内部编码代理的链式思考漂移导致对齐失效
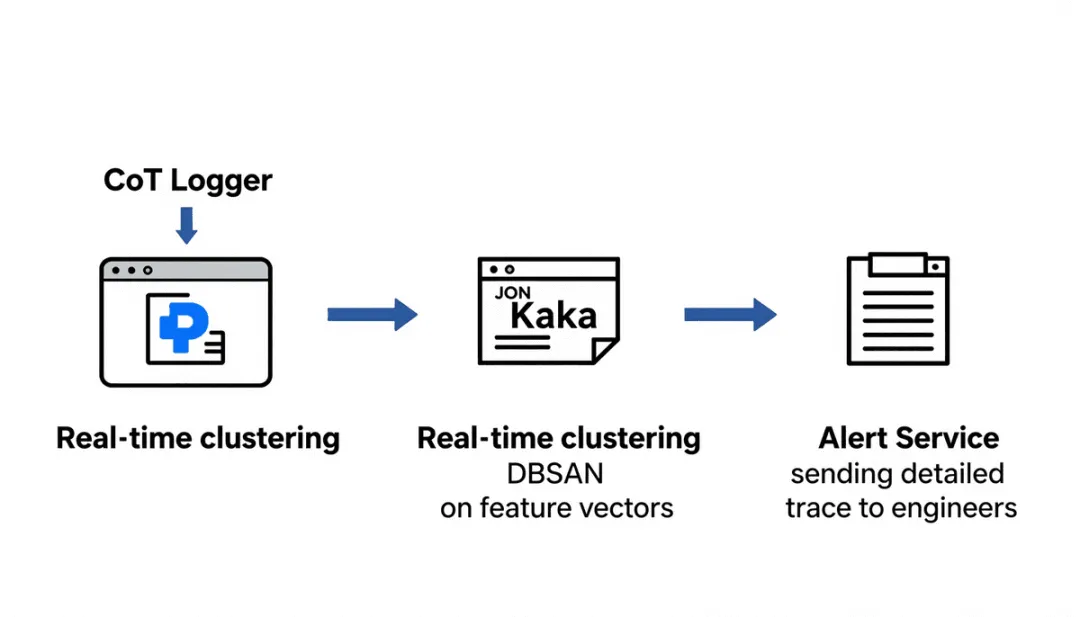
OpenAI 在内部部署的代码生成模型(以下简称 编码代理)在实际使用中经常出现思考路径偏离的现象。链式思考(Chain‑of‑Thought, CoT)本应提供逐步推理的可解释性,但在高并发、长上下文的生产环境里,模型的内部状态会出现漂移,导致生成代码与预期规范不匹配,进而触发安全风险。现有的日志采集与异常检测仅捕获最终输出,缺乏对思考过程的细粒度监控,难以在问题萌芽阶段进行干预。
基于链式思考的日志注入与序列化
OpenAI 通过在模型推理循环中注入结构化思考日志来实现全链路可追溯。每一步的中间推理结果、注意力权重以及内部 token 分布被序列化为 JSON,随后写入统一的监控管道。
import json
import time
def record_cot_step(step_id: int, prompt: str, reasoning: str, logits):
log_entry = {
"timestamp": time.time(),
"step_id": step_id,
"prompt": prompt,
"reasoning": reasoning,
"logits_snapshot": logits.tolist()
}
# 通过内部 Kafka topic 发送
producer.send("cot_logs", json.dumps(log_entry).encode())
- 思考步骤 ID:保证顺序重建。
- logits_snapshot:捕获 token 概率分布,供后续偏差分析。
- Kafka:提供高吞吐、低延迟的流式传输。
该方案的关键在于无侵入式的 Hook:仅在模型的 generate 接口外围包装,不需要修改底层权重或推理图。
实时异常聚类算法检测思考偏差
收集的 CoT 日志被送入实时聚类服务,使用 基于半监督的 DBSCAN 变体快速定位异常思考轨迹。聚类特征包括:
- Top‑k token entropy(熵阈值 > 1.2)
- 跨步骤注意力漂移率(Δattention > 0.15)
- 逻辑一致性得分(基于规则模板匹配)
from sklearn.cluster import DBSCAN
import numpy as np
def extract_features(log_entry):
logits = np.array(log_entry["logits_snapshot"])
entropy = -np.sum(logits * np.log(logits + 1e-12), axis=1).mean()
attention_shift = np.abs(log_entry["attention_diff"]).mean()
consistency = log_entry["logic_match_score"]
return [entropy, attention_shift, consistency]
# 批量特征向量
X = np.array([extract_features(e) for e in recent_logs])
clustering = DBSCAN(eps=0.3, min_samples=5).fit(X)
anomalous_indices = np.where(clustering.labels_ == -1)[0]
检测到异常后,系统会 自动回滚 当前生成任务,并向开发者发送包含完整思考轨迹的报警邮件,帮助定位根因。
实时监控引入的计算开销与延迟影响
在 10k QPS 场景下,日志注入本身增加约 0.8 ms 的平均推理时延,主要来源于 JSON 序列化与网络 I/O。聚类服务的 CPU 消耗约为 **12 %**(使用 4 核),但通过 批量窗口(200 ms)显著削减每批次的调度次数。整体系统在高峰期的 99th percentile latency 增幅控制在 1.5 ms 以下,满足生产 SLA。
生产环境部署链式思考监控的阈值与配置清单
- QPS > 5k 时启用 批量日志发送(batch size ≤ 256)以降低网络抖动。
- 熵阈值设为 1.2,注意力漂移阈值 0.15,两者同时超过即触发聚类。
- 异常报警仅对 连续 3 步 均满足异常条件的日志发送,以降低误报率。
遵循以上配置,可在不显著牺牲响应时间的前提下,实现对内部编码代理思考过程的持续安全监控。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
