1. 什么是Cachier?为什么要用它?
在日常开发中,你是否经常遇到这样的情况:一个函数执行一次要花好几秒(比如复杂的科学计算、数据库查询、API请求),但当用户短时间内反复用同样的参数调用它时,每次都要重新跑一遍,白白浪费时间和资源。
Python标准库里的 functools.lru_cache 可以缓存函数结果,但它的功能实在太简陋了——没有过期时间设置,缓存会永久驻留在内存里,程序重启就全部丢失。
Cachier 就是为了解决这些痛点而生的。它是一个纯Python编写的第三方库,通过一个简单的装饰器,就能给你的函数加上持久化缓存,支持过期时间、跨进程共享、甚至基于MongoDB的分布式缓存。
一句话总结:Cachier 让你的函数拥有“过目不忘”的能力——相同的输入直接返回记忆中的结果,而且这个记忆可以持久保存、自动过期。
2. 快速上手:三分钟学会Cachier
2.1 安装
没有其他依赖,纯Python实现,Python 3.5+ 都可以用。
2.2 最简单的例子
import timefrom cachier import cachier@cachier()def slow_calculation(x, y): """模拟一个耗时计算""" time.sleep(2) return x * y# 第一次调用:执行函数,耗时2秒start = time.time()result1 = slow_calculation(3, 5)print(f"第一次调用结果:{result1},耗时:{time.time() - start:.2f}秒")# 第二次调用:直接返回缓存,几乎0秒start = time.time()result2 = slow_calculation(3, 5)print(f"第二次调用结果:{result2},耗时:{time.time() - start:.2f}秒")
运行结果:
第一次调用结果:15,耗时:2.01秒第二次调用结果:15,耗时:0.00秒
第一次调用时函数正常执行(耗时2秒),第二次调用时Cachier直接从缓存中读取结果,几乎瞬间返回。缓存默认存储在 ~/.cachier/ 目录下,即使关闭Python重新运行程序,缓存依然有效。
2.3 Cachier vs lru_cache 直观对比
3. 核心功能详解
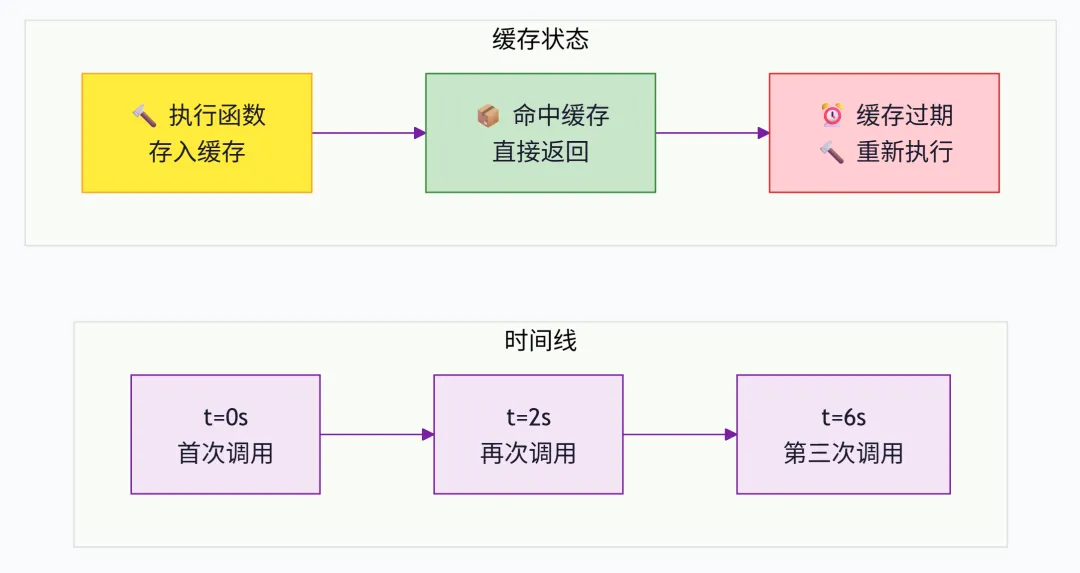
3.1 设置缓存过期时间(stale_after)
Cachier 最核心的功能就是可以给缓存设置“保质期”。使用 stale_after 参数,指定一个 timedelta 对象即可。
