PHP做ML的“正确姿势”正在从“在PHP里算”转向“用PHP编排”——把数值计算与推理下沉到C/Rust/GPU与通用推理运行时,PHP负责业务集成、可观测与工程化交付。很多讨论会把注意力放在“PHP能不能写算法”。但真正的转折点更朴素也更残酷——PHP的数组与内存模型并不适合稳定的数值计算吞吐。你可以把它跑起来,却很难把它跑稳、跑快、跑可控。于是生态自然走向“把计算外包给更合适的存储与执行层”,PHP逐步退回到编排与交付的位置。这不是性能微调,而是架构迁移。
下面换个角度,从团队最关心的三件事出发来组织判断——要不要做、怎么分层、怎么验收。
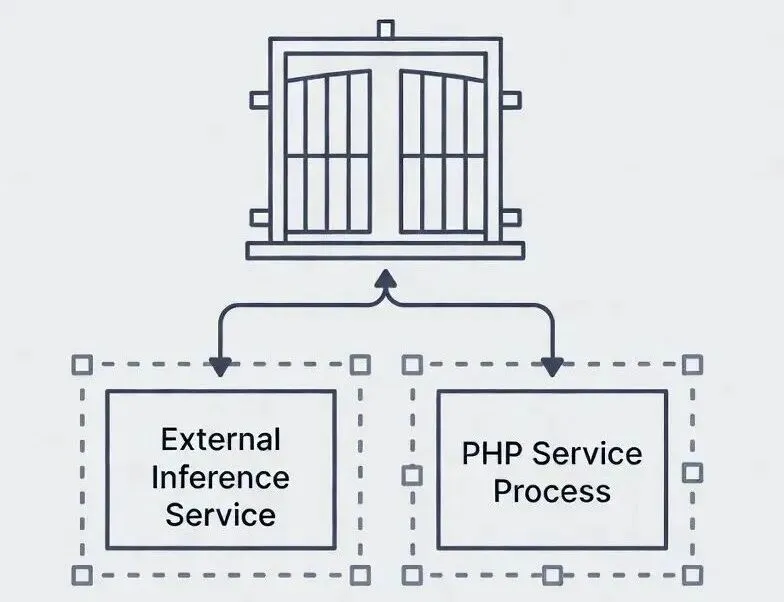
你真的应该把ML塞进PHP服务进程吗
先不要从“能不能集成”出发,而从SLO与边界条件出发做决策。你可以把下面这棵树当成一次技术评审的开场白。
- 否 → 优先外部推理服务,PHP只做请求聚合与结果处理
- 数据是否在PHP侧闭环(输入强依赖业务上下文、特征就在同一请求里)
- 否 → 外部推理服务更合适,避免把数据搬进PHP进程
- 是否允许引入原生依赖(扩展、FFI、或外部运行时)
- 否 → 现实结论是很难做“真正ML”,会被解释器与数组模型卡死
- 否 → 走CPU推理也可以,但仍建议通用推理引擎或原生后端
- 是 → 直接按“运行时 + 执行提供器”设计,不要把它当成PHP里的优化
如果以上任一关键问题的答案是“不”,就别硬把推理塞进PHP进程,外部推理服务往往更便宜、更可控。若答案多为“是”,再进入下一步,选择路线并写清SLO,比如p95延迟、目标吞吐、最大内存占用、降级策略。
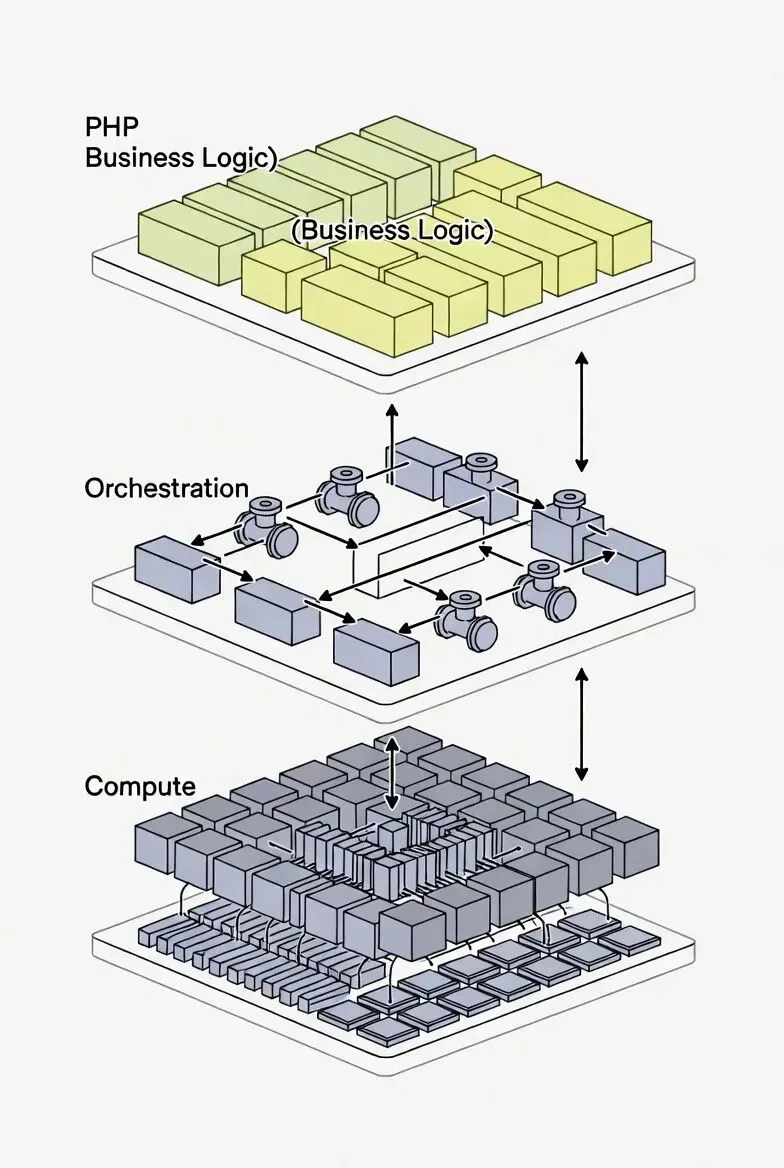
该把PHP放在哪一层才不容易后悔
把系统拆成三层,会让选型与风险暴露得更早。你不需要纠结某个库“够不够强”,而是要明确它属于哪一层、替换成本是什么。
业务层(PHP代码与框架)
- CLI Worker或Swoole/ReactPHP常驻进程
编排层(数据管道、特征处理、调用控制)
- 轻量特征处理放在PHP里做,但要把“数组式矩阵运算”当成禁区
- 把批处理、分片、缓存、重试、熔断、限流放在这里实现
- 一旦特征处理开始用PHP数组模拟向量/矩阵,吞吐与内存会不可预测
