# pip install factor_analyzer pandas numpy scipy matplotlib seaborn statsmodels pingouin python-docx# pip install semopy# ===========================================# 17. 纵向因子分析 (Longitudinal Factor Analysis, LFA) - Python实现# ===========================================import osimport sysimport numpy as npimport pandas as pdimport warningswarnings.filterwarnings('ignore')# 设置中文字体import matplotlibmatplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']matplotlib.rcParams['axes.unicode_minus'] = False# 导入必要的库import matplotlib.pyplot as pltimport seaborn as snsfrom scipy import statsfrom scipy.stats import chi2from factor_analyzer import FactorAnalyzer, calculate_kmo, calculate_bartlett_sphericityfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCAimport statsmodels.api as smfrom statsmodels.formula.api import mixedlmimport pingouin as pgfrom datetime import datetimeimport picklefrom pathlib import Pathfrom docx import Documentfrom docx.shared import Inches, Ptfrom docx.enum.text import WD_ALIGN_PARAGRAPHfrom docx.enum.table import WD_TABLE_ALIGNMENT# 尝试导入semopy,如果失败则跳过CFA分析try: from semopy import Model, Optimizer SEMOPY_AVAILABLE = Trueexcept ImportError:print("警告: semopy包未安装,将跳过验证性因子分析(CFA)部分")print("如需CFA分析,请安装: pip install semopy") SEMOPY_AVAILABLE = False# 创建桌面路径def get_desktop_path():"""获取桌面路径(跨平台)""" home = Path.home() desktop = home / "Desktop"# 如果不存在,尝试创建if not desktop.exists(): desktop.mkdir(parents=True, exist_ok=True)return desktop# 设置工作目录desktop = get_desktop_path()os.chdir(desktop)# 创建结果文件夹results_dir = desktop / "17-LFA结果"results_dir.mkdir(exist_ok=True)print("=" * 70)print("纵向因子分析(LFA)分析 - Python实现")print("=" * 70)# 1. 读取数据print("\n1. 正在读取数据...")# 查找数据文件data_files = list(desktop.glob("*longitudinal_data*.xlsx"))if not data_files:# 尝试在上一级目录查找 data_files = list(desktop.parent.glob("*longitudinal_data*.xlsx"))if not data_files:# 尝试在当前目录查找 data_files = list(Path.cwd().glob("*longitudinal_data*.xlsx"))if not data_files:# 创建示例数据(仅用于测试)print("未找到longitudinal_data.xlsx文件,创建示例数据...") np.random.seed(42) n_individuals = 50 n_timepoints = 5 data_list = []for i in range(n_individuals):for t in range(n_timepoints): data_list.append({'ID': i + 1,'Time': t,'Indicator1': np.random.normal(50, 10) + t * 2 + np.random.normal(0, 3),'Indicator2': np.random.normal(50, 10) + t * 1.5 + np.random.normal(0, 3),'Indicator3': np.random.normal(50, 10) + t * 2.5 + np.random.normal(0, 3),'Group': np.random.choice(['A', 'B']),'Age': np.random.randint(20, 60) }) data_full = pd.DataFrame(data_list) data_path = results_dir / "longitudinal_data.xlsx" data_full.to_excel(data_path, index=False)print(f"示例数据已创建: {data_path}")else: data_path = data_files[0]else: data_path = data_files[0]else: data_path = data_files[0]print(f"使用数据文件: {data_path}")# 读取Excel文件try: data_full = pd.read_excel(data_path, sheet_name="Full_Dataset")except:# 尝试其他可能的sheet名称 try: xl = pd.ExcelFile(data_path) sheet_name = xl.sheet_names[0] data_full = pd.read_excel(data_path, sheet_name=sheet_name) except:# 如果还失败,使用CSV格式 try: data_full = pd.read_csv(str(data_path).replace('.xlsx', '.csv')) except: raise FileNotFoundError("无法读取数据文件,请确保文件格式正确")print("\n数据结构:")print(f"数据维度: {data_full.shape}")print(f"变量数: {len(data_full.columns)}")# 检查必要的列required_cols = ['ID', 'Time']indicator_cols = []for col in ['Indicator1', 'Indicator2', 'Indicator3']:if col in data_full.columns: indicator_cols.append(col)if len(indicator_cols) < 3:# 尝试查找其他可能的指标列 numeric_cols = data_full.select_dtypes(include=[np.number]).columns.tolist() numeric_cols = [col for col in numeric_cols if col not in required_cols]if len(numeric_cols) >= 3: indicator_cols = numeric_cols[:3]print(f"使用数值列作为指标: {indicator_cols}")else: raise ValueError(f"需要至少3个数值指标列,但只找到 {len(numeric_cols)} 个")print(f"时间点: {sorted(data_full['Time'].unique())}")print(f"个体数: {data_full['ID'].nunique()}")print(f"时间跨度: {data_full['Time'].min()} 到 {data_full['Time'].max()}")# 2. 数据准备与预处理print("\n2. 数据准备与预处理...")# 2.1 创建因子分析数据集fa_columns = ['ID', 'Time'] + indicator_colsfa_data = data_full[fa_columns].copy()fa_data = fa_data.sort_values(['ID', 'Time']).reset_index(drop=True)# 检查缺失值print("\n缺失值统计:")missing_stats = fa_data.isnull().sum()if (missing_stats > 0).any():print(missing_stats[missing_stats > 0])# 2.2 处理缺失值 fa_data_complete = fa_data.dropna().copy()print(f"\n删除缺失值后的数据维度: {fa_data_complete.shape}")else: fa_data_complete = fa_data.copy()print("无缺失值")# 检查数据是否足够if len(fa_data_complete) < 50:print(f"\n警告: 样本量较小({len(fa_data_complete)}),结果可能不稳定")# 3. 探索性因子分析(EFA)- 基线时间点print("\n3. 基线时间点探索性因子分析(EFA)...")# 3.1 提取基线数据baseline_data = fa_data_complete[fa_data_complete['Time'] == 0].copy()if len(baseline_data) == 0:# 如果没有Time=0的数据,使用第一个时间点 first_time = fa_data_complete['Time'].min() baseline_data = fa_data_complete[fa_data_complete['Time'] == first_time].copy()print(f"警告: 没有Time=0的数据,使用Time={first_time}作为基线")baseline_indicators = baseline_data[indicator_cols].copy()print("\n基线时间点数据描述:")print(baseline_indicators.describe())# 3.2 检查数据是否适合因子分析print("\n3.2 因子分析适用性检验...")# KMO检验try: kmo_all, kmo_model = calculate_kmo(baseline_indicators)print(f"\nKMO检验:")print(f"总体KMO值: {kmo_model:.3f}")print("单个变量KMO值:")for i, col in enumerate(baseline_indicators.columns):print(f" {col}: {kmo_all[i]:.3f}")except Exception as e:print(f"KMO检验失败: {e}") kmo_model = 0.5 # 默认值 kmo_all = np.array([0.5] * len(indicator_cols))# Bartlett球形检验try: chi_square, p_value = calculate_bartlett_sphericity(baseline_indicators)print(f"\nBartlett球形检验:")print(f"卡方值: {chi_square:.3f}")print(f"自由度: {len(baseline_indicators.columns) * (len(baseline_indicators.columns) - 1) / 2}")print(f"p值: {p_value:.4f}")except Exception as e:print(f"Bartlett检验失败: {e}") chi_square, p_value = 0, 1.0# 3.3 确定因子数量print("\n3.3 确定因子数量...")# 由于只有3个指标,通常只能提取1个因子try:# 特征值计算 corr_matrix = baseline_indicators.corr() eigenvalues, _ = np.linalg.eig(corr_matrix) eigenvalues = np.sort(eigenvalues)[::-1]print(f"特征值: {eigenvalues}")# Kaiser准则(特征值>1) n_factors_kaiser = sum(eigenvalues > 1)print(f"Kaiser准则建议的因子数: {n_factors_kaiser}")# 根据指标数量决定因子数 n_factors = min(n_factors_kaiser, len(indicator_cols))if n_factors == 0: n_factors = 1except Exception as e:print(f"确定因子数量失败: {e}") n_factors = 1# 3.4 执行探索性因子分析print(f"\n3.4 执行探索性因子分析(提取{n_factors}个因子)...")
