本周有位粉丝反馈PyMe运行和打包时内存占用较大: 在Python开发中,内存占用过高是一个常见问题。当程序处理大量数据或长时间运行时,内存管理不当可能导致程序崩溃或服务器过载。PyMe之前主要精力放在功能研发上,对内存优化关注的不够,IDE需要设计界面和编辑属性的操作非常多,本次问题反馈也让我开始潜心优化,本文也将介绍几种实用的内存优化方法,并通过代码示例说明如何应用。
一、使用生成器代替列表
列表会将所有元素一次性加载到内存中,而生成器按需生成数据,显著降低内存占用。
# 内存密集型:一次性创建1000万个数字的列表numbers = [i for i in range(10000000)] # 占用约320MB内存sum_numbers = sum(numbers)# 内存友好型:使用生成器表达式numbers_gen = (i for i in range(10000000)) # 几乎不占用内存sum_numbers = sum(numbers_gen) # 边生成边求和
二、使用__slots__限制实例属性
Python默认使用字典存储对象属性,每个实例都有一个__dict__,占用额外内存。__slots__可以禁止动态添加属性,将属性存储为固定大小的元组。
示例:
# 传统类:每个实例占用大量内存class Employee: def __init__(self, name, age, salary): self.name = name self.age = age self.salary = salary# 优化后:使用__slots__class EmployeeOptimized: __slots__ = ('name', 'age', 'salary') def __init__(self, name, age, salary): self.name = name self.age = age self.salary = salary# 内存对比:创建100万个实例# 传统类:约200MB# 优化类:约70MB
三、使用array或numpy存储数值数据
Python内置的列表可以存储任意类型,每个元素都是完整的Python对象,开销较大。对于大量同类型数值数据,使用array模块或numpy数组更高效。
示例:
import arrayimport numpy as np# 列表:每个int是Python对象,内存占用大list_data = [i for i in range(1000000)] # 约28MB# array:紧凑存储C类型数据array_data = array.array('i', range(1000000)) # 约4MB# numpy:适合科学计算np_data = np.arange(1000000, dtype=np.int32) # 约4MB
四、及时释放不再使用的对象
Python的垃圾回收机制并非实时,可以通过显式删除引用或使用gc模块主动回收。
示例:
import gcdef process_large_data(): data = load_large_dataset() # 加载大文件 result = compute(data) # 处理完成后及时释放 del data gc.collect() # 主动触发垃圾回收 return result
五、使用weakref避免循环引用
循环引用会导致对象无法被回收,weakref模块可以创建弱引用,不增加引用计数。
示例:
import weakrefclass Node: def __init__(self, value): self.value = value self.parent = None # 使用弱引用避免循环class Tree: def __init__(self): self.root = None def add_child(self, parent, child): child.parent = weakref.ref(parent) # 弱引用父节点
六、按需读取文件而非一次性加载
处理大文件时,逐行或分块读取比read()一次性加载更节省内存。
示例:
# 内存密集型with open('large_file.txt', 'r') as f: content = f.read() # 整个文件加载到内存 lines = content.splitlines()# 内存友好型with open('large_file.txt', 'r') as f: for line in f: # 逐行迭代,每次只加载一行 process(line)
七、使用sys.intern复用字符串
当程序中出现大量重复字符串时,可以手动驻留字符串,让相同内容的字符串共享同一内存地址。
示例:
import sys# 大量重复的字符串tags = []for i in range(100000): # 手动驻留,相同内容的字符串复用内存 tags.append(sys.intern('category_product'))# 内存占用从约5MB降至约0.5MB
PyMe下一版的内存优化技术
PyMe在之前的版本中对内存占用关注较少,下一版本中将逐步通过引入以上技术,帮助开发者更智能地优化工程内存占用:
1. 智能对象池化技术
自动识别频繁创建和销毁的短生命周期对象,通过对象池复用机制,减少内存分配和垃圾回收开销。PyMe将分析代码热点,为高频对象自动生成池化管理代码。
2. 静态内存分析引擎
基于AST(抽象语法树)分析,在编码阶段预测内存峰值。该引擎能够识别潜在的内存泄漏风险、不必要的全局变量以及过大的容器结构,并给出优化建议。
3. 模块和代码行优化
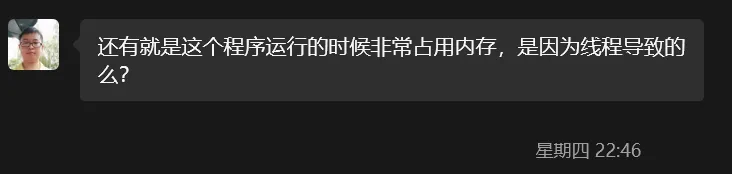
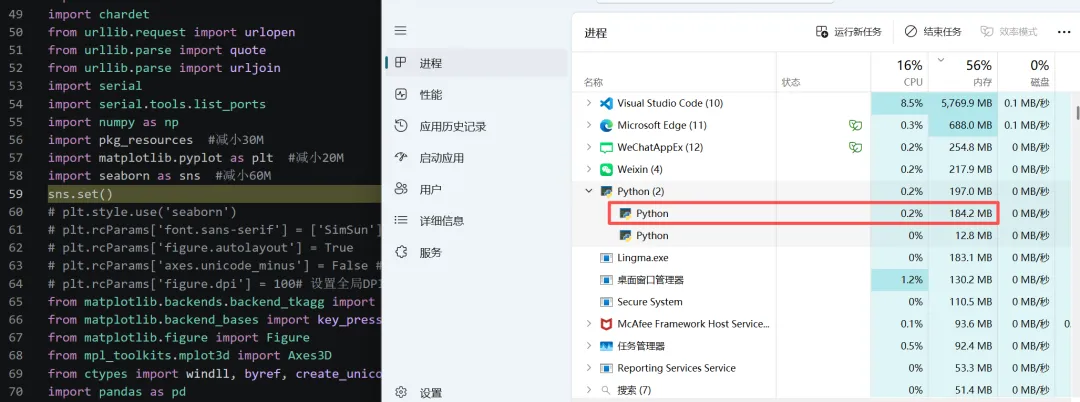
统计所有的模块和代码行,对其进行优化,去除不必要的模块,比如下图中导入的模块,占用了近100M。
注释掉后,内存占用从180M->80M,节省出100M内存。
在部分属性打印和处理的代码区,经过AI分析和优化,目前代码量减少了近万行,也提升了程序的运行速度。
内存优化是一个长期工作。PyMe将持续进行优化以满足用户需要,让内存的使用更加简单高效。让代码飞得更稳!
点击下方链接,下载PyMe,现在就来尝试可视化编程的魅力吧!
[官网地址]:www.py-me.com
[下载链接]:https://pyme.lanzoum.com/iMk423ku0glg
附:如果你在安装或使用中遇到任何问题,欢迎加入PyMe用户群,群里都是和你一样的小白,大家一起交流,一起成长。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
