上一章我们已经把一个最重要的观念先立住了。
字符串不是一段普通文字。 它是程序处理现实信息时,最常见的载体。
但光知道字符串重要,还不够。 真正开始动手时,你很快就会遇到一个特别现实的问题:
我不要整段内容,我只想拿其中一部分。
比如:
从文件名里拿后缀 从手机号里拿前 3 位 从身份证号里拿出生年份 从邮箱里拿用户名 从一串日期里拿出 年、月、日 从一段文本里截取关键词
这些操作,本质上都离不开两个核心能力:
索引 切片
这一章,我们就把它们讲透。
你会发现,字符串并不是只能整段使用。 它可以像一条被精准定位的带子一样,被你一个字符一个字符地取出来,也可以一段一段地切出来。
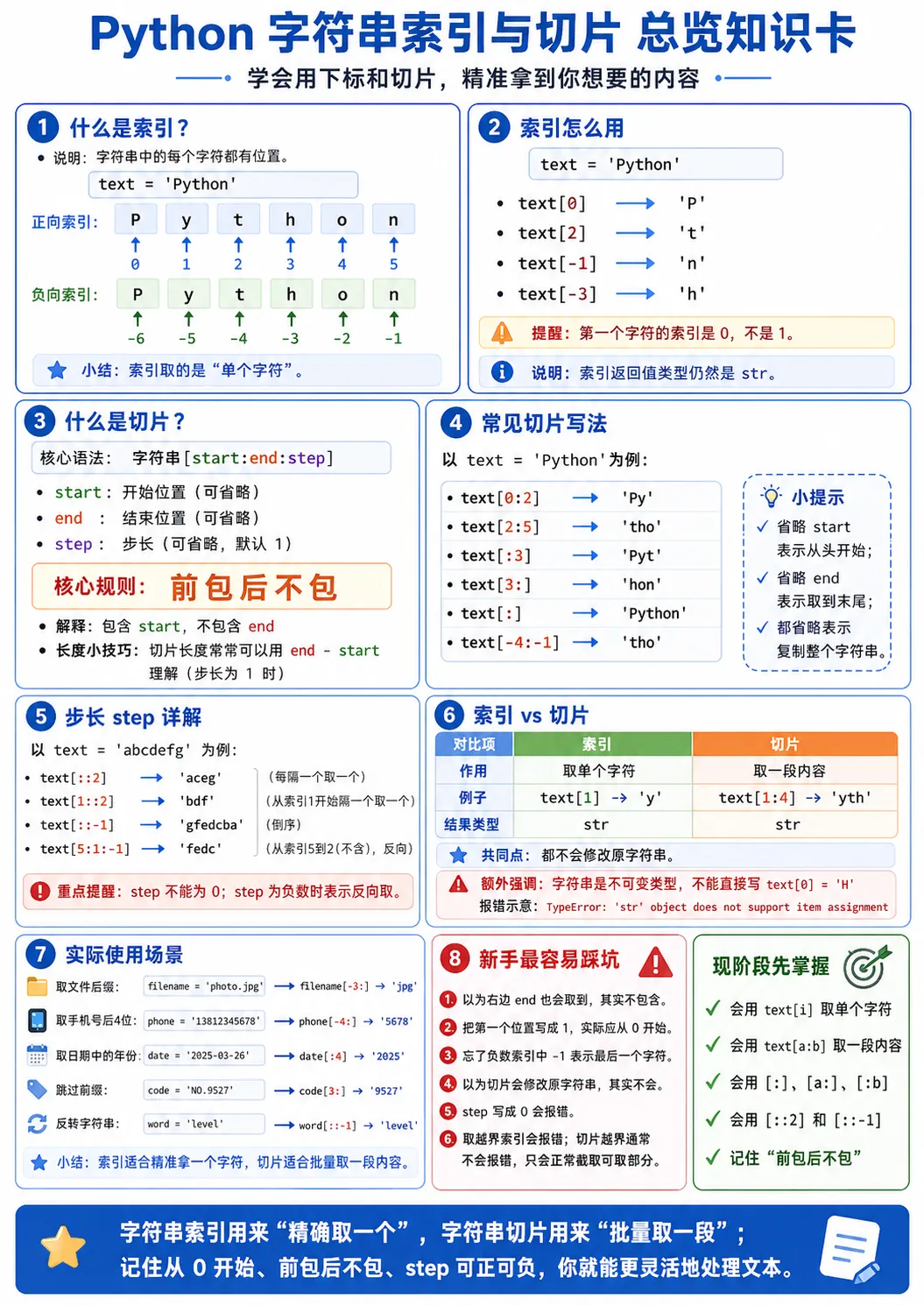
一、什么是索引
先看一个最简单的字符串:
text = 'python'
这 6 个字符,并不是一团模糊的整体。 在 Python 眼里,它们每一个都有自己的位置。
位置编号是这样的:
p y t h o n012345
这个位置编号,就叫索引。
也就是说:
第 1 个字符的索引是 0 第 2 个字符的索引是 1 第 3 个字符的索引是 2
注意,Python 里的索引,从 0 开始,不是从 1 开始。
这是很多新手刚开始最容易别扭的地方。 但你后面会越来越习惯。
二、如何通过索引取出单个字符
语法非常简单:
字符串[索引]
比如:
text = 'python'print(text[0])print(text[1])print(text[2])
输出:
pyt
这说明:
text[0] 拿到第 1 个字符text[1] 拿到第 2 个字符text[2] 拿到第 3 个字符
这里你要慢慢形成一个感觉:
索引不是第几个字符 而是字符所在的位置编号
编号从 0 开始,所以第几个 和 索引值 往往会差 1。
三、为什么索引要从 0 开始
这个问题很多人都会问。
你先不用一开始就深究特别底层的原理。 对入门阶段来说,记住这件事最重要:
Python 里大量和位置相关的东西,都是从 0 开始的。
列表是这样。 字符串也是这样。 后面很多别的结构,思路也差不多。
你可以先把它当成 Python 世界里的默认规则。 一开始可能有点不顺手,但用几天就习惯了。