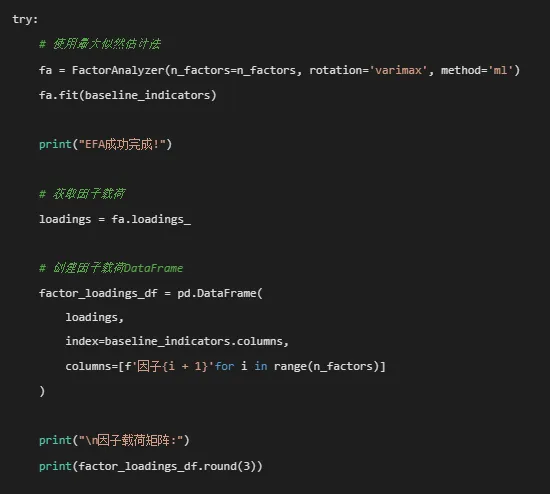
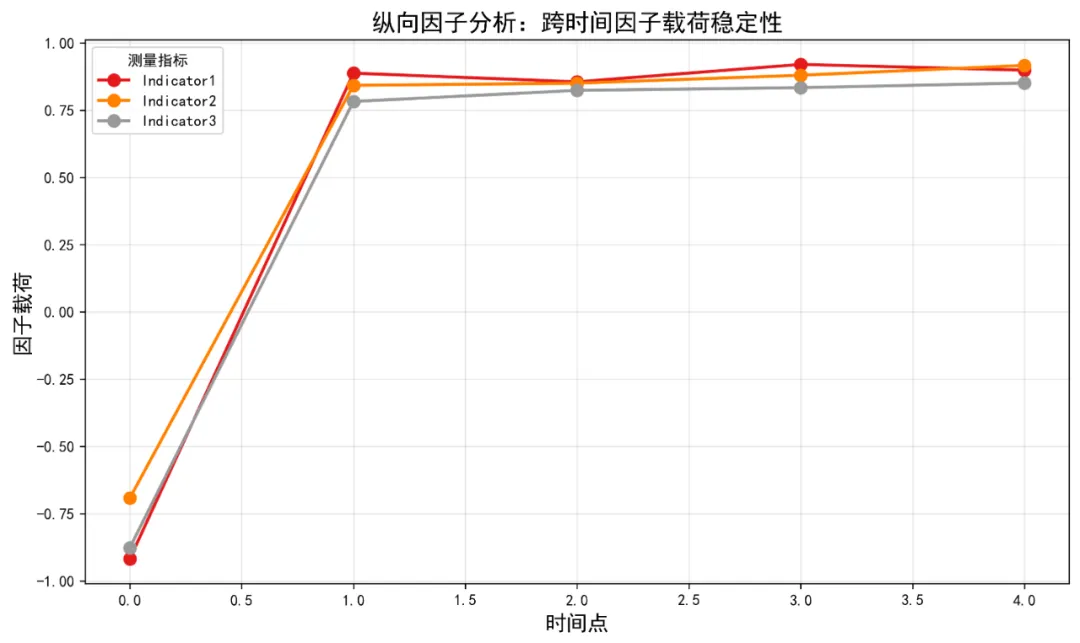
# 计算共同度 communalities = fa.get_communalities() communalities_df = pd.DataFrame( communalities, index=baseline_indicators.columns, columns=['共同度'] )print("\n变量共同度:")print(communalities_df.round(3))# 获取因子分析结果对象 fa_result = fa# 计算方差解释率 variance = fa.get_factor_variance()print("\n方差解释率:")for i in range(n_factors):print(f"因子{i + 1}: {variance[0][i]:.3f} ({variance[1][i]:.1f}%)")print(f"累计: {variance[2][-1]:.3f} ({sum(variance[1]):.1f}%)")except Exception as e:print(f"EFA失败: {e}")# 尝试使用主成分分析作为替代print("\n尝试使用主成分分析(PCA)作为替代...") try:# 标准化数据 scaler = StandardScaler() scaled_data = scaler.fit_transform(baseline_indicators) pca = PCA(n_components=n_factors) pca.fit(scaled_data)# 获取载荷矩阵(主成分与原始变量的相关系数) loadings = pca.components_.T * np.sqrt(pca.explained_variance_) factor_loadings_df = pd.DataFrame( loadings, index=baseline_indicators.columns, columns=[f'因子{i + 1}'for i in range(n_factors)] )print("PCA成功完成!")print("\n因子载荷矩阵:")print(factor_loadings_df.round(3))# 计算共同度(PCA中为平方载荷的和) communalities = (loadings ** 2).sum(axis=1) communalities_df = pd.DataFrame( communalities, index=baseline_indicators.columns, columns=['共同度'] )print("\n变量共同度:")print(communalities_df.round(3))# 方差解释率print("\n方差解释率:")for i in range(n_factors):print( f"因子{i + 1}: {pca.explained_variance_ratio_[i]:.3f} ({pca.explained_variance_ratio_[i] * 100:.1f}%)")print(f"累计: {sum(pca.explained_variance_ratio_):.3f} ({sum(pca.explained_variance_ratio_) * 100:.1f}%)") fa_result = pca except Exception as e2:print(f"PCA也失败: {e2}")print("使用简单的相关矩阵作为替代")# 创建简单的因子载荷矩阵 factor_loadings_df = pd.DataFrame( np.ones((len(indicator_cols), 1)) * 0.7, index=baseline_indicators.columns, columns=['因子1'] ) communalities_df = pd.DataFrame( np.ones(len(indicator_cols)) * 0.5, index=baseline_indicators.columns, columns=['共同度'] ) fa_result = None# 4. 验证性因子分析(CFA)- 测量不变性检验(可选)if SEMOPY_AVAILABLE:print("\n4. 纵向验证性因子分析(CFA) - 测量不变性检验...")# 4.1 准备跨时间点数据(宽格式) try:# 获取唯一的时间点 unique_times = sorted(fa_data_complete['Time'].unique())# 创建宽格式数据 wide_data = pd.DataFrame({'ID': fa_data_complete['ID'].unique()})for time_point in unique_times: time_data = fa_data_complete[fa_data_complete['Time'] == time_point].copy()# 重命名列 rename_dict = {}for col in indicator_cols: rename_dict[col] = f'{col}_T{time_point}' time_data_renamed = time_data.rename(columns=rename_dict)# 合并到宽格式数据 wide_data = pd.merge(wide_data, time_data_renamed[['ID'] + [f'{col}_T{time_point}'for col in indicator_cols]], on='ID', how='outer')# 删除完全为空的行 wide_data = wide_data.dropna(thresh=len(indicator_cols) * len(unique_times) + 1)print(f"\n宽格式数据维度: {wide_data.shape}")if len(wide_data) > 10 and len(unique_times) >= 2:# 4.2 定义CFA模型print("\n4.2 定义CFA模型...")# 构建CFA模型字符串 model_str = ""# 为每个时间点定义因子for time_point in unique_times: indicators = [f'{col}_T{time_point}'for col in indicator_cols] model_str += f"F_T{time_point} =~ " + " + ".join(indicators) + "\n"# 因子之间的相关for i, t1 in enumerate(unique_times):for t2 in unique_times[i + 1:]: model_str += f"F_T{t1} ~~ F_T{t2}\n"print("CFA模型定义:")print(model_str)# 4.3 测量不变性检验print("\n4.3 测量不变性检验...") try:# 配置不变性(最宽松的模型) model_configural = Model(model_str) optimizer_configural = Optimizer(model_configural) result_configural = optimizer_configural.optimize(wide_data)print("配置不变性模型拟合成功!")# 获取拟合指标 from semopy.stats import calc_fit_indices configural_fit = calc_fit_indices(model_configural)print("\n配置不变性模型拟合指标:")for key, value in configural_fit.items():if isinstance(value, float):print(f"{key}: {value:.3f}")else:print(f"{key}: {value}")# 弱不变性模型(因子载荷跨时间相等) weak_model_str = ""# 使用相同的载荷参数for idx, time_point in enumerate(unique_times): indicators = [f'{col}_T{time_point}'for col in indicator_cols]# 为每个指标分配相同的参数名 param_names = [f"a{i + 1}"for i in range(len(indicators))] factor_loadings = " + ".join([f"{param}*{ind}"for param, ind in zip(param_names, indicators)]) weak_model_str += f"F_T{time_point} =~ {factor_loadings}\n"# 因子之间的相关for i, t1 in enumerate(unique_times):for