Linux 调度器深度解析:CFS 完全公平调度,原来如此简单
- 2026-07-04 02:39:01
作者:小康,C/C++编程博主
关键词:CFS、调度器、vruntime、红黑树、nice 值、时间片、进程优先级
前言
每次面试被问"Linux 是怎么决定让哪个进程先跑的",很多人支支吾吾说不清楚。
其实 Linux 的调度器设计思路极其优雅,核心思想用一句话就能说清楚:
让所有进程的"已运行时间"尽可能相等——谁运行最少,谁下一个跑。
这就是 CFS(Completely Fair Scheduler,完全公平调度器),Linux 2.6.23 起成为默认调度器,至今仍是大多数场景的主力。
本篇从"为什么需要 CFS"讲起,顺着原理一路讲到实际调优,让你一次搞懂。
一、旧调度器的问题:什么叫"不公平"?
Linux 2.6.23 之前用的是 O(1) 调度器——名字来自它选下一个进程的时间复杂度是 O(1)。
它的核心思路是:给每个进程一个固定时间片(比如 100ms),按优先级轮流跑。
听起来合理,但有几个根本问题:
问题一:交互进程体验差
一个文本编辑器(交互进程)和一个编译任务(CPU 密集进程)优先级相同,各有 100ms 时间片轮流跑。用户按下键盘,编辑器最多要等 100ms 才响应——明显感觉到卡顿。
问题二:优先级是拍脑袋的"魔法数字"
怎么决定给 nice=-5 的进程分配多少时间片?没有一个优雅的数学公式,都是经验值。优先级数目一多,调整极其复杂。
问题三:CPU 使用率统计不准
O(1) 调度器用启发式算法猜一个进程是"交互型"还是"CPU 密集型",猜错了就会调度错误。
CFS 彻底抛弃了"时间片"这个概念,用一个极其优雅的思路重新设计。
二、CFS 的核心思想:虚拟时钟
CFS 的核心概念叫 vruntime(virtual runtime,虚拟运行时间)。
每个进程都有一个 vruntime 值,表示它"在虚拟时钟里已经跑了多久"。
CFS 的选择规则只有一条:每次都选 vruntime 最小的进程运行。
运行时间越少的进程,vruntime 越小,越优先被选中 进程运行时,vruntime 持续增加 这样,所有进程的 vruntime 会趋于相等——公平!
但只有 vruntime,还不够解释优先级——凭什么 nice=-20 的进程要比 nice=19 的进程跑得更多?
三、nice 值与权重:vruntime 的增速不一样
CFS 用 权重(weight) 来实现优先级差异。
每个 nice 值对应一个权重,nice=0 的权重是 1024(基准值)。nice 每降 1,权重增加约 25%;nice 每升 1,权重减少约 20%。
关键公式:
