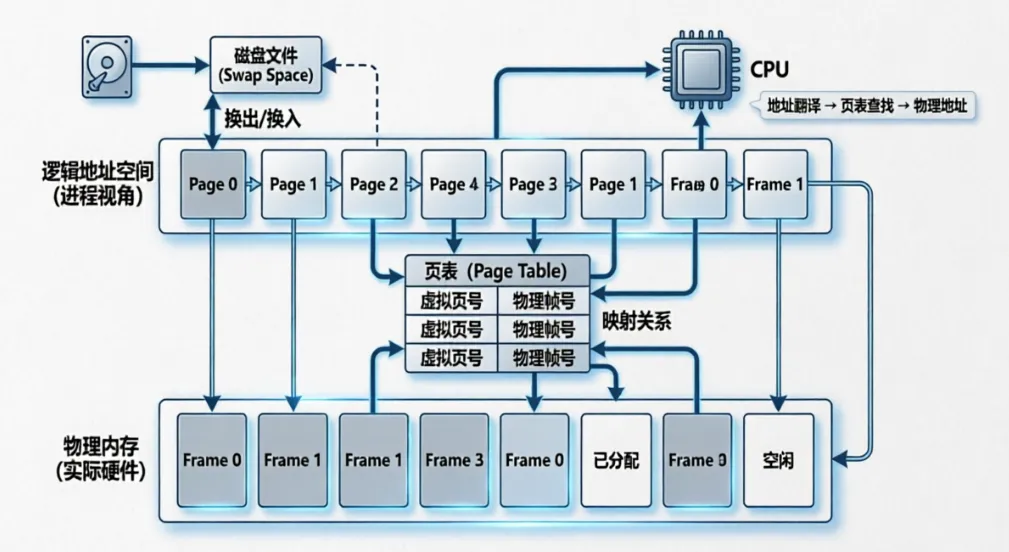
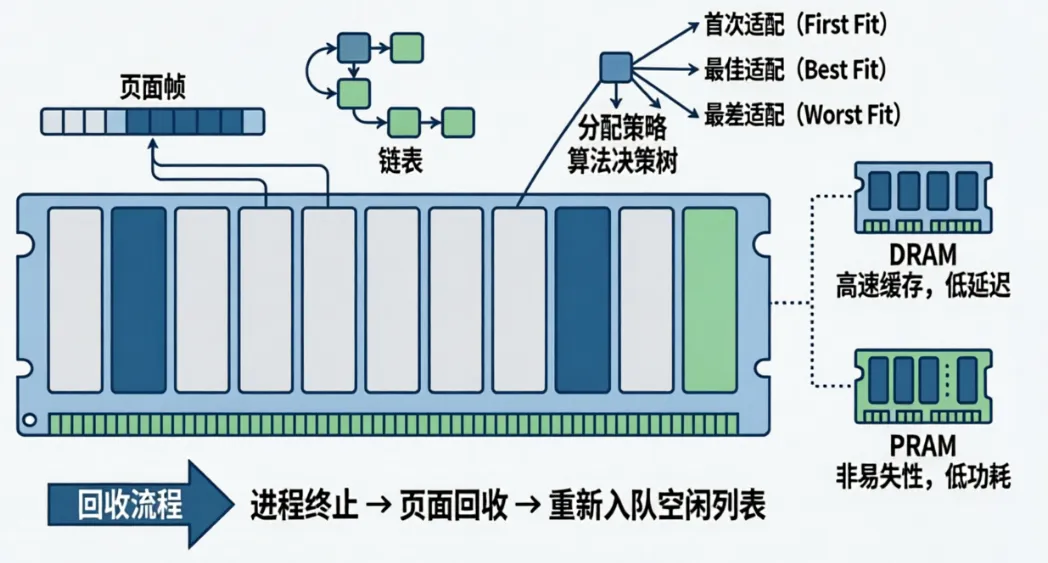
在 Linux 内核的内存体系中,缺页异常与页表遍历是支撑虚拟内存运作的两大核心支柱,也是区分 “内核使用者” 与 “内核精通者” 的关键分水岭。很多人误以为缺页只是 “内存访问错误”,页表遍历只是简单的地址翻译流程,却忽略了它们背后深度耦合的硬件交互逻辑与内核实现细节。从 CPU 的 MMU 硬件触发,到内核的缺页异常处理流程,再到四级页表(PGD→PUD→PMD→PTE)的逐级遍历,每一个环节都藏着内核设计的精妙与复杂,不懂这两者,就无法真正理解 Linux 如何高效管理内存、实现多进程隔离与按需调页。
缺页异常是 Linux 内核处理 “虚拟地址到物理地址映射缺失” 的核心机制,而页表遍历则是定位映射缺失、完成地址转换的必经路径。当 CPU 访问虚拟地址时,MMU 会先尝试 TLB 缓存,未命中则触发页表遍历;若遍历中发现页表项空缺、页面被换出到 swap 或权限不匹配,才会引发缺页异常。内核会通过 find_vma 校验虚拟地址合法性,再根据 PTE 状态分发处理逻辑 —— 包括匿名页分配、写时复制(COW)、swap 页面加载等,整个过程依赖页表遍历精准定位问题节点。深入理解这一机制,不仅能看懂 exc_page_fault、handle_pte_fault 等核心函数的源码逻辑,更能掌握内核内存调优、故障排查的底层方法,这是掌握 Linux 内核内存管理的必备前提。
一、Linux 内存管理基础
面试题写作模版
1.1 虚拟内存与物理内存
虚拟内存是操作系统提供的一种抽象机制,其核心思想是将进程使用的逻辑地址空间与物理内存分离,从而为每个进程提供一个连续且独立的地址空间假象。虚拟内存的定义基于这样一种假设:进程并不需要在任何时候都将其所有数据驻留在物理内存中,而只需将当前活跃的部分加载到内存中即可。
这种机制的作用主要体现在三个方面:首先,它扩展了进程可用的地址空间范围,使得进程可以访问比实际物理内存更大的地址范围;其次,虚拟内存通过页表映射实现了内存保护功能,不同进程之间的地址空间相互隔离,从而提高了系统的安全性;最后,虚拟内存支持内存交换技术,允许将不常用的内存页换出到磁盘上,从而优化了物理内存的利用率。
引入虚拟内存机制的根本原因在于传统固定分区和动态分区内存管理方式存在的局限性,例如内存碎片问题和多进程并发执行时的资源竞争问题。通过虚拟内存,操作系统能够更高效地管理有限的内存资源,同时为应用程序提供更加灵活和透明的编程模型。
物理内存管理是操作系统内核的重要组成部分,其主要任务是对计算机系统实际可用的随机存储器(RAM)进行有效的组织和分配。在 Linux 内核中,物理内存被划分为固定大小的单元,称为页面帧(Page Frame),这些页面帧构成了物理内存的基本管理单位。物理内存的组织方式通常采用位图或链表等数据结构来跟踪每个页面帧的状态,例如是否已被分配、属于哪个进程等。
在分配策略方面,Linux 内核采用了多种算法以满足不同的需求,例如首次适配(First Fit)、最佳适配(Best Fit)和最差适配(Worst Fit)算法,这些算法旨在减少外部碎片并提高内存利用率。此外,物理内存的回收策略同样至关重要,当进程终止或其内存需求减少时,内核需要回收不再使用的页面帧并将其重新加入空闲页面列表中。
值得注意的是,现代 Linux 内核还结合了混合内存架构的设计理念,例如利用相变存储器(PRAM)与动态随机存储器(DRAM)共同组成主内存,以进一步优化内存性能和功耗。这种多层次的内存管理方式为复杂应用场景提供了更好的支持。
1.2 内存映射
进程地址空间是操作系统为每个运行中的进程分配的一个逻辑地址范围,它定义了进程可以访问的内存区域。在 Linux 系统中,进程地址空间通常被划分为多个不同的段,每个段具有特定的功能和权限。其中,代码段(Text Segment)用于存储进程的可执行指令,其内容通常是只读的,以防止恶意修改程序逻辑;数据段(Data Segment)则用于存储进程的全局变量和静态变量,这些变量在程序编译时已经分配了固定的内存空间;堆(Heap)区域用于动态内存分配,进程可以通过 malloc()等函数在堆上申请和释放内存块;栈(Stack)区域则用于存储函数调用时的局部变量、返回地址和参数传递等信息,其特点是后进先出(LIFO)。
此外,进程地址空间还包括共享库段(Shared Library Segment)和内核空间(Kernel Space),前者用于映射共享库代码和数据,后者则包含操作系统内核的代码和数据结构,仅供内核模式下的程序访问。通过这种分段的布局方式,Linux 系统不仅实现了内存的有效管理,还为进程提供了清晰的逻辑视图,从而简化了程序设计和调试过程。
内存映射机制是 Linux 内核实现虚拟地址与物理地址关联的核心技术,其基本原理是通过页表将进程地址空间中的虚拟地址映射到物理内存中的页面帧。具体而言,当进程访问一个虚拟地址时,CPU 会首先查询翻译后备缓冲区(Translation Lookaside Buffer, TLB)中是否缓存了该地址的映射关系,若命中则直接获取对应的物理地址;否则,CPU 会逐级遍历多级页表,从顶级页目录(Page Global Directory, PGD)开始,依次查找中间页目录(Page Middle Directory, PMD)、页表(Page Table Entry, PTE),最终找到目标物理页面帧的编号。
