Python+LangChain/LangGraph框架开发Ai智能体系列��19节 | Agentic RAG 基础 | 从"检索一次"到"决策循环"
- 2026-07-04 11:18:18
Python+LangChain/LangGraph框架开发Ai智能体系列��19节 | Agentic RAG 基础 | 从"检索一次"到"决策循环"01 学习目标 02 核心概念 
03 技术架构图解 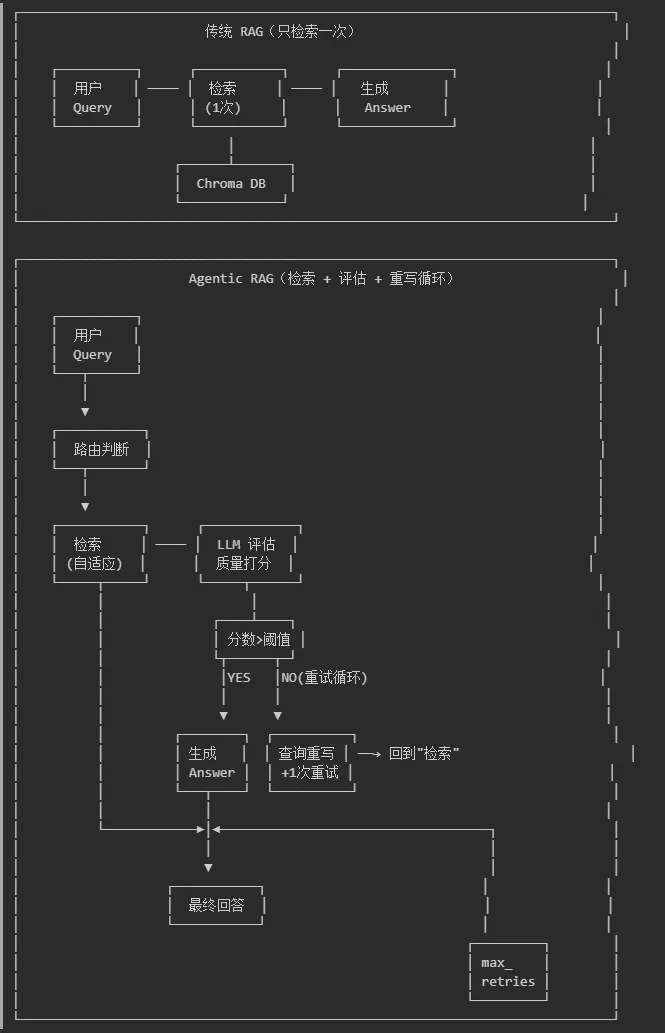
04 代码实现 05 代码运行演示
热点文章推荐: 🦞10分钟极速搭建OpenClaw龙虾智能体服务(Windows11版)“炒鸡详细” Python+langchain框架开发Ai智能体系列(一)
扫码入群获取源码,后续分享更多系列教程关注公众号探索更多精彩内容! 
1. 理解传统 RAG 和 Agentic RAG 的本质区别
2. 实现"检索 → 评估 → 重写 → 再检索"的决策循环
3. 直观感受 Agentic RAG 在模糊查询场景下的优势
用户提问 → 向量检索 → 拼接上下文 → LLM 生成 → 返回答案这个流程有一个致命问题:只检索一次。
想象一个场景:用户问"怎么让 AI 自己决定要不要查资料?"——这个问题关键词是"AI"和"查资料",跟知识库里的"Agentic RAG""自适应检索"完全不匹配。传统 RAG 检索出来的结果大概率是垃圾,然后 LLM 只能硬着头皮回答。
Agentic RAG 的核心思想:把检索从"一步到位的管线"变成"可循环的决策过程"——检索完了先评估,不够就重写查询再检索,直到信息充分。
左:传统 RAG 是直线管线;右:Agentic RAG 有评估-重写循环
图1:传统 RAG vs Agentic RAG 架构对比
核心区别:传统 RAG 是"线性流程",Agentic RAG 是"带反馈的循环"
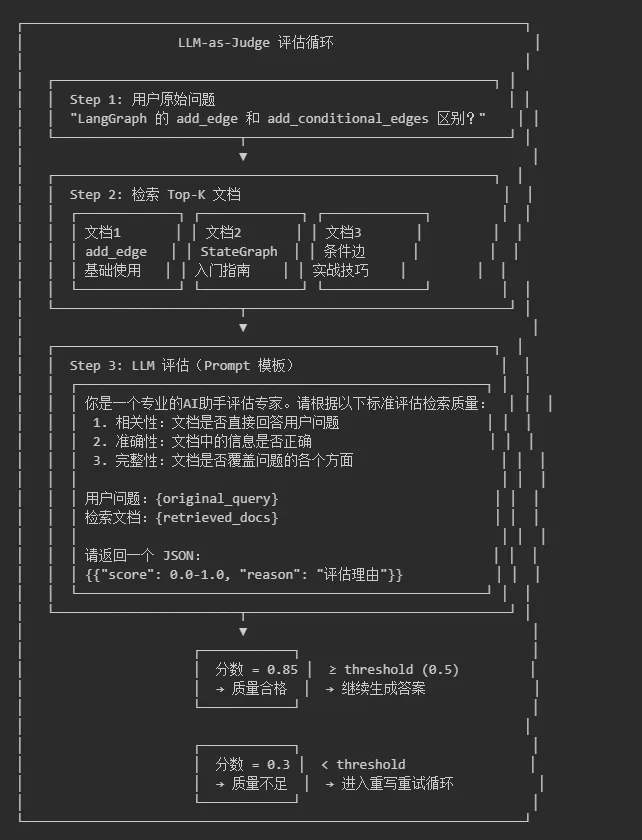
图2:LLM-as-Judge 评估循环
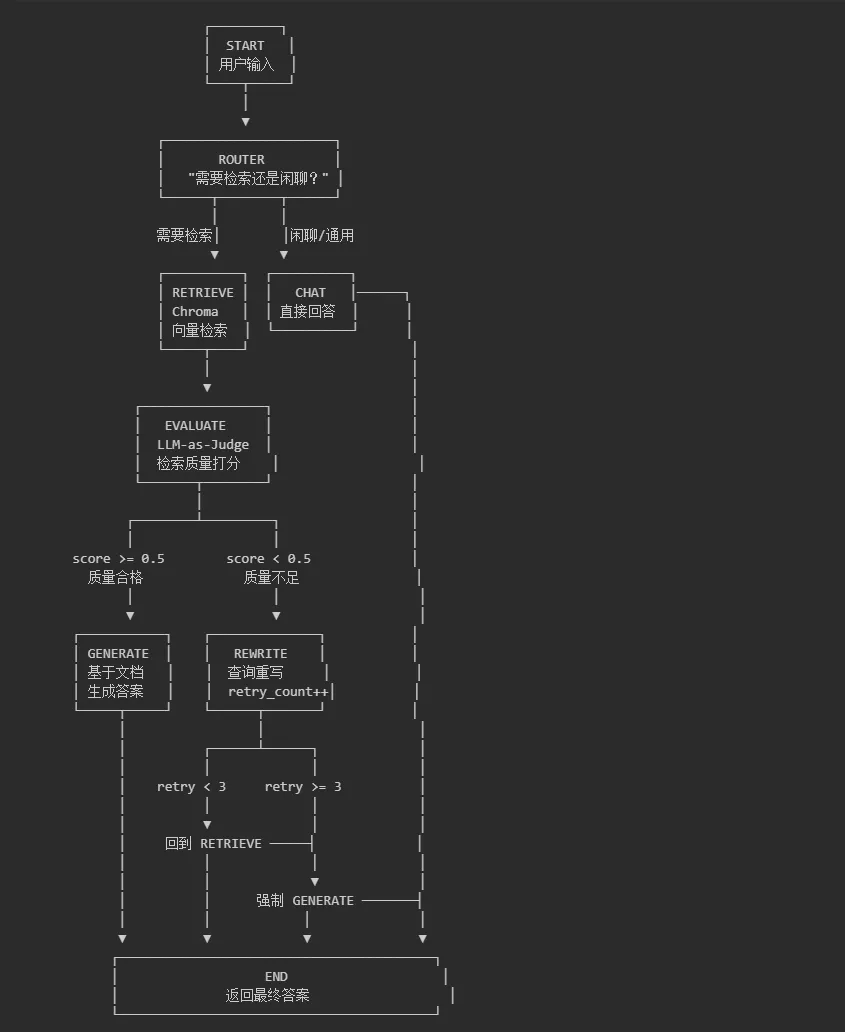
图3:LangGraph Agentic RAG 状态机流程图
4.1 工具函数:加载之前本地建好的 Chroma Collection
def _load_collection(persist_directory: str = None, collection_name: str = "day08_rag"):"""从本地持久化目录加载 Chroma Collection。复用之前文章已建好的索引数据,避免重复创建。默认指向 day08/chroma_db 目录。参数:persist_directory:Chroma 数据库目录(默认 day08/chroma_db)collection_name:Collection 名称(默认 day08_rag)返回:chromadb.Collection 对象(含 .query() 方法)"""import chromadbif persist_directory is None:persist_directory = str(_DAY08_DIR / "chroma_db")client = chromadb.PersistentClient(path=persist_directory)collection = client.get_collection(name=collection_name)print(f" [OK] Collection '{collection_name}' 加载成功,共 {collection.count()} 条记录")return collection
4.2 工具函数:底层向量检索
