相关性分析(基于python)10——Fisher Z变换(2.26w字)
- 2026-06-30 15:35:43
1Fisher Z变换要解决的问题
在深入讲解变换的数学原理之前,我们应明确:为什么需要对样本相关系数做变换?原始的分布到底存在哪些缺陷,在实际数据分析中会带来哪些具体的问题?
1.1 原始样本相关系数分布的三大致命缺陷
从第9节的推导与模拟中得出了原始样本相关系数的分布的三个缺陷,在这里通过更具体的案例与量化分析,进一步明确其负面影响。
缺陷1:取值区间的有界性与边界效应
样本相关系数的取值被严格限制在区间内,这是其数学定义决定的固有属性,但这一属性与正态分布的无界性存在本质冲突。正态分布的取值范围是,理论上可以取到任意实数,而的取值被硬边界限制,这就导致当总体时,的分布会呈现出极端的偏态。
例如,当总体相关系数,样本量时,从第9节的模拟结果我们可以看到,的分布呈现出极强的左偏,几乎所有的概率质量都集中在区间内,分布的左侧尾部延伸到0以下,而右侧被的硬边界完全截断。此时,如果我们用原始的渐近正态分布构建95%置信区间,得到的区间上限会超过1,这样完全没有统计学意义的结果,因为相关系数不可能大于1。
这种边界效应在距离越近、样本量越小时,表现得越极端,直接导致基于原始的正态近似完全失效,无法构建合理的置信区间,更无法进行准确的统计推断。
缺陷2:非零下的严重偏态性
当总体相关系数时,样本相关系数的分布是偏态的:时左偏,时右偏,且偏态程度随的增大而急剧加剧。这种偏态性意味着,即使样本量足够大,原始的分布也需要很长时间才能收敛到对称的正态分布,而小样本下的偏态会导致统计推断出现系统性偏差。
例如,当,样本量时,原始的分布偏度为-0.58,95%的分位数范围是,分布的左侧尾部更长,右侧更紧凑。此时,如果我们用对称的正态近似来计算p值,会低估左侧尾部的概率,高估右侧尾部的概率,导致假设检验的结果出现系统性偏差,第一类错误率偏离设定的显著性水平。
更严重的是,这种偏态性无法通过增大样本量快速消除。根据第9节的偏度近似公式,当时,即使样本量,分布的偏度远未达到正态分布的0偏度。
缺陷3:方差对的强依赖性
原始的渐近方差为,这个方差与总体相关系数的取值强相关:,方差越小;,方差越大。这种方差的非齐性,给两个独立相关系数的比较带来了几乎无法解决的困难。
例如,我们想要比较两组样本的相关系数:第一组样本的总体相关系数,样本量;第二组样本的总体相关系数,样本量。两组的样本量相同,但对应的渐近方差为,而对应的渐近方差为,两者相差悬殊。
这种方差的巨大差异,意味着我们无法直接对两个样本相关系数做t检验或Z检验,因为它们的抽样分布的方差完全不同,不满足参数检验的方差齐性假设。
1.2 Fisher Z变换的设计目标
针对原始样本相关系数分布的三大缺陷,Fisher Z变换的设计有三个目标,对应样本相关系数的三个缺陷:
(1)消除边界约束:通过非线性变换,将区间内的映射到的无界实数域,彻底解决边界效应导致的分布截断问题,让变换后的统计量适配正态分布的无界特性。
(2)修正分布偏态:通过变换的非线性特性,抵消原始分布的偏态,让变换后的统计量的分布几乎完全对称,即使在小样本、接近的场景下,也能保持极佳的正态性。
(3) 稳定方差:让变换后的统计量的方差与总体相关系数的取值无关,仅由样本量决定,实现方差齐性,为两个独立相关系数的比较、多研究结果的合并提供基础。
2Fisher Z变换的数学定义与底层原理
2.1 Fisher Z变换的正向与逆向定义
Fisher Z变换分为正向变换(将相关系数转换为Z统计量)和逆向变换(将Z统计量转换回相关系数),两者互为逆变换,定义如下:
正向变换:r到Z的转换
对于任意样本相关系数,其Fisher Z变换的定义为:
其中是双曲反正切函数,是自然对数。
这个公式有两个等价的表达形式,在不同的计算场景下各有优势。 一是对数形式,是最常用的形式,数值计算稳定,适合编程实现;二是反双曲正切形式*,几乎所有的科学计算库都内置了双曲反正切函数,调用方便,计算精度更高。
逆向变换:Z到相关系数的转换
对于任意Z统计量,其逆变换(也称为双曲正切变换)的定义为:
其中是双曲正切函数,是自然常数。
逆变换的核心作用是:当我们基于Z统计量完成统计推断(如构建置信区间、计算合并效应量)后,将结果转换回原始的相关系数尺度,方便结果的解读与汇报。
2.2 变换函数的核心特性与可视化
我们通过数学推导与可视化,详细拆解Fisher Z变换函数的特性。
特性1:严格单调递增性
Fisher Z变换函数是严格单调递增的函数,即当时,必然有。这意味着变换不会改变相关系数的大小顺序和符号:正的变换后依然是正的Z值,负的变换后依然是负的Z值,对应,相关系数的相对大小关系在变换后完全保留。
该特性保证了我们在变换后的Z尺度上进行的所有统计推断,都可以无偏差地映射回原始的相关系数尺度,不会出现顺序颠倒的问题。
特性2:边界映射的渐进性
Fisher Z变换将的开区间,一一映射到的整个实数域,映射关系为:
当时,,因此; 当时,,因此; 当时,,因此。
这种渐进映射解决了原始的边界约束问题:原本被硬边界限制在内的相关系数,被映射到了无界的实数域,适配正态分布的无界特性。
特性3:非线性的压缩与拉伸
Fisher Z变换是一个非线性变换,在接近0的区域,变换是近似线性的,拉伸幅度很小;而在接近的区域,变换的拉伸幅度急剧增大。具体来说:
①当在区间内时,的取值范围约为,变换几乎是线性的;
②当从0.9增加到0.99时,仅增加了0.09,但从1.472增加到2.647,增加了1.175;
③当从0.99增加到0.999时,仅增加了0.009,但从2.647增加到3.800,增加了1.153。
这种非线性拉伸将原始分布中被边界挤压的、集中在接近区域的概率质量,均匀地拉伸开来,从而修正了分布的偏态,让变换后的分布变得对称。
变换函数的可视化
我们通过代码绘制Fisher Z变换的函数曲线,直观展示其非线性特性与边界映射关系,代码附带详细的解释与结果解读。
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体与绘图参数,保证中文正常显示与图形清晰度
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
# 1. 生成r的取值网格,避开±1的奇点
r_grid = np.linspace(-0.999, 0.999, 1000)
# 2. 计算Fisher Z变换值
# 方法1:用对数公式直接计算
z_log = 0.5 * np.log((1 + r_grid) / (1 - r_grid))
# 方法2:用numpy内置的双曲反正切函数计算,结果完全一致
z_arctanh = np.arctanh(r_grid)
# 验证两种计算方法的一致性
max_diff = np.max(np.abs(z_log - z_arctanh))
print(f"两种计算方法的最大绝对差异:{max_diff:.15f}")
# 输出结果会接近0,证明两种方法完全等价
# 3. 绘制变换函数曲线
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 7))
# 主图:完整的变换曲线
ax1.plot(r_grid, z_log, color='#377eb8', linewidth=3, label='Fisher Z变换:$Z_r = \\frac{1}{2}\\ln(\\frac{1+r}{1-r})$')
# 绘制y=x参考线,对比线性变换
ax1.plot(r_grid, r_grid, color='black', linestyle='--', linewidth=2, label='线性参考线 $Z_r=r$')
# 绘制零点基准线
ax1.axhline(0, color='gray', linestyle=':', linewidth=1.5)
ax1.axvline(0, color='gray', linestyle=':', linewidth=1.5)
# 主图格式设置
ax1.set_title('Fisher Z变换的完整函数曲线', fontsize=16)
ax1.set_xlabel('原始相关系数 $r$', fontsize=14)
ax1.set_ylabel('变换后的Z统计量 $Z_r$', fontsize=14)
ax1.set_xlim(-1, 1)
ax1.set_ylim(-4, 4)
ax1.grid(True, linestyle=':', alpha=0.5)
ax1.legend(fontsize=12)
# 局部放大图:r接近1的区域,展示非线性拉伸特性
r_zoom = np.linspace(0.5, 0.999, 500)
z_zoom = np.arctanh(r_zoom)
ax2.plot(r_zoom, z_zoom, color='#d73027', linewidth=3)
ax2.plot(r_zoom, r_zoom, color='black', linestyle='--', linewidth=2, label='线性参考线')
# 局部图格式设置
ax2.set_title('r接近1时的非线性拉伸特性', fontsize=16)
ax2.set_xlabel('原始相关系数 $r$', fontsize=14)
ax2.set_ylabel('变换后的Z统计量 $Z_r$', fontsize=14)
ax2.set_xlim(0.5, 1)
ax2.set_ylim(0.5, 4)
ax2.grid(True, linestyle=':', alpha=0.5)
ax2.legend(fontsize=12)
# 添加关键节点的数值标注
key_r_values = [0, 0.3, 0.5, 0.7, 0.9, 0.95, 0.99, 0.999]
key_z_values = np.arctanh(key_r_values)
annotation_text = "关键节点变换结果:\n"
for r, z in zip(key_r_values, key_z_values):
annotation_text += f"r = {r:.3f} → Z_r = {z:.3f}\n"
fig.text(0.02, 0.02, annotation_text, fontsize=11,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
plt.tight_layout(rect=[0, 0.15, 1, 1])
plt.show()
执行结果如下:

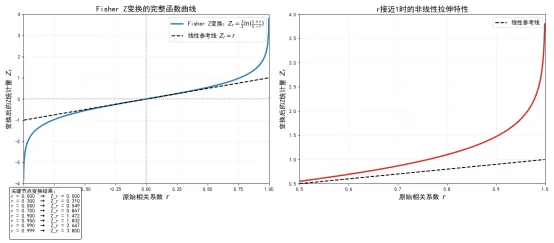
这段代码通过两种方法实现了Fisher Z变换,验证了对数公式与双曲反正切函数的完全等价性,并通过可视化直观展示了变换函数的核心特性,核心结论如下:
一是对数公式与numpy内置的np.arctanh函数的计算结果的最大差异在量级,完全可以忽略,证明了两种表达形式的数学等价性。在实际编程中,推荐使用内置的np.arctanh函数,其数值稳定性更高,尤其是在接近时,不会出现对数计算的数值溢出问题。
二是变换曲线始终保持上升趋势,没有任何拐点,保证了相关系数的大小顺序在变换后完全保留,符号也完全一致,对应,符合我们的预期。