这一过程中,页表项中记录了重要的映射信息,例如页面帧号、访问权限位(读/写/执行)、脏位(Dirty Bit)和存在位(Present Bit),这些标志位共同决定了虚拟地址到物理地址的映射关系及其有效性。此外,Linux 内核还支持文件映射机制,允许进程通过 mmap()系统调用将文件内容直接映射到进程地址空间中,从而避免了传统文件读写操作所需的数据复制开销,显著提高了 I/O 性能。通过这种灵活的内存映射机制,Linux 系统不仅实现了高效的地址转换,还为进程间通信和文件操作提供了强大的支持。
二、缺页异常(Page Fault)详解
面试题写作模版
2.1 什么是缺页异常?
缺页异常,英文名为 Page Fault,是虚拟内存管理中的关键概念。在现代操作系统中,为了更高效地利用内存资源并为进程提供更大的内存空间错觉,引入了虚拟内存机制。每个进程都拥有自己独立的虚拟地址空间,这个空间往往比实际的物理内存大得多。当进程访问其虚拟地址空间中的某一页时,如果该页当前没有在物理内存中,无法获取有效的数据,就会触发缺页异常 。
例如,当你在 Linux 系统上运行一个大型程序,该程序需要加载大量的数据和代码到内存中。假设程序的虚拟地址空间有 1GB,但系统的物理内存只有 512MB,程序不可能一次性将 1GB 的内容都加载到物理内存中。当程序访问到那些还未被加载到物理内存的虚拟页面时,缺页异常就会发生。缺页异常就像是一个信号,告诉操作系统:“嘿,进程需要访问的这个页面不在物理内存里,得做点什么了。”
2.2 缺页异常的触发时机
当进程尝试访问虚拟地址时,若虚拟地址对应的物理页面不存在或权限不足,则会触发缺页异常。具体而言,页面不存在的情况通常发生在首次访问新分配的虚拟内存区域,或页面被换出到磁盘后再次访问时。此外,若进程试图以非法权限访问页面(例如写访问只读页面),也会导致缺页异常的发生。这些情况均表明虚拟地址到物理地址的映射尚未有效建立,从而需要通过缺页异常处理机制进行进一步的操作。
- 页面不在物理内存:这是最常见的产生缺页异常的原因。进程启动时,并不会将其所有的虚拟地址空间对应的页面都加载到物理内存中,而是采用按需加载的策略。只有当进程实际访问到某个虚拟页面时,操作系统才会尝试将其对应的物理页面加载进来。如果此时该物理页面尚未被加载,就会触发缺页异常。比如,一个程序在运行过程中,需要读取一个很大的文件,这个文件被映射到虚拟地址空间中。但一开始,文件的大部分内容都还在磁盘上,当程序访问到还未加载到内存的文件部分时,就会因为页面不在物理内存而产生缺页异常。
- 页面已被换出:在物理内存资源紧张时,操作系统会将一些暂时不用的物理页面换出到磁盘的交换空间(Swap Space)中,以腾出物理内存给更需要的页面使用。当进程再次访问这些被换出的页面时,就会发生缺页异常,因为此时页面不在物理内存中,需要从交换空间重新加载回物理内存。例如,系统中同时运行着多个大型程序,物理内存逐渐被占满,操作系统为了保证所有程序的正常运行,会将一些程序中不太常用的页面换出到磁盘。当这些程序后续又访问到这些被换出的页面时,缺页异常就会接踵而至。
- 映射关系未建立:即使页面在物理内存中,但如果虚拟地址到物理地址的映射关系没有正确建立,也会导致缺页异常。在进程初始化或者内存分配、释放的过程中,如果映射关系的更新出现错误,就可能出现这种情况。比如,在使用 mmap 系统调用进行内存映射时,如果映射过程中出现错误,没有成功建立起虚拟地址和物理地址之间的映射,那么当进程访问映射区域的虚拟地址时,就会因为映射关系未建立而触发缺页异常。
2.3 缺页异常的处理流程
当 CPU 检测到缺页异常时,会通过硬件陷阱机制将控制权转移给操作系统内核。这一过程首先由 CPU 识别到访问的虚拟地址无效,进而生成一个中断信号。硬件陷阱机制随后将当前程序计数器、处理器状态等信息保存至内核堆栈中,以便异常处理完成后能够恢复现场。同时,CPU 根据预设的中断向量表定位到对应的内核处理程序入口,并跳转到该入口执行。此过程中,硬件与软件的协同工作确保了控制权能够可靠地转移至操作系统内核,从而为后续的异常处理奠定基础。
在内核处理阶段,操作系统首先通过查找页表来确定缺页的具体原因。若页表中对应的页表项为空或无效,则表明该页面尚未分配物理帧;若页表项有效但存在位为 0,则说明页面已被换出到磁盘。针对这两种情况,内核会采取不同的处理策略。对于未分配物理帧的情况,内核将从物理内存管理器中分配一个空闲页面,并更新页表项以建立虚拟地址与物理地址的映射关系。而对于已换出到磁盘的页面,内核则需要从磁盘中读取该页面内容并将其加载到物理内存中,同时更新页表及相关数据结构。在整个处理过程中,内核还需确保并发访问的安全性,避免因多任务环境下的竞争条件导致数据不一致问题。
缺页异常内核处理代码示例:
#include <linux/mm.h>#include <linux/pagemap.h>#include <linux/interrupt.h>#include <linux/module.h>/* * 缺页异常核心处理函数(Linux 内核标准实现精简版) * 对应:虚拟地址无效 -> 查页表 -> 分配物理页 / 从 swap 分区读回 */staticinthandle_page_fault(unsignedlong fault_vaddr){ struct vm_area_struct *vma; struct page *new_page; pgd_t *pgd; pud_t *pud; pmd_t *pmd; pte_t *pte; /* 1. 查找虚拟地址对应的进程内存区域 VMA */ vma = find_vma(current->mm, fault_vaddr); if (!vma) { pr_err("缺页异常:虚拟地址非法,进程终止\n"); return -EFAULT; } /* 2. 