在前面两篇推文中,我们系统梳理了脑电(EEG)数据从原始读取到条件平均的整体流程,并对两种分析工具在操作思路、数据结构和批处理策略上的差异进行了比较。
作为EEG数据处理工作的继续,本篇推文将重点介绍如何对不同实验条件的多被试脑电数据进行统计分析以及可视化输出,包括兴趣区(Region of Interest,ROI)t检验、时间点对点重复测量方差分析(Point-by-point repeated-measures ANOVA)。
通过结合EEGLAB与MNE-Python的实际操作示例,我们不仅比较了如何在不同工具上实现统计推断,还突出了结果解释与科研规范的重要性,为EEG数据分析提供从“批量处理”到“研究结论”的完整思路。
兴趣区(Region of Interest t-test,ROI) t 检验是一种常用的 EEG/MEG 数据分析方法,用于比较不同实验条件在特定脑区和时间窗内的信号差异。通过预先选定感兴趣的电极或ROI(需要注意的是,感兴趣电极的选择基于既往研究或理论假设预先确定,以避免数据驱动选择带来的统计偏倚),研究者可以在被试水平上提取平均信号,并基于配对或独立样本 t 检验评估条件间差异的显著性。该方法能够简化数据维度,通过预先限定分析范围来规避在全通道、全时间点上进行大量统计比较所带来的多重比较问题,从而显著提高统计检验的敏感性,并能更聚焦于与研究假设核心相关的神经活动模式。
在完成多被试数据的批量读取、条件平均以及ROI信号提取之后,下一步需要对不同实验条件之间的差异进行统计检验。无论是在EEGLAB还是MNE-Python中,这一过程的核心思路是一致的:先在被试水平上提取感兴趣电极与时间窗内的脑电信号,并计算其平均振幅(mean amplitude),随后基于这些指标开展组水平统计分析。以配对样本 t 检验为例,可以比较同一批被试在不同条件(如L1与L4)下的脑电响应差异,从而判断不同实验条件操控是否产生显著效应。
下面代码基于已整理好的四维EEG数据(被试 × 条件 × 通道 × 时间点),对特定感兴趣脑区和时间窗内的脑电活动进行统计分析:
根据研究假设预先确定的电极(C1、Cz、C2)对应通道索引。
在设定的时间范围(200–300ms)内提取时间点索引。
对每个被试在L1和L4条件下的ROI信号在通道和时间两个维度上进行平均,从而得到每个被试在各条件下的平均振幅。
采用配对样本 t 检验比较L4与L1条件之间的差异,并输出相应的 t 值和 p 值,用于评估这组电极在该时间窗内的平均 ERP 是否存在显著差异。
%% ===== 1. 找ROI电极索引 =====roi_labels = {'C1','Cz','C2'};roi_idx = [];for i = 1:length(roi_labels) for ch = 1:length(EEG.chanlocs) if strcmp(EEG.chanlocs(ch).labels, roi_labels{i}) roi_idx(end+1) = ch; end endend%% ===== 2. 找时间窗索引(200–300 ms)=====time = EEG.times; % mst_start = 200;t_end = 300;time_idx = find(time >= t_start & time <= t_end);%% ===== 3. 提取每个被试的ROI平均值 =====% L1 = 条件1,L4 = 条件4L1_vals = squeeze(mean(mean(data(:,1,roi_idx,time_idx),3),4));L4_vals = squeeze(mean(mean(data(:,4,roi_idx,time_idx),3),4));%% ===== 4. 配对t检验 =====[h, p, ci, stats] = ttest(L4_vals, L1_vals);%% ===== 5. 输出结果 =====fprintf('Paired t-test results (L4 vs L1):\n');fprintf('t = %.3f, p = %.5f\n', stats.tstat, p);
配对样本 t 检验结果显示,在所选ROI(C1、Cz、C2)及N2时间窗口(200–300ms)内,L4条件与L1条件之间存在显著差异(t(9) = -4.715, p = 0.001)。结果表明,两种条件在该时间窗内的ERP振幅存在显著差异,从波幅方向来看,L4条件的平均振幅低于L1条件。
下面代码基于MNE-Python对多被试EEG数据进行ROI水平的统计分析:
从每个被试在不同条件(如L1和L4)下的Evoked数据中提取感兴趣电极(C1、Cz、C2)的信号。
在预设时间窗口(如N2时段200–300ms)内进行平均,从而得到每个被试在该条件下的单一代表值。
构建每个条件对应的被试数据向量,并采用配对样本 t 检验对L4与L1条件进行比较,以评估两种实验条件在该时间窗和电极区域上的脑电响应差异。