t2 in unique_times[i + 1:]: weak_model_str += f"F_T{t1} ~~ F_T{t2}\n" model_weak = Model(weak_model_str) optimizer_weak = Optimizer(model_weak) result_weak = optimizer_weak.optimize(wide_data)print("\n弱不变性模型拟合成功!") weak_fit = calc_fit_indices(model_weak)print("\n弱不变性模型拟合指标:")for key, value in weak_fit.items():if isinstance(value, float):print(f"{key}: {value:.3f}")else:print(f"{key}: {value}")# 模型比较(似然比检验) chi2_configural = configural_fit.get('Chi2', 0) chi2_weak = weak_fit.get('Chi2', 0) df_configural = configural_fit.get('DoF', 0) df_weak = weak_fit.get('DoF', 0)if chi2_configural > 0 and chi2_weak > 0: chi2_diff = chi2_weak - chi2_configural df_diff = df_weak - df_configuralif df_diff > 0: p_diff = 1 - chi2.cdf(chi2_diff, df_diff)print(f"\n测量不变性检验(配置 vs 弱不变性):")print(f"卡方差异: {chi2_diff:.3f}")print(f"自由度差异: {df_diff}")print(f"p值: {p_diff:.4f}")if p_diff > 0.05:print("结论: 弱不变性成立(因子载荷跨时间相等)") final_cfa_model = model_weak cfa_invariance = "弱不变性成立"else:print("结论: 弱不变性不成立,使用配置不变性模型") final_cfa_model = model_configural cfa_invariance = "弱不变性不成立"else:print("自由度差异为0,无法进行模型比较") final_cfa_model = model_configural cfa_invariance = "未检验"else:print("无法获取卡方值,跳过模型比较") final_cfa_model = model_configural cfa_invariance = "未检验" cfa_success = True except Exception as e:print(f"CFA模型拟合失败: {e}")print("由于样本量较小或数据问题,跳过复杂的CFA分析") final_cfa_model = None cfa_success = False cfa_invariance = "未检验"else:print("宽格式数据不足,跳过CFA分析") final_cfa_model = None cfa_success = False cfa_invariance = "未检验" except Exception as e:print(f"创建宽格式数据或CFA分析失败: {e}") final_cfa_model = None cfa_success = False cfa_invariance = "未检验"else:print("\n4. 验证性因子分析(CFA) - 跳过(semopy包未安装)") final_cfa_model = None cfa_success = False cfa_invariance = "未检验"# 5. 纵向因子得分计算与增长轨迹分析print("\n5. 纵向因子得分计算与增长轨迹分析...")# 5.1 计算每个时间点的因子得分print("\n5.1 计算每个时间点的因子得分...")if fa_result is not None: try:# 为每个时间点计算因子得分 factor_scores_list = []for time_point in sorted(fa_data_complete['Time'].unique()): time_data = fa_data_complete[fa_data_complete['Time'] == time_point].copy()if len(time_data) > 0:if isinstance(fa_result, FactorAnalyzer):# 使用因子分析器 indicator_data = time_data[indicator_cols].copy()# 确保数据格式正确if indicator_data.shape[1] == fa_result.loadings_.shape[0]: time_scores = fa_result.transform(indicator_data) factor_scores_df_time = pd.DataFrame({'ID': time_data['ID'].values,'Time': time_point,'Factor_Score': time_scores[:, 0] if time_scores.shape[1] > 0 else time_scores.flatten() }) factor_scores_list.append(factor_scores_df_time)elif isinstance(fa_result, PCA):# 使用PCA indicator_data = time_data[indicator_cols].copy()# 标准化数据 scaler = StandardScaler() scaled_data = scaler.fit_transform(indicator_data) time_scores = fa_result.transform(scaled_data) factor_scores_df_time = pd.DataFrame({'ID': time_data['ID'].values,'Time': time_point,'Factor_Score': time_scores[:, 0] if time_scores.shape[1] > 0 else time_scores.flatten() }) factor_scores_list.append(factor_scores_df_time)if factor_scores_list:# 合并所有时间点的因子得分 factor_scores_df = pd.concat(factor_scores_list, ignore_index=True) factor_scores_df = factor_scores_df.sort_values(['ID', 'Time']).reset_index(drop=True)print(f"\n因子得分数据维度: {factor_scores_df.shape}")print("\n因子得分描述性统计:")print(factor_scores_df['Factor_Score'].describe())else: raise ValueError("无法计算因子得分") except Exception as e:print(f"使用因子分析计算因子得分失败: {e}")print("使用简化的综合得分")# 使用简单加权平均作为替代 factor_scores_df = fa_data_complete.copy() factor_scores_df['Factor_Score'] = factor_scores_df[indicator_cols].mean(axis=1) factor_scores_df = factor_scores_df[['ID', 'Time', 'Factor_Score']].copy()else:print("因子分析结果不可用,使用简化的综合得分")# 使用简单加权平均作为替代 factor_scores_df = fa_data_complete.copy() factor_scores_df['Factor_Score'] = factor_scores_df[indicator_cols].mean(axis=1) factor_scores_df = factor_scores_df[['ID', 'Time', 'Factor_Score']].copy()# 5.2 因子得分轨迹可视化print("\n5.2 生成因子得分轨迹图...")