下,通过优化协方差结构来最大化超额收益。
马科维茨模型完美地诠释了协方差的工程价值:在多维系统中,个体元素的方差并不重要,决定系统整体稳定性的,是元素之间错综复杂的协方差网络。
5协方差的局限性与非线性盲区
尽管协方差在代数性质优美、应用广泛,但作为一种度量随机变量关系的数学工具,它依然存在着根本性的局限。
我们在第1节和第2节中已经反复强调,协方差本质上是去中心化变量在希尔伯特空间中的内积。内积度量的是向量之间的线性投影关系。因此,协方差只能捕捉变量之间的线性依赖(Linear Dependence),对任何形式的非线性依赖都无能为力。
为了从代数上严格证明这一点,我们构造一个经典的非线性模型。假设随机变量 服从区间 上的均匀分布,即 。根据均匀分布的性质,它的期望 。
现在,我们定义变量 为 的绝对值,即 。显然, 和 之间存在着绝对的、确定性的函数关系。只要给定 的值, 的值就唯一确定。它们之间蕴含着极高的互信息,绝不是相互独立的。
我们来计算 和 的协方差。根据定义:
由于 ,后半部分为0,我们只需要计算混合原点矩 :
根据期望的积分定义,由于 在 上均匀分布,其概率密度函数 :
被积函数 是一个奇函数(因为 )。根据微积分基本定理,奇函数在对称区间上的定积分为0。因此:
最终我们得到:
代数推导给出了一个冷酷的结论:尽管 构成了完美的确定性依赖,但它们的协方差严格等于0。
这个数学事实再次警告我们:协方差为0(不相关)绝对不等于相互独立。 协方差的计算过程,本质上是用一条直线去拟合二维平面上的联合概率分布。当分布呈现出某种对称的非线性结构(如抛物线、绝对值折线、圆环)时,直线拟合的斜率为0,正向的偏差和负向的偏差在积分时相互抵消,导致最终的内积为0。
在现代机器学习和深度神经网络中,特征之间往往存在着极其复杂的非线性交互。如果我们仅仅依赖协方差矩阵(或皮尔逊相关系数矩阵)来进行特征选择或降维,将会不可避免地丢弃大量包含极高预测价值的非线性特征。
6协方差的物理直觉
在前一部分中,我们通过马科维茨投资组合理论见证了协方差在金融工程中的巨大威力,同时也从代数上证明了它对非线性关系的视而不见。这暴露出协方差作为一个度量工具,其内在的复杂性和矛盾性,我们进一步从协方差的物理角度,探究其局限性和边界。
我们再次回到协方差的展开式:
这个公式的右侧,实际上是两个期望值的比较。 这一项代表了一个“基准线”或“零假设”。它是在假设 和 相互独立的情况下,我们所期望的乘积的平均值。而 则是现实世界中,在 和 可能存在某种内在联系的情况下,我们实际观测到的乘积的平均值。
因此,协方差 的本质,是度量**“现实的互动”偏离“独立假设”的程度**。我们可以称之为“互动项”(Interaction Term)。
为了将这个抽象的概念具体化,我们构建一个最简单的离散概率模型。假设我们调查一个社区中,居民是否拥有“高学历”(事件 )和是否拥有“高收入”(事件 )。我们用指示函数随机变量来表示: 如果拥有高学历, 否则。 如果拥有高收入, 否则。