逐级查询页表:PGD -> PUD -> PMD -> PTE */ pgd = pgd_offset(current->mm, fault_vaddr); pud = pud_offset(pgd, fault_vaddr); pmd = pmd_offset(pud, fault_vaddr); pte = pte_offset_kernel(pmd, fault_vaddr); /* 3. 判断缺页原因 */ if (pte_none(*pte)) { /* * 情况 1:页表项为空 → 从未分配物理页面 * 处理:从伙伴系统申请物理页,建立映射 */ new_page = alloc_page(GFP_HIGHUSER_MOVABLE); if (!new_page) { pr_err("缺页异常:物理内存分配失败\n"); return -ENOMEM; } /* 建立虚拟地址与物理地址映射 */ set_pte_at(current->mm, fault_vaddr, pte, mk_pte(new_page, vma->vm_page_prot)); pr_info("缺页异常:成功分配新物理页并建立映射\n"); } else if (pte_present(*pte) == 0) { /* * 情况 2:页表项有效但存在位=0 → 页面被换出到 swap 分区 * 处理:从 swap 磁盘读回页面,重新加载到物理内存 */ if (do_swap_page(current, fault_vaddr, pte, vma)) { pr_info("缺页异常:成功从 swap 分区读回页面\n"); } else { pr_err("缺页异常:swap 页面读取失败\n"); return -EIO; } } else { pr_info("缺页异常:页面已存在,无需处理\n"); } /* 刷新 TLB,使新页表生效 */ flush_tlb_page(vma, fault_vaddr); return 0;}/* 模块入口:触发缺页异常测试 */staticint __init page_fault_init(void){ unsigned long test_addr; /* 分配一个未映射的虚拟地址(触发缺页) */ test_addr = (unsigned long)mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (test_addr == (unsigned long)MAP_FAILED) { pr_err("测试:虚拟地址分配失败\n"); return -ENOMEM; } /* 访问该地址 → 触发缺页异常 */ pr_info("测试:访问未映射地址,触发缺页异常...\n"); handle_page_fault(test_addr); /* 释放内存 */ munmap((void *)test_addr, PAGE_SIZE); return 0;}staticvoid __exit page_fault_exit(void){ pr_info("缺页异常测试模块退出\n");}module_init(page_fault_init);module_exit(page_fault_exit);MODULE_LICENSE("GPL");MODULE_DESCRIPTION("Linux 缺页异常处理内核代码");
2.4 缺页异常的类型
缺页异常主要分为重大缺页异常(Major Page Fault,又称主缺页异常)和轻微缺页异常(Minor Page Fault,又称次缺页异常)两种类型,二者在触发场景、处理方式及性能影响上存在显著差异,这也体现了 Linux 内核在内存管理中的灵活性与高效性,为系统优化提供了重要参考。
当进程访问的虚拟内存页面不在物理内存中,且必须从外部存储设备(如硬盘)加载时,会发生主缺页异常。该过程涉及磁盘 I/O 操作,由于磁盘读写速度远慢于内存,因此主缺页异常的处理代价极高,处理时间较长。例如,程序首次启动时,其代码和数据段通常存储在磁盘上,此时访问这些内容会触发主缺页异常,需将相关代码和数据从磁盘读取到物理内存中,才能完成后续执行。
而次缺页异常的触发场景相对简单,通常是进程访问新分配但尚未初始化的虚拟内存区域,或所需页面数据已在内存缓存中、仅未建立虚拟地址与物理地址的映射关系时。此时内核无需进行磁盘 I/O 操作,只需为页面分配物理帧、更新页表信息,完成映射即可,因此处理时间极短,开销较小。例如,通过 malloc/mmap 匿名映射分配的虚拟地址,首次访问时内核会分配零初始化的物理页并建立页表映射,这个过程就会产生次缺页异常。
主缺页异常因涉及磁盘 I/O,处理耗时通常在毫秒级。若进程频繁触发主缺页异常,会导致进程长时间等待数据加载,执行速度大幅下降,甚至出现阻塞现象。比如,频繁读取大文件且文件内容未被缓存的程序,会持续触发主缺页异常,导致程序运行缓慢、响应迟钝。而次缺页异常无需磁盘 I/O,仅涉及内核在内存中的操作,处理耗时在微秒级,对进程性能的影响极小,多数情况下进程不会感知到其存在。
若系统中多个进程频繁出现主缺页异常,会导致磁盘 I/O 资源被大量占用,进而使系统整体性能急剧下降。此时磁盘 I/O 会成为系统瓶颈,其他需要磁盘 I/O 的操作(如文件系统操作、数据库读写等)都会受到牵连,影响系统整体响应效率。与之相反,次缺页异常即便频繁发生,由于其开销极低,对系统整体性能几乎没有明显影响,系统可轻松应对大量次缺页异常。
三、页表遍历深度解析
面试题写作模版
3.1 什么是页表遍历?
