机器学习前必须做类别编码、特征转换,一套流水线代码直接喂模型。场景:用户特征(城市、性别、年龄、消费)转为模型可识别数值。核心:LabelEncoder、OneHotEncoder、cut 分箱、StandardScaler。① 生成测试数据
import pandas as pdimport numpy as npdf = pd.DataFrame({ "city": np.random.choice(["北京","上海","广州","深圳"],200), "gender": np.random.choice(["男","女"],200), "age": np.random.randint(18,70,200), "income": np.random.normal(8000,3000,200).round(2)})df.to_excel("feature.xlsx",index=False)print("feature.xlsx 已生成")
② 核心代码
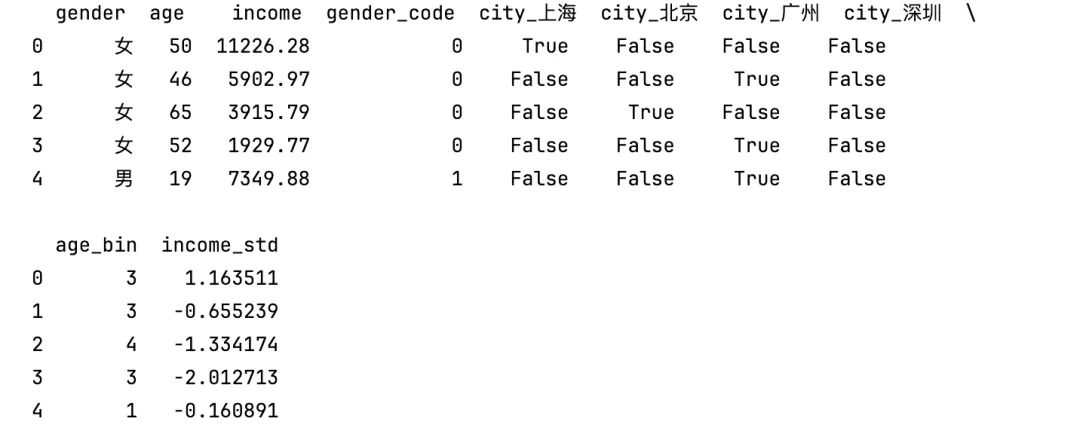
import pandas as pdfrom sklearn.preprocessing import LabelEncoder, StandardScalerdf = pd.read_excel("feature.xlsx")# 标签编码df["gender_code"] = LabelEncoder().fit_transform(df["gender"])# 独热编码df = pd.get_dummies(df, columns=["city"], prefix="city")# 年龄分箱df["age_bin"] = pd.cut(df["age"], bins=[18,30,45,60,70], labels=[1,2,3,4])# 标准化df["income_std"] = StandardScaler().fit_transform(df[["income"]])print(df.head())
结果展示
总结
特征工程是数据分析→机器学习必经步骤,代码可直接嵌入建模 pipeline。
问题:如果代码②执行报错了,则执行下面的代码安装模块pip3 install -U scikit-learn -i https://mirrors.aliyun.com/pypi/simple/