vruntime 增量 = 实际运行时间 × (nice=0的权重 / 该进程的权重)这意味着:高优先级(低 nice 值)进程的权重大,同样跑了 10ms,它的 vruntime 增加得少——下次被选中的概率更高,实际上获得了更多 CPU 时间。

同样跑了 10ms,高优先级进程(nice=-5)的 vruntime 只增加了 3.3ms,而低优先级进程(nice=+5)的 vruntime 增加了 30.5ms。vruntime 增加越慢,在红黑树里排名越靠左,被选中的频率越高——这就是优先级的本质。
四、红黑树:CFS 的"选人"数据结构
CFS 把所有可运行进程放进一棵红黑树里,以 vruntime 为键排序。
红黑树的最左节点,就是 vruntime 最小的进程——每次调度,直接取最左节点,O(log n) 时间,但内核缓存了最左节点指针,实际是 O(1)。
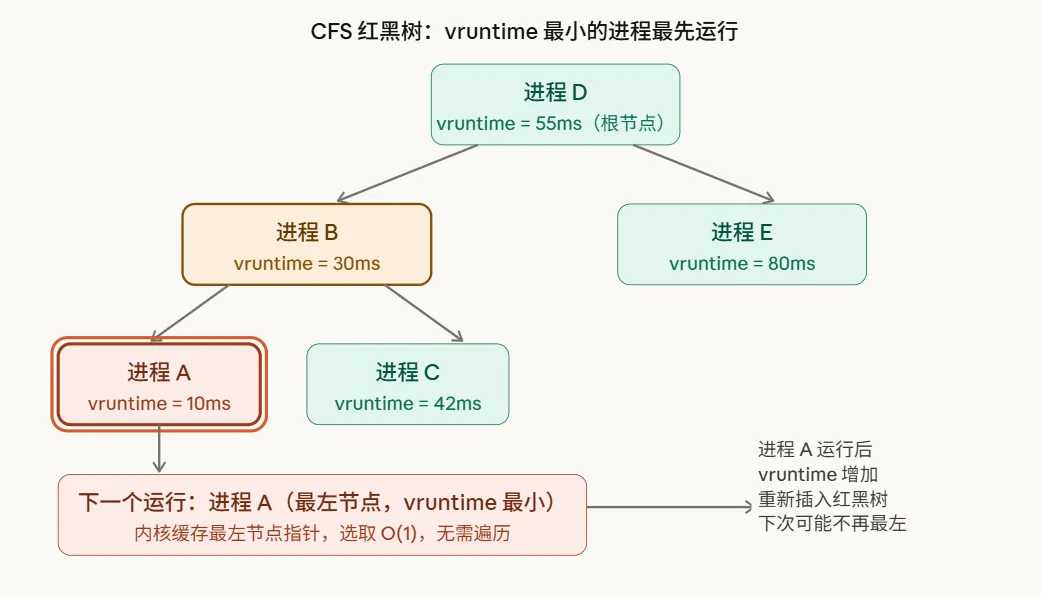
整个 CFS 的调度逻辑可以用三句话概括:
取红黑树最左节点(vruntime 最小的进程)运行 进程运行时,vruntime 不断增加(高权重进程增加慢) vruntime 增加后,进程从红黑树摘出、更新 vruntime、重新插入
这就是"完全公平"的本质——不是所有进程获得绝对相同的时间,而是 vruntime 趋于平衡。
五、调度周期与时间片:CFS 怎么决定一次跑多久?
CFS 没有固定时间片,但有一个调度周期(sched_latency),默认 6ms(低负载)到 48ms(高负载)。
在一个调度周期内,每个进程都会运行一次。每个进程分到的时间 = 调度周期 × (该进程权重 / 所有进程权重之和)。
假设 3 个进程,权重分别为 1024(A)、512(B)、512(C),调度周期 = 6ms:A 的时间 = 6ms × 1024/2048 = 3msB 的时间 = 6ms × 512/2048 = 1.5msC 的时间 = 6ms × 512/2048 = 1.5ms进程数越多,每个进程分到的时间越短。为了避免时间片太短导致频繁切换,CFS 设置了最小时间片(min_granularity),默认 0.75ms,低于这个值就不切换。
六、Linux 完整调度层次:CFS 不是唯一的
CFS 只是 Linux 调度器的一部分。Linux 的调度器是分层的,不同类型的进程走不同的调度器:

实时进程(SCHED_FIFO/SCHED_RR)只要存在,就会抢占所有普通进程,nice 值对它们没有意义。音视频驱动、工业控制等对延迟敏感的场景会用到实时调度。
普通应用程序几乎都跑在 CFS 下,通过 nice 值控制优先级。
七、实战:如何调整进程优先级?