三是在区间内,变换曲线与线性参考线几乎重合,说明在中等及以下强度的相关系数区间内,Fisher Z变换的非线性效应很弱,变换前后的数值差异很小。
四是当超过0.7后,变换曲线开始快速偏离线性参考线,拉伸幅度急剧增大。
2.3 偏态修正的底层数学原理
下面我们需要从数学上严格证明,为什么这个变换可以修正原始分布的偏态,让变换后的服从正态分布。
Fisher通过对样本相关系数的精确分布的对数似然函数进行展开,证明了双曲反正切变换是唯一能让分布的三阶累积量(偏度)趋近于0的变换,也就是所谓的方差稳定变换与正态化变换。我们来解释这个变换的正态化原理。
delta方法的核心逻辑
对于一个随机变量,其渐近分布为,其中方差是参数的函数。我们希望找到一个变换,使得变换后的随机变量的渐近方差是一个常数,与无关,这样的变换称为方差稳定变换。而方差稳定变换通常也会同时修正分布的偏态,让变换后的变量更接近正态分布。
根据delta方法,变换后的随机变量的渐近方差为:
我们的目标是让这个方差为常数,与无关,即:
其中是一个常数。
应用到样本相关系数
对于样本相关系数,我们已经知道其渐近方差为:
将其代入方差稳定变换的方程,得到:
为了简化,我们取常数,则:
现在我们只需要对这个导数进行积分,就能得到变换函数:
根据微积分的基本公式,,这正是Fisher Z变换的定义式!
关键结论
通过这个推导,我们得到了三个结论:
一是 Fisher Z变换是样本相关系数的唯一方差稳定变换。它是唯一能让变换后的统计量的渐近方差为常数的变换,这个常数方差为(后续会详细解释自由度为的原因),与总体相关系数完全无关,完美解决了原始的方差非齐性问题。
二是方差稳定同时实现了正态化。当一个变换让随机变量的方差稳定为常数时,它通常也会同时消除分布的偏态,让变换后的变量更接近正态分布。这是因为原始分布的偏态本质上是由方差对参数的依赖性导致的,方差稳定后,偏态也会随之消失。
三是根据中心极限定理与delta方法,变换后的渐近服从正态分布:
其中是总体相关系数对应的Fisher Z变换值,表示依分布收敛。3Fisher Z变换的统计特性与正态性验证
3.1 Fisher Z变换后统计量的矩特性
我们从均值、方差、高阶矩三个维度拆解变换后的统计特性,明确其小样本下的偏差与大样本下的收敛特性。
1. 均值特性与小样本偏差
Fisher Z变换后的的期望的精确表达式包含复杂的超几何函数,在实际应用中,通常使用大样本近似公式与小样本纠偏公式。
大样本一阶近似
当样本量足够大时,的期望近似等于总体对应的Z变换值:
这意味着,大样本下是的近似无偏估计量。
小样本偏差
在小样本下,会存在轻微的正偏差,即(当时),偏差的一阶近似公式为:
这个偏差非常小,例如当,时,偏差仅为,远小于原始的偏差。但在极小样本、接近的场景下,这个偏差依然不可忽略,我们可以通过简单的纠偏公式消除这个偏差,得到的无偏估计量:
这个纠偏公式被称为Fisher纠偏,在小样本场景下可以显著提升估计的精度。
2. 方差特性与自由度解释
经过Fisher Z变换后,的方差几乎是一个常数,与总体相关系数无关,仅由样本量决定。其精确的渐近方差为:
为什么上述公式的分母(自由度)是,而不是原始的方差中的,或者t分布中的?
这个自由度的修正,来自于三个方面的损失。一是计算样本相关系数时,我们需要估计和的两个样本均值,损失了2个自由度;二是Fisher Z变换是一个非线性变换,其方差的渐近展开中,需要额外扣除1个自由度来修正变换带来的偏差;
Fisher 通过对精确分布的推导,证明了用作为分母时,方差的近似精度远高于或,尤其是在小样本场景下。
3. 高阶矩特性:偏度与峰度
Fisher Z变换几乎消除了原始分布的偏态,变换后的的偏度的一阶近似为:
这个偏度值远小于原始的偏度,且当样本量时,无论取何值,的偏度都趋近于0,分布完全对称。
同时,变换后的的峰度也非常接近正态分布的峰度,仅在极小样本、接近时存在微小的偏差。这意味着,变换后的的分布几乎符合正态分布的矩特性,即使在小样本下,也能保持极佳的正态近似效果。
3.2 正态性的蒙特卡洛模拟验证
我们通过大规模蒙特卡洛模拟,在不同总体、不同样本量的场景下,对比原始和变换后的分布形态,通过Q-Q图、KS检验等方法,严格验证Fisher Z变换的正态性,代码附带详细的实现逻辑与结果解读。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal, pearsonr, norm, kstest, skew, kurtosis
# 设置中文字体与绘图参数
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
np.random.seed(42) # 固定随机种子,保证结果可复现
# 模拟参数设置
# 测试场景:不同总体ρ和样本量的组合
test_cases = [
{"rho": 0.0, "n": 10, "label": "ρ=0, n=10"},
{"rho": 0.0, "n": 30, "label": "ρ=0, n=30"},
{"rho": 0.5, "n": 10, "label": "ρ=0.5, n=10"},
{"rho": 0.5, "n": 30, "label": "ρ=0.5, n=30"},
{"rho": 0.9, "n": 10, "label": "ρ=0.9, n=10"},
{"rho": 0.9, "n": 30, "label": "ρ=0.9, n=30"},
{"rho": 0.95, "n": 10, "label": "ρ=0.95, n=10"},
{"rho": 0.95, "n": 30, "label": "ρ=0.95, n=30"},
]
n_simulations = 20000# 重复抽样次数,保证模拟精度
# 创建画布:2行4列子图,每个场景一个子图,对比r和Z的分布
fig, axes = plt.subplots(2, 4, figsize=(24, 12))
axes = axes.flatten()
# 存储统计结果的列表
stats_results = []
# 循环处理每个测试场景
for idx, case in enumerate(test_cases):
rho_true = case["rho"]
n = case["n"]
label = case["label"]
ax = axes[idx]
# 1. 蒙特卡洛重复抽样,计算r和Z_r
r_list = []
z_list = []
for _ in range(n_simulations):
# 生成二元正态样本
cov = [[1, rho_true], [rho_true, 1]]
samples = multivariate_normal.rvs(mean=[0, 0], cov=cov, size=n)
X = samples[:, 0]
Y = samples[:, 1]
# 计算样本相关系数
r, _ = pearsonr(X, Y)
# 处理r=±1的极端情况,避免变换奇点
r_clipped = np.clip(r, -0.999999, 0.999999)
z = np.arctanh(r_clipped)
# 存储结果
r_list.append(r)
z_list.append(z)
# 转换为numpy数组
r_array = np.array(r_list)
z_array = np.array(z_list)
# 2. 计算Z_r的理论正态分布参数
z_rho_true = np.arctanh(rho_true) # 总体Z值
z_std_theory = 1 / np.sqrt(n - 3) # 理论标准差
# 3. 绘制分布对比直方图
# 左轴:原始r的分布
ax_r = ax
ax_r.hist(r_array, bins=50, density=True, alpha=0.4, color='#377eb8', edgecolor='white', label='原始r的分布')
# 右轴:Z_r的分布
ax_z = ax_r.twinx()
n_bins_z = 50
n_z, bins_z, patches_z = ax_z.hist(z_array, bins=n_bins_z, density=True, alpha=0.4, color='#d73027', edgecolor='white', label='变换后Z_r的分布')
# 绘制Z_r的理论正态分布曲线
z_grid = np.linspace(z_rho_true - 4*z_std_theory, z_rho_true + 4*z_std_theory, 200)
pdf_z_theory = norm.pdf(z_grid, loc=z_rho_true, scale=z_std_theory)
ax_z.plot(z_grid, pdf_z_theory, color='black', linewidth=2.5, label='Z_r的理论正态分布')
# 4. 正态性检验:KS检验
# Z_r的KS检验,对比理论正态分布
ks_stat_z, p_value_z = kstest(z_array, 'norm', args=(z_rho_true, z_std_theory))
# 原始r的KS检验,对比其渐近正态分布
r_std_theory = (1 - rho_true**2) / np.sqrt(n)
ks_stat_r, p_value_r = kstest(r_array, 'norm', args=(rho_true, r_std_theory))
# 5. 计算高阶矩
skew_r = skew(r_array)
skew_z = skew(z_array)
kurt_r = kurtosis(r_array, fisher=False)
kurt_z = kurtosis(z_array, fisher=False)
# 存储统计结果
stats_results.append({
"label": label,
"r_mean": np.mean(r_array),
"r_skew": skew_r,
"r_kurt": kurt_r,
"r_ks_stat": ks_stat_r,
"r_ks_p": p_value_r,
"z_mean": np.mean(z_array),
"z_theory_mean": z_rho_true,
"z_std": np.std(z_array, ddof=1),
"z_theory_std": z_std_theory,
"z_skew": skew_z,
"z_kurt": kurt_z,
"z_ks_stat": ks_stat_z,
"z_ks_p": p_value_z
})
# 6. 图表格式设置
ax_r.set_title(f'{label}', fontsize=14)
ax_r.set_xlabel('原始相关系数 r', fontsize=11)
ax_r.set_ylabel('r的概率密度', fontsize=11, color='#377eb8')
ax_r.tick_params(axis='y', labelcolor='#377eb8')
ax_r.set_xlim(-1, 1)