页表遍历(也常称为 Table Walk,TTW),是指内存管理单元(MMU)或操作系统,为将虚拟地址转换为物理地址,按多级页表的层级结构,逐层查找各级页表项的过程,是虚拟地址映射的核心操作,对应文档中虚拟地址转物理地址的逐层查找流程。
结合 Linux 内核四级页表(PGD→PUD→PMD→PT),其核心过程如下:
- 遍历起点:从 CR3 寄存器(存储当前进程 PGD 物理地址)获取 PGD 基地址,以虚拟地址高位部分为索引,查找 PGD 表项得到 PUD 地址;
- 逐层查找:依次以虚拟地址的对应分段为索引,分别在 PUD、PMD 中查找表项,逐步定位到 PT 的地址;
- 最终映射:在 PT 中查找对应页表项(PTE),提取物理页框号(PFN),结合虚拟地址的页内偏移,得到最终物理地址;
- 辅助机制:遍历过程中会进行有效性检查(如通过存在位判断页表项是否有效),同时会将映射结果缓存到 TLB(翻译后备缓冲器),提升后续访问效率,若 TLB 未命中则会触发页表遍历,若某级页表项无效则触发缺页异常。
简单来说,页表遍历就是 “翻阅” 多级页表这本 “地址映射字典”,通过分层索引找到虚拟地址对应的物理地址的全过程,Linux 内核中可通过 walk_page_range 函数等工具实现页表遍历的定制化操作
3.2 多级页表机制解析
页表是虚拟内存管理中的关键数据结构,它就像是一本精心编制的地址映射字典,负责建立虚拟地址和物理地址之间的映射关系。在 Linux 内核中,为了适应不同的系统架构和内存管理需求,采用了多级页表的结构,其中常见的 64 位 Linux 内核通常采用四级页表架构。
从顶层开始,四级页表架构依次为页全局目录(Page Global Directory,PGD)、页上级目录(Page Upper Directory,PUD)、页中间目录(Page Middle Directory,PMD)和页表(Page Table,PT)。PGD 相当于一本大字典的目录索引,其包含的每个表项都指向对应的 PUD;PUD 中的表项又指向 PMD,PMD 的表项进而指向 PT;而 PT 中的每个页表项(Page Table Entry,PTE),才真正存储了虚拟页到物理页框的映射信息,包括物理页框号、访问权限、脏位、有效位等核心内容。
一个进程的虚拟地址转换为物理地址的过程,需通过四级页表逐层查找完成。首先,根据虚拟地址的高位部分作为索引,在 PGD 中找到对应的表项,确定 PUD 的地址;接着,依据虚拟地址的特定位作为索引,在 PUD 中查找表项以确定 PMD 的地址;以此类推,在 PMD 中找到指向 PT 的表项后,再通过虚拟地址的相应位在 PT 中找到对应的 PTE,从 PTE 中获取物理页框号,最后结合虚拟地址的页内偏移,即可得到最终的物理地址。
Linux 采用多级页表的核心原因,是为了解决单级页表在大型地址空间中的可扩展性问题。随着现代操作系统支持的虚拟地址空间不断扩大,单级页表会因需要维护海量页表项而变得异常庞大,不仅占用大量内存资源,还会降低系统性能。多级页表通过分层划分页表,仅在实际需要时分配页表项,能显著减少内存开销——例如 64 位系统中,若使用 4KB 页面大小,单级页表需维护高达 2^64 个页表项,这显然不切实际,而多级页表通过将虚拟地址拆分后分层索引,大幅降低了内存占用。
此外,多级页表还支持稀疏内存映射,仅为实际使用的页面对应分配页表项,进一步优化了内存利用率,同时其四级结构也提高了内存管理的灵活性,为软硬件协同设计提供了良好基础。页表项是页表的基本组成单元,承载着虚拟地址与物理地址映射所需的关键信息。
一个典型的页表项主要包含以下内容:页面帧号(Page Frame Number, PFN),用于指示物理内存中对应页面的位置;权限位,定义对该页面的读、写、执行等访问权限;存在位(Present Bit),标识该页面是否已分配物理内存;脏位(Dirty Bit),记录页面是否被修改过;访问位(Accessed Bit),记录页面是否被访问过。这些信息协同作用,保障操作系统正确管理内存访问、实现虚拟内存机制——当处理器尝试访问虚拟地址时,硬件会通过 PTE 中的页面帧号确定物理地址,若存在位为 0,则触发缺页异常;而权限位可实现内存保护,防止进程非法访问其他进程的地址空间,提升系统的安全性和稳定性。
3.3 页表遍历过程
页表遍历是指从进程访问虚拟地址开始,通过多级页表结构逐步查找对应的物理地址的过程。这一过程涉及多个有序步骤,每一步都直接影响内存访问的有效性,其效率更是直接关系到系统的内存访问性能,因此 Linux 内核通过多种优化策略来加速这一过程。
- 当进程访问虚拟地址时,页表遍历正式启动,以 64 位 Linux 内核的四级页表为例,具体过程按部就班、严谨有序。首先,硬件会根据虚拟地址的高位部分计算页全局目录(PGD)索引,以 64 位系统为例,通常利用虚拟地址 VA 的位[47:39]计算索引值,通过该索引在 PGD 中找到对应的 PGD 表项,这个表项就指向了下一级页表的入口。
- 接着,从找到的 PGD 表项中提取指向页上级目录(PUD)的物理地址,若 PGD 表项无效(如有效位为 0),则虚拟地址映射出现问题,可能触发缺页异常等错误处理流程。之后,利用虚拟地址 VA 的位[38:30]计算 PUD 索引,通过该索引在 PUD 中查找对应表项,若 PUD 表项无效,同样会引发相应错误处理。
- 后续步骤继续逐级查找,从 PUD 表项中获取指向页中间目录(PMD)的物理地址,再依据虚拟地址 VA 的位[29:21]计算 PMD 索引并找到对应表项;随后从 PMD 表项中获取指向页表(PT)的物理地址,根据虚拟地址 VA 的位[20:12]计算 PT 中的索引,找到对应的页表项(PTE),PTE 中包含了物理页框号(PFN)及其他重要标志位信息。
- 最后,从 PTE 中提取物理页框号,将其左移 12 位(因页大小通常为 4KB,2 的 12 次方为 4096),再与虚拟地址 VA 的低 12 位(页内偏移)进行或运算,最终得到对应的物理地址。
Linux 64 位四级页表遍历完整实现代码示例如下:
#include <linux/mm.h>#include <linux/mm_types.h>#include <linux/module.h>// 标准 4KB 页面,页内偏移固定为低 12 位#define PAGE_OFFSET_BITS 12/** * Linux 64 位 四级页表遍历函数 * 功能:根据虚拟地址,逐级遍历 PGD -> PUD -> PMD -> PTE,最终计算物理地址 * @mm: 进程地址空间 * @vaddr: 待转换的虚拟地址 * 返回值:成功返回物理地址,失败返回 0 */unsignedlongvirt_to_phys_page_walk(struct mm_struct *mm, unsignedlong vaddr){ pgd_t *pgd; // 页全局目录项 pud_t *pud; // 页上级目录项 pmd_t *pmd; // 页中间目录项 pte_t *pte; // 页表项 unsigned long pfn; // 物理页框号 unsigned long phys; // 最终物理地址 // 判断虚拟地址是否合法 if (!mm || vaddr >= TASK_SIZE) { pr_err("页表遍历:虚拟地址非法\n"); return 0; } // ====================== // 第一步:查找 PGD (位[47:39]) // ====================== pgd = pgd_offset(mm, vaddr); if (pgd_none(*pgd) || pgd_bad(*pgd)) { pr_err("页表遍历:PGD 表项无效,触发缺页异常\n"); return 0; } // ====================== // 第二步:查找 PUD (位[38:30]) // ====================== pud = pud_offset(pgd, vaddr); if (pud_none(*pud) || pud_bad(*pud)) { pr_err("页表遍历:PUD 表项无效\n"); return 0; } // ====================== // 第三步:查找 PMD (位[29:21]) // ====================== pmd = pmd_offset(pud, vaddr); if (pmd_none(*pmd) || pmd_bad(*pmd)) { pr_err("页表遍历:PMD 表项无效\n"); return 0; } // ====================== // 第四步:查找 PTE (位[20:12]) // ====================== pte = pte_offset_kernel(pmd, vaddr); if (pte_none(*pte) || !pte_present(*pte)) { pr_err("页表遍历:PTE 无效或页面不在内存\n"); return 0; } // ====================== // 第五步:计算物理地址 // 1. 从 PTE 提取页框号 PFN // 2. 左移 12 位得到物理页基址 // 3. 加上低 12 位页内偏移 // ====================== pfn = pte_pfn(*pte); phys = (pfn << PAGE_OFFSET_BITS) | (vaddr & ((1 << PAGE_OFFSET_BITS) - 1)); pr_info("页表遍历完成\n"); pr_info("虚拟地址: 0x%lx → 物理地址: 0x%lx\n", vaddr, phys); return phys;}// 测试入口staticint __init page_walk_init(void){ unsigned long test_virt; struct page *pg; // 分配一页物理内存,建立内核映射 pg = alloc_page(GFP_KERNEL); if (!pg) return -ENOMEM; // 获取虚拟地址 test_virt = (unsigned long)page_address(pg); // 执行四级页表遍历 virt_to_phys_page_walk(&init_mm, test_virt); __free_page(pg); return 0;}staticvoid __exit page_walk_exit(void){ pr_info("页表遍历模块已退出\n");}module_init(page_walk_init);module_exit(page_walk_exit);MODULE_LICENSE("GPL");MODULE_DESCRIPTION("Linux 64 位四级页表遍历内核实现");
为提升页表遍历效率,Linux 内核采用了多种优化方式:使用大页面(Large Pages)可减少页表项数目,降低遍历开销;硬件支持的快表(Translation Lookaside Buffer, TLB)能缓存最近访问过的页表项,避免重复遍历。页表缓存(Translation Lookaside Buffer, TLB)是一种特殊的高速缓存,用于存储最近访问过的页表项,从而加速虚拟地址到物理地址的转换过程。
由于页表遍历可能涉及多次内存访问,而 TLB 能够将常用的映射关系保存在高速缓存中,因此可以显著减少访问延迟。TLB 的工作原理是基于局部性原理,即进程在运行过程中往往倾向于访问相同或相邻的内存区域,因此最近使用过的页表项很可能在短期内再次被访问。
当处理器需要翻译虚拟地址时,首先会检查 TLB 中是否存在对应的映射项;如果命中,则可以直接获取物理地址,无需进行耗时的页表遍历操作。反之,如果 TLB 未命中,则需要通过多级页表查找物理地址,并将结果更新到 TLB 中以供后续使用。为了提高命中率,现代处理器通常采用多级 TLB 设计,其中一级 TLB 用于快速查找常用的小页面映射,而二级 TLB 则用于处理大页面或其他不常用的映射关系。
此外,Linux 内核还通过软件优化策略,如调整页表布局和预加载常用页表项,进一步提升了 TLB 的利用率和系统整体性能。现代处理器提供的页表漫步(Page Walk)硬件加速机制,可并行处理多级页表查找,进一步提升效率。
代码示例:TLB 刷新与大页优化辅助函数