import timefrom cachier import cachierfrom datetime import timedelta@cachier(stale_after=timedelta(seconds=5))def get_data(param): """模拟获取动态数据,缓存5秒后过期""" print(f"正在执行计算... param={param}") time.sleep(1) return f"计算结果_{param}_{time.time()}"# 测试过期机制for i in range(3): print(f"\n--- 第{i+1}轮 ---") print(get_data("test")) time.sleep(2) # 每次调用间隔2秒
运行过程示意:
--- 第1轮 ---正在执行计算... param=test计算结果_test_1700000000.123--- 第2轮 ---计算结果_test_1700000000.123 # 2秒后,缓存未过期,直接返回--- 第3轮 ---正在执行计算... param=test # 累计超过5秒,缓存过期,重新计算计算结果_test_1700000006.456
过期机制图解:
3.2 灵活控制单次调用行为
Cachier 允许在调用时传入特殊参数来控制本次调用的行为,非常灵活:
@cachier(stale_after=timedelta(days=7))def api_request(endpoint): print(f"发起API请求:{endpoint}") time.sleep(1.5) # 模拟网络延迟 return {"data": f"Response from {endpoint}"}# 正常调用(会使用缓存)data1 = api_request("/users")# 忽略缓存:强制重新执行(但不更新缓存)data2 = api_request("/users", ignore_cache=True)# 覆盖缓存:强制重新执行,并更新缓存data3 = api_request("/users", overwrite_cache=True)# 调试模式:打印缓存命中的详细逻辑data4 = api_request("/users", verbose_cache=True)
3.3 后台刷新缓存(next_time)
有时候你希望缓存过期时不要等待重新计算,而是先返回旧数据,后台慢慢更新。这正是 next_time=True 的用武之地:
@cachier(stale_after=timedelta(seconds=5), next_time=True)def slow_external_api(query): """耗时很长的外部API调用""" print(f"⏳ 正在调用外部API,查询: {query}") time.sleep(5) # 模拟一个很慢的API return f"最新数据_{query}"# 测试 next_time 效果result = slow_external_api("天气")print(f"立即返回结果: {result}") # 如果有旧缓存,会立即返回,同时后台更新
当缓存过期时:
函数立即返回旧的缓存值(如果存在)
在后台线程中重新执行函数,更新缓存
期间其他调用不会被阻塞
4. 高级特性
4.1 手动清理缓存
Cachier 会给被装饰的函数添加一个 clear_cache() 方法,方便手动清理:
@cachier()def my_function(x): return x * 2my_function.clear_cache() # 一键清空该函数的全部缓存
4.2 MongoDB 分布式缓存
如果需要多个机器共享同一份缓存,Cachier 支持基于 MongoDB 的跨机器缓存:
import pymongofrom cachier import cachier# 连接到MongoDBclient = pymongo.MongoClient('mongodb://localhost:27017/')collection = client['my_cache_db']['function_cache']@cachier(mongetter=lambda: collection)def shared_computation(param): # 这个函数的缓存将在多台机器间共享 return heavy_calc(param)
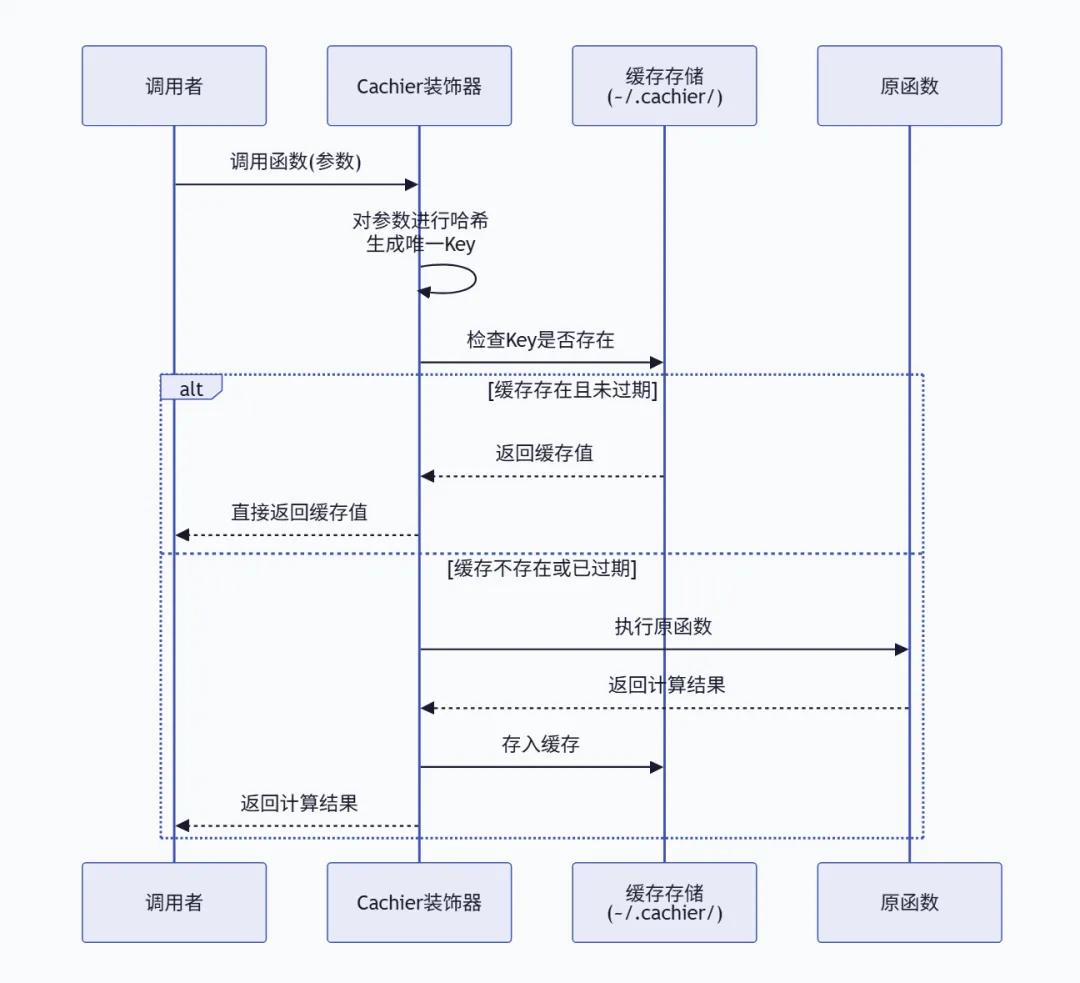
4.3 缓存存储原理
Cachier 的工作流程如下:
默认情况下,缓存以 pickle 文件的形式存储在 ~/.cachier/ 目录中,每个被装饰的函数对应一个独立的文件。
5. 实战案例:加速斐波那契数列计算
下面用一个完整的例子展示 Cachier 的威力:
import timefrom cachier import cachierfrom datetime import timedelta# 不使用缓存的版本def fib_no_cache(n): if n <= 1: return n return fib_no_cache(n-1) + fib_no_cache(n-2)# 使用Cachier缓存的版本@cachier(stale_after=timedelta(hours=1))def fib_with_cache(n): if n <= 1: return n # 注意:递归调用也必须用被装饰后的函数 return fib_with_cache(n-1) + fib_with_cache(n-2)# 性能对比n = 35print("=== 不使用缓存 ===")start = time.time()result1 = fib_no_cache(n)print(f"fib({n}) = {result1},耗时:{time.time() - start:.2f}秒")print("\n=== 使用Cachier缓存 ===")start = time.time()result2 = fib_with_cache(n)print(f"第一次 fib({n}) = {result2},耗时:{time.time() - start:.2f}秒")start = time.time()result3 = fib_with_cache(n)print(f"第二次 fib({n}) = {result3},耗时:{time.time() - start:.5f}秒")
运行结果示意:
=== 不使用缓存 ===fib(35) = 9227465,耗时:3.12秒=== 使用Cachier缓存 ===第一次 fib(35) = 9227465,耗时:3.08秒第二次 fib(35) = 9227465,耗时:0.00002秒
6. Cachier 的优缺点
优势 ✅
极简集成:一行装饰器即可启用,无需修改函数逻辑
持久化存储:缓存自动保存到磁盘,跨进程、跨Python会话有效
过期时间:支持灵活的缓存保质期设置
线程安全:底层实现保证多线程环境下的安全性
分布式支持:可选MongoDB后端实现跨机器缓存
MIT协议:可自由用于商业项目
注意事项 ⚠️
参数限制:函数参数必须是可哈希的类型(int、str、tuple等),不能是列表、字典等可变容器
代码变更无感知:如果修改了函数内部的逻辑,Cachier不会自动使旧缓存失效,需要手动清理
适合中慢速函数:Cachier本身有约1毫秒的开销,适合耗时1秒以上的函数;如果是微秒级的快速函数,建议用 lru_cache
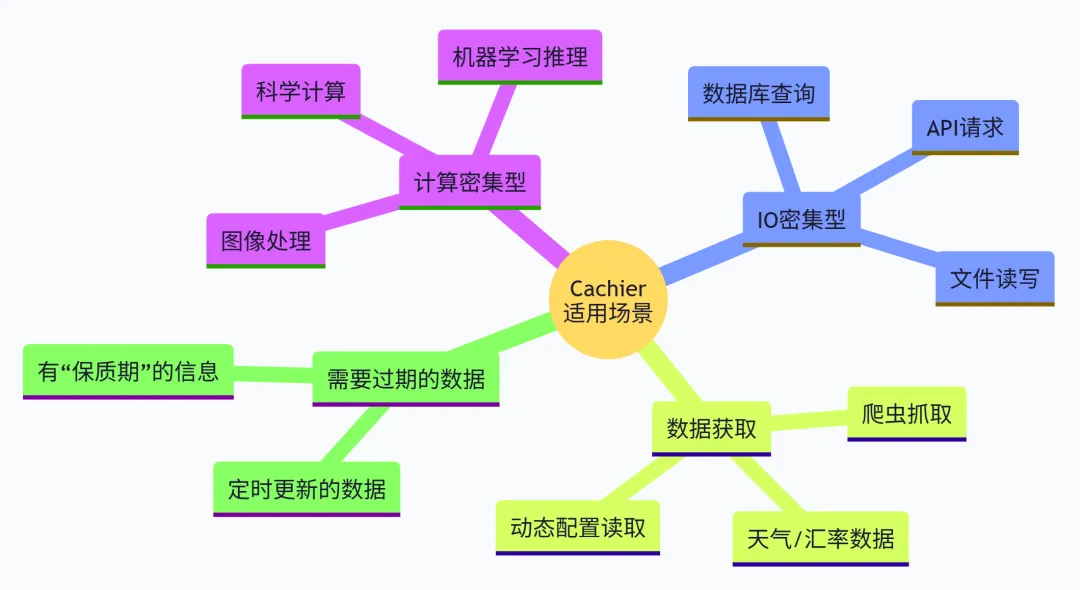
7. 适用场景总结
Cachier 特别适合以下场景: