我做 HR 的朋友每天要处理大量简历,需要把候选人信息发给同事或第三方,但姓名、手机号、邮箱、学校这些 PII 直接暴露有风险。
今天分享一个 Python 脚本,帮你一键脱敏。
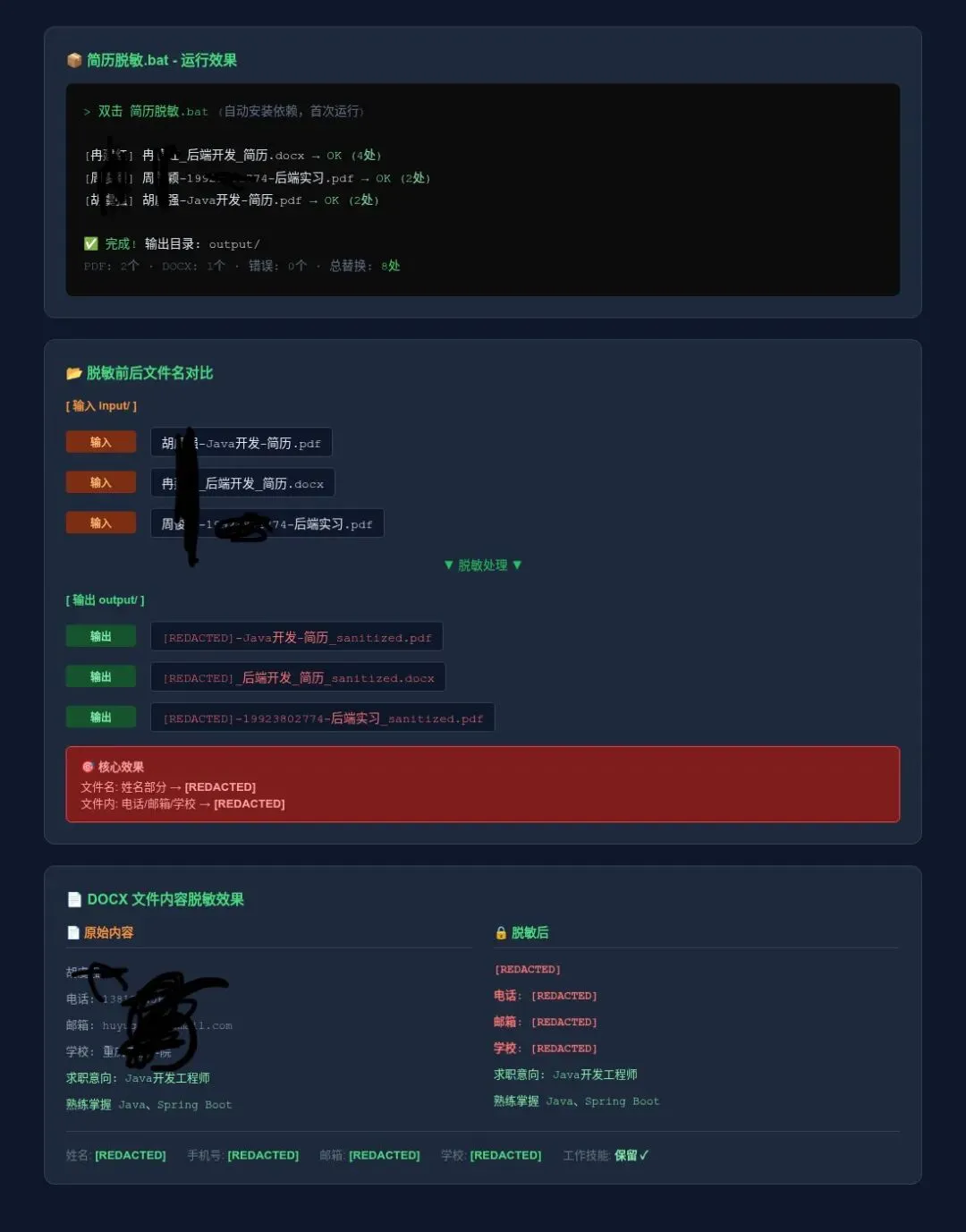
效果展示
需求是什么?
输入:PDF 或 Word 格式的简历
输出:PII 被替换为 [REDACTED] 的干净版本
需要脱敏的内容:
难点:用户给过来的简历格式千差万别——有的是 张三-Java开发.pdf,有的是 软件开发工程师_李四_138xxxx1234.pdf,还有的是扫描件图片。
第一版:正则匹配,困难重重
手机号和邮箱
这两个最简单,用正则就行:
# 手机号:中国手机号格式
RE_PHONE = re.compile(r'(?<!\d)1[3-9]\d[\s\-]?\d{4}[\s\-]?\d{4}(?!\d)')
# 邮箱
RE_EMAIL = re.compile(r'[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}')
学校名称
最初想写一个通用的高校识别正则,用前缀+后缀匹配:
RE_SCHOOL = re.compile(
r'(?<![A-Za-z0-9])'
r'(?:清华|北大|复旦|...|重庆|...)' # 地名前缀
r'(?:大学|学院|学校|...)' # 学校后缀
r'(?=[\s\n\r,]|$)'
)
测试发现根本不可行:重庆xx学院的"重庆"被匹配了,但"xx学院"不是标准后缀,结果只替换了"重庆",留下了"xx学院"。
解决:只匹配目标学校就行了。需求简单,方案就简单:
RE_SCHOOL = re.compile(r'重庆xx学院')
姓名识别
姓名没有固定格式,不能用正则猜。解决方案:从文件名中提取姓名。
⚠️ 踩坑:最初版用了 [\u4e00-\u9fa5]{2,4} 匹配所有 2-4 个汉字,结果简历正文里几乎所有中文都被替换成了 [REDACTED]!