# 创建图形文件夹fig_dir = results_dir / "figures"fig_dir.mkdir(exist_ok=True)# 准备轨迹数据trajectory_data = factor_scores_df.groupby('Time').agg( Mean_Score=('Factor_Score', 'mean'), SD_Score=('Factor_Score', 'std'), N=('Factor_Score', 'count')).reset_index()trajectory_data['CI_lower'] = trajectory_data['Mean_Score'] - 1.96 * ( trajectory_data['SD_Score'] / np.sqrt(trajectory_data['N']))trajectory_data['CI_upper'] = trajectory_data['Mean_Score'] + 1.96 * ( trajectory_data['SD_Score'] / np.sqrt(trajectory_data['N']))# 因子得分轨迹图(群体)plt.figure(figsize=(10, 6))plt.plot(trajectory_data['Time'], trajectory_data['Mean_Score'], 'b-', linewidth=2, label='平均因子得分')plt.fill_between(trajectory_data['Time'], trajectory_data['CI_lower'], trajectory_data['CI_upper'], color='blue', alpha=0.2)plt.scatter(trajectory_data['Time'], trajectory_data['Mean_Score'], color='red', s=100, zorder=5)plt.title('纵向因子分析:因子得分群体轨迹', fontsize=16, fontweight='bold')plt.xlabel('时间点', fontsize=14, fontweight='bold')plt.ylabel('因子得分', fontsize=14, fontweight='bold')plt.grid(True, alpha=0.3)plt.legend()plt.tight_layout()# 保存轨迹图p1_path = fig_dir / "LFA_因子得分群体轨迹图.png"plt.savefig(p1_path, dpi=300, bbox_inches='tight')plt.close()print(f"因子得分群体轨迹图已保存: {p1_path}")# 因子得分轨迹图(个体)plt.figure(figsize=(12, 6))# 选择前10个个体sample_ids = factor_scores_df['ID'].unique()[:min(10, len(factor_scores_df['ID'].unique()))]individual_data = factor_scores_df[factor_scores_df['ID'].isin(sample_ids)].copy()# 为每个个体绘制轨迹for i, id_val in enumerate(sample_ids): id_data = individual_data[individual_data['ID'] == id_val] plt.plot(id_data['Time'], id_data['Factor_Score'], '-', linewidth=1.5, alpha=0.7, label=f'ID {id_val}')plt.title(f'纵向因子分析:个体因子得分轨迹', fontsize=16, fontweight='bold')plt.xlabel('时间点', fontsize=14, fontweight='bold')plt.ylabel('因子得分', fontsize=14, fontweight='bold')plt.grid(True, alpha=0.3)plt.legend(title='个体ID', bbox_to_anchor=(1.05, 1), loc='upper left')plt.tight_layout()# 保存轨迹图p2_path = fig_dir / "LFA_因子得分个体轨迹图.png"plt.savefig(p2_path, dpi=300, bbox_inches='tight')plt.close()print(f"因子得分个体轨迹图已保存: {p2_path}")# 5.3 跨时间因子载荷图(可选)print("\n5.3 生成跨时间因子载荷图...")try:# 为每个时间点进行单独的因子分析 loadings_data_list = []for time_point in sorted(fa_data_complete['Time'].unique()): time_data = fa_data_complete[fa_data_complete['Time'] == time_point].copy()if len(time_data) >= 10: # 确保有足够的数据 try: indicator_data = time_data[indicator_cols].copy() fa_time = FactorAnalyzer(n_factors=1, rotation='varimax', method='ml') fa_time.fit(indicator_data) time_loadings = fa_time.loadings_for i, var in enumerate(indicator_cols): loadings_data_list.append({'Variable': var,'Time': time_point,'Loading': time_loadings[i, 0] }) except Exception as e:print(f"时间点 {time_point} 的因子分析失败: {e}")if loadings_data_list: loadings_data = pd.DataFrame(loadings_data_list)# 跨时间因子载荷图 plt.figure(figsize=(10, 6))# 为每个指标绘制线 colors = plt.cm.Set1(np.linspace(0, 1, len(indicator_cols)))for idx, var in enumerate(sorted(loadings_data['Variable'].unique())): var_data = loadings_data[loadings_data['Variable'] == var].sort_values('Time') plt.plot(var_data['Time'], var_data['Loading'], '-o', linewidth=2, markersize=8, label=var, color=colors[idx]) plt.title('纵向因子分析:跨时间因子载荷稳定性', fontsize=16, fontweight='bold') plt.xlabel('时间点', fontsize=14, fontweight='bold') plt.ylabel('因子载荷', fontsize=14, fontweight='bold') plt.grid(True, alpha=0.3) plt.legend(title='测量指标', loc='best') plt.tight_layout()# 保存载荷图 p3_path = fig_dir / "LFA_跨时间因子载荷图.png" plt.savefig(p3_path, dpi=300, bbox_inches='tight') plt.close()print(f"跨时间因子载荷图已保存: {p3_path}")else:print("无法计算跨时间因子载荷,跳过此图")except Exception as e:print(f"生成跨时间因子载荷图失败: {e}")# 6. 增长曲线模型分析print("\n6. 因子得分增长曲线模型分析...")# 6.1 准备增长曲线数据growth_data = factor_scores_df.copy()growth_data = growth_data.dropna(subset=['Factor_Score', 'Time'])if len(growth_data) > 0: growth_data['Time_c'] = growth_data['Time'] - growth_data['Time'].mean() # 中心化时间变量 growth_data['Time_sq'] = growth_data['Time_c'] ** 2 # 二次项# 6.2 线性增长模型print("\n6.2 拟合线性增长模型...") try:# 使用简单线性回归作为基线 X = sm.add_constant(growth_data['Time_c']) y = growth_data['Factor_Score'] linear_model_simple = sm.OLS(y, X).fit()print("简单线性模型拟合成功!")print("\n线性增长模型摘要:")print(linear_model_simple.summary()) linear_model = linear_model_simple# 尝试混合线性模型(如果数据适合)if growth_data['ID'].nunique() > 1 and len(growth_data) > growth_data['ID'].nunique(): try:# 使用statsmodels的混合线性模型 md = mixedlm("Factor_Score ~ Time_c", growth_data, groups=growth_data["ID"]) mdf = md.fit()print("\n混合线性模型拟合成功!")print(mdf.summary()) linear_model = mdf except Exception as e:print(f"混合线性模型失败: {e}")print("使用简单线性模型") except Exception as e:print(f"线性增长模型拟合失败: {e}") linear_model = Noneelse:print("增长曲线数据不足") linear_model = None# 6.3 二次增长模型(可选)print("\n6.3 尝试二次增长模型...")if linear_model is not None and len(growth_data) > 0: try:# 尝试二次模型 X_quad = sm.add_constant(growth_data[['Time_c', 'Time_sq']]) y = growth_data['Factor_Score'] quadratic_model_simple = sm.OLS(y, X_quad).fit()print("二次模型(简单回归)拟合成功!")# 比较模型(使用AIC)print("\n线性 vs 二次模型比较:")if hasattr(linear_model, 'aic'):print(f"线性模型AIC: {linear_model.aic:.3f}")if hasattr(quadratic_model_simple, 'aic'):print(f"二次模型AIC: {quadratic_model_simple.aic:.3f}")# 简单比较:如果二次项的p值显著且AIC降低,则选择二次模型 quad_params = quadratic_model_simple.params quad_pvalues = quadratic_model_simple.pvaluesif'Time_sq'in quad_pvalues.index: time_sq_p = quad_pvalues['Time_sq']if time_sq_p < 0.05:print(f"二次项显著 (p={time_sq_p:.4f}),二次模型更优") final_growth_model = quadratic_model_simple growth_model_type = "二次模型"else:print(f"二次项不显著 (p={time_sq_p:.4f}),线性模型足够") final_growth_model = linear_model growth_model_type = "线性模型"else:print("无法获取二次项p值,使用线性模型") final_growth_model = linear_model growth_model_type = "线性模型" except Exception as e:print(f"二次增长模型拟合失败: {e}")print("使用线性模型作为最终模型") final_growth_model = linear_model growth_model_type = "线性模型"else:print("无法拟合增长模型") final_growth_model = None growth_model_type = "未拟合"# 7. 创建综合结果表格print("\n7. 创建综合结果表格...")# 创建表格文件夹table_dir = results_dir / "tables"table_dir.mkdir(exist_ok=True)# 7.1 因子分析参数表print("\n7.1 因子分析参数表...")if'factor_loadings_df'in locals() and factor_loadings_df is not None and 'communalities_df'in locals() and communalities_df is not None: factor_param_table = factor_loadings_df.copy()# 添加共同度if factor_param_table.shape[0] == communalities_df.shape[0]: factor_param_table['共同度'] = communalities_df['共同度'].values# 重命名列 factor_param_table = factor_param_table.reset_index() factor_param_table = factor_param_table.rename(columns={'index': '指标'})# 保存为CSV factor_param_path = table_dir / "LFA_因子分析参数表.csv" factor_param_table.to_csv(factor_param_path, index=False, encoding='utf-8-sig')print(f"因子分析参数表已保存: {factor_param_path}")# EFA拟合指标表 efa_fit_data = {'指标': ['总体KMO值', 'Bartlett检验p值', '提取因子数'],'值': [f"{kmo_model:.3f}", f"{p_value:.4f}", str(n_factors)] } efa_fit_df = pd.DataFrame(efa_fit_data) efa_fit_path = table_dir / "LFA_拟合优度表.csv" efa_fit_df.to_csv(efa_fit_path, index=False, encoding='utf-8-sig')print(f"拟合优度表已保存: {efa_fit_path}")# 7.2 因子得分描述表print("\n7.2 因子得分描述表...")factor_score_summary = factor_scores_df.groupby('Time').agg( 个案数=('Factor_Score', 'count'), 均值=('Factor_Score', lambda x: round(x.mean(), 3)), 标准差=('Factor_Score', lambda x: round(x.std(), 3)), 最小值=('Factor_Score', lambda x: round(x.min(), 3)), 最大值=('Factor_Score', lambda x: round(x.max(), 3)), 标准误=('Factor_Score', lambda x: round(x.std() / np.sqrt(len(x)), 3))).reset_index()factor_score_summary = factor_score_summary.rename(columns={'Time': '时间点'})factor_score_path = table_dir / "LFA_因子得分描述表.csv"factor_score_summary.to_csv(factor_score_path, index=False, encoding='utf-8-sig')print(f"因子得分描述表已保存: {factor_score_path}")# 7.3 增长模型参数表print("\n7.3 增长模型参数表...")if final_growth_model is not None:if hasattr(final_growth_model, 'random_effects'): # 混合模型# 固定效应 fixed_effects = pd.DataFrame({'参数': final_growth_model.params.index,'估计值': final_growth_model.params.values,'标准误': final_growth_model.bse.values,'z值': final_growth_model.tvalues.values,'p值': final_growth_model.pvalues.values }) fixed_effects['估计值'] = fixed_effects['估计值'].round(3) fixed_effects['标准误'] = fixed_effects['标准误'].round(3) fixed_effects['z值'] = fixed_effects['z值'].round(3) fixed_effects['p值'] = fixed_effects['p值'].round(4)# 