真正让人卡住的,往往不是从 0 开始本身, 而是总把 索引 和 第几个字符 混着想。
这个一定要分清。
四、字符串也支持负数索引
正数索引,是从左往右数。 字符串还支持负数索引,也就是从右往左数。
看这个字符串:
text = 'python'
它的负数索引可以这样理解:
p y t h o n-6-5-4-3-2-1
也就是说:
-1 表示最后一个字符-2 表示倒数第二个字符-3 表示倒数第三个字符
来看代码:
text = 'python'print(text[-1])print(text[-2])print(text[-3])
输出:
noh
这个功能特别实用。
因为真实开发里,你经常会想取最后一个字符、最后几个字符。 如果只用正数索引,就得先去算长度。 而负数索引会轻松很多。
五、什么时候负数索引特别好用
举个很贴近实际的例子。
假设你想看看一个文件名最后一个字符是不是数字:
filename = 'report1'print(filename[-1])
或者你想拿出一个手机号最后 4 位:
phone = '13812345678'print(phone[-4])print(phone[-3])print(phone[-2])print(phone[-1])
虽然这样一个个取也行,但你已经能感觉到:
从末尾开始取数据时,负数索引非常自然。
后面讲切片时,你会更明显地感受到这一点。
六、索引越界是什么意思
看下面这段代码:
text = 'python'print(text[10])
这会直接报错。
为什么?
因为 python 只有 6 个字符,索引范围是:
0 到 5
你去取 10,当然超出了范围。
这就叫索引越界。
同样地,负数也不能乱写:
print(text[-10])
也会报错。
所以索引虽然好用,但前提是你要拿一个真的存在的位置。
如果字符串长度不确定,就要格外小心。
七、len() 和索引经常一起出现
前面你学过 len(),它可以拿到字符串长度。
比如:
text = 'python'print(len(text))
输出:
6
这说明字符串一共有 6 个字符。
那最后一个字符的正数索引是多少?