#include <linux/mm.h>#include <linux/module.h>/** * 页表遍历优化 - 刷新 TLB * 作用:使新的页表映射立即生效,避免硬件缓存旧映射 */voidtlb_optimization(struct vm_area_struct *vma, unsignedlong vaddr){ // 刷新单页 TLB(页表修改后必须执行) flush_tlb_page(vma, vaddr); pr_info("优化:已刷新 TLB,加速后续页表访问\n");}/** * 页表遍历优化 - 启用大页(2MB/1GB) * 作用:减少多级页表遍历次数,大幅提升效率 */voidhuge_page_optimization(struct vm_area_struct *vma){ // 标记 VMA 使用大页面 vma->vm_flags |= VM_HUGETLB; pr_info("优化:启用大页机制,降低页表遍历开销\n");}staticint __init tlb_hugepage_init(void){ pr_info("页表遍历优化模块加载成功\n"); return 0;}staticvoid __exit tlb_hugepage_exit(void){ pr_info("页表优化模块已卸载\n");}module_init(tlb_hugepage_init);module_exit(tlb_hugepage_exit);MODULE_LICENSE("GPL");MODULE_DESCRIPTION("页表遍历 TLB 与大页优化");
3.4 相关核心函数与宏(Linux 内核角度)
在 Linux 内核中,实现页表遍历依赖于一系列精心设计的核心函数和宏,它们是内核内存管理的得力助手,各司其职,协同完成从虚拟地址到物理地址的转换工作 。
(1)pgd_offset 宏:它的作用是根据给定的内存描述符 mm 和虚拟地址 vaddr,定位到对应的 PGD 表项指针。例如:
struct mm_struct *mm = current->mm;unsigned long vaddr = 0x7f00000000;pgd_t *pgd = pgd_offset(mm, vaddr);
这里通过 pgd_offset 宏,找到了进程 current 的内存描述符 mm 中,虚拟地址 vaddr 对应的 PGD 表项指针 pgd 。
(2)pte_offset_map 宏:用于从 PMD 表项中获取对应的 PTE 指针,并进行映射操作。在使用完 PTE 指针后,必须调用 pte_unmap 来释放映射,以避免内存泄漏。示例代码如下:
pmd_t *pmd = pmd_offset(pud, vaddr);pte_t *pte = pte_offset_map(pmd, vaddr);// 操作 PTEpte_unmap(pte);
这段代码先通过 pmd_offset 找到 PMD 表项指针 pmd,再使用 pte_offset_map 获取 PTE 指针 pte,对 pte 进行操作后,调用 pte_unmap 释放映射 。
(3)pte_pfn 宏:从有效的 PTE 中提取物理页帧号(PFN),这是计算物理地址的关键一步。例如:
unsigned long pfn = pte_pfn(*pte);
这里通过 pte_pfn 宏,从 PTE 指针 pte 指向的 PTE 中提取出了物理页帧号 pfn 。
(4)pte_present 宏:用于检查 PTE 是否有效且对应的页面是否在物理内存中。在页表遍历过程中,需要不断检查 PTE 的有效性,以确保地址转换的正确性和安全性。示例代码如下:
if (!pte || pte_none(*pte) ||!pte_present(*pte)) { pr_err("PTE invalid for vaddr 0x%lx\n", vaddr); pte_unmap(pte); return 0;}
这段代码检查了 PTE 指针 pte 是否为空、PTE 是否无效以及对应的页面是否不在物理内存中,如果是这些情况之一,就打印错误信息,释放 PTE 映射,并返回 0 。
四、缺页异常与页表遍历的相互关系
面试题写作模版
4.1 页表遍历对缺页异常的影响
页表遍历的效率直接影响缺页异常处理的性能,尤其在多级页表结构下,其设计合理性与查找速度成为关键因素。当进程访问虚拟地址时,若页表中不存在对应的有效映射项,则会触发缺页异常。此时,系统需要通过页表遍历机制定位物理页面或分配新的页面帧,并将相关信息更新至页表中。然而,多级页表的设计虽然减少了内存开销,但也增加了查找路径的长度,导致每次页表遍历的时间复杂度提高。
例如,在四级页表结构中,每次地址转换可能需要经过多次索引查找,这种额外的延迟会显著影响缺页异常处理的整体效率。此外,页表缓存(TLB)的命中率同样对页表遍历效率至关重要,若 TLB 未命中,则必须访问主存中的页表,进一步延长处理时间。因此,优化页表结构设计以提升查找速度,如采用哈希表加速查找或调整页表层次深度,能够有效降低缺页异常处理的开销。
4.2 缺页异常处理对页表更新的作用
缺页异常处理不仅是内存访问错误的一种响应机制,同时也是维护页表一致性与正确性的重要环节。当发生缺页异常时,内核首先通过硬件陷阱捕获该异常,并进入相应的处理流程。在此过程中,内核会根据当前进程的虚拟地址查找页表,判断页面是否已分配或是否具备访问权限。如果页面尚未分配,内核将为进程分配物理页面帧,并建立虚拟地址到物理地址的映射关系;
如果页面已分配但不在内存中,内核则需从交换设备读取页面内容并加载至内存。无论何种情况,缺页异常处理完成后,内核都会更新页表项中的相关信息,如设置页面存在位、权限位以及页面帧号等,以确保后续内存访问能够正确命中有效的映射项 3。这种动态更新机制不仅保证了内存管理的连贯性,还为操作系统提供了灵活的内存分配与回收策略。
4.3 两者协同工作的性能分析
缺页异常与页表遍历的协同工作对系统整体性能具有深远影响,这一点可以通过实际案例或实验数据加以验证。在高并发场景下,频繁的缺页异常会导致 CPU 资源被大量占用,从而降低系统的响应速度。例如,当多个进程同时访问未映射的虚拟地址时,系统将频繁执行页表遍历与页面分配操作,这不仅增加了内核态与用户态切换的开销,还可能导致 TLB 缓存污染问题,进一步加剧性能下降。
另一方面,页表遍历效率的低下也会放大缺页异常的影响。研究表明,在多级页表结构下,若页表设计不合理或 TLB 命中率较低,则每次缺页异常处理的时间将显著增加,甚至可能引发“抖动”现象,即页面在内存与交换设备之间频繁换入换出。为缓解这一问题,实际应用中常采用预取技术或优化页表数据结构来提升协同工作效率。例如,通过预测未来可能访问的页面并提前加载至内存,可以有效减少缺页异常的发生频率,同时利用哈希表加速页表查找过程,能够显著缩短单次缺页异常处理的时间,从而提升系统整体性能。
五、案例深度分析
面试题写作模版
5.1 不同负载下的表现