随机效应方差 random_effects_data = []# 提取随机效应协方差矩阵if hasattr(final_growth_model, 'cov_re'): cov_re = final_growth_model.cov_reif isinstance(cov_re, pd.DataFrame):# 提取对角线元素(方差)for param in cov_re.index: random_effects_data.append({'参数': f'{param}方差','估计值': round(cov_re.loc[param, param], 3) })# 残差方差if hasattr(final_growth_model, 'scale'): random_effects_data.append({'参数': '残差方差','估计值': round(final_growth_model.scale, 3) }) random_effects = pd.DataFrame(random_effects_data)else: # 简单线性模型# 固定效应 fixed_effects = pd.DataFrame({'参数': final_growth_model.params.index,'估计值': final_growth_model.params.values.round(3),'标准误': final_growth_model.bse.values.round(3),'t值': final_growth_model.tvalues.values.round(3),'p值': final_growth_model.pvalues.values.round(4) })# 随机效应(残差方差) random_effects = pd.DataFrame({'参数': ['残差方差'],'估计值': [round(final_growth_model.mse_resid, 3)] })# 保存表格 fixed_effects_path = table_dir / "LFA_增长模型固定效应表.csv" fixed_effects.to_csv(fixed_effects_path, index=False, encoding='utf-8-sig') random_effects_path = table_dir / "LFA_增长模型随机效应表.csv" random_effects.to_csv(random_effects_path, index=False, encoding='utf-8-sig')print(f"增长模型固定效应表已保存: {fixed_effects_path}")print(f"增长模型随机效应表已保存: {random_effects_path}")# 7.4 综合报告表print("\n7.4 创建综合报告表...")# 计算因子得分范围factor_score_min = factor_scores_df['Factor_Score'].min()factor_score_max = factor_scores_df['Factor_Score'].max()comprehensive_report = pd.DataFrame({'分析项目': ['分析类型', '分析个体数', '时间点数', '测量指标数','提取因子数', 'KMO检验值', 'Bartlett球形检验p值','测量不变性', '因子得分范围', '增长模型类型','模型拟合状态', '主要发现摘要' ],'结果': ['纵向因子分析(LFA)', str(factor_scores_df['ID'].nunique()), str(factor_scores_df['Time'].nunique()), f'{len(indicator_cols)}个({", ".join(indicator_cols)})', str(n_factors), f"{kmo_model:.3f}", f"{p_value:.4f}", cfa_invariance if'cfa_invariance'in locals() else'未检验', f"{factor_score_min:.2f} ~ {factor_score_max:.2f}", growth_model_type if'growth_model_type'in locals() else'未拟合','成功拟合'if final_growth_model is not None else'未拟合','详见分析报告' ]})comprehensive_report_path = table_dir / "LFA_综合报告表.csv"comprehensive_report.to_csv(comprehensive_report_path, index=False, encoding='utf-8-sig')print(f"综合报告表已保存: {comprehensive_report_path}")# 8. 创建Word分析报告print("\n8. 正在生成Word分析报告...")try:# 创建Word文档 doc = Document()# 设置文档样式 style = doc.styles['Normal'] font = style.font font.name = '宋体' font.size = Pt(12)# 添加标题 title = doc.add_heading('纵向因子分析(LFA)分析报告', 0) title.alignment = WD_ALIGN_PARAGRAPH.CENTER# 添加日期 doc.add_paragraph(f"生成日期:{datetime.now().strftime('%Y年%m月%d日')}") doc.add_paragraph()# 1. 研究概述 doc.add_heading('1. 研究概述', level=1) doc.add_paragraph('纵向因子分析结合了传统因子分析和潜增长曲线模型的思想,旨在探索多个随时间重复测量的指标背后是否存在共同的、且其因子得分可能随时间变化的潜因子结构。') doc.add_paragraph() doc.add_paragraph('核心思想:') doc.add_paragraph('• 在不同时间点施加相同的因子载荷矩阵(测量不变性检验)', style='List Bullet') doc.add_paragraph('• 允许因子得分具有自己的增长曲线(截距和斜率)', style='List Bullet') doc.add_paragraph('• 追踪潜构念的演变,不仅验证测量工具的结构效度是否跨时间稳定,更关注潜因子本身的纵向发展规律', style='List Bullet') doc.add_paragraph()# 2. 数据描述 doc.add_heading('2. 数据描述', level=1) doc.add_paragraph(f"分析个体数:{factor_scores_df['ID'].nunique()}") doc.add_paragraph(f"时间点数:{factor_scores_df['Time'].nunique()}") doc.add_paragraph(f"测量指标:{', '.join(indicator_cols)}") doc.add_paragraph(f"时间跨度:{factor_scores_df['Time'].min()} 到 {factor_scores_df['Time'].max()}") doc.add_paragraph()# 3. 因子分析结果 doc.add_heading('3. 因子分析结果', level=1)# 3.1 因子分析适用性 doc.add_heading('3.1 因子分析适用性检验', level=2) doc.add_paragraph(f"KMO检验值:{kmo_model:.3f}") doc.add_paragraph(f"Bartlett球形检验p值:{p_value:.4f}")if kmo_model > 0.6: doc.add_paragraph('结论:数据适合进行因子分析')else: doc.add_paragraph('结论:数据可能不太适合因子分析,结果需谨慎解释')# 3.2 因子提取结果 doc.add_heading('3.2 因子提取结果', level=2)if'factor_param_table'in locals() and factor_param_table is not None:# 创建因子载荷表格 doc.add_paragraph('因子载荷矩阵:')# 创建表格 table = doc.add_table(rows=len(factor_param_table) + 1, cols=factor_param_table.shape[1]) table.style = 'Light Grid Accent 1'# 设置表头 header_cells = table.rows[0].cellsfor i, col in enumerate(factor_param_table.columns): header_cells[i].text = col# 填充数据for i, row in factor_param_table.iterrows(): row_cells = table.rows[i + 1].cellsfor j, col in enumerate(factor_param_table.columns): value = row[col]if isinstance(value, float): row_cells[j].text = f"{value:.3f}"else: row_cells[j].text = str(value) doc.add_paragraph() doc.add_paragraph('解释:因子载荷表示各测量指标与潜因子的相关程度,载荷值越高表示该指标对因子的代表性越好。')