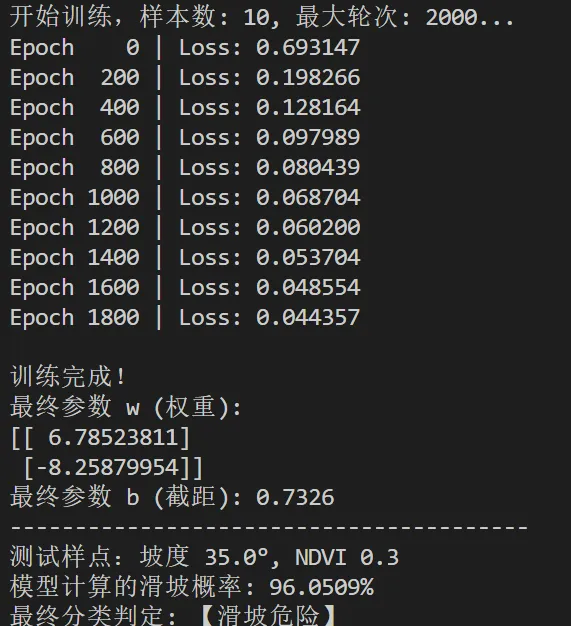
import numpy as npimport pandas as pd#第一阶段:训练阶段#1. 从 CSV 读取数据df = pd.read_csv('逻辑回归.csv')#提取特征(X)和标签(y)X = df[['Slope', 'NDVI']].values # 矩阵形式 [n_samples, 2]y = df['Landslide'].values.reshape(-1, 1) # 变成列向量 [n_samples, 1]# 2. 数据归一化 (Min-Max) 得到每一列的最大值和最小值X_min = X.min(axis=0)X_max = X.max(axis=0)X_norm = (X - X_min) / (X_max - X_min) #得到标准化后的值# 3. 参数初始化n_samples, n_features = X.shapew = np.zeros((n_features, 1)) # 唯一的全局权重[2, 1]b = 0 # 唯一的全局偏置lr = 0.2 # 学习率epochs = 500 # 最大轮次Epochsdef sigmoid(z): return 1 / (1 + np.exp(-z))print(f"开始训练,样本数: {n_samples}, 最大轮次: {epochs}...")# 迭代循环,这个每迭代一次用的是全量样本for i in range(epochs): #A.前向传播:计算预测概率P z = np.dot(X_norm, w) + b #一次性计算出所有样本的wi*xi p = sigmoid(z) #B.计算总损失Loss (交叉熵) #这一步是为了监控模型是否在进步 loss = -np.mean(y * np.log(p + 1e-9) + (1 - y) * np.log(1 - p + 1e-9)) #C.计算梯度 (基于损失函数求导) error = p - y dw = np.dot(X_norm.T, error) / n_samples # 汇总所有样本对w的改进 db = np.sum(error) / n_samples # 汇总所有样本对b的改进 #D.参数更新 (朝着损失减小的方向迈步) w = w - lr * dw b = b - lr * db #每200轮打印一次进度 if i % 200 == 0: print(f"Epoch {i:4d} | Loss: {loss:.6f}")print("\n训练完成!")print(f"最终参数 w (权重): \n{w}")print(f"最终参数 b (截距): {b:.4f}")#第二阶段:预测阶段def predict_landslide(slope_val, ndvi_val): """ 输入原始特征值,输出滑坡概率 """ # 1. 对新样点进行同样的归一化 new_x = np.array([[slope_val, ndvi_val]]) new_x_norm = (new_x - X_min) / (X_max - X_min) # 2. 代入学好的公式 (不再计算Loss和梯度) z_pred = np.dot(new_x_norm, w) + b prob = sigmoid(z_pred)[0][0] return prob# 预测test_slope = 35.0test_ndvi = 0.3probability = predict_landslide(test_slope, test_ndvi)print("-" * 40)print(f"测试样点:坡度 {test_slope}°, NDVI {test_ndvi}")print(f"模型计算的滑坡概率: {probability:.4%}")print(f"最终分类判定: {'【滑坡危险】'if probability > 0.5else'【区域安全】'}")
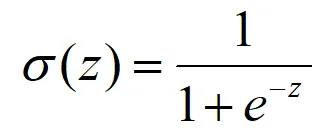
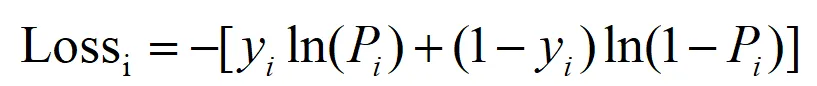
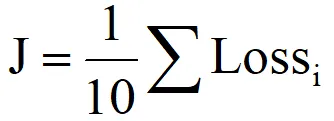
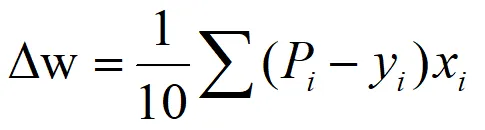
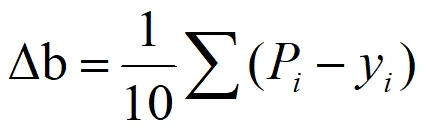
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