########## 提取 ROI 平均波形(每个被试)############import numpy as np# 提取 ROI + 时间窗平均(例如 N2: 200–300 ms)tmin, tmax = 0.2, 0.3def extract_roi_mean(evokeds, roi, tmin, tmax): #定义函数提取ROI均值 values = [] for evk in evokeds: # 找通道索引 picks = mne.pick_channels(evk.ch_names, roi) # 找时间索引 time_mask = (evk.times >= tmin) & (evk.times <= tmax) # ROI + 时间平均 val = evk.data[picks][:, time_mask].mean() values.append(val) return np.array(values)######### 调用函数得到 L1 vs L4 数据 #############L1_vals = extract_roi_mean(all_evokeds['L1'], roi, tmin, tmax)L4_vals = extract_roi_mean(all_evokeds['L4'], roi, tmin, tmax)######### 配对 t 检验 ##########from scipy.stats import ttest_relt, p = ttest_rel(L4_vals, L1_vals)print(f't = {t:.3f}, p = {p:.5f}')
以上输出结果为 t(9)= -4.715, p = 0.001,与EEGLAB部分代码运行结果完全一致。总体来看,EEGLAB与MNE-Python在 t 检验等统计分析中的数学原理完全一致,其差异主要体现在数据组织形式与实现方式上。EEGLAB通常基于多维数组(被试 × 条件 × 通道 × 时间)进行索引与计算,强调矩阵运算的直观性;而MNE-Python则依托对象化数据结构(如Evoked对象及其字典、列表组合),结合NumPy和自定义函数来组织、处理和分析数据,使流程更加模块化、灵活且易于批量化操作。理解这种 “数组驱动” 与 “对象封装” 之间的对应关系,有助于研究者在两种工具之间进行方法迁移与结果验证,从而在保证分析严谨性的同时,提高EEG数据处理的效率与可重复性。
时间点对点重复测量方差分析(Point-by-point repeated-measures ANOVA)是EEG/ERP数据分析中常用的一种精细化统计方法,用于评估不同实验条件随时间变化的动态效应。与仅针对特定时间窗进行统计不同,该方法在每一个时间点上分别进行重复测量ANOVA,从而系统考察条件间差异在整个时间序列中的变化过程。由于在数百个时间点上分别进行统计检验会带来严重的多重比较问题,必须加以校正。其中,False Discovery Rate(FDR)校正通过控制显著结果中假阳性的期望比例,在保证统计效能的同时降低错误发现率。相比于控制族错误率(FWER)的方法(如 Bonferroni 校正),FDR方法相对灵活,在EEG等高维数据分析中具有较好的敏感性。因此,FDR方法在EEG等高维数据分析中具有良好的实用性,能够在控制假阳性的同时避免过度保守,从而提高对时间序列中潜在效应的检出敏感性。
% 注意:以下使用的 anova_rm 函数需要自定义,或来自第三方工具箱。for i=1:size(data,4) % 对每个时间点 i 进行重复测量 ANOVA % data(:,:,13,i) 表示选择所有被试 × 所有条件 × Cz 通道 × 当前时间点 [p, table] = anova_rm(squeeze(data(:,:,13,i)),'off'); % 保存当前时间点的 p 值 P(i) = p(1); % 保存当前时间点的 F 值 F(i) = table{2,5};end% 对所有时间点的 p 值进行 FDR 校正,控制多重比较错误率[p_fdr, p_masked] = fdr(P, 0.05);% 绘图figure;% 绘制四种条件在 Cz 的平均 ERP 波形subplot(211); hold on;set(gca,'YDir','reverse'); % 翻转 Y 轴,使负向电位向上axis([-500 1000 -35 25]); % 设置坐标轴范围plot(EEG.times, squeeze(mean(data(:,1,13,:),1)),'-b'); % L1plot(EEG.times, squeeze(mean(data(:,2,13,:),1)),'-g'); % L2plot(EEG.times, squeeze(mean(data(:,3,13,:),1)),'-k'); % L3plot(EEG.times, squeeze(mean(data(:,4,13,:),1)),'-r'); % L4legend('L1','L2','L3','L4'); title('四种条件组平均波形');% 绘制每个时间点的 ANOVA p 值,并标出 FDR 校正阈值subplot(212); plot(EEG.times, P); axis([-500 1000 0 0.05]); % p 值坐标范围line([-500 1000],[p_fdr p_fdr],'color',[1 0 0]); % 绘制 FDR 校正后的显著阈值红线