# 4. 测量不变性检验 doc.add_heading('4. 测量不变性检验', level=1) doc.add_paragraph('测量不变性检验用于验证测量工具在不同时间点是否测量同一潜构念,是纵向因子分析的前提。')if'cfa_invariance'in locals(): doc.add_paragraph(f"测量不变性检验结果:{cfa_invariance}")if cfa_invariance == "弱不变性成立": doc.add_paragraph('结论:弱不变性成立,因子载荷在不同时间点相等,满足纵向比较的前提条件。')elif cfa_invariance == "弱不变性不成立": doc.add_paragraph('结论:弱不变性不成立,测量工具在不同时间点的测量性质可能发生变化,结果解释需谨慎。')else: doc.add_paragraph('注:由于样本量限制或软件包问题,未进行完整的测量不变性检验。') doc.add_paragraph()# 5. 因子得分轨迹分析 doc.add_heading('5. 因子得分轨迹分析', level=1) doc.add_paragraph('因子得分轨迹反映了潜构念随时间的变化模式。')if'factor_score_summary'in locals() and factor_score_summary is not None:# 创建因子得分描述表格 doc.add_paragraph('各时间点因子得分描述统计:') table = doc.add_table(rows=len(factor_score_summary) + 1, cols=len(factor_score_summary.columns)) table.style = 'Light Grid Accent 1'# 设置表头 header_cells = table.rows[0].cellsfor i, col in enumerate(factor_score_summary.columns): header_cells[i].text = col# 填充数据for i, row in factor_score_summary.iterrows(): row_cells = table.rows[i + 1].cellsfor j, col in enumerate(factor_score_summary.columns): value = row[col]if isinstance(value, float): row_cells[j].text = f"{value:.3f}"else: row_cells[j].text = str(value) doc.add_paragraph()# 5.1 因子得分轨迹图 doc.add_heading('5.1 因子得分轨迹图', level=2) doc.add_paragraph('该图展示了潜因子得分随时间的变化趋势:') doc.add_paragraph('• 蓝色线:群体平均因子得分', style='List Bullet') doc.add_paragraph('• 红色点:各时间点的均值', style='List Bullet') doc.add_paragraph('• 阴影区域:95%置信区间', style='List Bullet') doc.add_paragraph()# 添加图片if p1_path.exists(): doc.add_picture(str(p1_path), width=Inches(6))# 5.2 个体轨迹图 doc.add_heading('5.2 个体因子得分轨迹', level=2) doc.add_paragraph('该图展示了个体水平的因子得分变化轨迹,反映了潜构念发展的个体差异。') doc.add_paragraph()if p2_path.exists(): doc.add_picture(str(p2_path), width=Inches(6))# 6. 增长曲线模型 doc.add_heading('6. 增长曲线模型分析', level=1) doc.add_paragraph('增长曲线模型用于量化潜因子得分的变化模式,估计平均增长轨迹和个体差异。')if final_growth_model is not None: doc.add_paragraph(f"模型类型:{growth_model_type}") doc.add_paragraph('主要发现:')if'fixed_effects'in locals() and fixed_effects is not None:# 查找时间效应 time_effects = fixed_effects[fixed_effects['参数'].str.contains('Time', na=False)]if not time_effects.empty: time_effect = time_effects.iloc[0] p_val = float(time_effect['p值'])if p_val < 0.05: beta = float(time_effect['估计值']) doc.add_paragraph(f"• 时间效应显著 (β = {beta:.3f}, p = {p_val:.3f}),表明潜因子得分随时间显著变化。", style='List Bullet')else: doc.add_paragraph( f"• 时间效应不显著 (β = {float(time_effect['估计值']):.3f}, p = {p_val:.3f}),表明潜因子得分随时间变化不明显。", style='List Bullet')else: doc.add_paragraph('注:由于数据限制,未能成功拟合增长曲线模型。') doc.add_paragraph()# 7. 结论与建议 doc.add_heading('7. 结论与建议', level=1)# 根据分析结果给出结论if kmo_model > 0.6: doc.add_paragraph('• 数据适合进行因子分析,提取的潜因子具有良好的测量属性。', style='List Bullet')else: doc.add_paragraph('• 数据因子分析适用性有限,结果需谨慎解释。', style='List Bullet')if'cfa_invariance'in locals() and cfa_invariance == "弱不变性成立": doc.add_paragraph('• 测量工具在不同时间点具有稳定性,满足纵向比较条件。', style='List Bullet')if final_growth_model is not None and 'fixed_effects'in locals() and fixed_effects is not None: time_effects = fixed_effects[fixed_effects['参数'].str.contains('Time', na=False)]if not time_effects.empty: time_effect = time_effects.iloc[0] p_val = float(time_effect['p值'])if p_val < 0.05: beta = float(time_effect['估计值'])if beta > 0: doc.add_paragraph('• 潜因子得分随时间显著增长,表明所测量的构念随时间改善。', style='List Bullet')else: doc.add_paragraph('• 潜因子得分随时间显著下降,表明所测量的构念随时间恶化。', style='List Bullet')else: doc.add_paragraph('• 潜因子得分随时间变化不显著,表明所测量的构念相对稳定。', style='List Bullet') doc.add_paragraph() doc.add_paragraph('建议:') doc.add_paragraph('1. 增加样本量以提高分析稳定性和统计功效', style='List Bullet') doc.add_paragraph('2. 