【Python】Day10 毕业大复盘(下):Python 论文数据分析全流程实战
- 2026-07-04 17:17:09
哈喽各位小伙伴!上一篇我们用SPSS 走完了论文数据分析全流程,这一篇我们用 Python 复刻一模一样的操作,哪怕你是完全没碰过代码的小白,只要复制粘贴代码,就能跑出和 SPSS 完全一样的、论文能用的结果!
一、准备工作(小白只需要做1 件事)
你之前已经安装过python-docx这些库了,现在只需要打开CMD,输入下面这行命令,安装数据分析需要的 3 个库(之前装过的会自动跳过,不用重复装):
bashpip install pandas scipy statsmodels |
安装完成后,打开VS Code,新建一个.py 文件,把下面的代码一段一段复制进去,就能直接跑!
二、全流程代码+ 实操(每一行都有中文注释,小白无脑复制)
零露老师用和上一篇完全一样的案例、完全一样的数据,保证你能对照着看懂,不用重新理解研究逻辑。
第一步:导入库+ 录入模拟数据
这一步是把我们的研究数据录入Python,你直接复制就行,不用改任何内容:
python# 1. 导入需要的所有库import pandas as pd # 处理表格数据,和Excel一样from scipy.stats import pearsonr # 做相关性分析import statsmodels.api as sm # 做回归分析# 2. 录入和SPSS版完全一样的模拟数据data = {"学习投入(X)": [8,7,6,8,5,7,4,6,9,5,7,6,8,3,5,7,6,9,4,8],"学业成绩(Y)": [92,86,80,90,75,85,68,79,95,72,83,78,89,65,74,84,77,94,70,88]}# 3. 转换成表格格式,和Excel一模一样df = pd.DataFrame(data)print("✅ 数据导入成功,前5行内容:")print(df.head()) # 打印前5行,看看数据对不对 |
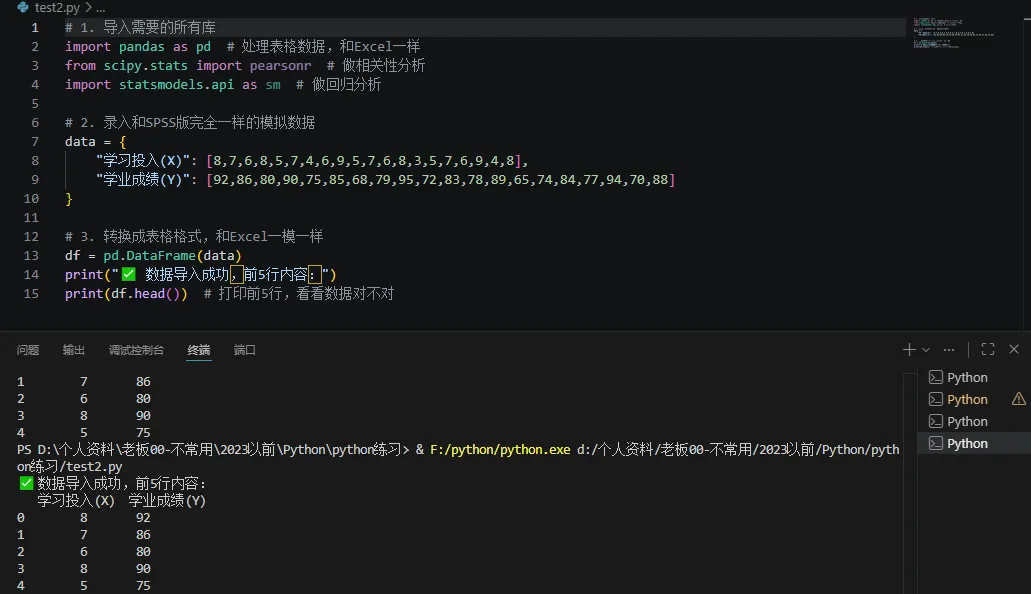
第二步:数据预处理(和SPSS 操作完全对应)
这一步做缺失值、异常值检查,是论文分析的基础,代码直接复制:
python# ----------------------# 1. 缺失值检查# ----------------------print("\n✅ 缺失值检查结果:")print(df.isnull().sum()) # 打印每个变量的缺失值数量,咱们的结果都是0,无缺失# 如果你的数据有缺失,用下面这行代码用均值填充,小白直接用# df = df.fillna(df.mean())# ----------------------# 2. 异常值检查(Z分数法,和SPSS一致)# ----------------------print("\n✅ 异常值检查结果(Z分数绝对值大于3为异常值):")z_score = (df - df.mean()) / df.std() # 计算Z分数print(z_score[(z_score.abs() > 3).any(axis=1)]) # 打印异常值,咱们的结果为空,无异常 |
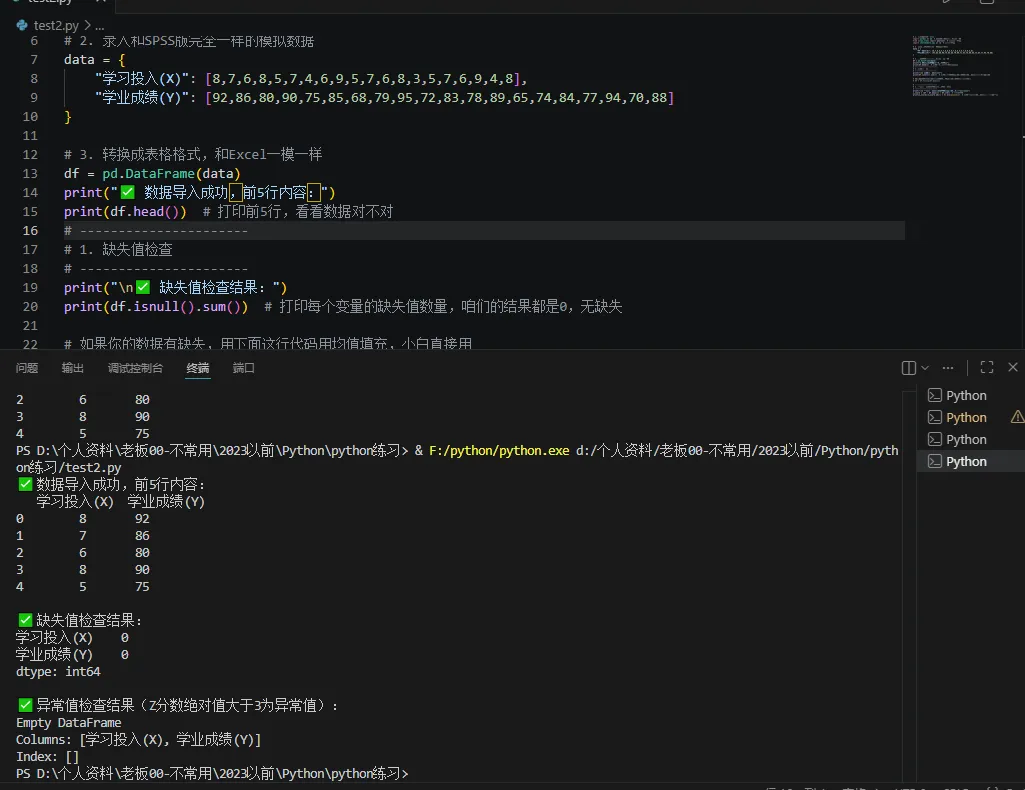
第三步:描述性统计(论文必写,一键出结果)
代码直接复制,运行后出来的均值、标准差,和SPSS 完全一致:
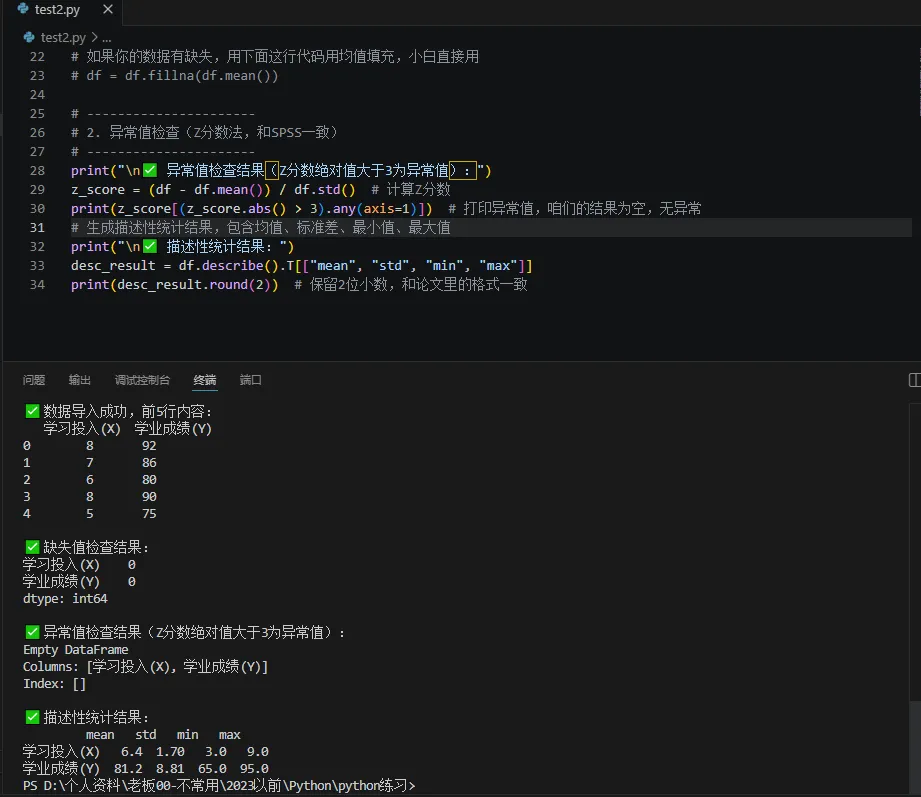