def _vector_search(collection, query: str, top_k: int = 3) -> list[dict]:"""执行一次向量检索,返回原始结果。封装 Chroma 的 query 调用,统一处理嵌入和查询逻辑。参数:collection:Chroma Collection 对象query:查询字符串top_k:返回的文档数量返回:list[dict],每个 dict 包含 content / metadata / distance"""from langchain_ollama import OllamaEmbeddingsembeddings = OllamaEmbeddings(model="nomic-embed-text")query_vector = embeddings.embed_query(query)results = collection.query(query_embeddings=[query_vector],n_results=top_k,include=["documents", "metadatas", "distances"],)docs = []raw_docs = results.get("documents", [[]])[0]raw_metas = (results.get("metadatas") or [[]])[0]raw_dists = (results.get("distances") or [[]])[0]for i, content in enumerate(raw_docs):meta = raw_metas[i] if i < len(raw_metas) else {}distance = raw_dists[i] if i < len(raw_dists) else Nonedocs.append({"content": content,"metadata": meta,"distance": distance,})return docs
4.3 工具函数:LLM 调用
def _call_llm(prompt: str, model: str = "qwen3:4b") -> str:"""调用 Ollama LLM 生成回复。封装 ChatOllama 调用,统一错误处理。参数:prompt:输入提示词model:Ollama 模型名称返回:LLM 生成的文本字符串"""from langchain_ollama import ChatOllamallm = ChatOllama(model=model, temperature=0, num_ctx=4096)response = llm.invoke(prompt)return response.content.strip()
4.4 传统 RAG:检索一次 → 直接生成(对比基线)
def _simple_rag_query(collection, query: str, top_k: int = 3) -> dict:"""传统 RAG 实现:检索一次 → 直接生成回答。这是 Day8 学过的模式:1. 将 query 嵌入为向量2. Chroma 检索 Top-K 文档3. 拼接上下文 → LLM 生成局限性:- 如果查询模糊,检索结果可能不相关- 没有评估机制,无法判断检索质量- 只检索一次,无法自我修正参数:collection:Chroma Collectionquery:用户查询top_k:检索文档数量返回:dict:{"answer": str, "context": list[dict], "retrieval_count": int}"""# 步骤 1:检索docs = _vector_search(collection, query, top_k)# 步骤 2:拼接上下文context_parts = []for i, doc in enumerate(docs):src = doc["metadata"].get("source", "?")context_parts.append(f"[来源{i+1}({src})]\n{doc['content']}")context_str = "\n\n".join(context_parts)# 步骤 3:LLM 生成prompt = f"""你是一个有帮助的 AI 助手,基于提供的上下文回答问题。【上下文】{context_str}【问题】{query}请简洁、准确地回答。如果上下文无法回答,请说明"当前上下文没有相关信息"。"""answer = _call_llm(prompt)return {"answer": answer,"context": docs,"retrieval_count": 1, # 传统 RAG 只检索一次}