答案是:
len(text) - 1
也就是:
6 - 1 = 5
所以:
text[len(text) - 1]
和:
text[-1]
拿到的是同一个字符。
看代码:
text = 'python'print(text[len(text) - 1])print(text[-1])
输出都是:
n
这说明负数索引很多时候,其实就是一种更省事的写法。
八、字符串可以遍历,本质上也是在按索引走
比如:
text = 'python'for ch in text: print(ch)
输出会一个一个打印出字符。
虽然你没显式写索引,但本质上程序还是在按顺序访问每个位置上的字符。
所以从某种角度看,索引是你理解字符串内部结构的基础。 只要你真正明白字符串是由一个个有位置的字符组成,后面很多操作都会更顺。
九、什么是切片
如果说索引是拿一个字符, 那么切片就是拿一段字符。
看例子:
text = 'python'print(text[0:3])
输出:
pyt
这就是切片。
它的意思是:
从索引 0 开始取 取到索引 3 前面为止 注意,不包含 3
所以实际拿到的是:
0、1、2
也就是:
p、y、t
这和前面列表切片的逻辑是一模一样的。
最核心的规则还是那一句:
前包后不包
十、切片的基本语法
字符串切片的完整写法是:
字符串[start:end:step]
这三个部分分别表示:
开始位置 结束位置 步长
其中最常用的是前两个,也就是:
字符串[start:end]
先把这个用熟最重要。
比如:
text = 'python'print(text[0:2])print(text[1:4])print(text[2:6])
输出:
pyyththon
这里你要特别注意右边不包含。 这个规则只要你搞清楚,切片就会轻松很多。
十一、切片为什么也是前包后不包
和列表一样,字符串切片也是这样设计的:
前包后不包
这么设计有个很大的好处:
长度很好算。
比如:
text[1:4]
长度直接就是:
4 - 1 = 3
实际拿到的也正好是 3 个字符。
再比如:
text[2:5]
长度就是:
5 - 2 = 3
这个规则一开始看着有点反直觉,但用熟以后会非常顺手。 尤其是你后面处理区间、分页、文本截取时,它会省很多脑子。
十二、省略开始和结束位置
切片里,开始位置和结束位置都可以省略。
1. 省略开始位置
如果不写开始位置,默认从头开始。
text = 'python'print(text[:3])
输出:
pyt
等价于:
print(text[0:3])
2. 省略结束位置
如果不写结束位置,默认切到最后。
print(text[2:])
输出:
thon
等价于:
print(text[2:len(text)])
3. 前后都省略
如果前后都不写,就表示取整个字符串。
print(text[:])
输出:
python
这一点看起来像没什么用,但实际上后面做字符串复制、格式处理时也会遇到。
十三、切片和索引到底有什么区别
这个点一定要分清。
索引,拿到的是单个字符。 切片,拿到的是一段字符串。
看例子:
text = 'python'a = text[1]b = text[1:2]print(a)print(b)print(type(a))print(type(b))
输出:
yy<class 'str'><class 'str'>
你会发现,虽然打印出来看着都像 y, 但含义是不一样的。
text[1] 是取第 2 个字符。text[1:2] 是切出一段长度为 1 的字符串。
从结果类型看,它们都是字符串。 但前者是单字符访问,后者是区间截取。
这点在很多逻辑里会影响你的思路。
十四、步长 step 是什么
切片的完整语法里,还有第三个参数:
字符串[start:end:step]
这个 step 表示每隔几个字符取一次。
比如:
text = 'python'print(text[0:6:2])
输出:
pto
因为它取的是:
索引 0 索引 2 索引 4
也就是:
p、t、o
再看:
text = 'abcdefgh'print(text[1:8:2])
输出:
bdfh
你可以把步长理解成:
跳着取
默认步长是 1,也就是一个一个正常往前取。 步长是 2,就是隔一个取一个。 步长是 3,就是隔两个取一个。
十五、最常见的几种字符串切片写法
这一组写法非常高频,建议你直接形成肌肉记忆。
取前 3 个字符:
text[:3]
取后 3 个字符:
text[-3:]
跳过前 2 个字符:
text[2:]
每隔一个取一个:
text[::2]
复制整个字符串:
text[:]
反转字符串:
text[::-1]
比如:
text = 'python'print(text[::-1])
输出:
nohtyp
这一招特别经典。
为什么能反转?