根因:正则没有任何语义约束,后端开发、Java工程师 这种技术术语也中招。解决:删除宽泛匹配,只保留标签格式 姓名: 张三 。
def extract_name_from_filename(filename):
parts = re.split(r'[\-_\s]+', filename)
for part in parts:
if re.fullmatch(r'[\u4e00-\u9fa5]{2,4}', part):
return part
return None
但实际文件名千奇百怪:张三-Java开发、软件开发工程师_李四_138xxxx1234。需要给每个候选项打分:
| 信号 |
加分 |
| 前面是职位词(开发/工程/设计...) |
+25 |
| 后面是手机号/邮箱 |
+25 |
| 常见姓氏开头 |
+5 |
| 2-3字片段 |
+10 |
最终得分最高的就是姓名。
第二版:PDF 中文变黑方块
用 ReportLab 生成 PDF 时,中文全部显示成黑方块。
原因:默认字体 Helvetica 不支持中文。
解决:自动检测并注册中文字体:
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
candidates = [
"/System/Library/Fonts/PingFang.ttc", # macOS
"C:\\Windows\\Fonts\\msyh.ttc", # Windows
"/usr/share/fonts/...NotoSansCJK.ttc", # Linux
]
for path in candidates:
if os.path.exists(path):
font = TTFont("ChineseFont", path)
pdfmetrics.registerFont(font)
macOS 和装了中文字体的 Windows 会自动找到,Linux 需要装 Noto Sans CJK。
第三版:扫描件(图片型 PDF)
有些简历是扫描件,PyMuPDF 读到的文本是 0。
解决方案:OCR 自动降级。检测到文本 < 30 字符时,触发 RapidOCR:
import fitz
from rapidocr_onnxruntime import RapidOCR
def process_pdf(input_path, output_path, target_name):
doc = fitz.open(input_path)
for page in doc:
text = page.get_text() or ""
if len(text.strip()) < 30:
# OCR 降级
mat = fitz.Matrix(2.0, 2.0) # 2倍分辨率
pix = page.get_pixmap(matrix=mat)
img_bytes = pix.tobytes("png")
ocr = RapidOCR()
result, _ = ocr(img_bytes)
if result:
text = "\n".join(item[1] for item in result)
# ... 脱敏逻辑
OCR 识别率很高,但有个新问题:形近字误差。
第四版:OCR 形近字误差
测试发现,张开 被 OCR 识别成了 再造(开→再,张→造)。
精确匹配完全失效。需要在脱敏前做模糊查找:
def fuzzy_find(text, target_name):
"""
容忍 OCR 形近字误差的模糊匹配
最多容忍 2 个字符误差,但必须连续匹配 ≥ 2
"""
confusion = {
'冉': ['再'], '再': ['冉'],
'建': ['造'], '造': ['建'],
'红': ['江', '弘'],
# ... 更多形近字
}
for start in range(len(text)):
substr = text[start:start + len(target_name)]
# 逐字符匹配,容忍混淆字
# ...
这样即使用户收到的扫描件质量一般,姓名依然能被正确识别和脱敏。

最终方案
架构:
输入文件
↓
PyMuPDF 读取文本
↓ 文本<30字符?
↓ 是 → RapidOCR 图片识别
↓ 否 → 直接脱敏
↓
sanitize_text() → [REDACTED] 替换
↓
ReportLab 生成 PDF
↓
输出文件(文件名也脱敏)
依赖(只有 4 个):
pip install pymupdf python-docx reportlab rapidocr_onnxruntime
小白使用方法:双击运行 .bat 脚本,简历丢进 input 文件夹,结果从 output 取,全程不需要碰命令行。
踩坑总结
| 坑 |
原因 |
解决 |
| PDF 中文黑方块 |
Helvetica 不支持中文 |
自动注册中文字体 |
| 扫描件读不到 |
纯图片 PDF |
RapidOCR 自动降级 |
| OCR 形近字 |
冉→再,建→造 |
模糊匹配 fallback |
| 学校正则误匹配 |
地名前缀被单独匹配 |
精确匹配目标学校 |
| 首页空白 PDF |
showPage() 调用时机错误 |
first_page 标志位 |
核心心得
需求简单,方案就简单。
不要过度设计,找到真正的问题,逐个解决,比一开始就设计"完美方案"要靠谱得多。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