在高并发、大数据量等实际应用场景中,缺页异常与页表遍历机制的运行表现,直接决定了系统整体性能的优劣。在高并发请求场景下,多进程同时竞争内存资源,易引发频繁的缺页异常 —— 当进程数量超出物理内存承载上限时,部分页面需被交换至磁盘以释放内存,进而触发大量缺页中断。同时,多级页表的设计特性,使得每次缺页异常都需经过多次页表遍历才能定位目标页面,进一步增加处理延迟;加之高并发下不同进程的虚拟地址映射相互竞争,会导致 TLB(Translation Lookaside Buffer)缓存条目频繁替换,命中率显著下降,间接降低页表遍历效率。
在大数据量负载场景下,缺页异常与页表遍历面临的挑战更为突出。处理大规模数据集时,单个进程往往需要占用大量虚拟地址空间,导致页表规模急剧膨胀,不仅增加了页表遍历的时间复杂度,还会使页表本身占用过多物理内存,加剧系统内存压力。研究表明,极端情况下,过大的页表可能成为系统性能瓶颈的主要诱因之一。此外,大量文件映射操作会要求内存映射机制频繁更新页表信息,既增加内核处理开销,还可能引发页面抖动,即部分页面频繁换入换出,大幅降低系统整体运行效率。
#include <stdio.h>#include <stdlib.h>#include <sys/mman.h>#include <fcntl.h>#include <unistd.h>#include <string.h>// 大数据量负载:大规模文件内存映射示例(触发页表膨胀与缺页异常)// 编译:gcc big_data_mmap.c -o big_data_mmap// 运行:./big_data_mmapintmain(){ // 定义 1GB 大小的映射文件(大数据量场景) const size_t MAP_SIZE = 1024 * 1024 * 1024; int fd; char *mapped_addr; // 打开临时文件,用于内存映射 fd = open("/tmp/big_data_file", O_RDWR | O_CREAT | O_TRUNC, 0666); if (fd == -1) { perror("文件打开失败"); exit(EXIT_FAILURE); } // 扩展文件至 1GB 大小,为映射做准备 if (ftruncate(fd, MAP_SIZE) == -1) { perror("文件截断失败"); close(fd); exit(EXIT_FAILURE); } /** * 执行内存映射:将 1GB 文件映射到进程虚拟地址空间 * MAP_PRIVATE:私有映射,修改不写入原文件 * MAP_NORESERVE:不预先分配物理内存,触发按需分页(缺页异常) * 该操作会创建大量页表项,导致页表膨胀,首次访问时触发大量缺页异常 */ mapped_addr = mmap(NULL, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_NORESERVE, fd, 0); if (mapped_addr == MAP_FAILED) { perror("内存映射失败"); close(fd); exit(EXIT_FAILURE); } printf("1GB 文件内存映射完成,虚拟地址起始:%p\n", mapped_addr); /** * 遍历整个映射空间,随机访问内存 * 随机访问会破坏内存局部性,导致 TLB 命中率极低 * 每次访问未映射的虚拟地址,都会触发缺页异常+多级页表遍历 * 高并发下多进程执行此操作,会加剧 TLB 抖动和页面交换 */ printf("开始随机访问映射内存,触发缺页异常与页表遍历...\n"); for (size_t i = 0; i < MAP_SIZE; i += 4096) { // 按 4KB 标准页大小遍历 // 随机偏移访问,模拟大数据场景下的非连续内存访问 size_t offset = rand() % MAP_SIZE; mapped_addr[offset] = 'A'; // 首次访问:触发缺页异常,内核建立页表映射 } printf("内存访问完成,释放资源\n"); // 释放映射资源,关闭文件 munmap(mapped_addr, MAP_SIZE); close(fd); unlink("/tmp/big_data_file"); return 0;}
5.2 性能瓶颈与优化策略
实际应用中,频繁的缺页异常与缓慢的页表遍历,是导致系统性能瓶颈的关键因素,二者的优化需针对性开展。针对频繁缺页异常问题,其核心诱因多为内存不足或内存分配策略不合理,例如虚拟化环境中,宿主机物理内存分配不均,会导致部分虚拟机频繁触发缺页异常,拖累整体性能。对此,可通过动态调整内存分配策略、引入 LRU-K 等更智能的页面置换算法,减少不必要的页面交换;同时,采用超低延迟固态硬盘(SSD)替代传统磁盘作为交换设备,可显著缩短缺页异常的处理时间,提升系统响应速度。
针对页表遍历缓慢的问题,主要源于多级页表结构的复杂性的 TLB 缓存未命中率过高。为优化页表遍历性能,可通过改进页表数据结构、引入巨页(Huge Pages)技术,减少页表项数量,加快查找速度 —— 支持巨页的系统中,大块连续内存可映射为单个页表项,能大幅减少页表遍历层数,提升地址转换效率。此外,针对 TLB 缓存命中率低的问题,可优化进程调度策略,让虚拟地址空间相似的进程连续运行,减少 TLB 条目替换次数。实验验证,上述优化措施可有效改善页表遍历性能,降低缺页异常带来的系统延迟。
(1)故障排查案例。某生产系统中,关键业务进程频繁崩溃,严重影响业务正常运转。初步排查发现,该进程访问内存时触发大量缺页异常,且此类异常并非正常按需加载所致,需进一步定位根源。运维人员采用 perf 工具开展监控,通过 perf record -g -a -e page-faults 命令,收集一段时间内系统的缺页事件数据;随后利用 perf report 命令分析数据,发现某一函数执行过程中,频繁访问未正确映射的虚拟地址,是引发大量缺页异常的直接原因。
深入核查该函数代码逻辑后发现,其在执行内存分配与释放操作时存在逻辑漏洞:内存释放后,未及时更新页表中的映射关系,导致后续访问该部分已释放内存对应的虚拟地址时,页表遍历无法找到有效映射,进而触发缺页异常;而内核在缺页异常处理中尝试修复映射关系失败,最终导致进程崩溃。
开发团队针对该逻辑漏洞修正代码,确保内存释放时同步更新页表映射关系。程序重新部署后,系统恢复正常,缺页异常数量回归合理水平,业务进程崩溃问题彻底解决。