因为步长是 -1,表示倒着走。
十六、负数索引和切片配合起来特别强
前面你已经知道,负数索引是从右往左数。 和切片配合起来之后,它会变得特别实用。
比如取最后 4 个字符:
text = 'report.pdf'print(text[-4:])
输出:
.pdf
这在判断文件后缀时就很好用。
再比如取手机号最后 4 位:
phone = '13812345678'print(phone[-4:])
输出:
5678
再比如去掉字符串最后一个字符:
text = 'hello!'print(text[:-1])
输出:
hello
这类写法在实际开发里真的很常见。
十七、字符串是不可变的,这对索引和切片有什么影响
这一点特别重要。
字符串虽然能通过索引取字符、通过切片取子串, 但它本身不能像列表那样按位置修改。
比如下面这样是不行的:
text = 'python'text[0] = 'P'
这会报错。
为什么?
因为字符串是不可变类型。 你可以读它,可以切它,但不能原地改它。
那如果你真的想改怎么办?
做法是重新生成一个新字符串。
比如把第一个字符改成大写:
text = 'python'new_text = 'P' + text[1:]print(new_text)
输出:
Python
这里你会发现,切片又派上用场了。
前面手动写一个新字符, 后面用切片接上原字符串剩下的部分, 就组成了一个新的字符串。
十八、实际场景一:提取文件后缀
这是非常经典的一个需求。
比如你拿到文件名:
filename = 'photo.png'
你想知道它是不是 png 文件。
最简单粗暴的方式之一,就是取最后几位:
print(filename[-4:])
输出:
.png
如果你只关心后缀名,不要点,也可以自己再处理。
不过这里先不展开讲方法链,当前这一章的重点是感受:
切片真的能非常直接地解决现实需求。
十九、实际场景二:提取手机号中间和末尾部分
比如一个手机号:
phone = '13812345678'
取前三位:
print(phone[:3])
输出:
138
取中间四位:
print(phone[3:7])
输出:
1234
取后四位:
print(phone[-4:])
输出:
5678
这在做手机号脱敏、区号识别、信息展示时都很常见。
比如脱敏显示:
phone = '13812345678'safe_phone = phone[:3] + '****' + phone[-4:]print(safe_phone)
输出:
138****5678
你看,字符串切片一旦会了,这种操作几乎是一眼就能写出来。
二十、实际场景三:从邮箱里取用户名
假设邮箱是:
email = 'tom123@example.com'
如果你已经知道用户名部分在前面,那么最直接的思路就是先观察结构。
虽然更精确的分隔方法后面会学,但现在先用切片建立感觉。
比如你知道 @ 前面都是用户名。 那你就已经开始有了一个非常重要的字符串处理意识:
不是整段拿,而是只取我想要的那一部分。
这一章先把索引和切片彻底用顺。 到后面讲查找和拆分时,你会把这些操作组合得更自然。
二十一、实际场景四:截取日期中的年月日
比如:
date = '2026-03-26'
年:
print(date[:4])
输出:
2026
月:
print(date[5:7])
输出:
03
日:
print(date[8:10])
输出:
26
这个例子特别适合新手理解切片。 因为每一段的位置都很清楚,看一眼就能明白。
你会发现,切片其实非常像拿尺子在字符串上量位置,然后把需要的那段剪下来。
二十二、实际场景五:反转字符串
比如回文判断、密码掩码、文本逆序展示,都可能用到。
最简单的反转写法就是:
text = 'abcdef'print(text[::-1])
输出:
fedcba
这里很多人第一次看到都会有点惊讶。 但其实拆开看就明白了:
开始和结束都省略 步长是 -1也就是从后往前一个一个拿
这就是切片厉害的地方。 很多过去你以为要写循环的事,实际上一个切片就能解决。
二十三、切片最容易犯的几个错
1. 以为右边也会取到
比如:
text = 'python'print(text[1:3])
很多新手会以为结果是:
yth
其实正确结果是:
yt
因为 3 不包含。
2. 把索引值和第几个字符混淆
比如第 3 个字符,其实索引是 2。 这个错前期特别常见,只能靠多练习慢慢纠正。
3. 忘了字符串不能原地改
text[0] = 'P'
这是不行的。 字符串只能重新拼出一个新的。
4. 乱用越界索引
text[100]
这会直接报错。
但这里有个细节要注意:
单个索引越界会报错, 切片越界通常不会报错。
比如:
text = 'python'print(text[0:100])
输出:
python
因为切片会自动尽量取到能取到的部分。
这点很实用,也很容易让人混淆。
二十四、为什么切片越界通常不报错
因为切片本质上是在说:
从这里取到那里,如果那里太远,那就取到字符串末尾为止。
比如:
text = 'python'print(text[2:100])
程序不会生气,它只会老老实实把从索引 2 到最后的内容给你。
输出:
thon
这和单个索引取值不一样。
单个索引必须精确指向一个存在的位置。 切片是一个范围概念,范围稍微大一点没关系。
二十五、索引和切片,本质上是在训练什么能力
表面上看,这一章学的是语法。 但更深一层,其实是在训练你对字符串结构的敏感度。
你开始会观察:
第几个字符在哪里 哪一段从哪里开始 哪一段到哪里结束 我到底要单个字符,还是一段文本 我是不是应该从前面数,还是从后面数更方便
这种感觉一旦建立起来,后面学查找、拆分、替换、格式化时,你会轻松很多。
因为你已经不再把字符串当成一整坨文字了。 你开始把它看成一个可以被定位、被拆解、被提取的结构。
二十六、练习题:这章一定要自己敲
下面这些练习非常典型,建议你自己先写。
1. 定义字符串 python,取出第一个字符和最后一个字符
参考答案:
text = 'python'print(text[0])print(text[-1])
2. 取出前 3 个字符
print(text[:3])
3. 取出后 3 个字符
print(text[-3:])
4. 取出中间的 yth
print(text[1:4])
5. 每隔一个字符取一次
print(text[::2])
6. 把字符串反转
print(text[::-1])
7. 把手机号 13812345678 脱敏成 138****5678
phone = '13812345678'result = phone[:3] + '****' + phone[-4:]print(result)
8. 从日期 2026-03-26 中分别取出年、月、日
date = '2026-03-26'print(date[:4])print(date[5:7])print(date[8:10])
这些题一旦你自己敲顺了,索引和切片基本就稳了。
二十七、本章小结
这一章你真正要掌握的,是把字符串从 整体 看成 结构。
索引,用来拿单个字符。 切片,用来拿一段字符串。 索引从 0 开始。 负数索引表示从右往左数。 切片最核心的规则是前包后不包。 步长可以控制跳着取,甚至倒着取。 字符串虽然能索引、能切片,但它本身不可变,不能原地修改。
最常用的高频写法,你可以再过一遍:
text[0] # 第一个字符text[-1] # 最后一个字符text[:3] # 前3个字符text[2:] # 从索引2到最后text[-3:] # 最后3个字符text[::2] # 每隔一个取一个text[::-1] # 反转字符串
学会这一章之后,你处理字符串就不再只能整段拿来用。 你已经开始具备最基础也最关键的文本提取能力了。
下一章我们继续讲 常见字符串方法全梳理:split、join、replace 等。 到了那里,你会发现,索引和切片像是一把小刀,而字符串方法则更像一整套工具箱。