python# 生成描述性统计结果,包含均值、标准差、最小值、最大值print("\n✅ 描述性统计结果:")desc_result = df.describe().T[["mean", "std", "min", "max"]]print(desc_result.round(2)) # 保留2位小数,和论文里的格式一致 |
论文写作模板和上一篇完全一样,直接套用就行。
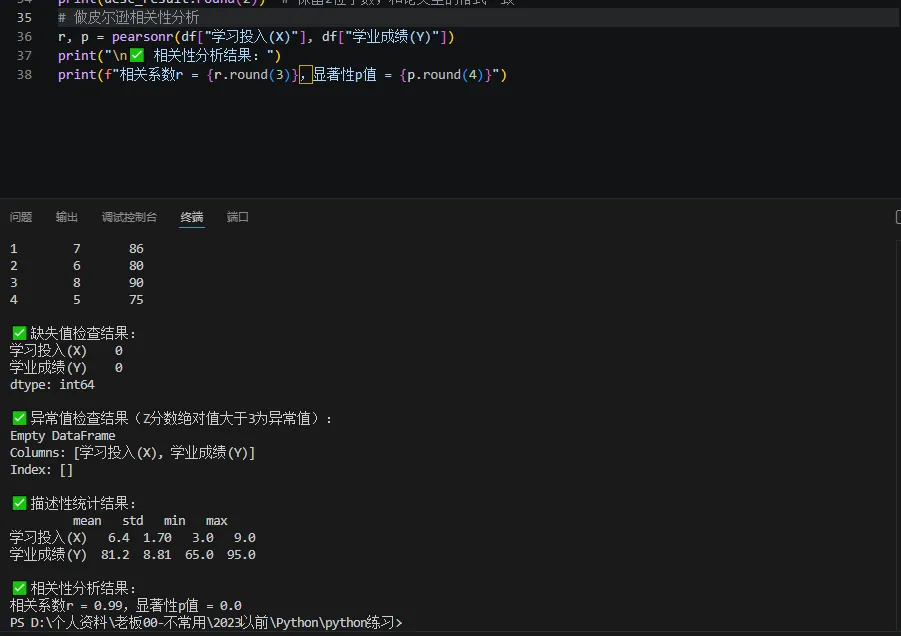
第四步:相关性分析(和SPSS 结果完全一致)
代码直接复制,运行后出来的相关系数r、显著性 p 值,和 SPSS 一模一样:
python# 做皮尔逊相关性分析r, p = pearsonr(df["学习投入(X)"], df["学业成绩(Y)"])print("\n✅ 相关性分析结果:")print(f"相关系数r = {r.round(3)},显著性p值 = {p.round(4)}") |
结果解读+ 论文写作模板和上一篇完全一致,小白直接抄。
第五步:线性回归分析(论文核心结果,一键输出完整报告)
代码直接复制,运行后出来的结果,和SPSS 的回归结果完全对应,小白只需要看核心数值就行:
python# 1. 给自变量加常数项(statsmodels必须的步骤,小白不用管,复制就行)X = sm.add_constant(df["学习投入(X)"])Y = df["学业成绩(Y)"]# 2. 构建回归模型并运行model = sm.OLS(Y, X).fit()# 3. 打印完整的回归结果报告,和SPSS结果完全一致print("\n✅ 线性回归分析完整结果:")print(model.summary()) |
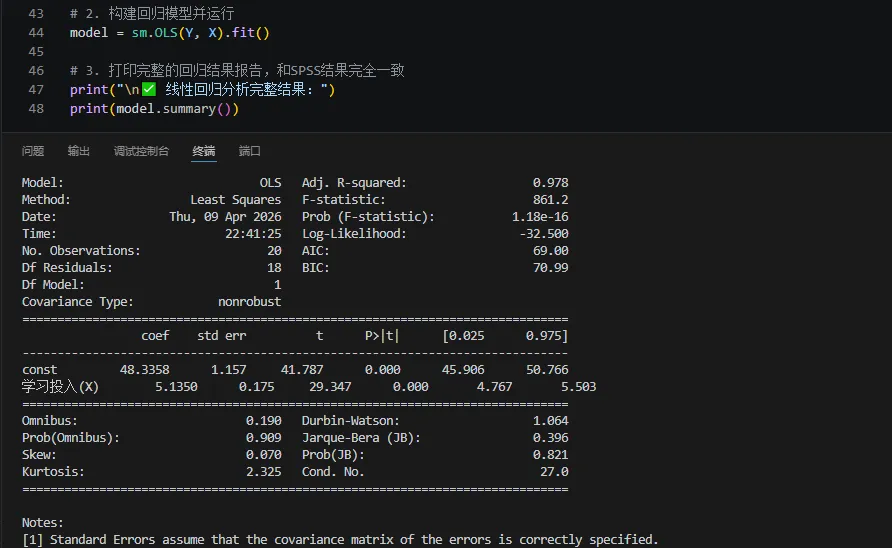
结果解读+ 论文写作模板和上一篇完全一致,小白直接套用,就能写出论文里的核心结果部分。