- 需要明确批大小、超时、并发上限,否则推理端再快也会被调用方式拖垮
计算层(原生扩展、通用推理引擎、本地推理后端、GPU)
- C/Rust扩展或FFI绑定,用连续内存结构承载Tensor/NDArray类数据
- ONNX Runtime一类通用推理引擎,通过C API共享同一套执行与硬件加速能力
- llama.cpp等成熟C/C++本地推理后端,用于把本地推理门槛压低
- GPU执行提供器作为计算引擎的一部分,而不是“给PHP提速的开关”
- 安装与升级从“composer问题”变成“系统依赖与ABI问题”
- 连续内存结构带来吞吐稳定性,但也引入数据拷贝边界,需要压测验证
这里有一个关键判断点——从“PHP数组矩阵”走向Tensor/NDArray,本质是把数据从hash table式容器迁移到更接近连续内存的布局,换取SIMD/GPU友好性与更稳定的吞吐。你不必在PHP里重造算子,但必须承认数据结构决定了上限。
选ONNX Runtime、llama.cpp还是自写扩展时,代价分别是什么
不要按“功能多寡”选,按你要解决的工程问题选。
当你需要跨语言一致的推理行为、并且希望CPU/GPU切换成本低
- 工程收益是语言层只要能绑定C API,就能共享同一套执行与加速路径
- 运维代价是运行时依赖更重,执行提供器(CPU/GPU)选择要进发布流程
当你更看重本地推理的落地门槛、模型偏轻量或你愿意接受特定后端的约束
- 工程收益是“能用的推理引擎”现成可接,不必在PHP里复刻核心算子
- 运维代价是你要处理线程数、上下文缓存、常驻进程内存水位等细节
当你的瓶颈并不在模型推理,而在特征计算、向量化、数据搬运
- 工程收益是把“不可控的数组计算”替换成可预测的连续内存计算
- 运维代价是构建链与调试成本上升,并且要把崩溃隔离纳入设计
另外一个生态信号也值得留意——当高层API开始稳定(例如transformers风格的调用方式),推理细节会被隐藏到原生后端或运行时里,开发者更多写业务逻辑与数据管道。这对PHP尤其重要,因为它把你的关注点从“怎么实现推理”拉回到“怎么交付推理”。
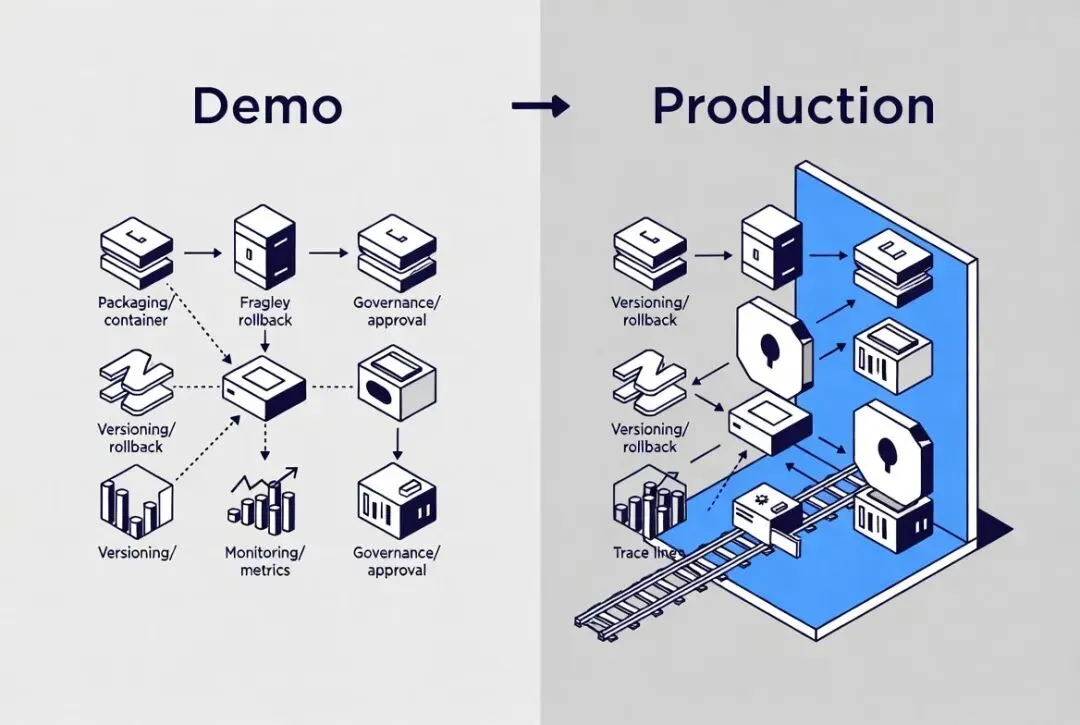
真正的分水岭不是能跑,而是能交付