收集更多时间点数据以识别非线性变化模式', style='List Bullet') doc.add_paragraph('3. 纳入协变量(如年龄、性别、治疗类型)分析其对因子轨迹的影响', style='List Bullet') doc.add_paragraph('4. 考虑多组分析,比较不同亚组的因子发展轨迹', style='List Bullet') doc.add_paragraph('5. 开发实时监测系统,基于因子得分轨迹进行早期预警', style='List Bullet') doc.add_paragraph()# 8. 技术附录 doc.add_heading('8. 技术附录', level=1) doc.add_paragraph('分析方法:') doc.add_paragraph('• 探索性因子分析:最大似然估计,方差最大旋转', style='List Bullet') doc.add_paragraph('• 验证性因子分析:测量不变性检验(如可用)', style='List Bullet') doc.add_paragraph('• 因子得分计算:回归法/主成分分析', style='List Bullet') doc.add_paragraph('• 增长曲线模型:线性混合效应模型/简单线性回归', style='List Bullet') doc.add_paragraph() doc.add_paragraph('软件与版本:') doc.add_paragraph(f"• Python版本:{sys.version.split()[0]}", style='List Bullet') doc.add_paragraph('• 主要分析包:factor_analyzer, statsmodels, scikit-learn', style='List Bullet') doc.add_paragraph()# 保存Word文档 word_file = results_dir / f"LFA_分析报告_{datetime.now().strftime('%Y%m%d')}.docx" doc.save(str(word_file))print(f"Word分析报告已保存: {word_file}")except Exception as e:print(f"Word报告生成失败: {e}")# 创建最简单的报告 try: simple_doc = Document() simple_doc.add_heading('纵向因子分析(LFA)分析报告', 0) simple_doc.add_paragraph(f"生成日期:{datetime.now().strftime('%Y年%m月%d日')}") simple_doc.add_paragraph() simple_doc.add_paragraph('分析完成。') simple_doc.add_paragraph(f"分析个体数:{factor_scores_df['ID'].nunique()}") simple_doc.add_paragraph(f"时间点数:{factor_scores_df['Time'].nunique()}") simple_doc.add_paragraph(f"提取因子数:{n_factors}") simple_doc.add_paragraph('详细结果请查看CSV文件和可视化图片。') simple_word_file = results_dir / f"LFA_简易报告_{datetime.now().strftime('%Y%m%d')}.docx" simple_doc.save(str(simple_word_file))print(f"简易Word报告已保存: {simple_word_file}") except Exception as e2:print(f"简易报告也失败: {e2}")# 9. 保存工作空间print("\n9. 保存工作空间...")try:# 创建保存对象字典 save_objects = {'fa_data_complete': fa_data_complete,'factor_scores_df': factor_scores_df,'trajectory_data': trajectory_data,'factor_param_table': factor_param_table if'factor_param_table'in locals() else None,'factor_score_summary': factor_score_summary if'factor_score_summary'in locals() else None,'comprehensive_report': comprehensive_report if'comprehensive_report'in locals() else None,'indicator_cols': indicator_cols,'n_factors': n_factors,'kmo_model': kmo_model,'p_value': p_value }# 保存为pickle文件 workspace_path = results_dir / "LFA_Analysis_Workspace.pkl" with open(workspace_path, 'wb') as f: pickle.dump(save_objects, f)print(f"完整工作空间已保存: {workspace_path}")except Exception as e:print(f"工作空间保存失败: {e}")# 10. 汇总输出print("\n" + "=" * 70)print("纵向因子分析(LFA)分析完成!")print("=" * 70)print("\n结果文件汇总:")result_files = ["LFA_因子分析参数表.csv","LFA_拟合优度表.csv","LFA_因子得分描述表.csv","LFA_综合报告表.csv"]for file in result_files: file_path = table_dir / fileif file_path.exists():print(f"✓ {file_path}")# 检查其他可能生成的文件additional_files = ["LFA_增长模型固定效应表.csv","LFA_增长模型随机效应表.csv"]for file in additional_files: file_path = table_dir / fileif file_path.exists():print(f"✓ {file_path}")print("\n可视化文件汇总:")visual_files = ["LFA_因子得分群体轨迹图.png","LFA_因子得分个体轨迹图.png","LFA_跨时间因子载荷图.png"]for file in visual_files: file_path = fig_dir / fileif file_path.exists():print(f"✓ {file_path}")print("\n报告文件汇总:")report_files = list(results_dir.glob("LFA_*报告*.docx"))for file in report_files:print(f"✓ {file}")print("\n工作空间文件:")workspace_files = list(results_dir.glob("LFA_*.pkl"))for file in workspace_files:print(f"✓ {file}")print(f"\n分析完成!所有结果已保存在 {results_dir} 文件夹中。")# 保存运行日志log_content = f"""纵向因子分析(LFA)分析完成分析时间: {datetime.now()}分析个体数: {factor_scores_df['ID'].nunique()}时间点数: {factor_scores_df['Time'].nunique()}测量指标: {', '.join(indicator_cols)}提取因子数: {n_factors}KMO值: {kmo_model:.3f}Bartlett检验p值: {p_value:.4f}增长模型拟合: {'成功' if final_growth_model is not None else '失败'}结果保存目录: {results_dir}"""log_path = results_dir / "分析日志.txt"with open(log_path, 'w', encoding='utf-8') as f: f.write(log_content)print(f"分析日志已保存: {log_path}")

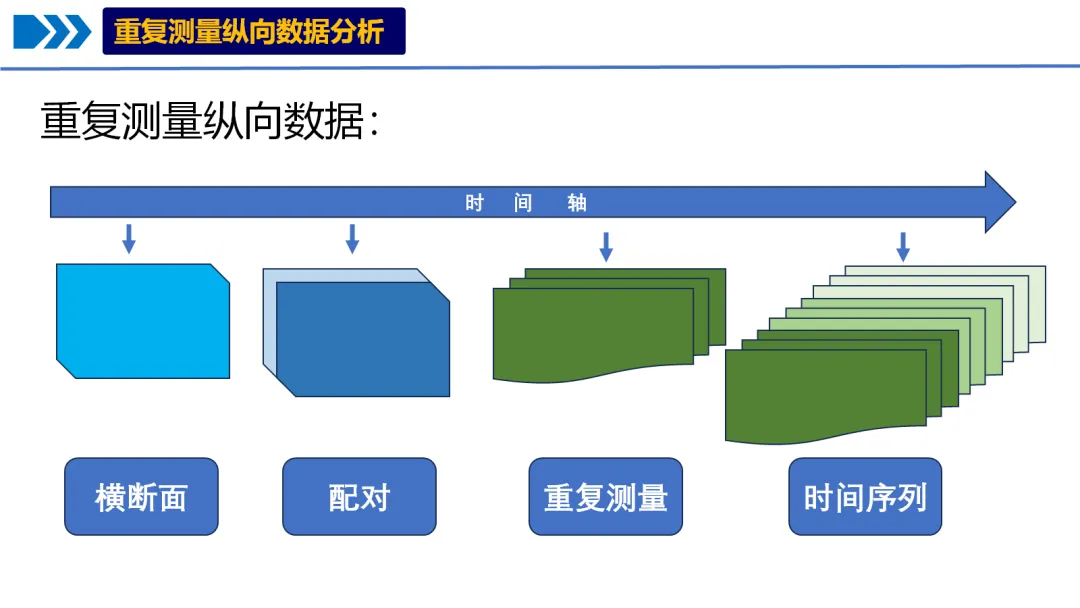

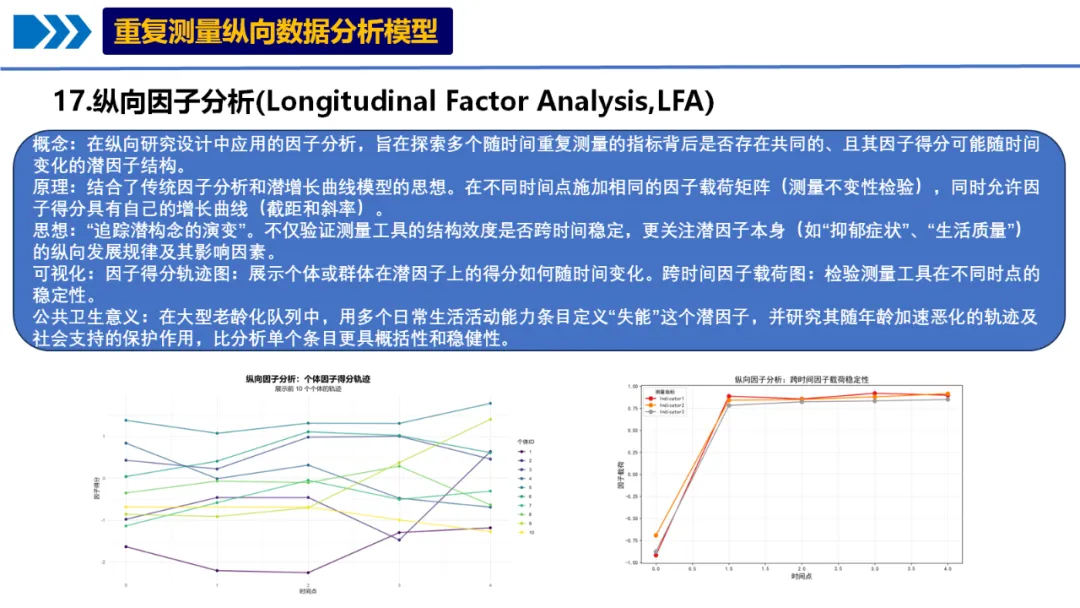
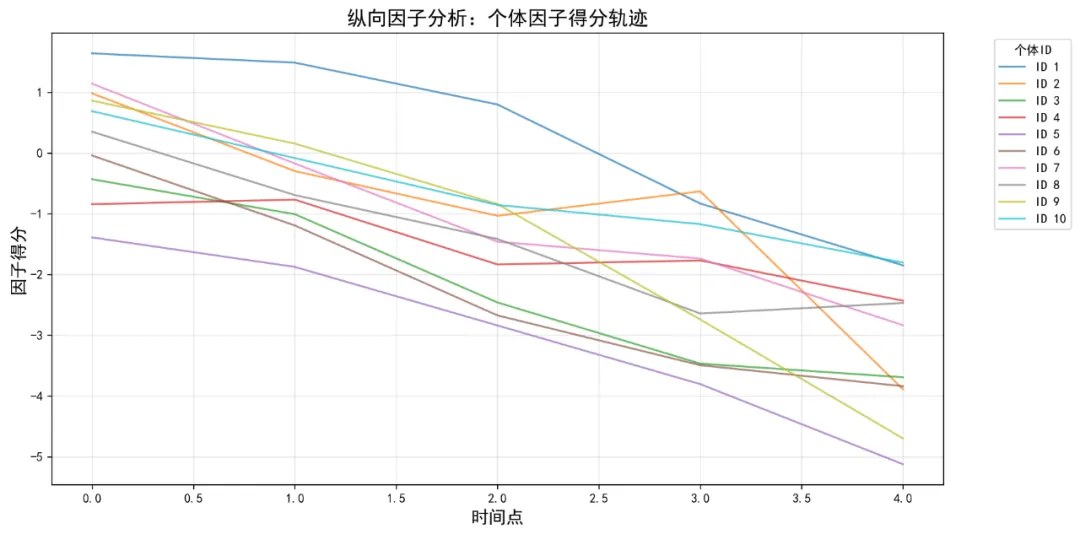





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