三、10天学习终极复盘
到今天为止,我们10 天的论文数据分析急救营就全部结束了!从最开始的「连p 值是什么都不知道」,到现在你已经能独立用 SPSS 和 Python,走完一篇本科毕业论文的全流程数据分析,甚至能做出可以卖给别人的工具,你已经超过了 80% 同届的毕业生!
给所有小白的终极毕业建议:
论文数据分析从来都不是什么难事,不用你懂复杂的统计学公式,只要你记住「万能流程」,找对对应的方法,照着步骤操作,就能搞定90%的毕业论文。
如果你不想自己写代码、不想自己点SPSS,我们的「零露论文数据分析工具」即将上线,9.9 元基础版就能一键搞定描述性统计、相关性分析、差异性检验,29.9 元完整版解锁全功能回归分析,还有保姆级教程和数据模板,小白闭眼就能用,帮你省下 3 天的改稿时间!清华大学数学科学系-东门
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- marimo:一个响应式的 Python 笔记本开发环境,集成了 SQL 查询、交互式 slider、表格浏览、图表渲染等
- Python指数月线回测系统,回测逻辑3种新写法
- 黑客视角的运维安全:这 7 个 Linux 服务器配置漏洞,你中招了吗?
- Linux命令大全-cut命令
- Python程序设计课程记录(一)
- 相关性分析(基于python)10——Fisher Z变换(2.26w字)
- 内存管理-第1章-Linux 内核内存管理概述
- 【重复测量纵向数据】Python13.广义相加模型(Generalized Additive Models,GAM)
- 与AI协作的"拉扯"式Python编程课程纲领创作 - AIPY编程系列 · 创作手记(二)
- Python必备的48个函数(入门速查手册)