把ML带进生产环境,关键不在Demo,而在部署、扩展、观测与治理。下面给一份偏“验收”的清单,建议在上线前就写进发布门槛。
生产验收清单(面向推理能力交付,而不是模型效果)
- 明确是否允许
ffi.enable,并做权限与配置基线检查 - 扩展加载失败时的降级路径要可验证(返回默认结果、切外部服务、或熔断)
- 运行时动态库、执行提供器、模型文件的打包方式要固定
- 镜像内写清构建产物校验方式(hash或版本号),避免“线上机器不一致”
- 把“是否启用GPU”做成可配置能力,并可在灰度中切换
- 吞吐(QPS或items/s)、p50/p95/p99延迟
- 错误类型分布(超时、加载失败、执行提供器不可用、OOM)
- 模型版本、运行时版本、扩展版本要能在一次发布中被追溯
- 回滚必须验证“旧模型 + 新运行时”或“新模型 + 旧运行时”是否允许混跑
- 至少准备一条无模型路径(返回兜底或转外部服务)用于事故止血
如果你的团队只做到了“请求能通、结果能出”,那仍然停留在实验阶段。生产需要的是确定性。
用一次小实验把边界画清楚
回到团队里做一个一小时内能完成的小动作,不需要上GPU也不需要训练模型。
- 选一条真实业务接口,抽取一段“看似简单但高频”的特征处理逻辑
- B版把特征处理或推理调用改成“编排式”,即PHP只做参数组装与调用控制,计算交给原生后端或推理运行时
- p95延迟、峰值RSS、错误率、每请求的原生内存增量(或进程RSS增长趋势)
这一步的价值不在性能数字本身,而在让团队对“边界在哪里”达成共识。
一个自用的评审框架,让讨论不再跑偏
最后给一个我更愿意在评审会上用的三问框架,避免讨论陷入“选哪个库更强”。
- 这段逻辑到底是在做业务决策,还是在做数值计算与推理
- 数据是否能以连续内存形态流转(Tensor/NDArray),还是被困在hash table数组里
把这三问写进你的设计文档,你会发现很多“PHP里做ML”的争论其实是交付与边界问题,而不是算法问题。
真正值得关注的变化,是PHP生态在ML上的角色越来越清晰——它不是要变成新的数值计算平台,而是在成为可靠的编排与交付层。承认这一点,选型就会更简单,事故也会更少。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