此时,,。它们的协方差为:
这个简单的离散形式清晰地揭示了协方差的来源。如果高学历和高收入是两个完全独立的社会现象,那么 ,协方差为0。但现实是,高学历往往会带来高收入,即 ,这就产生了一个正的协方差。
现在,我们将这种离散的直觉,推广到连续的物理系统中。想象有两个通过弹簧连接的摆锤。每个摆锤的位置(偏离中心点的距离)是一个随时间波动的随机变量。
方差 :代表了摆锤 A 自身振动的平均能量或功率。振幅越大,方差越大。 协方差 :代表了连接两个摆锤的弹簧的“耦合效应”。 :这相当于一个普通的拉伸弹簧。当摆锤 A 向右摆动时,弹簧被拉伸,会给摆锤 B 一个向右的拉力,导致它们倾向于同向摆动(In-phase Oscillation)。 :这相当于两个摆锤之间没有弹簧连接。它们的振动是完全解耦的,一个的运动对另一个没有任何预测价值。 :这需要一个更巧妙的机械结构,比如通过一个杠杆连接。当摆锤 A 向右摆动时,杠杆的另一端会推动摆锤 B 向左摆动,导致它们倾向于反向摆动(Anti-phase Oscillation)。
这个物理模型,比单纯的代数公式更能帮助我们理解协方差在系统动力学中的角色。在任何一个由多个相互关联的组件构成的复杂系统中,系统的整体稳定性(总方差)都取决于组件之间协方差的正负号和大小。
7协方差的尺度依赖性
尽管物理直觉非常强大,但协方差作为一个度量单位,存在一个系统性的缺陷:它不是无量纲的,其数值大小会随着变量本身的尺度(方差)而剧烈变化。
我们在上一小节的结尾通过一个简单的例子指出了这一点。现在,我们进行一个更系统、更具说服力的模拟实验。我们将固定三个不同强度的线性相关性(例如,弱、中、强),然后对每一级别的相关性,我们都逐步放大数据的尺度,观察协方差和相关系数的变化。
import numpy as npimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定随机种子np.random.seed(123)# 定义三个级别的相关系数correlations = [0.2, 0.6, 0.95]# 定义三个级别的数据尺度(标准差)scales = [1, 10, 100]# 创建 3x3 的子图网格fig, axes = plt.subplots(3, 3, figsize=(15, 15), sharex='col', sharey='row')fig.suptitle('协方差的尺度依赖性 vs 相关系数的尺度不变性', fontsize=20)for i, r in enumerate(correlations):for j, s in enumerate(scales): ax = axes[i, j]# 构造协方差矩阵# Var(X) = Var(Y) = s^2# Cov(X,Y) = r * s * s cov_matrix = [[s**2, r * s**2], [r * s**2, s**2]]# 生成数据 data = np.random.multivariate_normal([0, 0], cov_matrix, 300) x = data[:, 0] y = data[:, 1]# 计算样本协方差和相关系数 sample_cov = np.cov(x, y)[0, 1] sample_corr = np.corrcoef(x, y)[0, 1]# 绘图 ax.scatter(x, y, alpha=0.6)# 添加文本 text_content = f"Cov = {sample_cov:.1f}\nCorr = {sample_corr:.2f}" ax.text(0.05, 0.95, text_content, transform=ax.transAxes, fontsize=12, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))# 设置坐标轴标签if i == 2: ax.set_xlabel(f'尺度(Std) = {s}', fontsize=12)if j == 0: ax.set_ylabel(f'真实相关性 = {r}', fontsize=12)plt.tight_layout(rect=[0, 0, 1, 0.96])plt.show()执行结果如下:
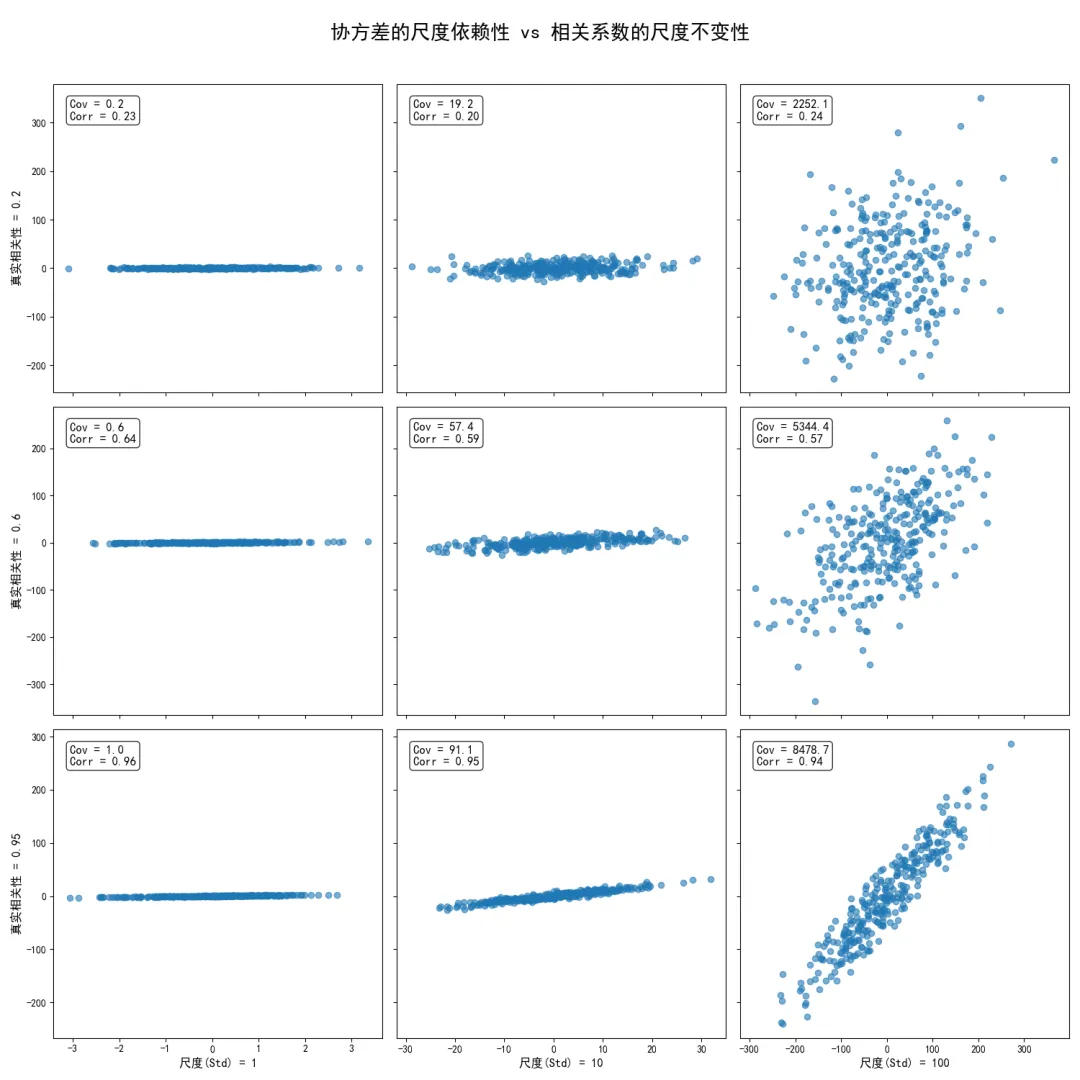
这个 3x3 的图表矩阵提供了无可辩驳的视觉证据。观察每一行:当我们从左到右移动时,散点图的胖瘦程度(即线性关联的紧密程度)是保持不变的。然而,由于数据的尺度(坐标轴范围)被放大了10倍、100倍,协方差的数值也随之爆炸性增长了100倍、10000倍!一个在左上角仅为0.2的协方差,在右下角飙升到了接近9500。观察每一列:当我们从上到下移动时,数据的尺度保持不变,但线性关联度越来越强。协方差和相关系数都在同步增加。对比协方差和相关系数:最关键的发现是,无论尺度如何变化(从左到右),相关系数的值始终稳定地保持在真实设定值附近。在第一行,它始终在0.2左右;在第三行,它始终在0.95左右。
这个实验系统地证明了:
协方差(Covariance)是一个尺度同变(Scale-equivariant)的量。它混合了“关联强度”和“数据幅度”两个信息,使得我们无法仅凭其数值大小来判断关联的纯粹强度。 相关系数(Correlation)是一个尺度不变(Scale-invariant)的量。它通过标准差的归一化,成功地将“数据幅度”的信息剥离,只留下了纯粹的“线性关联强度”。
因此,在任何需要跨数据集、跨变量比较关联强度的场景下,使用协方差都是极其危险的。我们必须转向使用无量纲的相关系数。
8柯西-施瓦茨不等式——协方差的数学边界
为什么相关系数能够被完美地约束在 区间内?这个看似平凡的性质,背后是深刻的数学原理——柯西-施瓦茨不等式(Cauchy-Schwarz Inequality)在概率空间中的体现。
对于任意两个随机变量 和 (假设其方差有限且不为0),柯西-施瓦茨不等式断言:
或者写成平方形式:
这个不等式为协方差的绝对值设定了一个无法逾越的上限,这个上限完全由两个变量自身的标准差乘积所决定。当我们用这个上限去除协方差时,得到的结果(相关系数)的绝对值必然小于等于1。
下面,我们给出一个严谨的、自洽的代数证明。
证明:
令 和 为两个去中心化的随机变量。我们的目标是证明 。
考虑一个新的随机变量 ,它是 和 的线性组合,其中 是一个任意的实数:
根据方差的基本性质,任何随机变量的方差都不能是负数。因此, 必须大于等于0(因为 的期望为0,):
我们将平方项展开,并利用期望的线性性质:
将方差和协方差的定义代入:
这个不等式对于任意实数 都必须成立。这意味着,关于 的这个二次函数 ,其图像必须始终在横轴上方或与横轴相切。
一个二次函数恒大于等于0的充要条件是,它的判别式(Discriminant) 必须小于等于0。 在这个二次函数中,,,。
计算判别式:
证明完成。
这个证明不仅揭示了相关系数边界的来源,还蕴含着深刻的几何意义。我们构造的二次函数 实际上是在寻找一个最优的 ,使得 在 上的投影残差的能量最小。当这个二次函数的判别式为0时,等号成立,这意味着残差的能量为0,即 可以被 完美地线性表示。这恰好对应于相关系数为 的情况。
本节总结
在本节中,我们对协方差的定义与性质进行了全面而深入的剖析。
我们从基础代数性质出发,推导了协方差的对称性、平移不变性、尺度同变性,并证明了协方差算子的双线性。这个核心性质引出了和的方差公式,并将其推广到了多维随机向量的二次型 。
接着,我们将这个纯数学公式应用于马科维茨投资组合理论,通过一个详尽的Python模拟,展示了协方差矩阵如何在金融工程中实现风险的对冲与优化,揭示了“分散化”的数学本质。
然后,我们回归到协方差的局限性。通过代数推导和系统性的可视化实验,我们揭示了协方差对非线性关系的盲区和对数据尺度的敏感性。这强调了在实践中转向使用无量纲的相关系数的必要性。
最后,我们通过严谨证明柯西-施瓦茨不等式,为协方差的绝对值设定了数学上的严格边界,并从根本上解释了皮尔逊相关系数为何被约束在 区间内。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【新书资讯】GeoAI with Python: A Practical Guide to Open-Source Geospatial AI
- 新手如何提高自己的Python编程水平
- Python高手总结的自动化办公知识库!太厉害了
- Python高手总结的自动化办公知识库!太厉害了
- 学习AI第三天:我开始接触 Python 的元组、集合和字典了
- 来自Python扩展包的七伤拳
- 来自Python扩展包的七伤拳
- 【运维资料】Linux云计算运维学习资料合集(Linux初中高级+服务器+运维+监控等)
- 马哥 Linux 架构班完整测评|运维人进阶架构师,这套课到底怎么样?
- 深夜告警炸裂?这份Linux故障排查“作战地图”请收好