# 启动时设置 nice 值(-20 最高,+19 最低)nice -n -5 ./my_program # nice = -5(需要 root)nice -n 10 ./background_job # nice = +10(普通用户可以调高不能调低)# 修改正在运行的进程renice -n 5 -p 1234 # 把 PID 1234 的 nice 值改为 5# 查看进程的 nice 值和调度策略ps -o pid,ni,cls,comm -p 1234# PID NI CLS COMMAND# 1234 5 TS my_program# TS = SCHED_OTHER(普通 CFS),RR = 实时轮转,FF = 实时先进先出# 设置实时优先级(需要 root)chrt -f 50 ./realtime_task # SCHED_FIFO,优先级 50chrt -r 50 ./realtime_task # SCHED_RR,优先级 50# 查看调度策略chrt -p 1234在 C 代码里直接设置:
#include<sched.h>// 设置实时调度(需要 CAP_SYS_NICE 权限)structsched_paramparam = { .sched_priority = 50 };sched_setscheduler(0, SCHED_FIFO, ¶m);// 普通进程设置 nice 值nice(10); // 降低优先级八、CFS 的边界情况:新进程和睡醒进程怎么处理?
新进程的 vruntime 初始化:
如果新进程从 0 开始计 vruntime,而其他进程 vruntime 已经跑到几百毫秒,新进程会一直抢占 CPU,直到 vruntime 赶上来。这不合理。
实际上,新进程的 vruntime 初始值 = 当前 CPU 运行队列里最小的 vruntime(min_vruntime)。这样新进程从"起跑线"开始,而不是从 0 开始。
睡眠唤醒的进程:
进程睡眠期间不更新 vruntime,醒来后 vruntime 可能远小于其他进程,会一直抢占 CPU。
CFS 的处理:进程唤醒时,将其 vruntime 设置为 max(其原始 vruntime, min_vruntime - sched_latency)——既保证它能获得一些"补偿",又不会让它无限制地占用 CPU。
九、高频面试题精析
Q:CFS 的"完全公平"是什么意思?
不是所有进程获得绝对相同的 CPU 时间,而是"理想中的 CPU 使用时间"——每个进程都精确获得按权重分配的 CPU 份额。实现手段是通过 vruntime 使每个进程的"虚拟运行时间"趋于相等。
Q:nice 值和 priority 有什么区别?
priority(PRI)是调度器内部用的实际优先级,包含 nice 值的影响以及动态调整。用户可以通过 nice(-20 到 +19)影响普通进程的优先级,实际 priority = 20 + nice。实时进程有单独的实时优先级(1-99),不通过 nice 控制。
Q:为什么 Redis 建议降低进程优先级?
Redis 通常不建议使用实时优先级,反而建议不调整优先级(用默认 CFS)。因为实时进程如果陷入死循环或长时间运行,会把所有普通进程饿死,系统无响应。Redis 的高性能主要靠单线程+epoll,不依赖实时调度。
Q:Linux 上怎么让一个程序"独占" CPU?
几种方法:① chrt -f 99 设最高实时优先级(危险);② taskset -c 3 ./prog 绑定到 CPU 3,配合 isolcpus=3 内核参数把 CPU 3 从调度器隔离;③ 容器/cgroup 限制 CPU 分配。
结语
理解了 CFS,三个核心点牢记:
vruntime(虚拟运行时间)—— 公平性的度量标准红黑树(最左节点) —— O(1) 选出下一个进程weight(权重) —— 通过 nice 值决定 vruntime 增速三者组合,就是 Linux 每秒钟在数百个进程之间精确分配 CPU 时间的秘密。
这也解释了为什么服务器上 100 个进程同时跑,没有一个进程会被彻底饿死——CFS 保证了每个进程都能获得至少一点 CPU 时间,同时让高优先级进程获得更多份额。
原创不易!觉得有收获,点赞、推荐、转发 支持下哦~ 🙏
📌 还在打基础?从这里出发
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急——三门入门课程帮你打好地基:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
🚀 基础扎实了?来做工业级项目
如果你已经有一定基础,想冲击更高的天花板,这些工业级 C++ 项目正是为你准备的:
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
另外,最近还开放了一个新的 C++ 项目实战课程:参考 LevelDB 实现的 LSM 存储项目 StoneDB,涵盖 MemTable / SSTable、WAL 日志、Compaction、多级存储等核心机制,完整还原 KV 存储引擎设计。感兴趣的朋友可以看看 👉 课程详情:手写 C++ LSM存储引擎:MemTable、SSTable、Compaction 全流程实现