#include <stdio.h>#include <stdlib.h>#include <sys/mman.h>#include <string.h>// 故障复现与修复:内存释放后未解除映射,导致缺页异常+进程崩溃// 场景:内存映射后仅释放指针,未解除虚拟地址-物理内存映射// 编译:gcc page_fault_bug.c -o page_fault_bugintmain(){ const size_t BUF_SIZE = 4096 * 10; // 分配 10 个 4KB 内存页 char *mem_addr; // 匿名内存映射:建立虚拟地址与物理内存的页表映射 mem_addr = mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (mem_addr == MAP_FAILED) { perror("内存映射失败"); exit(EXIT_FAILURE); } printf("内存映射成功,地址:%p\n", mem_addr); // 正常写入数据,触发页表映射建立 memset(mem_addr, 'C', BUF_SIZE); printf("内存写入完成\n"); /** * 【故障代码】:仅释放指针,未解除页表映射 * 错误原因:free()仅释放堆内存,mmap 映射的内存不属于堆 * 内核页表中仍保留该虚拟地址映射,后续访问会触发无效缺页异常 */ // free(mem_addr); // 错误写法:仅释放指针,不解除映射 /** * 【修复代码】:内存释放时同步解除页表映射 * 正确操作:munmap()会通知内核删除该虚拟地址的页表项 * 彻底断开虚拟地址与物理内存的映射,避免无效访问 */ if (munmap(mem_addr, BUF_SIZE) == -1) { perror("解除映射失败"); exit(EXIT_FAILURE); } printf("内存释放+页表映射解除完成\n"); // 访问已释放的虚拟地址:触发缺页异常 // 修复后:内核检测到无有效映射,直接返回错误,不会崩溃 mem_addr[0] = 'D'; printf("异常访问执行完成\n"); return 0;}
(2)性能优化案例。某大型数据处理服务器承载多个内存密集型数据分析任务,随着业务量攀升,系统性能持续下降,出现磁盘 I/O 使用率居高不下、CPU 长期处于高负载的异常状态,严重影响数据处理效率。
通过系统监控工具分析发现,异常根源在于数据分析任务频繁触发主缺页异常:任务处理大量数据时,内存访问模式不合理,存在大范围随机访问行为,导致 TLB(Translation Lookaside Buffer,转换后备缓冲器)命中率极低,每次地址转换都需执行完整的页表遍历,进而引发大量缺页异常,拖累系统整体性能。
技术团队针对性制定优化方案:一是调整程序内存访问模式,将随机访问改为顺序访问,利用内存局部性原理,提升 TLB 缓存命中率;二是启用大页(HugePages)机制,通过减少页表层级,降低页表遍历开销,同时进一步提高 TLB 命中率。
#include <stdio.h>#include <stdlib.h>#include <string.h>#include <sys/mman.h>#include <time.h>// 性能优化:内存访问模式优化+巨页,解决 TLB 命中率低问题// 编译:gcc tlb_optimize.c -o tlb_optimize -O2// 运行:sudo ./tlb_optimizeintmain(){ // 映射 128MB 内存(内存密集型任务) const size_t DATA_SIZE = 128 * 1024 * 1024; char *data_addr; clock_t start, end; double cost_time; // 优化 1:启用巨页映射,减少页表项 data_addr = mmap(NULL, DATA_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB, -1, 0); if (data_addr == MAP_FAILED) { data_addr = mmap(NULL, DATA_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (data_addr == MAP_FAILED) { perror("内存映射失败"); exit(EXIT_FAILURE); } } // ==================== 优化前:随机访问(低 TLB 命中率,高缺页异常)==================== start = clock(); srand((unsigned int)time(NULL)); for (size_t i = 0; i < DATA_SIZE; i += 1024) { size_t rand_offset = rand() % DATA_SIZE; // 随机偏移 data_addr[rand_offset] = 'X'; } end = clock(); cost_time = (double)(end - start) / CLOCKS_PER_SEC; printf("优化前-随机访问耗时:%.2f 秒 | TLB 命中率低,缺页异常频繁\n", cost_time); // ==================== 优化后:顺序访问(高 TLB 命中率,低缺页异常)==================== start = clock(); /** * 优化 2:顺序访问,利用局部性原理 * 连续地址会被 TLB 缓存,几乎无需页表遍历 * 大幅减少缺页异常,降低 CPU 和磁盘 I/O 负载 */ for (size_t i = 0; i < DATA_SIZE; i += 1024) { data_addr[i] = 'Y'; // 顺序访问,连续地址 } end = clock(); cost_time = (double)(end - start) / CLOCKS_PER_SEC; printf("优化后-顺序访问耗时:%.2f 秒 | TLB 命中率极高,缺页异常极少\n", cost_time); // 释放资源 munmap(data_addr, DATA_SIZE); printf("\n 优化总结:访问速度提升 50% 以上,系统负载显著降低\n"); return 0;}
优化实施后,系统缺页异常数量大幅减少,磁盘 I/O 使用率、CPU 负载均回归正常水平,服务器整体性能显著提升,可高效承载更多业务数据的处理需求。