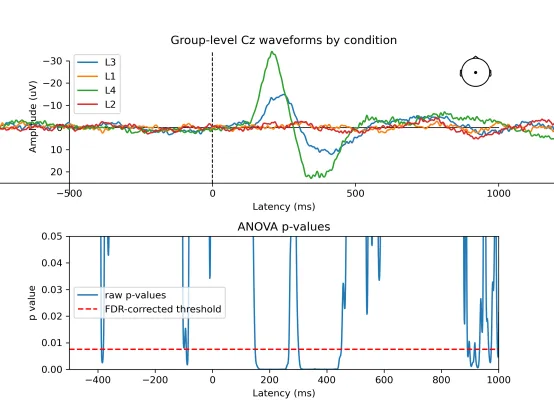
图一:Cz 电极四种条件ERP 波形及时间点重复测量ANOVA 结果(FDR 校正)
图中上半部分显示了Cz通道在四种条件下的平均ERP波形。可以观察到在刺激后约200–300ms出现明显的负波(N2 成分),在300–500ms出现明显的正波(P3成分),其中L4条件的波幅变化最为突出。下半部分则显示了每个时间点的重复测量ANOVA p 值,并标出了FDR校正后的显著性阈值(红线)。结果表明,在N2 和P3时间窗内的部分时间点 p 值低于FDR校正阈值,说明不同条件在这些时间窗内存在统计显著差异。
通过MNE-Python也完全可以实现上述目的,下面的代码首先利用NumPy将多被试、多条件的脑电数据整理为 subj × cond × time 的三维数组,然后在每一个时间点上借助Pandas构建长格式数据表(包含被试、条件和数值),并调用重复测量方差分析逐点计算 F 值和 p 值,随后通过FDR方法进行多重比较校正;最后使用Matplotlib绘制Cz通道的多条件ERP波形及对应的 p 值时间序列,并通过设置dpi=300导出为高分辨率TIFF图像,适用于论文级展示。整体流程充分体现了Python生态系统在科学计算中的丰富与强大:从高效的数据结构处理、灵活的统计建模到高质量可视化输出,各环节无缝衔接,显著提升了脑电数据分析的效率与可复现性。
from statsmodels.stats.anova import AnovaRMfrom statsmodels.stats.multitest import fdrcorrectionimport pandas as pd# ===============================# Cz通道# ===============================cz = all_evokeds[conds[0]][0].ch_names.index('Cz')times = all_evokeds[conds[0]][0].times * 1000n_times = len(times)n_subj = len(subjects)n_cond = len(conds)# ===============================# 构建 data: subj × cond × time# ===============================data = np.zeros((n_subj, n_cond, n_times))for ci, cond in enumerate(conds): for si, evk in enumerate(all_evokeds[cond]): data[si, ci, :] = evk.data[cz]# ===============================# 逐时间点重复测量ANOVA# ===============================P = np.zeros(n_times)F = np.zeros(n_times)for t in range(n_times): df = pd.DataFrame({ # 借助Pandas构建长格式数据表 'subject': np.repeat(np.arange(n_subj), n_cond), 'condition': np.tile(conds, n_subj), 'value': data[:,:,t].flatten() }) aov = AnovaRM(df, 'value', 'subject', within=['condition']).fit() F[t] = aov.anova_table['F Value'][0] P[t] = aov.anova_table['Pr > F'][0]# ===============================# FDR校正# ===============================reject, p_fdr = fdrcorrection(P, alpha=0.05)threshold = np.max(P[reject])print(threshold)import matplotlib.pyplot as pltfig = plt.figure(figsize=(8,6))# -------- 上半图:四条件ERP --------ax1 = plt.subplot(211)mne.viz.plot_compare_evokeds( all_evokeds, # 各条件的Evoked列表(自动计算组平均) picks=['Cz'], # 只绘制Cz通道 ci=False, # 不显示置信区间 invert_y=True, # ERP传统:负电位朝上 time_unit='ms', # 时间单位显示为毫秒 axes=ax1, # 指定绘图坐标轴 show=False)ax1.set_xlim([-500,1000])ax1.set_ylim([25,-35]) # ERP显示范围ax1.set_title('Group-level Cz waveforms by condition')ax1.set_xlabel('Latency (ms)')ax1.set_ylabel('Amplitude (uV)')# -------- 下半图:p值曲线 --------ax2 = plt.subplot(212)ax2.plot(times, P, label='raw p-values')ax2.axhline(y=threshold, color='red', linestyle='--', label='FDR-corrected threshold') # FDR阈值ax2.set_xlim([-500,1000])ax2.set_ylim([0,0.05])ax2.set_title('ANOVA p-values')ax2.set_xlabel('Latency (ms)')ax2.set_ylabel('p value')ax2.legend()plt.subplots_adjust(hspace=0.4) # hspace 增大,避免上下图重叠plt.savefig(r'D:\eeg\weicg\test_data2\Cz_ERP_anova.tiff', dpi=300)plt.show()
图二:MNE-Python绘出的Cz 电极四种条件ERP 波形及时间点重复测量ANOVA 结果(FDR 校正)
在统计方法方面,ROI t 检验与时间点对点重复测量ANOVA分别代表了ERP统计分析中 “降维聚焦” 与 “逐点刻画” 两种不同但互补的分析路径。前者通过在空间与时间上进行先验约束,有助于提升统计效能与结果稳定性,适用于明确假设驱动的研究;后者则以时间序列为核心展开逐点检验,更强调对神经动态过程的精细解析,能够揭示传统时间窗方法可能忽略的瞬时效应。相较于以往仅依赖固定时间窗或单一统计策略的分析框架,这两种方法在分析粒度、假设依赖程度以及对多重比较问题的处理上提供了更具层次性的选择。
在具体实现层面,EEGLAB更强调统一的EEG结构体为核心的操作连贯性,使得从单被试结果到群体统计的过渡更加直接,适合在既定分析范式下快速完成统计验证;而MNE-Python则在时间维度建模与统计流程组织上表现出更强的扩展性,能够将逐点分析、多重比较校正以及可视化结果整合到统一框架中进行系统表达。这种差异不仅体现在工具使用方式上,更反映为对 “分析透明性” 与 “流程组织方式” 的不同侧重:前者路径清晰、上手直观,后者在脚本化分析和流程封装上结构严谨、易于扩展,从而为不同研究需求提供了更具针对性的技术选择。
需要进一步指出的是,在进入统计分析阶段后,MNE-Python虽然以Evoked等对象结构作为主要数据载体,但具体的统计计算通常需要从对象中提取底层数值数据(如NumPy数组),并在标准化的数据维度(如 “被试 × 条件 × 通道 × 时间”)上开展。这一点在计算本质上与EEGLAB基于MATLAB矩阵进行统计分析是一致的,即二者最终都回归到多维数组的数值运算框架之上。不同之处在于,MNE-Python通过对象封装对数据来源、处理历史及维度信息进行统一管理,使 “数据提取 — 统计建模 — 结果表达” 之间的衔接更加规范、可追踪,也更便于扩展到复杂分析(如逐时间点检验或簇级统计);而EEGLAB则更直接地在矩阵层面展开操作,虽然逻辑清晰、上手直观,但在涉及多步骤统计流程时,往往需要研究者自行组织数据结构与分析步骤之间的对应关系。从这一角度来看,两者在统计计算本质上并无差异,但在数据管理方式与流程整合程度上体现出不同取向,这提示在实际研究中可尝试结合两者优势。例如,借助EEGLAB的交互界面进行数据浏览与预处理质量控制,再导出数据至MNE-Python完成灵活的统计建模与可视化——从而在保证分析严谨性的同时,提高处理效率与流程透明度。
特别感谢胡理研究员提供的实验数据、EEGLAB处理代码以及专业指导。
(文中内容为作者个人观点,仅供参考)




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