4.5 Agentic RAG:检索 → 评估 → 重写 → 再检索(核心函数)
def _agentic_rag_query(collection,query: str,top_k: int = 3,max_retries: int = 3,score_threshold: float = 0.6,) -> dict:"""Agentic RAG 实现:检索 → 评估 → 重写 → 再检索的决策循环。与传统 RAG 的核心区别:1. 检索后,LLM 评估结果质量(0-1 评分)2. 评分不足时,LLM 重写查询,重新检索3. 最多重试 max_retries 轮,防止无限循环4. 记录每次检索的评分和查询,便于调试参数:collection:Chroma Collectionquery:用户查询top_k:每次检索的文档数量max_retries:最大重试次数score_threshold:评分阈值(低于此值触发重试)返回:dict:{"answer": str,"context": list[dict],"retrieval_count": int,"history": list[dict], # 每轮检索的评分和查询记录}"""current_query = queryhistory = [] # 记录每轮检索的评分和查询best_docs = [] # 保留最好的检索结果for attempt in range(max_retries + 1): # 初始 1 次 + 最多 max_retries 次重试# ── 步骤 1:检索 ──────────────────────────────────docs = _vector_search(collection, current_query, top_k)# ── 步骤 2:评估检索质量 ────────────────────────────context_str = "\n".join(f"- {doc['content'][:100]}" for doc in docs)eval_prompt = f"""你是一个检索质量评估器。根据用户问题和检索到的上下文,评估检索结果的相关度。【用户问题】{query}【检索到的上下文】{context_str}请评估检索结果对回答用户问题的帮助程度,只输出一个 0 到 1 之间的数字:- 0.8-1.0:检索结果完全能回答问题- 0.6-0.8:检索结果部分相关,但信息不够充分- 0.4-0.6:检索结果有一定关联,但缺少关键信息- 0.0-0.4:检索结果与问题基本无关只输出一个数字,不要其他内容:"""try:score_text = _call_llm(eval_prompt)# 提取数字:取字符串中第一个浮点数import rematch = re.search(r'(\d+\.?\d*)', score_text)score = float(match.group(1)) if match else 0.5score = max(0.0, min(1.0, score)) # 钳位到 [0, 1]except Exception:score = 0.5 # 评估失败时默认中等评分history.append({"attempt": attempt + 1,"query": current_query,"score": score,"doc_count": len(docs),})# 保留评分最高的结果if not best_docs or score > max(h["score"] for h in history[:-1]):best_docs = docs# ── 步骤 3:判断是否需要重试 ────────────────────────if score >= score_threshold:print(f" [评估] 第 {attempt+1} 轮评分 {score:.2f} >= {score_threshold},信息充分")breakprint(f" [评估] 第 {attempt+1} 轮评分 {score:.2f} < {score_threshold},信息不充分")# 已达最大重试次数,强制退出if attempt >= max_retries - 1:print(f" [评估] 已达最大重试次数 {max_retries},强制生成")break# ── 步骤 4:重写查询 ────────────────────────────────rewrite_prompt = f"""你是一个查询优化专家。用户提出了一个问题,但当前检索结果不够相关。【原始问题】{query}【当前检索查询】{current_query}【检索结果评分】{score:.2f}(满分 1.0)请重写检索查询,使其更精确、更有针对性地找到相关信息。重写策略:1. 添加更具体的关键词2. 换一种表述方式3. 拆分为更聚焦的子问题只输出重写后的查询,不要其他内容:"""try:new_query = _call_llm(rewrite_prompt)if new_query and len(new_query) > 2:current_query = new_queryprint(f" [重写] 新查询:{current_query[:60]}...")else:print(f" [重写] 重写失败,保持原查询")break # 重写失败,不再重试except Exception:print(f" [重写] 重写异常,保持原查询")break# ── 步骤 5:生成最终回答 ──────────────────────────────────context_parts = []for i, doc in enumerate(best_docs):src = doc["metadata"].get("source", "?")context_parts.append(f"[来源{i+1}({src})]\n{doc['content']}")context_str = "\n\n".join(context_parts)generate_prompt = f"""你是一个有帮助的 AI 助手,基于提供的上下文回答问题。【上下文】{context_str}【问题】{query}请简洁、准确地回答。如果上下文无法回答,请说明"当前上下文没有相关信息"。"""answer = _call_llm(generate_prompt)return {"answer": answer,"context": best_docs,"retrieval_count": len(history),"history": history,}
5.1 对比演示:传统 RAG vs Agentic RAG
def_load_collection(persist_directory: str = None, collection_name: str = "day08_rag"):"""从本地持久化目录加载 Chroma Collection。复用之前文章已建好的索引数据,避免重复创建。默认指向 day08/chroma_db 目录。参数:persist_directory:Chroma 数据库目录(默认 day08/chroma_db)collection_name:Collection 名称(默认 day08_rag)返回:chromadb.Collection 对象(含 .query() 方法)"""import chromadbif persist_directory isNone:persist_directory = str(_DAY08_DIR / "chroma_db")client = chromadb.PersistentClient(path=persist_directory)collection = client.get_collection(name=collection_name)print(f" [OK] Collection '{collection_name}' 加载成功,共 {collection.count()} 条记录")return collection
5.1执行结果
注意事项:
前置条件:
- 完成之前文章的学习(chroma_db 目录已存在,day08_rag Collection 已建索引)
- 本地搭建好ollama 向量模型ollama pull nomic-embed-text
- 本地搭建好ollama LLM模型 qwen3:4b 可用(评估和生成需要 LLM)
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

