想象有一个项目,有几百个人申请,现在一个表已经汇集了申请人的姓名,邮箱,推荐单位。
OneDrive上每一个人都有一个文件夹,以申请序号+申请人名字命名,每个文件夹里面有简历,作品集,推荐信,提案等各种命名千奇百怪的文件。
现在老板要你把所有申请人的推荐人姓名和邮箱(存在于每个文件夹的推荐信中)都加上。
要是之前我就手动点开一个个汇总,但是最近接触了Python,想问能不能自动提取?
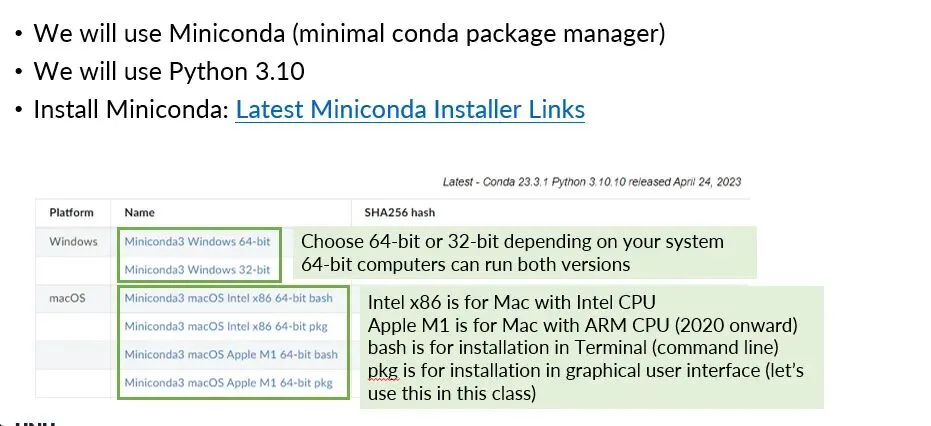
1.对着联合国大学老师ppt安装Miniconda,安装各种需要的包,并创造专属环境,获得可以输入代码的操作界面
下载自己电脑适配的安装包: https://docs.conda.io/en/latest/miniconda.html
双击安装包开始安装(和其他网站差不多
到时候安装完毕打开的操作界面是Anacoda Prompt
建环境就好像创立一个虚拟工作空间,不影响其他项目。
3.准备原始数据
3.1把OneDrive上所有文件夹下载下来
3.2还有包含申请人姓名,推荐单位,邮箱的Excel
放一个文件夹Data Folder
4.让ChatGPT写Code,存成一个.py文件
表达自己需求给ChatGPT,指定Data Folder在电脑中的路径,还有提取指定信息的规则,让它写Code。
我在此处的规则就是提取每个文件夹里面所有邮箱(关键标志@,后期再排除掉申请人本人邮箱),姓名就是sincerely,Best,Best Regard,faithfully 后面的内容。
不清楚提取规则的话,最好多提供一些sample,让ChatGPT 自己总结规则,然后调整Code。
5.在Anaconda Prompt 里面下命令run这个py文件
>>>是可以输入Python的标志,但是在这种交互模式下不可以run .py文件
要退出Python交互模式,才可以run .py文件
6.会有很多错误,遇到错误就复制回ChatGPT问怎么解决错误常常:某个需要的包没装,找不到指定文件,下命令不在对的模式,以及提取效果不理想。
我的提取效果不理想的一大原因是很多文件是转曲过的,无法识别文字,需要安装专门的OCR的包,ChatGPT也会告知下载网址和安装方法,装好后让ChatGPT给个测试code确定装好。
这个出错修复的过程会花费比较久的时间,我花了两天再在搞这个事情,大部分时间都在和ChatGPT一起修bug。
7.最后成果!
最后成功帮我找出了大概一半的推荐人姓名和邮箱,并匹配了申请人ID,生成了一个excel,另外一半我只能自己手工去找。
找的过程中发现没识别出来这些,有大多是照片格式推荐信,还有有的很模糊肉眼都很难识别,有的姓名正楷和签字部分重合很难识别……
在想下次这种信息提取项目,要增强对图片OCR能力,以及有没有可能提前把所有里面的签名拿掉,提升辨别能力。
其实这和我手动打开几百个文件夹去人工识别所花费的时间差不多,只不过我借这个工作安装了基本的Python工具,扫清了一些误区,探索了一下用Python更高效率工作的可能性!
我之前汇总申请人的姓名,邮箱那叫一个辛苦,要是那时候我有一些Python 辅助,应该会省很多力气。
之前的一些误区:
⚡我以为Python是个软件,其实它是一种计算机语言,操作界面可以用Anaconda Promopt,也可以用Visual Studio Code,老师说是目前Python常用的运行环境,我需要同时安装这个和Python,然后要用的时候打开这个界面即可。
下载地址:
https://code.visualstudio.com/docs/setup/windows
⚡我以为Python很高深,必须要有很强基础才能去应用。其实太简单了!只要装好,把需求告诉ChatGPT它会帮忙写code,有问题也发给它,也总会有解决方案,梦回我当初学习R的过程了哈哈哈
🧠Python常用的包和库(一些标准化可直接调用的工具)
⭐NumPy (Numerical Python):提供数值计算的基础数据结构(高性能数组)与算法,是大多数科学计算应用的核心基础
⭐SciPy:基于 NumPy 的科学计算工具包,解决积分、优化、信号处理等基础科学计算问题,与 NumPy 一起构成完整成熟的计算基础
⭐pandas:用于处理结构化/表格数据的高级工具,核心对象包括 DataFrame(二维表格)和 Series(一维数组),操作灵活直观
⭐matplotlib:用于生成二维数据可视化图表(如折线图、柱状图、散点图等)
⭐IPython / Jupyter Notebook:支持交互式编程环境,强调“边执行边探索”的工作流,提高数据分析与实验效率
⭐scikit-learn:通用机器学习工具库,包括分类(SVM、KNN、随机森林、逻辑回归等)、回归(Lasso、Ridge 等)和聚类(K-means、谱聚类等)算法
⭐statsmodels:侧重传统统计学与计量经济学分析,提供回归模型(线性回归、广义线性模型、稳健回归)、方差分析(ANOVA)以及统计模型结果的可视化与解释(如显著性检验)
看着都挺有用的,得用了才知道!
这两天搞这个事情搞得我眼睛痛,不过最后做出来还挺有成就感的!
虽然不是很完美,但是未来数据提取和汇总类的工作,我都有个一些自动化的概念!
之前觉得Python很困难,一直也没有开始,现在上手真的没啥难的,有困难就问ChatGPT总能解决。
感觉自己以前就是被自己预设的困难吓倒了,生活中的很多事情都是这样,做之前千难万难,开始做就会迎刃而解!
希望我的经历能够给你一些启发,也欢迎大家给出建议看有没有更高效的方案去完成这个项目。
一起学习,一起进步!




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