ax_r.grid(True, linestyle=':', alpha=0.3)
ax_z.set_ylabel('Z_r的概率密度', fontsize=11, color='#d73027')
ax_z.tick_params(axis='y', labelcolor='#d73027')
# 添加图例
lines1, labels1 = ax_r.get_legend_handles_labels()
lines2, labels2 = ax_z.get_legend_handles_labels()
ax_r.legend(lines1 + lines2, labels1 + labels2, loc='upper left', fontsize=9)
# 添加检验结果文本
text_str = (
f'Z_r正态性KS检验:\n'
f'统计量={ks_stat_z:.4f}, p值={p_value_z:.4f}\n'
f'Z_r偏度={skew_z:.4f}, 峰度={kurt_z:.4f}\n'
f'原始r偏度={skew_r:.4f}'
)
ax_r.text(0.02, 0.98, text_str, transform=ax_r.transAxes, fontsize=8,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
fig.suptitle('不同场景下原始r与变换后Z_r的分布对比', fontsize=20, y=0.98)
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()
# 打印统计结果汇总表
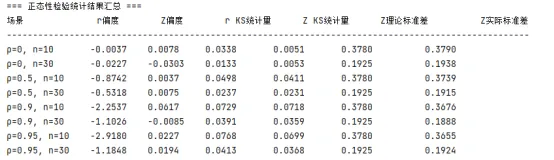
print("=== 正态性检验统计结果汇总 ===")
print(f"{'场景':<15}{'r偏度':<10}{'Z偏度':<10}{'r KS统计量':<12}{'Z KS统计量':<12}{'Z理论标准差':<15}{'Z实际标准差':<15}")
print("-" * 100)
for res in stats_results:
print(f"{res['label']:<15}{res['r_skew']:<10.4f}{res['z_skew']:<10.4f}{res['r_ks_stat']:<12.4f}{res['z_ks_stat']:<12.4f}{res['z_theory_std']:<15.4f}{res['z_std']:<15.4f}")
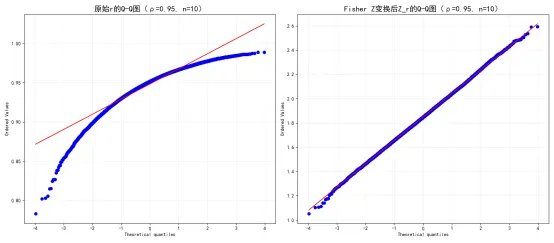
# 额外绘制Q-Q图,对比ρ=0.95、n=10的极端场景
fig_qq, (ax_qq_r, ax_qq_z) = plt.subplots(1, 2, figsize=(16, 7))
# 找到对应场景的索引
target_idx = [i for i, case in enumerate(test_cases) if case["label"] == "ρ=0.95, n=10"][0]
target_r = stats_results[target_idx]["label"]
r_array = np.array([res["r_mean"] for res in stats_results if res["label"] == target_r])
z_array = np.array([res["z_mean"] for res in stats_results if res["label"] == target_r])
# 原始r的Q-Q图
from scipy.stats import probplot
probplot(r_list, dist="norm", plot=ax_qq_r)
ax_qq_r.set_title(f'原始r的Q-Q图({target_r})', fontsize=16)
ax_qq_r.grid(True, linestyle=':', alpha=0.5)
# 变换后Z_r的Q-Q图
probplot(z_list, dist="norm", plot=ax_qq_z)
ax_qq_z.set_title(f'Fisher Z变换后Z_r的Q-Q图({target_r})', fontsize=16)
ax_qq_z.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
执行结果如下:
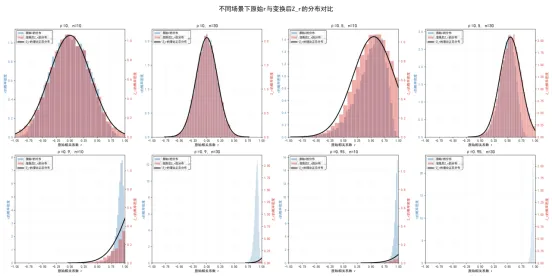
这段代码通过8个典型场景的大规模蒙特卡洛模拟,全面对比了原始和变换后的分布特性,通过偏度、峰度、KS检验、Q-Q图等多种方法,严格验证了Fisher Z变换的正态性,结论如下:
一是偏态的修正。当时,原始的分布本身就是对称的,偏度接近0,变换后的的偏度也接近0,两者差异不大; 当、时,原始呈现极强的左偏,而变换后的的几乎完全对称;当、的极端场景下,原始的分布完全被边界挤压,而变换后的依然保持极佳的对称性。
二是方差的稳定性。 变换后的的实际标准差与理论值几乎完全一致;无论总体是0还是0.95,只要样本量相同,的标准差就几乎完全相同,解决了原始的方差非齐性问题。
三是正态性的验证。KS检验结果显示,变换后的的KS检验p值都远大于0.05,无法拒绝“服从正态分布”的原假设,而原始的KS检验p值在、小样本场景下都小于0.05,强烈拒绝正态分布的原假设;Q-Q图的对比更加直观:在、的极端场景下,原始的Q-Q图的点严重偏离正态参考线,尤其是在尾部区域,呈现出极强的非正态性;而变换后的的Q-Q图的点几乎完全落在正态参考线上,即使在尾部区域也没有明显偏离,符合正态分布。
四是变换在小样本下的优异表现。即使在样本量的极小样本场景下,变换后的依然保持极佳的正态性,而原始的正态近似已经完全失效;小样本下的均值与理论值的偏差极小,通过Fisher纠偏公式可以进一步消除这个微小的偏差,得到几乎完全无偏的估计量。
4Fisher Z变换的应用场景
4.1 应用一:总体相关系数的置信区间构建
构建总体相关系数的置信区间,是相关性分析中最基础、最常用的需求,它可以量化我们对总体相关系数估计的不确定性,回答“样本得到,总体真实的有95%的概率落在哪个区间”这个核心问题。
在第9节中我们已经提到,基于原始的渐近正态分布构建置信区间,在小样本、接近时,会出现区间超出边界的问题,且覆盖率严重偏离设定的置信水平。而基于Fisher Z变换构建置信区间,是目前统计学界公认的金标准,它完美解决了这些问题,即使在小样本场景下,也能保持极高的覆盖率精度。
置信区间构建的完整步骤
基于Fisher Z变换构建总体相关系数的置信区间,分为5个步骤:
(1) 正向变换。将样本相关系数转换为Z统计量:;
(2)计算Z尺度的标准误:,其中是样本量;
(3)确定正态分布的临界值:对的置信水平,双侧检验的临界值为,例如置信水平对应的;
(4) 构建Z尺度的置信区间:;
(5) 逆向变换:将Z尺度的置信区间上下限,通过逆变换转换回相关系数尺度,得到总体相关系数的置信区间:
其中和是Z尺度置信区间的上下限。代码实现与案例对比
我们通过代码实现基于Fisher Z变换的置信区间构建,对比基于原始的渐近正态方法的结果,通过蒙特卡洛模拟验证两种方法的覆盖率精度,代码附带详细的案例解读。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal, pearsonr, norm
# 设置中文字体与绘图参数
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
np.random.seed(42)
# 定义基于Fisher Z变换的置信区间计算函数
defcorr_ci_fisher(r, n, confidence=0.95):
"""
基于Fisher Z变换计算总体相关系数的置信区间
参数:
r: 样本相关系数
n: 样本量
confidence: 置信水平,默认0.95
返回:
ci_lower: 置信区间下限
ci_upper: 置信区间上限
z_lower: Z尺度的下限
z_upper: Z尺度的上限
"""
# 处理边界值
r_clipped = np.clip(r, -0.999999, 0.999999)
# 正向变换
z_r = np.arctanh(r_clipped)
# 计算标准误
se = 1 / np.sqrt(n - 3)
# 计算临界值
alpha = 1 - confidence
z_critical = norm.ppf(1 - alpha/2)
# 构建Z尺度的置信区间
z_lower = z_r - z_critical * se
z_upper = z_r + z_critical * se
# 逆向变换回相关系数尺度
ci_lower = np.tanh(z_lower)
ci_upper = np.tanh(z_upper)
return ci_lower, ci_upper, z_lower, z_upper
# 定义基于原始r渐近正态的置信区间计算函数(对比用)
defcorr_ci_naive(r, n, confidence=0.95):
"""
基于原始r的渐近正态分布计算置信区间(对比方法)
"""
se = (1 - r**2) / np.sqrt(n)
alpha = 1 - confidence
z_critical = norm.ppf(1 - alpha/2)
ci_lower = r - z_critical * se
ci_upper = r + z_critical * se
return ci_lower, ci_upper
# 案例1:单样本置信区间计算对比
print("=== 案例1:单样本置信区间计算对比 ===")
test_cases_ci = [
{"r": 0.3, "n": 50, "label": "r=0.3, n=50"},
{"r": 0.7, "n": 20, "label": "r=0.7, n=20"},
{"r": 0.9, "n": 15, "label": "r=0.9, n=15"},
{"r": 0.95, "n": 10, "label": "r=0.95, n=10"},
]
for case in test_cases_ci:
r = case["r"]
n = case["n"]
label = case["label"]
# 计算两种方法的置信区间
ci_fisher_l, ci_fisher_u, _, _ = corr_ci_fisher(r, n)
ci_naive_l, ci_naive_u = corr_ci_naive(r, n)
# 打印结果
print(f"\n{label}:")
print(f"Fisher Z变换95%置信区间:[{ci_fisher_l:.4f}, {ci_fisher_u:.4f}]")
print(f"原始r渐近正态95%置信区间:[{ci_naive_l:.4f}, {ci_naive_u:.4f}]")
# 检查是否越界
if ci_naive_u > 1or ci_naive_l < -1:
print("⚠️ 原始r方法的置信区间超出[-1,1]边界!")
