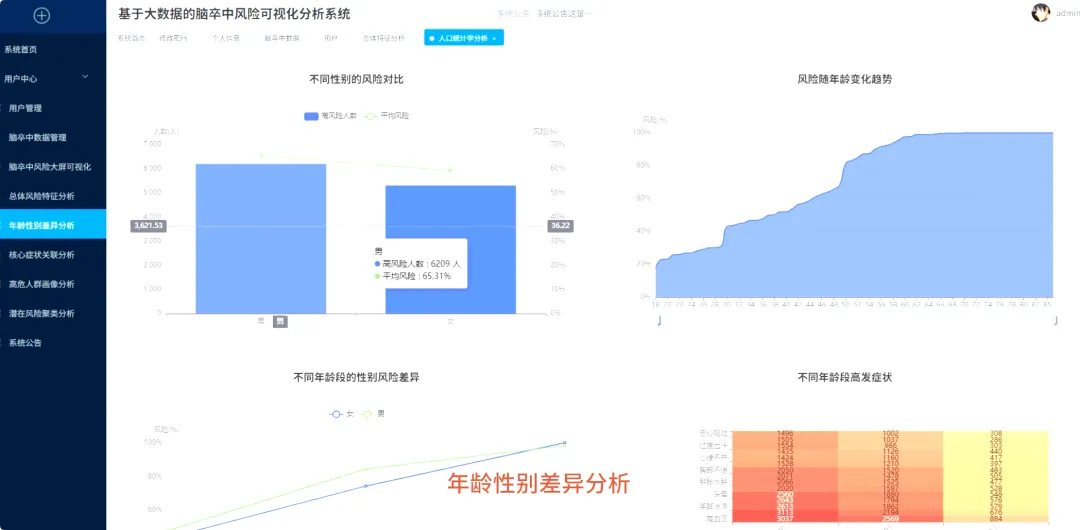
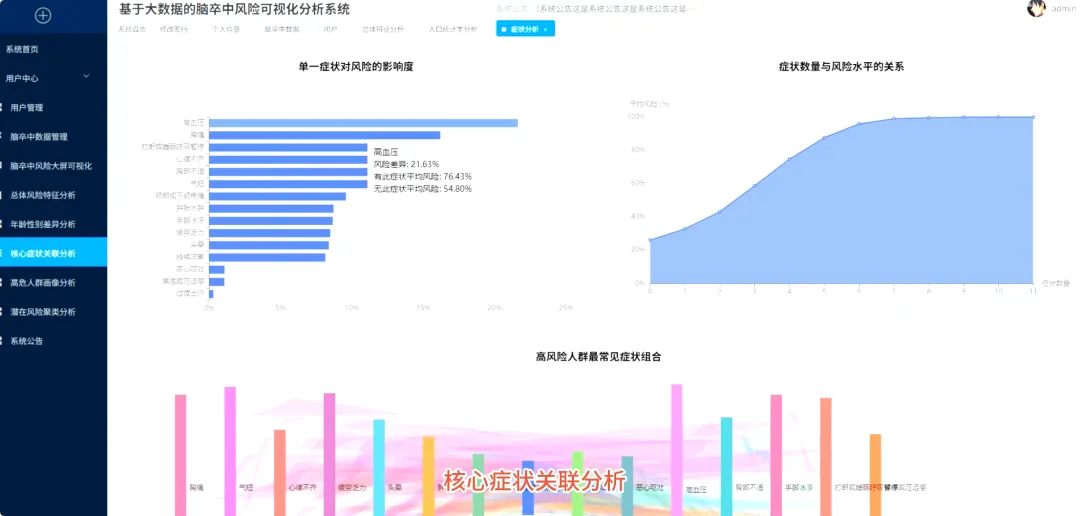
from pyspark.sql import SparkSessionfrom pyspark.ml.feature import VectorAssembler, KMeansfrom pyspark.ml.linalg import Vectorsimport pandas as pdfrom mlxtend.frequent_patterns import apriorifrom mlxtend.preprocessing import TransactionEncoderspark = SparkSession.builder.appName("StrokeAnalysis").getOrCreate()df = spark.read.csv("hdfs://path/to/stroke_risk_dataset_v2.csv", header=True, inferSchema=True)def analyze_risk_by_age_trend(df): # 核心功能1: 分析风险百分比随年龄变化的趋势 # 按年龄分组,计算每个年龄的平均风险百分比 age_risk_df = df.groupBy("age").agg(F.avg("stroke_risk_percentage").alias("avg_risk")) # 按年龄升序排列,以便观察趋势 age_risk_df = age_risk_df.orderBy("age") # 转换为Pandas DataFrame,方便前端库如Echarts使用 age_risk_pd = age_risk_df.toPandas() # 这里可以添加数据平滑处理,例如移动平均 # age_risk_pd['smoothed_risk'] = age_risk_pd['avg_risk'].rolling(window=3).mean() # 返回处理后的数据 return age_risk_pddef find_high_risk_symptom_associations(df): # 核心功能2: 高风险人群中的主要症状组合分析 (Apriori算法) # 筛选出高风险人群 high_risk_df = df.filter(F.col("at_risk") == 1) # 选择所有症状相关的列 symptom_cols = [c for c in df.columns if c not in ['age', 'gender', 'stroke_risk_percentage', 'at_risk']] # 将Spark DataFrame转换为Pandas DataFrame以应用mlxtend库 high_risk_pd = high_risk_df.select(symptom_cols).toPandas() # 将数据转换为事务列表格式,Apriori算法需要这种格式 transactions = [] for index, row in high_risk_pd.iterrows(): transaction = [symptom_cols[i] for i, val in enumerate(row) if val == 1] if transaction: # 确保事务不为空 transactions.append(transaction) # 使用TransactionEncoder进行one-hot编码 te = TransactionEncoder() te_ary = te.fit(transactions).transform(transactions) transaction_df = pd.DataFrame(te_ary, columns=te.columns_) # 应用Apriori算法挖掘频繁项集 frequent_itemsets = apriori(transaction_df, min_support=0.2, use_colnames=True) # 返回找到的频繁项集 return frequent_itemsetsdef cluster_patients_by_symptoms(df): # 核心功能3: 基于症状的患者聚类分群 (K-Means算法) # 选择症状特征列 symptom_cols = [c for c in df.columns if c not in ['age', 'gender', 'stroke_risk_percentage', 'at_risk']] # 使用VectorAssembler将特征列合并为一个特征向量 assembler = VectorAssembler(inputCols=symptom_cols, outputCol="features") assembled_data = assembler.transform(df) # 初始化K-Means模型,设置聚类数量为4 kmeans = KMeans(featuresCol="features", predictionCol="cluster", k=4, seed=1) # 训练模型 model = kmeans.fit(assembled_data) # 使用模型对数据进行预测,得到聚类结果 clustered_data = model.transform(assembled_data) # 按聚类分组,计算每个聚类的平均风险和人数 cluster_analysis = clustered_data.groupBy("cluster").agg( F.avg("stroke_risk_percentage").alias("avg_risk"), F.count("*").alias("patient_count") ) # 返回聚类分析结果 return cluster_analysis




















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