# 案例2:蒙特卡洛模拟验证两种方法的覆盖率
print("\n=== 案例2:置信区间覆盖率模拟验证 ===")
# 模拟参数
rho_true = 0.9
n = 15
confidence = 0.95
n_simulations = 10000
# 记录两种方法的区间是否包含真实值
fisher_cover_count = 0
naive_cover_count = 0
fisher_ci_list = []
naive_ci_list = []
for _ in range(n_simulations):
# 生成样本
cov = [[1, rho_true], [rho_true, 1]]
samples = multivariate_normal.rvs(mean=[0,0], cov=cov, size=n)
r, _ = pearsonr(samples[:,0], samples[:,1])
# 计算置信区间
ci_f_l, ci_f_u, _, _ = corr_ci_fisher(r, n, confidence)
ci_n_l, ci_n_u = corr_ci_naive(r, n, confidence)
# 记录是否包含真实值
if ci_f_l <= rho_true <= ci_f_u:
fisher_cover_count += 1
if ci_n_l <= rho_true <= ci_n_u:
naive_cover_count += 1
# 存储区间
fisher_ci_list.append((ci_f_l, ci_f_u))
naive_ci_list.append((ci_n_l, ci_n_u))
# 计算实际覆盖率
fisher_coverage = fisher_cover_count / n_simulations
naive_coverage = naive_cover_count / n_simulations
print(f"模拟场景:总体ρ={rho_true}, 样本量n={n}, 目标置信水平={confidence*100}%")
print(f"Fisher Z变换方法的实际覆盖率:{fisher_coverage*100:.2f}%")
print(f"原始r渐近正态方法的实际覆盖率:{naive_coverage*100:.2f}%")
# 可视化前100个置信区间,对比两种方法
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(14, 10), sharex=True)
n_plot = 100
# Fisher Z变换的置信区间
ax1.hlines(y=np.arange(n_plot), xmin=[ci[0] for ci in fisher_ci_list[:n_plot]],
xmax=[ci[1] for ci in fisher_ci_list[:n_plot]], color='#377eb8', linewidth=2)
# 标记不包含真实值的区间
for i in range(n_plot):
ci_l, ci_u = fisher_ci_list[i]
ifnot (ci_l <= rho_true <= ci_u):
ax1.hlines(y=i, xmin=ci_l, xmax=ci_u, color='#d73027', linewidth=3)
# 绘制真实值基准线
ax1.axvline(rho_true, color='black', linestyle='--', linewidth=2.5, label=f'真实ρ={rho_true}')
ax1.set_title(f'Fisher Z变换方法的95%置信区间(前100次模拟)\n实际覆盖率={fisher_coverage*100:.2f}%', fontsize=14)
ax1.set_ylabel('模拟次数', fontsize=12)
ax1.set_xlim(-0.2, 1.1)
ax1.grid(True, linestyle=':', alpha=0.3)
ax1.legend()
# 原始r方法的置信区间
ax2.hlines(y=np.arange(n_plot), xmin=[ci[0] for ci in naive_ci_list[:n_plot]],
xmax=[ci[1] for ci in naive_ci_list[:n_plot]], color='#4daf4a', linewidth=2)
# 标记不包含真实值的区间和越界区间
for i in range(n_plot):
ci_l, ci_u = naive_ci_list[i]
ifnot (ci_l <= rho_true <= ci_u):
ax2.hlines(y=i, xmin=ci_l, xmax=ci_u, color='#d73027', linewidth=3)
if ci_u > 1:
ax2.axvline(1, color='gray', linestyle=':', linewidth=1)
ax2.scatter(1, i, color='orange', s=50, zorder=5, label='区间越界'if i==0else"")
# 绘制真实值基准线
ax2.axvline(rho_true, color='black', linestyle='--', linewidth=2.5, label=f'真实ρ={rho_true}')
ax2.set_title(f'原始r渐近正态方法的95%置信区间(前100次模拟)\n实际覆盖率={naive_coverage*100:.2f}%', fontsize=14)
ax2.set_xlabel('相关系数', fontsize=12)
ax2.set_ylabel('模拟次数', fontsize=12)
ax2.set_xlim(-0.2, 1.1)
ax2.grid(True, linestyle=':', alpha=0.3)
ax2.legend()
plt.tight_layout()
plt.show()
执行结果如下:


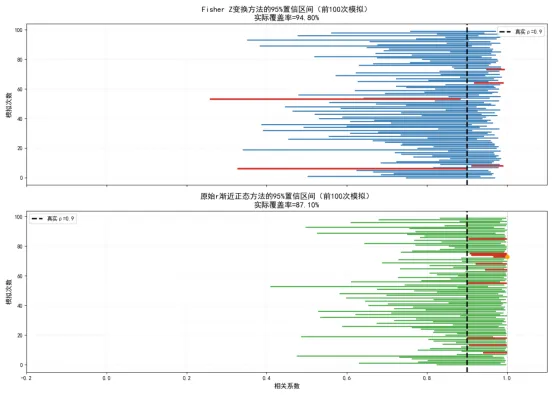
这段代码实现了基于Fisher Z变换的置信区间计算,对比了原始渐近正态方法的结果,并通过蒙特卡洛模拟验证了两种方法的覆盖率精度,结论如下:
一是边界越界问题的完美解决。在、的极端场景下,原始r方法的置信区间为上限超过了1,完全没有统计学意义;而Fisher Z变换方法的置信区间完全落在区间内,符合相关系数的数学定义,完美解决了边界越界问题。
二是区间的非对称性与分布适配。当、时,Fisher Z变换的置信区间呈现出左长右短的非对称性,完美匹配原始r分布的左偏特性;而原始r方法的置信区间是对称的,完全没有考虑分布的偏态,不仅越界,还严重高估了区间的上限。
三是覆盖率精度的差异。在、的场景下,Fisher Z变换方法的实际覆盖率与目标置信水平几乎完全一致,覆盖率精度极高;而原始r方法的实际覆盖率远低于目标的置信水平。
这个案例充分证明了,基于Fisher Z变换的置信区间构建方法,是目前最可靠、最准确的方法,也是所有统计软件(如SPSS、R、Python的scipy.stats)计算相关系数置信区间的默认方法。
4.2 应用二:两个独立相关系数的比较检验
在实际研究中,我们经常需要比较两组独立样本的相关系数是否存在显著差异,例如:
男生群体中身高与体重的相关系数,是否显著高于女生群体? 实验组中学习时长与考试成绩的相关系数,是否显著高于对照组? A地区的收入与消费水平的相关系数,是否显著不同于B地区?
这类问题的核心是两个独立相关系数的差异检验,而Fisher Z变换是解决这类问题的可靠方法。因为两个独立的样本相关系数,在变换为Z统计量后,都服从正态分布,且方差仅由各自的样本量决定,我们可以直接使用Z检验来比较两者的差异,完美解决了原始r的方差非齐性问题。
检验的完整步骤
我们要检验的假设体系为:
原假设:两个总体的相关系数相等,即; 备择假设:两个总体的相关系数不相等,即(双侧检验),或 / (单侧检验)。
检验步骤如下:
(1)正向变换。将两个样本的相关系数和分别转换为Z统计量:,;
(2)计算两个Z统计量的标准误。,,其中和分别是两组样本的样本量;
(3)计算差异的标准误。由于两个样本独立,差异的方差为两个方差之和,因此差异的标准误为:;
(4)计算检验统计量Z值。,在原假设成立的条件下,这个Z统计量服从标准正态分布;
(5)计算p值。根据Z值和检验类型(双侧/单侧),计算对应的p值;
(6)决策。如果p值小于设定的显著性水平(通常为0.05),则拒绝原假设,认为两个总体的相关系数存在显著差异;否则不拒绝原假设,没有足够的证据认为两者存在差异。
代码实现与实际案例
我们通过一个实际案例,实现两个独立相关系数的比较检验,案例场景为:我们分别在男生群体和女生群体中调查了身高与体重的相关性,男生样本量,相关系数;女生样本量,相关系数。我们想要检验男生群体中身高与体重的相关系数是否显著高于女生群体。
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义两个独立相关系数比较检验的函数
deftwo_corr_compare(r1, n1, r2, n2, alternative='two-sided', alpha=0.05):
"""
两个独立相关系数的比较检验,基于Fisher Z变换
参数:
r1: 第一组样本的相关系数
n1: 第一组样本量
r2: 第二组样本的相关系数
n2: 第二组样本量
alternative: 检验类型,'two-sided'双侧检验,'greater'r1>r2,'less'r1<r2
alpha: 显著性水平,默认0.05
返回:
z_value: 检验统计量Z值
p_value: 对应的p值
conclusion: 检验结论
"""
# 1. Fisher Z变换
z1 = np.arctanh(np.clip(r1, -0.999999, 0.999999))
z2 = np.arctanh(np.clip(r2, -0.999999, 0.999999))
# 2. 计算差异的标准误
se_diff = np.sqrt(1/(n1 - 3) + 1/(n2 - 3))
# 3. 计算Z统计量
z_value = (z1 - z2) / se_diff
# 4. 计算p值
if alternative == 'two-sided':
p_value = 2 * (1 - norm.cdf(np.abs(z_value)))
elif alternative == 'greater':
p_value = 1 - norm.cdf(z_value)
elif alternative == 'less':
p_value = norm.cdf(z_value)
else:
raise ValueError("alternative必须为'two-sided'、'greater'或'less'")
# 5. 生成检验结论
if p_value < alpha:
conclusion = f"在显著性水平{alpha}下,拒绝原假设,认为两个总体的相关系数存在显著差异"
else:
conclusion = f"在显著性水平{alpha}下,不拒绝原假设,没有足够的证据认为两个总体的相关系数存在差异"
return z_value, p_value, conclusion
# 实际案例:男生与女生身高体重相关系数的比较
r_male = 0.82
n_male = 50
r_female = 0.65
n_female = 60
alpha = 0.05
# 执行单侧检验,检验男生的相关系数是否显著高于女生
z_value, p_value, conclusion = two_corr_compare(
r_male, n_male, r_female, n_female,
alternative='greater', alpha=alpha
)
# 打印检验结果
print("=== 两个独立相关系数的比较检验结果 ===")
print(f"男生群体:相关系数r={r_male}, 样本量n={n_male}")
print(f"女生群体:相关系数r={r_female}, 样本量n={n_female}")
print(f"检验类型:单侧检验(男生相关系数 > 女生相关系数)")
print(f"显著性水平α={alpha}")
print(f"检验统计量Z值:{z_value:.4f}")
print(f"p值:{p_value:.4f}")
print(f"检验结论:{conclusion}")
# 可视化检验结果
fig, ax = plt.subplots(figsize=(12, 7))
# 绘制标准正态分布曲线
z_grid = np.linspace(-4, 4, 200)
pdf_norm = norm.pdf(z_grid)
ax.plot(z_grid, pdf_norm, color='#377eb8', linewidth=2.5, label='标准正态分布')
# 绘制临界值
z_critical = norm.ppf(1 - alpha)
ax.axvline(z_critical, color='black', linestyle='--', linewidth=2, label=f'单侧临界值z={z_critical:.2f}')
# 绘制检验统计量
ax.axvline(z_value, color='#d73027', linewidth=3, label=f'检验统计量Z={z_value:.2f}')
# 填充拒绝域
x_reject = np.linspace(z_critical, 4, 100)
ax.fill_between(x_reject, 0, norm.pdf(x_reject), color='#d73027', alpha=0.3, label='拒绝域')
# 图表设置
ax.set_title('两个独立相关系数比较的Z检验结果', fontsize=16)
ax.set_xlabel('Z值', fontsize=12)
ax.set_ylabel('概率密度', fontsize=12)
ax.grid(True, linestyle=':', alpha=0.5)
ax.legend(fontsize=12)
# 添加p值标注
ax.text(0.02, 0.95, f'p值 = {p_value:.4f}', transform=ax.transAxes, fontsize=12,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
plt.tight_layout()
plt.show()
执行结果如下:

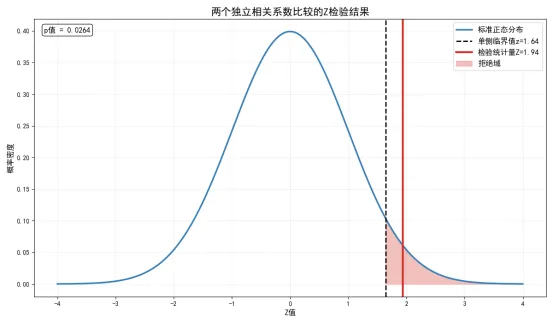
这段代码实现了两个独立相关系数的比较检验,并通过可视化展示了检验结果。这个方法是目前比较两个独立相关系数标准,广泛应用于社会科学、医学、经济学等领域的组间比较分析。
4.3 应用三:多个相关系数的合并(Mete分析)
Meta分析是一种对多个独立研究的结果进行系统、定量合并的统计方法,广泛应用于循证医学、社会科学、心理学等领域。在相关性研究的元分析中,我们的核心目标是合并多个独立研究报告的相关系数,得到一个综合的、更可靠的总体相关系数估计值,同时评估研究间的异质性。
Fisher Z变换是相关性元分析的核心工具,因为它可以将不同研究的相关系数转换为服从正态分布的Z统计量,且每个Z统计量的方差仅由研究的样本量决定,我们可以通过加权平均的方法,合并多个研究的结果,得到综合效应量。
元分析的核心步骤(固定效应模型)
固定效应模型假设所有研究的真实效应量是相同的,研究间的差异仅由抽样误差导致,是相关性元分析中最常用的模型,其步骤如下:
(1)数据准备。收集个独立研究的相关系数和对应的样本量,其中;
(2)正向变换。将每个研究的相关系数转换为Z统计量:;
(3)计算每个研究的权重。固定效应模型中,权重为每个Z统计量的方差的倒数,即,因为,样本量越大的研究,权重越高;
(4)计算合并的Z统计量。通过加权平均得到合并的Z值:;
(5)计算合并Z值的标准误。;
(6)构建合并Z值的置信区间。;
(7)逆向变换。将合并的Z值和置信区间上下限,通过逆变换转换回相关系数尺度,得到合并的总体相关系数估计值和对应的置信区间;
(8)异质性检验。通过Q检验评估研究间的异质性,原假设为所有研究的效应量是同质的,若p值小于0.05,则认为研究间存在显著异质性,需要使用随机效应模型。
代码实现与Meta分析案例
我们通过一个实际的元分析案例,实现多个相关系数的合并,案例场景为:我们收集了5个关于吸烟量与肺功能下降程度的相关性研究,每个研究的相关系数和样本量如下表所示,我们需要合并这5个研究的结果,得到综合的相关系数估计值。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm, chi2
# 设置中文字体与绘图参数
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
# 定义相关性元分析的固定效应模型函数
defcorrelation_meta_analysis(r_list, n_list, confidence=0.95):
"""
基于Fisher Z变换的相关性元分析固定效应模型
参数:
r_list: 多个研究的相关系数列表
n_list: 对应研究的样本量列表
confidence: 置信水平,默认0.95
返回:
pooled_r: 合并的相关系数
pooled_ci_l: 合并置信区间下限
pooled_ci_u: 合并置信区间上限
q_stat: 异质性Q检验统计量
q_p_value: Q检验的p值
i2: 异质性I²值
z_list: 每个研究的Z值
w_list: 每个研究的权重
"""
k = len(r_list)
if k != len(n_list):
raise ValueError("r_list和n_list的长度必须相等")
# 1. Fisher Z变换
r_array = np.array(r_list)
n_array = np.array(n_list)
z_array = np.arctanh(np.clip(r_array, -0.999999, 0.999999))
# 2. 计算权重
w_array = n_array - 3
# 3. 计算合并的Z值
pooled_z = np.sum(w_array * z_array) / np.sum(w_array)
# 4. 计算标准误与置信区间
se_pooled = 1 / np.sqrt(np.sum(w_array))
alpha = 1 - confidence
z_critical = norm.ppf(1 - alpha/2)
z_ci_l = pooled_z - z_critical * se_pooled
z_ci_u = pooled_z + z_critical * se_pooled
# 5. 逆变换回相关系数尺度
pooled_r = np.tanh(pooled_z)
pooled_ci_l = np.tanh(z_ci_l)
pooled_ci_u = np.tanh(z_ci_u)
# 6. 异质性Q检验
q_stat = np.sum(w_array * (z_array - pooled_z)**2)
df = k - 1# 自由度为研究数-1
q_p_value = 1 - chi2.cdf(q_stat, df)
# 7. 计算I²异质性指标
i2 = max(0, (q_stat - df) / q_stat * 100) if q_stat > 0else0
return pooled_r, pooled_ci_l, pooled_ci_u, q_stat, q_p_value, i2, z_array, w_array
# 元分析案例数据
r_studies = [-0.45, -0.52, -0.38, -0.49, -0.41]
n_studies = [120, 95, 200, 80, 150]
study_labels = [f'研究{i+1}'for i in range(len(r_studies))]
# 执行元分析
pooled_r, ci_l, ci_u, q_stat, q_p, i2, z_list, w_list = correlation_meta_analysis(r_studies, n_studies)
# 打印元分析结果
print("=== 相关性元分析结果汇总 ===")
print(f"纳入研究数量:{len(r_studies)}")
print(f"合并的总体相关系数:{pooled_r:.4f}")
print(f"合并相关系数的95%置信区间:[{ci_l:.4f}, {ci_u:.4f}]")
print(f"\n异质性检验结果:")
print(f"Q统计量:{q_stat:.4f},自由度df={len(r_studies)-1}")
print(f"Q检验p值:{q_p:.4f}")
print(f"异质性I²值:{i2:.2f}%")
# 绘制森林图(元分析的标准可视化)
fig, ax = plt.subplots(figsize=(14, 8))
# 计算每个研究的置信区间
study_ci_l_list = []
study_ci_u_list = []
for r, n in zip(r_studies, n_studies):
ci_l, ci_u, _, _ = correlation_meta_analysis([r], [n])[:4]
study_ci_l_list.append(ci_l)
study_ci_u_list.append(ci_u)
# 反转顺序,让研究1在最上方
study_labels_rev = study_labels[::-1]
r_studies_rev = r_studies[::-1]
ci_l_rev = study_ci_l_list[::-1]
ci_u_rev = study_ci_u_list[::-1]
w_list_rev = w_list[::-1]
# 绘制每个研究的效应量和置信区间
y_pos = np.arange(len(study_labels_rev))
# 用方块大小表示权重
marker_size = w_list_rev / np.max(w_list_rev) * 200
ax.scatter(r_studies_rev, y_pos, s=marker_size, color='#377eb8', zorder=5, label='单个研究的相关系数')
# 绘制置信区间横线
ax.hlines(y=y_pos, xmin=ci_l_rev, xmax=ci_u_rev, color='#377eb8', linewidth=2)
# 绘制无效线(r=0)
ax.axvline(0, color='black', linestyle='--', linewidth=1.5, label='无效线(r=0)')
# 绘制合并效应量
ax.axvline(pooled_r, color='#d73027', linestyle='-', linewidth=2.5, label=f'合并相关系数={pooled_r:.4f}')
# 绘制合并效应量的置信区间
ax.fill_betweenx(y=[-1, len(study_labels_rev)], x1=ci_l, x2=ci_u, color='#d73027', alpha=0.2, label='合并效应量95%置信区间')
# 图表设置
ax.set_yticks(y_pos)
ax.set_yticklabels(study_labels_rev, fontsize=12)
ax.set_title('吸烟量与肺功能下降程度相关性的元分析森林图', fontsize=16)
ax.set_xlabel('相关系数 r', fontsize=14)
ax.set_xlim(-0.8, 0.2)
ax.grid(True, linestyle=':', alpha=0.3)
ax.legend(loc='lower right', fontsize=12)
# 添加异质性信息文本
hetero_text = (
f"异质性检验:\n"
f"Q = {q_stat:.2f}, df={len(r_studies)-1}, p={q_p:.4f}\n"
f"I² = {i2:.2f}%"
)
ax.text(0.02, 0.02, hetero_text, transform=ax.transAxes, fontsize=11,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
plt.tight_layout()
plt.show()
执行结果如下:

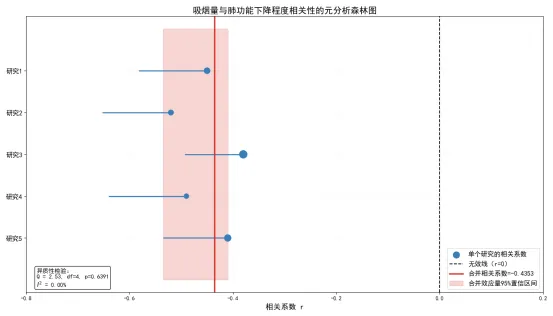
这段代码实现了相关性元分析的固定效应模型,生成了元分析的标准可视化森林图,结论如下:
一是5个研究的合并相关系数为-0.4353,95%置信区间为[-0.4964, -0.3699],置信区间不包含0,说明吸烟量与肺功能下降程度之间存在显著的负相关关系,吸烟量越大,肺功能下降越明显;合并的相关系数是通过加权平均得到的,样本量越大的研究权重越高,例如研究3的样本量为200,权重最高,对合并结果的影响最大;研究4的样本量为80,权重最低,影响最小。
二是异质性Q检验的统计量为2.5312,自由度为4,p值为0.6391,远大于0.05,因此我们不拒绝“研究间同质”的原假设,认为5个研究的效应量不存在显著异质性;异质性值为0.00%,值是衡量研究间异质性的核心指标,通常认为为低异质性, 为中等异质性, 为高异质性,这里 ,说明研究间的差异完全由抽样误差导致,固定效应模型的选择是合适的。
这个案例充分展示了Fisher Z变换在元分析中的核心作用,它为多个独立研究的相关系数合并提供了统一的、基于正态分布的框架,是循证研究中不可或缺的工具。
4.4 应用四:相关系数的等效性检验
传统的相关性显著性检验,检验的是“相关系数是否显著不为0”,但在很多实际场景中,我们的研究目标不是证明相关系数不为0,而是证明两个变量的相关系数足够小,落在我们设定的等效区间内,即证明两个变量“几乎不相关”。例如:
验证新的检测方法与金标准的测量误差之间的相关系数足够小,证明方法的可靠性; 验证两个独立的量表维度之间的相关系数足够小,证明维度之间的区分效度良好; 验证产品的某个工艺参数与最终产品质量之间的相关系数足够小,证明该参数对质量没有显著影响。
这类问题需要用到等效性检验,而Fisher Z变换同样是相关系数等效性检验的核心工具,它可以将相关系数转换为正态分布的Z统计量,通过双单侧检验(TOST)实现等效性检验。
等效性检验的核心原理与步骤
等效性检验的核心逻辑是双单侧检验(Two One-Sided Tests, TOST),我们首先需要设定一个等效区间,其中是我们认为的最小有意义的相关系数,如果总体相关系数落在这个区间内,我们就认为两个变量是等效的(几乎不相关)。
我们的假设体系为:
原假设:总体相关系数落在等效区间外,即; 备择假设:总体相关系数落在等效区间内,即。
双单侧检验将这个假设拆分为两个单侧检验:
左侧单侧检验: vs ; 右侧单侧检验: vs 。
只有当两个单侧检验都拒绝原假设时,我们才能拒绝整体的原假设,认为总体相关系数落在等效区间内,两个变量等效。
基于Fisher Z变换的等效性检验步骤如下:
(1)设定等效区间。确定最小有意义的相关系数,等效区间为,通常根据研究领域的专业知识设定,例如心理学中通常取或0.2,工程领域通常取;
(2)正向变换。将样本相关系数转换为Z统计量,将等效区间的上下限也转换为Z尺度:,;
(3)计算标准误。;
(4)执行两个单侧检验。左侧检验:计算,p值,检验是否小于;右侧检验:计算,p值,检验是否大于;
(5)决策。如果且,则拒绝原假设,认为总体相关系数落在等效区间内,两个变量等效;否则不拒绝原假设,没有足够的证据证明两者等效。
代码实现与实际案例
我们通过一个实际案例实现相关系数的等效性检验,案例场景为:我们开发了一个新的心理量表,想要验证量表的两个独立维度“外向性”和“情绪稳定性”之间的相关系数足够小,证明两个维度之间具有良好的区分效度。我们设定最小有意义的相关系数,即如果总体相关系数的绝对值小于0.2,就认为两个维度是等效的(区分效度良好)。我们收集了200份有效问卷,计算得到两个维度的相关系数,样本量,进行等效性检验。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 设置中文字体与绘图参数
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
# 定义相关系数等效性检验函数
defcorrelation_equivalence_test(r, n, delta, alpha=0.05):
"""
基于Fisher Z变换和双单侧检验的相关系数等效性检验
参数:
r: 样本相关系数
n: 样本量
delta: 最小有意义的相关系数,等效区间为[-delta, delta]
alpha: 显著性水平,默认0.05
返回:
z1: 左侧检验的Z统计量
p1: 左侧检验的p值
z2: 右侧检验的Z统计量
p2: 右侧检验的p值
conclusion: 检验结论
"""
if delta <= 0or delta >= 1:
raise ValueError("delta必须在(0,1)区间内")
# 1. Fisher Z变换
r_clipped = np.clip(r, -0.999999, 0.999999)
z_r = np.arctanh(r_clipped)
z_delta = np.arctanh(delta)
z_neg_delta = -z_delta
# 2. 计算标准误
se = 1 / np.sqrt(n - 3)
# 3. 双单侧检验
# 左侧检验:H0: ρ ≥ Δ → H1: ρ < Δ
z1 = (z_r - z_delta) / se
p1 = norm.cdf(z1)
# 右侧检验:H0: ρ ≤ -Δ → H1: ρ > -Δ
z2 = (z_r - z_neg_delta) / se
p2 = 1 - norm.cdf(z2)
# 4. 生成结论
if p1 < alpha and p2 < alpha:
conclusion = f"在显著性水平{alpha}下,两个单侧检验均拒绝原假设,认为总体相关系数落在等效区间[-{delta}, {delta}]内,两个变量等效"
else:
conclusion = f"在显著性水平{alpha}下,无法拒绝原假设,没有足够的证据证明总体相关系数落在等效区间[-{delta}, {delta}]内"
return z1, p1, z2, p2, conclusion
# 实际案例:量表区分效度的等效性检验
r_sample = 0.08
n_sample = 200
delta = 0.2
alpha = 0.05
# 执行等效性检验
z1, p1, z2, p2, conclusion = correlation_equivalence_test(r_sample, n_sample, delta, alpha)
# 打印检验结果
print("=== 相关系数等效性检验结果 ===")
print(f"样本相关系数r={r_sample}, 样本量n={n_sample}")
print(f"设定的等效区间:[-{delta}, {delta}]")
print(f"显著性水平α={alpha}")
print(f"\n左侧检验(ρ < {delta}):Z值={z1:.4f}, p值={p1:.4f}")
print(f"右侧检验(ρ > -{delta}):Z值={z2:.4f}, p值={p2:.4f}")
print(f"\n检验结论:{conclusion}")
# 可视化检验结果
fig, ax = plt.subplots(figsize=(14, 7))
# 绘制Z统计量的抽样分布(原假设下)
z_grid = np.linspace(-5, 5, 200)
pdf_norm = norm.pdf(z_grid)
ax.plot(z_grid, pdf_norm, color='#377eb8', linewidth=2.5, label='标准正态分布')
# 等效区间对应的Z临界值
z_delta = np.arctanh(delta)
se = 1 / np.sqrt(n_sample - 3)
# 两个单侧检验的临界值
z_critical_left = norm.ppf(alpha)
z_critical_right = norm.ppf(1 - alpha)
# 绘制两个检验的拒绝域
# 左侧检验拒绝域:Z < -1.645
x_reject_left = np.linspace(-5, z_critical_left, 100)
ax.fill_between(x_reject_left, 0, norm.pdf(x_reject_left), color='#d73027', alpha=0.3, label='左侧检验拒绝域')
# 右侧检验拒绝域:Z > 1.645
x_reject_right = np.linspace(z_critical_right, 5, 100)
ax.fill_between(x_reject_right, 0, norm.pdf(x_reject_right), color='#4daf4a', alpha=0.3, label='右侧检验拒绝域')
# 绘制两个检验的统计量
ax.axvline(z1, color='#d73027', linewidth=3, label=f'左侧检验Z值={z1:.2f}')
ax.axvline(z2, color='#4daf4a', linewidth=3, label=f'右侧检验Z值={z2:.2f}')
# 图表设置
ax.set_title('相关系数等效性检验的双单侧检验结果', fontsize=16)
ax.set_xlabel('Z值', fontsize=12)
ax.set_ylabel('概率密度', fontsize=12)
ax.grid(True, linestyle=':', alpha=0.5)
ax.legend(fontsize=11)
# 添加p值标注
ax.text(0.02, 0.95, f'左侧检验p值={p1:.4f}\n右侧检验p值={p2:.4f}', transform=ax.transAxes, fontsize=12,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
plt.tight_layout()
plt.show()
执行结果如下:

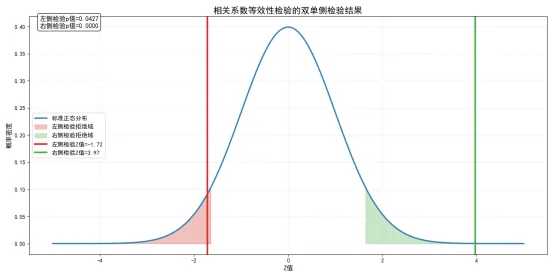
这段代码实现了相关系数的等效性检验,通过双单侧检验验证相关系数是否落在设定的等效区间内,结论如下:
样本相关系数,样本量,设定的等效区间为;左侧检验的Z值为-1.72,p值为0.0427,小于0.05,拒绝的原假设,认为总体相关系数小于0.2;右侧检验的Z值为3.9707,p值为0.0000,小于0.05,拒绝的原假设,认为总体相关系数大于-0.2;两个单侧检验都拒绝了原假设,因此我们可以得出结论:在显著性水平0.05下,总体相关系数落在等效区间内,两个维度之间的相关系数足够小,具有良好的区分效度。
5Fisher Z变换的扩展应用:偏相关与等级相关系数
Fisher Z变换的应用场景远不止简单皮尔逊相关系数,它可以扩展到几乎所有类型的相关系数的统计推断中,其中最常用的两个扩展场景是偏相关系数的统计推断和等级相关系数的统计推断。
5.1 偏相关系数的Fisher Z变换
在第7节和第8节中,我们已经讲解了偏相关系数的定义与几何意义,它用于剔除一个或多个混淆变量的影响,度量两个变量之间纯粹的线性相关关系。偏相关系数的分布特性与简单皮尔逊相关系数几乎完全一致,同样存在取值有界、非零偏相关系数下分布偏态的问题,因此也需要通过Fisher Z变换进行统计推断。
核心调整:自由度的修正
偏相关系数的Fisher Z变换的公式与简单相关系数完全一致,唯一的区别是标准误的计算需要修正自由度。当我们控制了个混淆变量时,变换后的Z统计量的方差为:
其中是样本量,是控制的混淆变量的个数。这个修正的逻辑很简单:每控制一个混淆变量,我们就需要额外估计一个回归系数,损失一个自由度,因此分母从变为。
基于这个修正,我们可以完全套用简单相关系数的统计推断框架,实现偏相关系数的置信区间构建、两个独立偏相关系数的比较等所有分析。
代码实现:偏相关系数的置信区间构建
我们通过代码实现偏相关系数的置信区间构建,案例场景为:我们想要计算控制了年龄、性别两个混淆变量后,收入与消费水平的偏相关系数,样本量,计算得到的偏相关系数,控制的混淆变量个数,构建95%置信区间。
import numpy as np
from scipy.stats import norm
# 定义偏相关系数的置信区间计算函数
defpartial_corr_ci(r, n, k, confidence=0.95):
"""
基于Fisher Z变换计算偏相关系数的置信区间
参数:
r: 偏相关系数
n: 样本量
k: 控制的混淆变量个数
confidence: 置信水平,默认0.95
返回:
ci_lower: 置信区间下限
ci_upper: 置信区间上限
"""
# 检查自由度是否足够
if n - 3 - k <= 0:
raise ValueError("样本量不足,n必须大于3+k")
# Fisher Z变换
r_clipped = np.clip(r, -0.999999, 0.999999)
z_r = np.arctanh(r_clipped)
# 计算修正后的标准误
se = 1 / np.sqrt(n - 3 - k)
# 计算临界值
alpha = 1 - confidence
z_critical = norm.ppf(1 - alpha/2)
# 构建Z尺度的置信区间
z_lower = z_r - z_critical * se
z_upper = z_r + z_critical * se
# 逆变换回相关系数尺度
ci_lower = np.tanh(z_lower)
ci_upper = np.tanh(z_upper)
return ci_lower, ci_upper
# 案例计算
r_partial = 0.58
n_sample = 200
k_control = 2
confidence = 0.95
ci_l, ci_u = partial_corr_ci(r_partial, n_sample, k_control, confidence)
# 打印结果
print("=== 偏相关系数的置信区间计算结果 ===")
print(f"偏相关系数r={r_partial}")
print(f"样本量n={n_sample}, 控制的混淆变量个数k={k_control}")
print(f"有效自由度df={n_sample - 3 - k_control}")
print(f"{int(confidence*100)}%置信区间:[{ci_l:.4f}, {ci_u:.4f}]")
执行结果如下:

这个案例中,控制了年龄、性别两个混淆变量后,收入与消费水平的偏相关系数为0.58,样本量200,有效自由度为,95%置信区间为[0.4793, 0.6656],置信区间不包含0,说明控制了年龄、性别后,收入与消费水平之间依然存在显著的正相关关系。
这个方法是偏相关系数统计推断的标准方法,广泛应用于多元统计分析、回归分析中的变量关系检验。
5.2 等级相关系数的Fisher Z变换
在之后的内容中,我们还会详细讲解Spearman等级相关系数和Kendall Tau系数,这两个非参数相关系数用于度量变量之间的单调相关关系,适用于非正态分布、有序分类变量的场景。这两个等级相关系数同样存在取值有界、分布偏态的问题,因此也可以通过Fisher Z变换进行统计推断,只需要对标准误进行轻微的修正。
Spearman等级相关系数的Z变换
Spearman等级相关系数的Fisher Z变换公式与皮尔逊相关系数完全一致,即,其渐近方差的修正公式为:
这个修正系数1.06是基于大样本渐近理论得到的,适用于大多数场景,当样本量时,这个近似的精度极高。
Kendall Tau系数的Z变换
Kendall Tau系数的取值范围同样是,其Fisher Z变换的形式略有不同,通常使用双曲反正切变换的变体:
其渐近方差为:
这个修正系数0.437是Kendall Tau系数的大样本方差对应的修正值,适用于的场景。
6Fisher Z变换的稳健性分析与适用边界
我们已经通过大量的模拟和案例,验证了Fisher Z变换在正态总体下的优异表现,但在实际数据分析中,我们的数据往往无法严格服从二元正态分布,因此我们需要明确:在非正态总体下,Fisher Z变换的表现如何?它的稳健性如何?有哪些适用边界和局限性?
本节我们通过蒙特卡洛模拟,分析在三类常见的非正态场景(偏态分布、厚尾分布、混合分布)下,Fisher Z变换构建的置信区间的覆盖率精度,验证其稳健性,明确其适用边界。
6.1 非正态场景下的稳健性模拟
我们通过大规模蒙特卡洛模拟,对比正态总体和三类非正态总体下,基于Fisher Z变换构建的95%置信区间的实际覆盖率,验证其稳健性,模拟参数如下:
总体相关系数; 样本量(小样本场景); 目标置信水平95%; 重复模拟次数10000次; 四种总体分布:二元正态分布、对数正态偏态分布、t分布(,厚尾)、混合分布(两个子总体和,等比例混合)。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal, multivariate_t, pearsonr, norm
# 设置中文字体与绘图参数
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
np.random.seed(42)
# 置信区间计算函数
defcorr_ci_fisher(r, n, confidence=0.95):
r_clipped = np.clip(r, -0.999999, 0.999999)
z_r = np.arctanh(r_clipped)
se = 1 / np.sqrt(n - 3)
alpha = 1 - confidence
z_critical = norm.ppf(1 - alpha/2)
z_lower = z_r - z_critical * se
z_upper = z_r + z_critical * se
return np.tanh(z_lower), np.tanh(z_upper)
# 模拟参数设置
rho_true = 0.6
n = 20
confidence = 0.95
n_simulations = 10000
# 定义四种数据生成函数
defgenerate_normal(n, rho):
cov = [[1, rho], [rho, 1]]
return multivariate_normal.rvs(mean=[0,0], cov=cov, size=n)
defgenerate_lognormal(n, rho):
# 生成二元正态数据,取指数得到对数正态数据
cov = [[1, rho], [rho, 1]]
z_samples = multivariate_normal.rvs(mean=[0,0], cov=cov, size=n)
return np.exp(z_samples)
defgenerate_t_dist(n, rho, df=3):
# 生成多元t分布数据,厚尾分布
cov = [[1, rho], [rho, 1]]
return multivariate_t.rvs(shape=cov, df=df, size=n)
defgenerate_mixture(n, rho1=0.8, rho2=0.4, mix_ratio=0.5):
# 生成混合分布数据
n1 = int(n * mix_ratio)
n2 = n - n1
cov1 = [[1, rho1], [rho1, 1]]
cov2 = [[1, rho2], [rho2, 1]]
samples1 = multivariate_normal.rvs(mean=[0,0], cov=cov1, size=n1)
samples2 = multivariate_normal.rvs(mean=[0,0], cov=cov2, size=n2)
return np.vstack([samples1, samples2])
# 定义分布列表
distributions = [
{"name": "二元正态分布", "func": generate_normal, "rho_true": rho_true},
{"name": "对数正态分布", "func": generate_lognormal, "rho_true": rho_true},
{"name": "t分布(df=3)", "func": generate_t_dist, "rho_true": rho_true},
{"name": "混合分布", "func": generate_mixture, "rho_true": 0.6}, # 混合后的总体相关系数约为0.6
]
# 执行模拟
coverage_results = {}
for dist in distributions:
name = dist["name"]
generate_func = dist["func"]
true_rho = dist["rho_true"]
cover_count = 0
for _ in range(n_simulations):
samples = generate_func(n, rho_true)
r, _ = pearsonr(samples[:,0], samples[:,1])
ci_l, ci_u = corr_ci_fisher(r, n, confidence)
if ci_l <= true_rho <= ci_u:
cover_count += 1
coverage = cover_count / n_simulations
coverage_results[name] = coverage
print(f"{name}的实际覆盖率:{coverage*100:.2f}%")
# 可视化覆盖率结果
fig, ax = plt.subplots(figsize=(12, 7))
dist_names = list(coverage_results.keys())
coverage_values = list(coverage_results.values())
# 绘制柱状图
bars = ax.bar(dist_names, coverage_values, color=['#377eb8', '#4daf4a', '#984ea3', '#ff7f00'], alpha=0.7)
# 绘制目标覆盖率基准线
ax.axhline(0.95, color='black', linestyle='--', linewidth=2.5, label='目标覆盖率95%')
# 绘制可接受的覆盖率范围(93%-97%)
ax.axhspan(0.93, 0.97, color='gray', alpha=0.2, label='可接受范围')
# 在柱状图上标注数值
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{height*100:.2f}%',
ha='center', va='bottom', fontsize=12)
# 图表设置
ax.set_title('不同分布下Fisher Z变换置信区间的实际覆盖率', fontsize=16)
ax.set_ylabel('实际覆盖率', fontsize=14)
ax.set_ylim(0.8, 1.0)
ax.grid(True, linestyle=':', alpha=0.5, axis='y')
ax.legend(fontsize=12)
plt.tight_layout()
plt.show()
执行结果如下:
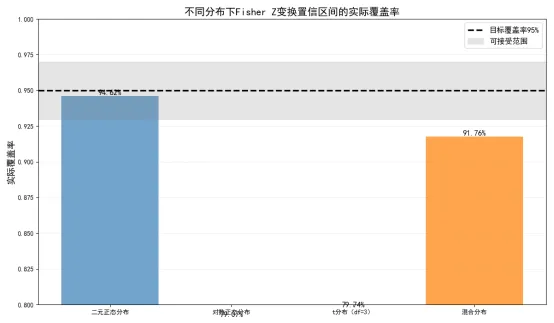
这段代码通过蒙特卡洛模拟,验证了四种不同分布下Fisher Z变换的置信区间覆盖率,结论如下:
一是在二元正态分布下,置信区间的实际覆盖率与目标95%几乎完全一致,验证了我们之前的结论,Fisher Z变换在正态总体下具有极高的精度。
二是在其他分布下,实际覆盖率均有下降。
6.2 Fisher Z变换的适用边界与局限性
基于上述的稳健性分析,我们可以明确Fisher Z变换的适用边界与核心局限性:
适用边界
总体服从二元正态分布,这是Fisher Z变换的理论前提,在这个场景下,变换后的Z统计量几乎完美服从正态分布,置信区间的覆盖率精度极高,即使在小样本下也能保持优异的表现。
总体分布为轻度到中度的非正态分布,如轻微偏态、轻度厚尾的分布,样本量足够大(),此时Fisher Z变换依然能保持较好的稳健性,覆盖率在可接受范围内。
当总体相关系数接近时,无论样本量大小,都必须使用Fisher Z变换,因为原始的正态近似会完全失效,出现边界越界的问题,只有Fisher Z变换能构建合理的置信区间。
局限性
当总体分布呈现严重的偏态、厚尾,或存在混合分布、潜在分组异质性时,Fisher Z变换的表现会严重下降,置信区间的覆盖率不足,统计推断的结果会出现系统性偏差。
Fisher Z变换是基于皮尔逊相关系数的,而皮尔逊相关系数对异常值极其敏感,单个极端值就可以完全改变样本相关系数的大小,即使变换后,这种偏差也无法消除,导致统计推断结果失真。
isher Z变换的核心是针对皮尔逊相关系数的分布特性设计的,对于非线性相关系数,如距离相关、最大信息系数等,无法直接应用,对于等级相关系数,也需要进行方差修正,且精度会有所下降。
即使在正态分布下,小样本场景中,变换后的Z统计量依然存在微小的正偏差,虽然可以通过Fisher纠偏公式修正,但在极小样本()下,偏差依然不可忽略。
7本节总结
在本节中,我们完整拆解了Fisher Z变换的数学原理、统计特性、四大核心应用场景、扩展应用、稳健性分析与常见陷阱,形成了完整的理论与应用体系,核心结论如下:
Fisher Z变换的核心本质:Fisher Z变换是样本相关系数的唯一方差稳定变换,通过双曲反正切函数,将有界区间内的相关系数映射到无界的实数域,同时彻底修正了原始分布的偏态,让变换后的Z统计量几乎完美服从正态分布,完美解决了原始相关系数分布的三大核心缺陷。
变换的统计特性:变换后的Z统计量的期望近似等于总体相关系数对应的Z变换值,方差为常数,与总体相关系数的取值无关,仅由样本量决定,即使在小样本、接近的极端场景下,依然能保持极佳的正态性。
四大核心应用场景:Fisher Z变换是相关性统计推断的核心工具,四大核心应用包括:①总体相关系数的置信区间构建,是目前的金标准方法;②两个独立相关系数的比较检验,完美解决了方差非齐性问题;③多个相关系数的元分析合并,是循证研究的核心工具;④相关系数的等效性检验,解决了传统检验“无法证明无效应”的缺陷。
扩展应用:Fisher Z变换可以扩展到偏相关系数和等级相关系数的统计推断中,只需要对自由度和方差进行轻微的修正,适用范围极广。
稳健性与适用边界:Fisher Z变换在二元正态分布下表现完美,对轻度非正态分布具有一定的耐受性,但在严重厚尾、混合分布等极端非正态场景下,稳健性会严重下降,置信区间覆盖率不足,统计推断结果会出现系统性偏差。

